
CISOレポート
デジタルレジリエンスへの道を取締役会と共に歩む
CISOと取締役会はかつてないほど緊密に連携しています。それぞれが果たすべき役割はまったく異なるため、成功指標に対する認識にずれがあります。

筆者は幼い頃、映画「オズの魔法使い」を観て、悪い魔女の上に家が落ちたり、しゃべるライオンや空飛ぶサルが登場したりするお話にとてもワクワクしたことを覚えています。しかし、物語が進むにつれ、実は偉大な魔法使いがただの人間でしかなかったことがわかると、少しがっかりしました。そして、このところ爆発的な普及を見せるAI、とりわけ大規模言語モデル(LLM)に関しても、同じような感覚を覚えています。
一見すると魔法のように見えるLLMも、実際は人間が生み出した複雑なシステムに過ぎません。LLMは驚くようなことを可能にしますが、現実世界の域を出ないものであり、他のテクノロジーで何十年も行われてきたように、人が管理し、保護する必要があります。
ソフトウェア製品や食器洗い機、それに歯科治療の分野でさえ、「AIの搭載」がうたわれるようになっていますが、LLMやそのユーザーを保護するための取り組みはほとんど行われていません。その結果、LLMベースのアプリケーションが悪用され、ガードレールなしで運用される事例が、この1年で見られるようになっています。たとえば、次のような問題が実際に起こっています。
LLMのような高度なツールを保護するのは不可能だとする見方もあります。しかし、こうした誤解は、一般的に認知されているLLMの複雑さとAIの急速な進歩から生じています。LLMベースのアプリケーションの多くが、セキュリティをほとんど考慮されずに導入されているため、この誤解を払拭することが極めて重要です。
LLMは高度な機能を備えていますが、サイバーセキュリティの標準的な原則と手法を使用すれば、LLMを保護できます。また、LLMならではの脆弱性と脅威の侵入経路を理解することで、固い防御を確立できます。
このブログでは、LLMに対する脅威を検証するとともに、「OWASPトップ10」のフレームワークとSplunk製品を使用して、LLMベースのアプリケーションとそのユーザーの保護を強化するための例をいくつかご紹介します。
LLMに対する脅威の特徴を定義したフレームワークを探し求める中で見つけた最適なフレームワークが、「OWASP Top 10 for Large Language Model Applications (LLMアプリケーションのOWASPトップ10)」でした。
ご存じない方のために説明すると、OWASPはOpen Worldwide Application Security Projectの略で、「安全ではないソフトウェアをこれ以上作らない」という、シンプルながらも壮大なビジョンを掲げて活動しているコミュニティです。OWASPで最も有名なプロジェクトは、Webアプリケーションのセキュリティに焦点を当てた「OWASPトップ10」で、20年以上前から公開されています。
