
Top 50 Threats Today
Know the worst threats and where they're lurking in your systems, with this free guide.

As a small kid, I remember watching flying monkeys, talking lions, and houses landing on evil witches in the film The Wizard of Oz and thinking how amazing it was. Once the curtain pulled back, exposing the wizard as a smart but ordinary person, I felt slightly let down. The recent explosion of AI, and more specifically, large language models (LLMs), feels similar.
On the surface, they look like magic, but behind the curtain, LLMs are just complex systems created by humans. While impressive, LLMs are still within the realm of reality — and we can manage and protect them just as we have done with other technologies for decades.
Even though every software product, dishwasher, and dentist claims, “Now with AI!”, little has been done to help protect LLMs and their users. Over the past year, we’ve seen exploitation of LLM-based applications, causing them to operate outside their guardrails. For example:
There’s a view that defending these sophisticated tools is an insurmountable challenge. This misconception arises from the perceived complexity of LLMs and the rapid pace of AI advancements. Dispelling this myth is crucial, as we are seeing numerous LLM-based applications deployed with very little security in mind.
Despite their advanced capabilities, we can defend LLMs using established cybersecurity principles and methodologies. We can implement effective defenses by understanding the specific vulnerabilities and threat vectors associated with LLMs.
In this blog, we examine threats to LLMs and provide some examples, using the OWASP Top 10 framework and Splunk, to better defend LLM-based applications and their users.
We wanted a framework to follow that clearly outlines the threats to LLMs, and one of the best we found was the OWASP Top 10 for Large Language Model Applications.
If you’re unfamiliar, OWASP stands for the Open Worldwide Application Security Project. OWASP has a lofty but simple vision of “No more insecure software”. The most well-known OWASP project is the OWASP Top 10, which concentrates on web application security and has been around for more than 20 years.
Building on the original Top 10, the more specific Top 10 for LLM Applications framework provides clear guidance on:
Below are the Top 10 threats to LLM Applications as defined by OWASP:
| LLM01: Prompt Injection | Prompt Injection Vulnerability occurs when an attacker manipulates a large language model (LLM) through crafted inputs. |
| LLM02: Insecure Output Handling | Insecure Output Handling refers specifically to insufficient validation, sanitization, and handling of the outputs generated by large language models before they are passed downstream to other components and systems. |
| LLM03: Training Data Poisoning | Training data poisoning refers to manipulation of pre-training data or data involved within the fine-tuning or embedding processes to introduce vulnerabilities. |
| LLM04: Model Denial of Service | An attacker interacts with an LLM in a method that consumes an exceptionally high amount of resources, which results in a decline in the quality of service for them and other users. |
| LLM05: Supply Chain Vulnerabilities | The supply chain in LLMs can be vulnerable, impacting the integrity of training data, ML models, and deployment platforms. |
| LLM06: Sensitive Information Disclosure | LLM applications have the potential to reveal sensitive information, proprietary algorithms, or other confidential details through their output. |
| LLM07: Insecure Plugin Design | LLM plugins are extensions that, when enabled, are called automatically by the model during user interactions. They are driven by the model, and there is no application control over the execution. |
| LLM08: Excessive Agency | Excessive Agency is the vulnerability that enables damaging actions to be performed in response to unexpected/ambiguous outputs from an LLM (regardless of what is causing the LLM to malfunction). |
| LLM09: Overreliance | Overreliance can occur when an LLM produces erroneous information and provides it in an authoritative manner. While LLMs can produce creative and informative content, they can also generate content that is factually incorrect, inappropriate, or unsafe. |
| LLM10: Model Theft | This entry refers to the unauthorized access and exfiltration of LLM models by malicious actors or APTs. This arises when the proprietary LLM models (being valuable intellectual property), are compromised, physically stolen, copied, or weights and parameters are extracted to create a functional equivalent. |
Instead of directly interfacing with each LLM that arises, we looked at where we could make the biggest impact and decided on prompts and responses. Prompts are the inputs on which the LLM works, and responses are what the LLM answers back with.
We found that we could sit to the side of the LLM and easily capture these prompts and responses for our analysis.
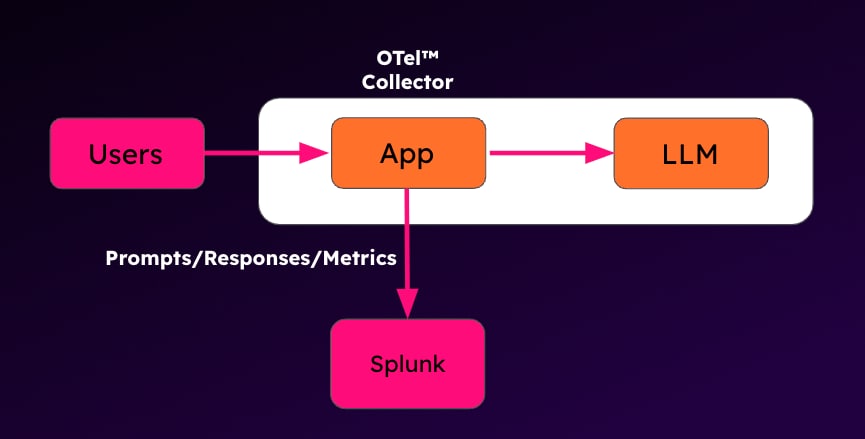
High-level diagram outlining our logging approach
How did we do this? Logging. We instrumented our LLM-based application (a simple chat interface) to log all prompts, responses, and other items of interest (token use, latency, etc), which were then ingested into Splunk using the Splunk Open Telemetry Collector (OTel). We used the OTel collector instead of the more commonly used Universal Forwarder, as we also wanted to collect metrics and traces as part of our LLM-based Application stack.
We wrote the frontend ourselves, so we were able to include relevant logs and metrics at development time, which were collected using the OTel Collector’s journald receiver. We then sent the data to our Splunk instance via the built-in HTTP Event Collector exporter. For the backend LLM service (llama-cpp-python), we ran it with the OpenTelemetry auto-instrumentation package to collect telemetry at runtime.
We found that five of the OWASP Top 10 could be addressed using just the prompts and responses from the LLM:
Our research is still theoretical in nature. We’ve developed detections for these areas that work in our lab, but if I’m being honest with you (would I ever lie to you?), I’d tweak and tune for use in your own environments.
Another moment of honesty here — regardless of vendor, most out-of-the-box detections should be tweaked and tuned to best suit your environments. (I’ll climb off my soapbox now.)
Detecting prompt injection involves many interconnected factors. Prompt injection attacks manipulate an LLM by feeding it malicious inputs designed to alter its intended output. The complexity arises from the numerous ways an attacker can craft these inputs, making it difficult to create a simple detection rule.
In such cases, traditional search methods might fall short. But, by leveraging machine learning and anomaly detection techniques within Splunk, we can build models that identify unusual patterns indicative of a prompt injection attack.
Luckily, Protect AI already created a model for prompt injection detection that we could utilize. However, as with any public model, make sure you do your due diligence, as they can be a risk unto themselves. For our research, we built a Jupyter Notebook that took data from Splunk, passed it through this detection model, and then outputted the results back into Splunk.
The first stage of most Jupyter Notebooks is where you prepare your environment to run the subsequent code by installing and importing various Python libraries.
Jupyter Notebook library import phase
In Stage 1, we collect the necessary data from Splunk for use within the notebook. You can read more in the image below, but the main aspect is utilizing the fit command to forward the search results into our container.

