
CISOレポート
デジタルレジリエンスへの道を取締役会と共に歩む
CISOと取締役会はかつてないほど緊密に連携しています。それぞれが果たすべき役割はまったく異なるため、成功指標に対する認識にずれがあります。

Phishing(フィッシング)メールとは、受信者を欺き、ログイン資格情報、金融情報、個人データなどの機密情報を明かさせるように仕組まれた詐欺的または悪意のあるメールです。フィッシングメールの内容は通常、受信者を操作する可能性が高いさまざまなソーシャルエンジニアリングの手法を利用しており、個人や企業の情報セキュリティに重大な損害をもたらす可能性があります。そのため、セキュリティセクターにおいてフィッシングメールの検知を実装することは非常に重要です。
過去において、フィッシング検知アルゴリズムは、不審なメールを検知するために固定なルールやパターンに依存していました。例えば、送信者の設定をブラックリストと照合したり、URLを検証したり、スペルミスや文法エラー、特定のキーワードなどのテキスト的な特徴を分析することが挙げられます。
しかし、フィッシング攻撃がますます洗練される中で、これらのアルゴリズムが進化し、実際のテキスト内容を理解しながらセマンティックな構造を活用することが重要になってきました。メッセージそのものに焦点を当てることで、フィッシング検知システムは新たな手法に迅速に適応し、新興の脅威を効率的に検知し、偽陽性を大幅に削減することが可能となります。これにより、組織や個人をサイバー脅威から保護するための不可欠なツールとなっています。
このプロジェクトでは、自然言語処理(NLP)で広く使用されているニューラルネットワークアーキテクチャであるBERTモデル(Bidirectional Encoder Representations from Transformers)を使用して、フィッシングメール検知モデルを構築しました。BERTは大規模コーパスで事前にトレーニングされており、自然言語の高レベルな表現を学習し、テキスト分類などの下流のタスクに対して簡単にFine-tuningできるようになっています。
下の図に示されたように、BERTモデルは12個のTransformerブロックで構成されています。各ブロックにはself-attention機構を使用して、文章中の単語間の複雑な双方向の依存関係をモデル化し、ローカルおよびグローバルな文脈を捉えます。
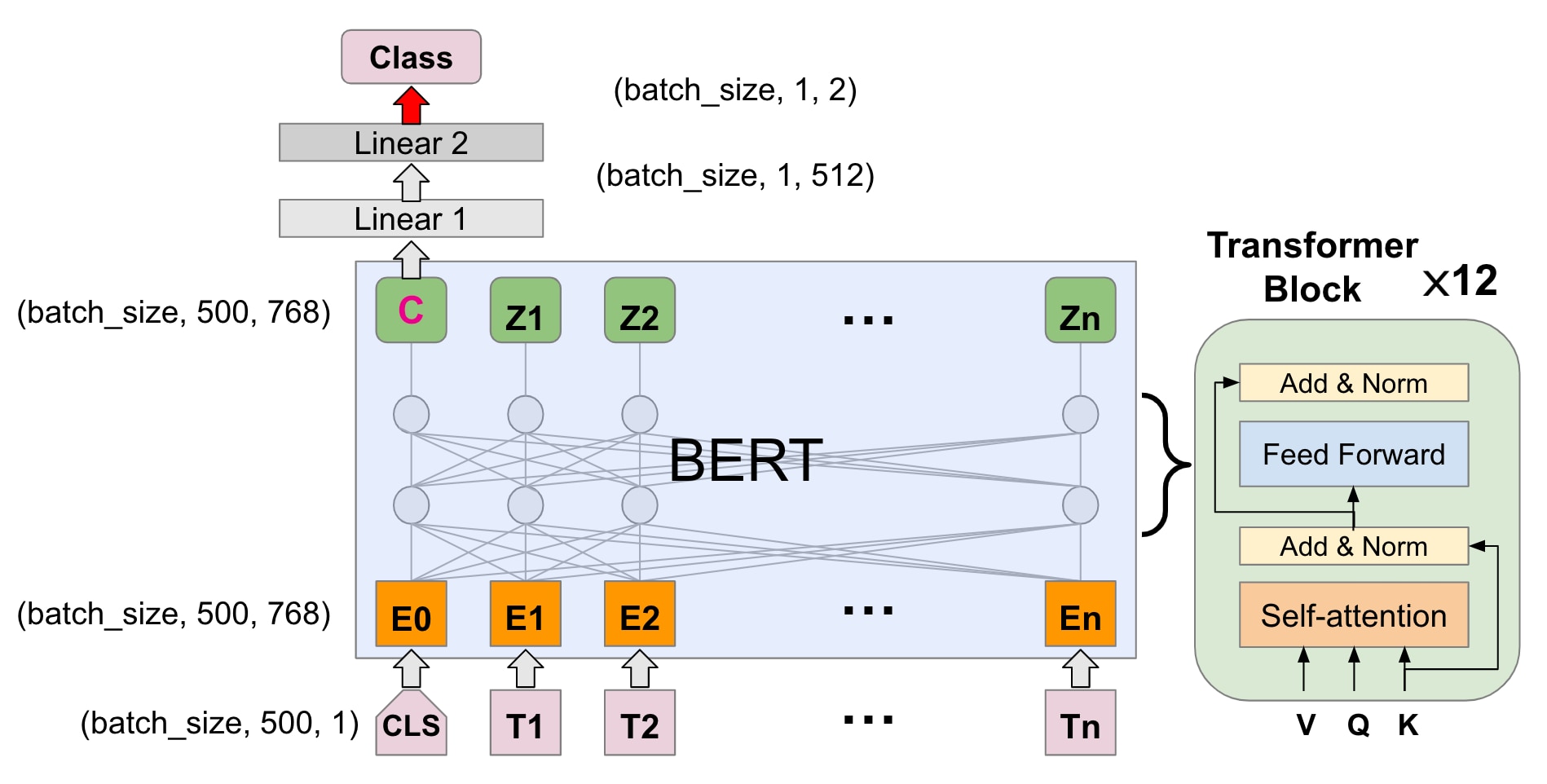
私たちは、テキスト分類タスク向けの公開ベンチマークから取得した181,781件のメールテキスト発話から成るデータセットを使用して、BERTモデルのFine-tuningを行いました。Fine-tuningでは、上記の図に示されているように、上位3つのTransformer層と線形層を20エポックの間更新し、検証損失が最も低いモデルを選択しました。
Fine-tuningされたモデルの実世界での性能を評価するために、別の情報源から取得したデータセット(32,681件のメールテキスト発話)を使用してテストしました。BERTベースのフィッシング検知モデルは、F1スコア0.99、真陽性率(True Positive)99.06%、真陰性率(True Negative)98.5%を達成しました。また、DistilBERT、LSTM、SVM、Random Forest、Logistic Regressionといった他のディープラーニングモデルや伝統的な機械学習アルゴリズムとBERTモデルを比較しました。さらに、メールのテキストデータだけでなく、通常の手法でよく使われるリンクやドメイン名などの他の特徴データも使用して実験を行いました。
以下の図に実験結果をプロットしました。BERTモデルは、すべての機械学習アルゴリズムを大きく上回り、深層学習モデルの中で最も優れたパフォーマンスを示しました。補助的な入力特徴の使用はBERTモデルのパフォーマンスに影響を与えませんでした。これは、BERTモデルにテキストのみを入力として使用することの適切性を示しています。