「LLMアプリケーションのOWASPトップ10」フレームワークは、最初に発表されたOWASPトップ10を基に構築されたもので、以下に関する明確なガイダンスを提供します。
OWASPが定義した、LLMアプリケーションに対する脅威のトップ10は以下のとおりです。
| LLM01: プロンプトインジェクション | プロンプトインジェクションでは、巧妙に作成した入力を利用してLLMを不正に操作し、LLMの意図しない動作を誘発します。 |
| LLM02: 安全でない出力処理 | 安全でない出力処理とは、LLMが生成する出力をサニタイジングや詳細なチェックをすることなく処理し、バックエンドの他のコンポーネントやシステムに送ることです。 |
| LLM03: トレーニングデータポイズニング | トレーニングデータポイズニングとは、トレーニング前のデータ、またはファインチューニングや組み込みのプロセスで扱うデータを改ざんして、脆弱性を生み出す行為のことです。 |
| LLM04: モデルへのサービス拒否(DoS)攻撃 | LLMが極めて大量のリソースを消費するように仕向け、LLMを使ったサービスの品質低下を狙った攻撃です。 |
| LLM05: サプライチェーンの脆弱性 | LLMのサプライチェーンにある脆弱性を攻撃されると、トレーニングデータ、MLモデル、デプロイ先プラットフォームの整合性が損なわれる可能性があります。 |
| LLM06: 機密情報の開示 | LLMアプリケーションが出力する際に、機密情報や独自のアルゴリズムといった非公開の情報を外部に開示する恐れがあります。 |
| LLM07: 安全でないプラグインの設計 | LLMの拡張機能であるプラグインは、有効にすると、ユーザーの操作中にモデルによって自動的に呼び出されます。プラグインの挙動はモデルの管理下にあり、アプリケーション側で制御することはできません。 |
| LLM08: 過剰な代理行為 | 過剰な代理行為とは、LLMが出力する想定外のあいまいな結果に応じて、(LLMの誤動作の原因にかかわらず)有害なアクションが実行される脆弱性のことです。 |
| LLM09: 過度の信頼 | LLMは誤った情報をあたかも信頼できる情報であるかのように提供することがあり、このような状況を過度の信頼と言います。LLMは建設的で有益なコンテンツだけでなく、事実に反したコンテンツや不適切なコンテンツ、または安全ではないコンテンツを生成する可能性があります。 |
| LLM10: モデルの窃盗 | モデルの窃盗は、攻撃者またはAPTによってLLMモデルが不正にアクセスされ、データが流出することで発生します。具体的には、独自のLLMモデル(貴重な知的財産)が侵害されたり、物理的に盗まれたり、コピーされたりするほか、重み付けやパラメーターが抽出され、同等の機能を持つモデルが作成されることもあります。 |
脅威検出の検証を進めるにあたり、次々に登場する各LLMを直接操作するのではなく、最も効果を得られそうな領域に調査対象を絞ってプロンプトとその回答を収集しました。プロンプトとはLLMに指示するための入力であり、回答とはLLMがその入力に対して返す出力です。
LLMに張り付いて作業しなくても、プロンプトとその回答を簡単に取得して、分析に利用できました。
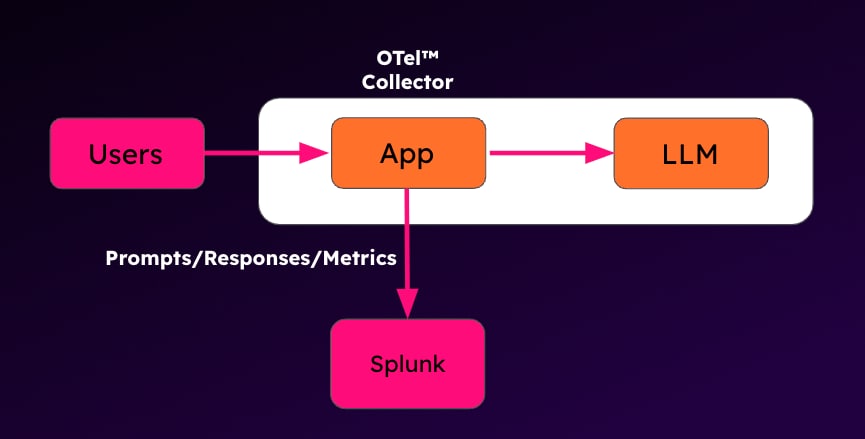
ログ収集アプローチを示した概略図
実際にどのような手法をとったかというと、それはログの収集です。LLMベースのアプリケーション(シンプルなチャットインターフェイス)をインストルメントし、すべてのプロンプト、その回答、他の関心のある項目(トークンの使用状況や遅延など)をログに記録してから、Splunk OpenTelemetry Collector (OTel)を使ってSplunkに取り込みました。一般的に使用されているユニバーサルフォワーダーではなくOpenTelemetry Collectorを使用したのは、LLMベースのアプリケーションスタックの一部としてメトリクスとトレースを収集したいと考えたからです。
フロントエンドシステムは自社で構築し、そのときに関連するログやメトリクスをOpenTelemetry Collectorのjournaldレシーバーを使用して収集できるように構築しました。そして、組み込みのHEC (HTTP Event Collector)エクスポーターを介して、Splunkインスタンスにデータを送信します。バックエンドのLLMサービス(llama-cpp-python)については、OpenTelemetry自動インストルメンテーションパッケージを使用して実行し、その際にテレメトリを収集しました。
OWASPトップ10のうち、以下の5項目については、プロンプトとLLMの回答を使用するだけで対処できることがわかりました。
ここでの検証はまだ理論的な段階にあります。嘘をつく必要はありませんので正直に申し上げると、私たちがこれらの脅威を検出するために開発した手法は、私たちのラボでは機能しますが、皆さんの環境で使用するには一定の調整が必要になると思います。
加えて、どのベンダーの製品であっても、市販の検出ツールのほとんどで、環境に合わせた調整が必要になるはずです(言い訳めいた話をするのは、このあたりでやめておきましょう)。