最新版のSplunk App for Data Science and Deep Learning(DSDL)にTransformersライブラリを統合することで、フィッシングメール検知モデルの展開が簡単にできています。
フィッシングメール検知モデルは、以下の手順でSplunk DSDLを介して展開できます:
wget https://huggingface.co/Huaibo/phishing_bert/resolve/main/pytorch_model.pt
| fit MLTKContainer algo=bert_phishing text from text into app:bert_phishing as prediction
次のスクリーンショットは、メールテキストの入力を使用して、Splunk Search & Reporting appでモデルのパフォーマンスを示しています。ラベルフィールドは、メールがフィッシングかどうかを示しており、モデルの出力はpredictionフィールドに表示されます。モデルはすべての入力サンプルを正しくラベル付けし、フィッシングメールの検知におけるその効果を示しています。

実世界の応用では、さまざまな形式のメールテキストデータを含むことがよくありますので、モデルが高い頑健性を持つことが重要です。そのため、ウェブスクレイピングされたデータを使用してモデルの性能をさらに評価しました。以下のスクリーンショットにあるデータセットにはランダムなトークンや文字の繰り返しが含まれており、ノイズが多く構造化されていない入力が多くあります。このような追加の複雑さにもかかわらず、モデルは正確にサンプルをラベル付けすることでその頑健性を示し、多様な入力テキストを処理する能力を見せました。

このプロジェクトでは、BERTモデルをベースとした高度なフィッシングメール検知モデルを開発しました。大規模なデータセットでのFine-tuningにより、他のテキストベースの手法を上回るパフォーマンスが得られました。また、Splunk DSDLを介したモデルの展開にも成功し、この機能は次回リリースで正式にサポートされる予定です。
Note: このプロジェクトはSplunk Machine Learning for Security team (SMLS)との共同で実施されました。

Splunkプラットフォームは、データを行動へとつなげる際に立ちはだかる障壁を取り除いて、オブザーバビリティチーム、IT運用チーム、セキュリティチームの能力を引き出し、組織のセキュリティ、レジリエンス(回復力)、イノベーションを強化します。
Splunkは、2003年に設立され、世界の21の地域で事業を展開し、7,500人以上の従業員が働くグローバル企業です。取得した特許数は1,020を超え、あらゆる環境間でデータを共有できるオープンで拡張性の高いプラットフォームを提供しています。Splunkプラットフォームを使用すれば、組織内のすべてのサービス間通信やビジネスプロセスをエンドツーエンドで可視化し、コンテキストに基づいて状況を把握できます。Splunkなら、強力なデータ基盤の構築が可能です。

© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