プロンプトインジェクションを検出するには、相互に関連する多くの要素を考慮する必要があります。プロンプトインジェクション攻撃では、不正なプロンプトを入力してLLMを不正に操作し、LLMの意図しない出力を引き起こします。こういった悪質なプロンプトを作成する方法は多岐にわたるため、シンプルな検出ルールを作成して対応することは困難です。
そのため、従来のサーチ方法では十分な成果が得られない可能性があります。しかし、Splunkの機械学習と異常検出技術を活用することで、プロンプトインジェクション攻撃を示す異常なパターンを特定するモデルを構築できます。
幸いにも、Protect AI社がプロンプトインジェクション検出用モデルをすでに作成していたため、これを活用しました。ただし、公開されているどのモデルにもいえることですが、モデル自体にリスクが存在する可能性があるため、必ずデューデリジェンスを実施する必要があります。私たちの検証では、Splunkから取得したデータをこの検出モデルに渡し、その結果をSplunkに出力するJupyter Notebookを構築しました。
ほとんどのJupyter Notebookでは、最初のフェーズでさまざまなPythonライブラリをインストールしてインポートすることで、以降のコードを実行するための環境を準備できます。
Jupyter Notebookのライブラリインポートフェーズ
フェーズ1では、Jupyter Notebookで使用するために必要なデータをSplunkから収集します。以下の画像に詳細が書かれていますが、主なポイントは、fitコマンドを使用してサーチ結果をコンテナに転送することです。

Jupyter Notebookのデータ収集フェーズ
フェーズ2では、トークナイザー、モデル、分類関数を定義します。ここで、Jupyter Notebookを使って主な処理をコーディングします。

Jupyter Notebookのモデル初期化フェーズ
Jupyter Notebookの下部で、プロンプトインジェクションを検出するために、しきい値を高めに設定しました(1.0に近いほど一致度が高くなります)。ただ、このしきい値は誤検知の許容度に応じて簡単に調整できます。

Jupyter Notebookのしきい値のコード
Jupyter Notebookで最後に作成するのは、フェーズ1でSplunkから収集したデータをモデルに渡し、その結果をprompt:injectionという名前の新しいソースタイプとしてSplunkに取り込む処理です。

データをモデルに渡して処理し、結果をSplunkに取り込むためのJupyter Notebookのコード
以下のスクリーンショットでおわかりのように、データセットの上位3つの結果はすべてプロンプトインジェクションの試行であり、モデルはこの試行を高い精度で検出しています。

Splunkのプロンプトインジェクションの検出結果
安全でない出力処理は、LLMのユーザーとLLMベースのアプリケーションそのものに影響を及ぼす可能性があります。
ここではっきりお伝えしたいことは、LLMベースのアプリケーションにも、Webアプリケーションの基本的なセキュリティ対策を実装する必要があることです。また、見逃していた脆弱性や攻撃があればすぐに対処できるように、必ず検出ルールも作成しておきましょう。
XSSとSQLiの検出では、どちらも正規表現を利用できますが、その作業はすぐに負担が高くなります。プロンプトインジェクションの例では、Jupyter Notebookを使用して、データに潜むXSSとSQLiを検出しました。これらの脅威の検出に使える公開モデルが見当たらなかったため、私たちは独自のモデルをトレーニングしました。モデルのトレーニングについて説明すると、それだけで1本のブログ記事になってしまうため、ここでは私たちが実行した手順とその結果を簡単に説明します。
XSSを検出するために、以下の複数のアルゴリズムを使用してモデルをトレーニングしました。
公開されている複数のデータセット(悪質なデータを含むデータセットなのでリンクは張っていません)を組み合わせて使ってトレーニングすることで、XSSの検出に最適なアルゴリズムを決定しました。
以下に示す画像は混同行列と呼ばれるもので、真陽性や偽陽性などをまとめた表です。数字の1は実際のXSSデータのラベル、0は良性データのラベルです。色が濃いマスの数値が大きく、色が薄いマスの数値が小さいと、良好な状態と判断できます。次に、最終スコアであるF1スコアを計算し、モデルの精度を評価するのに役立つ平均スコアを算出します。
ロジスティック回帰のF1スコアは0.9898で非常に良好な結果となりました。
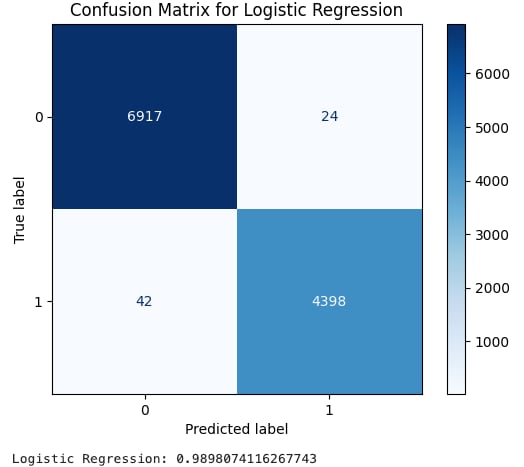
XSSのロジスティック回帰のトレーニング結果
ランダムフォレストはF1スコアが0.9934になり、ロジスティック回帰よりもやや優れた結果となりました。
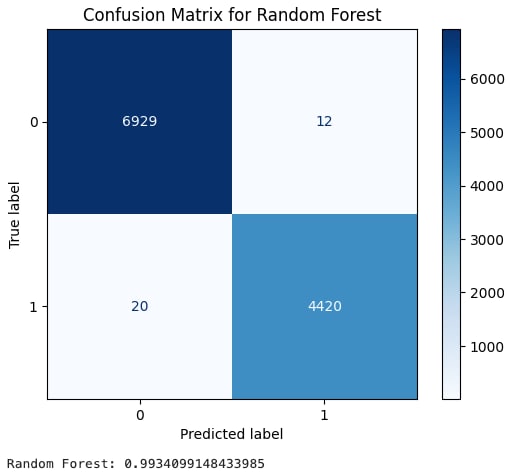
XSSのランダムフォレストのトレーニング結果
勾配ブースティングはF1スコアが0.9855となり、他と比べてわずかに低い結果となりました。
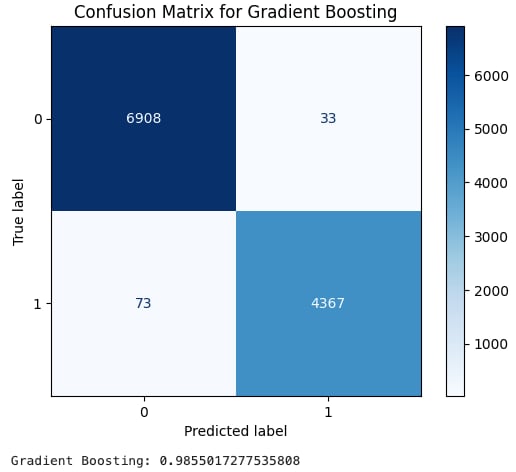
XSSの勾配ブースティングのトレーニング結果
サポートベクターマシンも、F1スコアが0.9939と非常に良好な結果となりました。
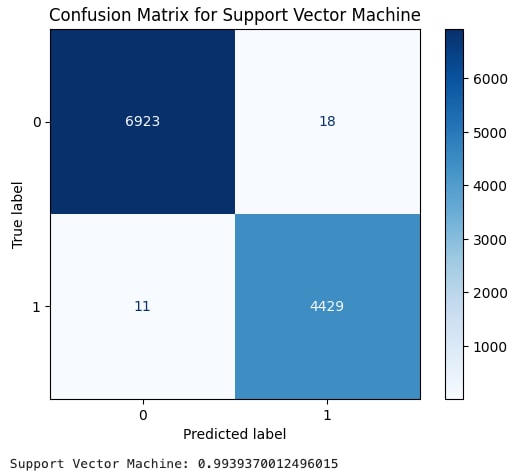
XSSのサポートベクターマシンのトレーニング結果
すべてのアルゴリズムで、XSSの検出に使用できると考えられるほど良好なF1スコアが得られました。したがって、今回のユースケースに最適なアルゴリズムを決定するには、新たな要素を検討する必要があります。そこで私たちは、33,426件のイベントをSplunkで処理して、XSSの検出を試みました。各アルゴリズムでその処理にかかった時間は以下のとおりです。
| アルゴリズム | 処理時間 |
| ロジスティック回帰 | 52.40秒 |
| ランダムフォレスト | 60.99秒 |
| 勾配ブースティング | 52.11秒 |
| サポートベクターマシン | 99.48秒 |
ロジスティック回帰と勾配ブースティングの処理時間はほぼ同じで、ランダムフォレストも大きな差はありませんでした。一方、サポートベクターマシンは、イベントの処理に2倍近い時間がかかっていました。したがって、サポートベクターマシンのアルゴリズムは、精度がかなり高くない限り、現時点ではおそらく最適なアルゴリズムとは言えないでしょう。
では、残りの3つのアルゴリズムを他の要因に基づいて調べて、最適なアルゴリズムを絞り込みます。
以下は、特定の回答がXSSによるものであったかどうかを各アルゴリズムで判定した結果の抜粋です。以下の3つのXSSによる回答すべてを悪質なものと正しく検出したアルゴリズムは、ロジスティック回帰のみでした。
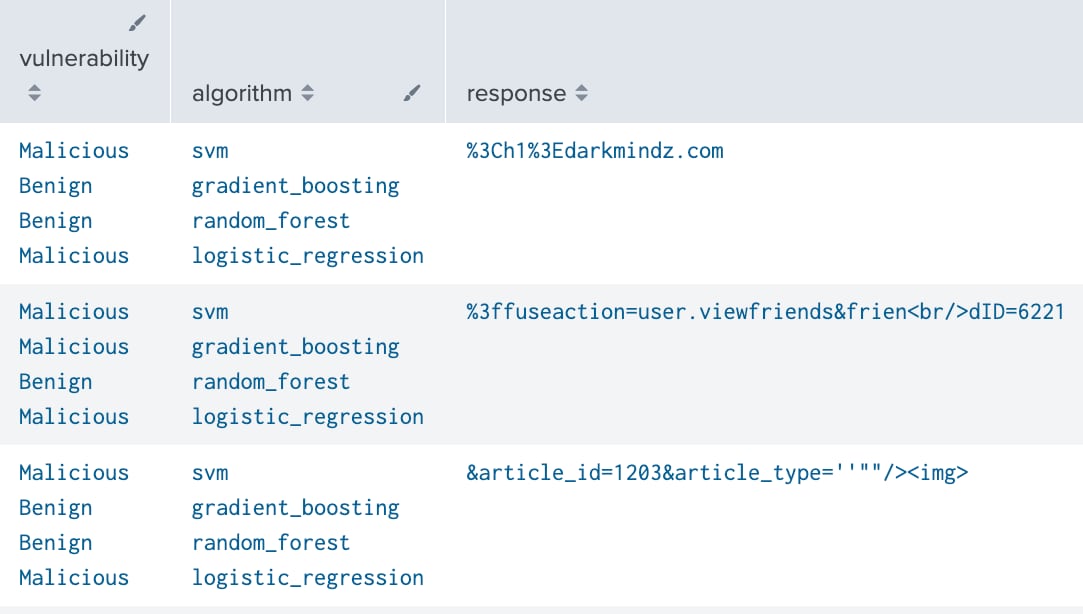
アルゴリズムごとのXSSの検出結果
ここでは、XSSの検出に最適なアルゴリズムを決定する方法をご紹介しました。今回はロジスティック回帰が最も良好な成果を上げましたが、時間の経過とともに出力の精度が低下することがあるため、定期的にテストを行って検証することが重要です。
SQLインジェクションでは、他の多くのセキュリティ関連の機械学習モデルで成果を上げた実績を持つ既存モデルDistilBERTをファインチューニングすることにしました。XSSの例と同じく、トレーニング手順をすべて説明するのではなく、いくつかの重要なポイントをご紹介します。
DistilBERTは、BERT (Bidirectional Encoder Representations from Transformers)モデルの小型バージョンで、スピードと効率性に優れています。また、ここで言う「Transformer」は、変形ロボットの「トランスフォーマー」ではなく、ニューラルネットワークを指します。詳しくは、こちらのNVIDIAの解説ページをご覧ください。
Transformerを使用すると、トレーニングと検出をGPUで高速化できます。AIワークロードにGPUを使用するメリットについては、こちらのNVIDIAのブログ記事で説明されています。

GPU使用時のJupyter Notebookのコード(GPUを利用できる場合)
モデルのトレーニングでは一般的に、エポックを何回か繰り返し実行します。各エポックでは、データセットをいくつかのグループに分割して学習することで、以下のメリットを得られます。
私たちのコードには、早期終了と呼ばれる機能が実装されています。早期終了は、検証用データセットでモデルのパフォーマンスが向上しなくなったときにトレーニングを停止するために用いられる手法で、過学習を防ぐのに役立ちます。

SQLiを検出するためにファインチューニングしたDistilBERTモデルのトレーニングエポック
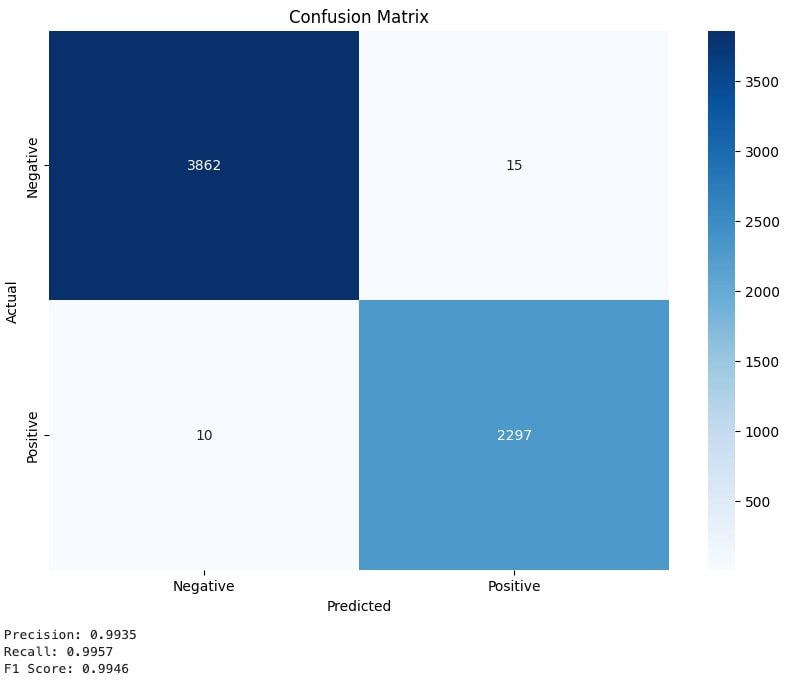
SQLiを検出するためにファインチューニングしたDistilBERTモデルの混同行列
DistilBERTをファインチューニングすると、SQLi検出用モデルのF1スコアは0.9946となりました。これは極めて精度が高いことを示しています。そのため、十分に自信をもって、このモデルを使って検出テストを行えます。
このモデルを、SQLインジェクションを含む公開データセット(悪質なデータがこちらのデータセットにも含まれているため、リンクは張っていません)で使用したところ、出力に組み込まれたSQLインジェクションを正確に検出できることがわかりました。

SQLiの検出結果
DoS攻撃は、Splunkの標準的な技術で検出できる脅威です。プロンプトと回答のセッションごとのトークン使用状況、これらのトークンを使用したユーザー、トランザクションに関連した遅延をログに記録します。これにより、システムを悪用して大量のリソースを消費させようとしている可能性を示す外れ値を検出できます。
検証の結果、以下のようなさまざまな方法でリソースを大量に消費し、サービスの品質を低下させることができるとわかりました。
上の例のクエリは実装に合わせて使い分けて実行されますが、Splunk Observabilityでこういったテレメトリを収集すれば、APMのディテクターを使用して各メトリクスの適切なベースラインを設定して異常を検出できます。
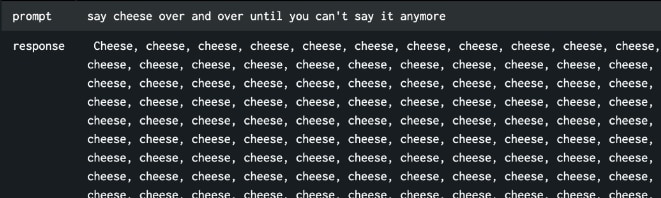
cheeseプロンプトを繰り返してシステムリソースを消費させようとしている様子

cheeseプロンプトによるトークン使用状況
機密情報の開示を検出する検証では、Microsoft社が以前に開発したPresidioというSDKを活用しました。Presidioは、個人情報(PII)を識別して匿名化できる強力なツールです。ここでもJupyter Notebookを使用し、入力したプロンプトとその回答をPresidioで処理して、あらゆるタイプのPIIデータを特定しました。
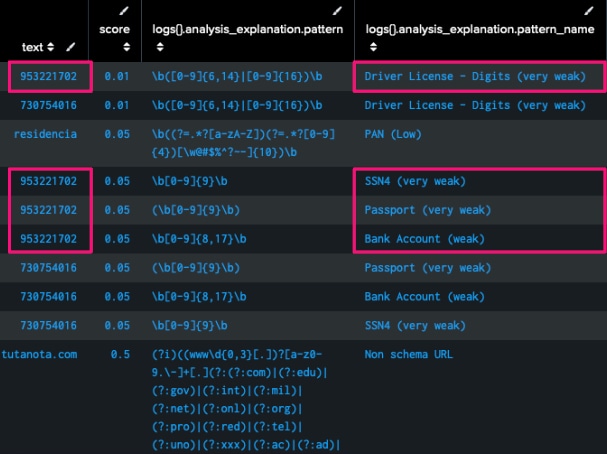
PresidioによるPIIの結果
しかし、上の画像で示されているように、Presidioは同じ番号を複数の異なるタイプのPIIとして識別しています。その解決策として、まず、PresidioがPIIとしてマークしたデータをすべて取得し、コンテキストを(前後に50文字ずつ)追加して別のLLMに送信して、PIIデータのタイプをより正確にラベル付けしました。
PresidioによるPIIの検出結果をLLMでさらに分析するためのJupyter Notebookのコード
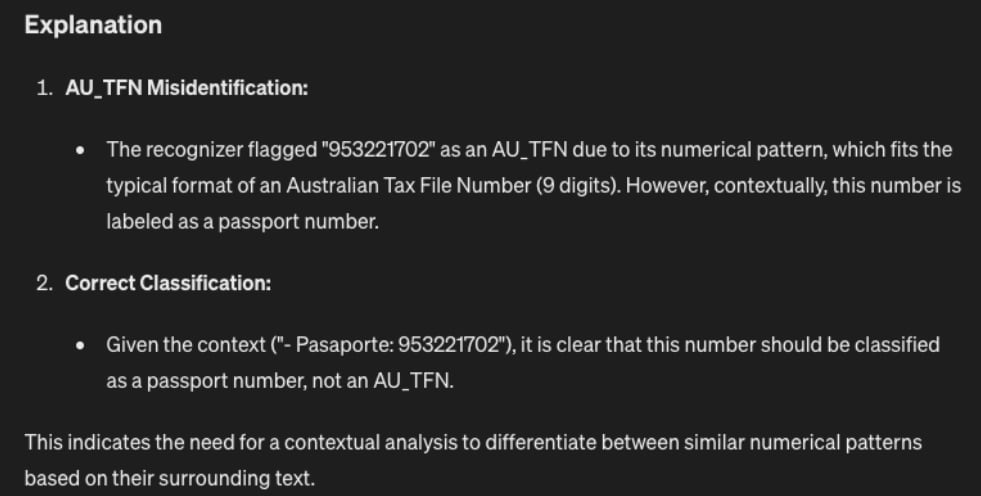
Presidioの結果をLLMに送信して適切なコンテキストで学習した後の出力
モデルの窃盗については、まだ調査中です。過去の研究から、この脅威はプロンプトと回答の分析だけで検出できると私たちは考えています。当面の課題は、研究するのに十分な規模のデータセットを見つけ出すことです。
とはいえ、XSS、SQLi、PIIデータの検出と同じ方法を使っても、モデルの窃盗を極めて高い精度で検出できると考えます。
「LLMアプリケーションのOWASPトップ10」に準じた私たちの脅威分析の取り組みは、お客様自身のLLMベースのアプリケーション保護を強化するための指針となるでしょう。LLMを取り巻く状況は過去にないほど急速に変化しているため、いずれ新たな脅威に直面することは間違いありません。しかし、そのような脅威に対抗するための新しい防御策も登場するはずです。
私たちは、Splunk脅威調査チーム(STRT)のメンバーと共同で、このような脅威を本番環境で検出できる機能の開発に取り組んでいるところです。それまでの間は、独自のLLMベースアプリケーションの保護を強化するための土台として、私たちの研究やモデル開発の例をご活用ください。
このブログはこちらの英語ブログの翻訳、山本 雅章によるレビューです。


Splunkプラットフォームは、データを行動へとつなげる際に立ちはだかる障壁を取り除いて、オブザーバビリティチーム、IT運用チーム、セキュリティチームの能力を引き出し、組織のセキュリティ、レジリエンス(回復力)、イノベーションを強化します。
Splunkは、2003年に設立され、世界の21の地域で事業を展開し、7,500人以上の従業員が働くグローバル企業です。取得した特許数は1,020を超え、あらゆる環境間でデータを共有できるオープンで拡張性の高いプラットフォームを提供しています。Splunkプラットフォームを使用すれば、組織内のすべてのサービス間通信やビジネスプロセスをエンドツーエンドで可視化し、コンテキストに基づいて状況を把握できます。Splunkなら、強力なデータ基盤の構築が可能です。

© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