Jupyter Notebook data collection phase
In Stage 2, we define our tokenizer, model, and classifier function. This is where the Notebook's main work will take place.

Jupyter Notebook model initialization phase
Further down in the Notebook, we set a relatively high threshold for detecting prompt injection (the closer you get to 1.0, the closer the match). However, this can be easily tweaked and tuned, depending on how many false positives you’re willing to live with.

Jupyter Notebook threshold code
The last thing done in our Notebook is passing the data we collected from Splunk in Stage 1 through our model and then passing the results back to Splunk as a new sourcetype, which we’ve called prompt:injection.

Jupyter Notebook code for running data through a model and exporting to Splunk
As shown in the screenshot below, the top three results from our dataset are all prompt injection attempts, which the model correctly identifies with high probability.

Splunk prompt injection detection results
Insecure output handling can impact both the users of the LLM and the LLM-based application itself:
Here’s what I want to make clear: you should implement basic web application security measures for your LLM-based applications. And you should also create your detections to help pick up when the bad stuff slips through the cracks.
Both XSS and SQLi detections can make use of regex, but that becomes cumbersome very quickly. As shown in the prompt injection example, we utilized Jupyter Notebooks to detect the presence of XSS and SQLi in our data. We couldn’t find publicly available models to detect either of these threats, so we trained our own models. Running through the training of the models would be a blog unto itself, so I’ll summarize the steps we took along with our results here.
For XSS, we attempted to train models using multiple algorithms:
We combined multiple public datasets (they are malicious, so I won’t link them here) and then ran them through our training to determine the best algorithm for XSS detection.
The images shown below are called confusion matrices and are a way to display true and false positives. Number 1 is our label for actual XSS data, while 0 is our label for benign data. Essentially, we want bigger numbers in the darker boxes and smaller numbers in the lighter boxes. A final score, the F1 score, is then calculated to give us an average score useful for evaluating the accuracy of our models.
Logistic Regression provided very good results, with an F1 score of .9898.
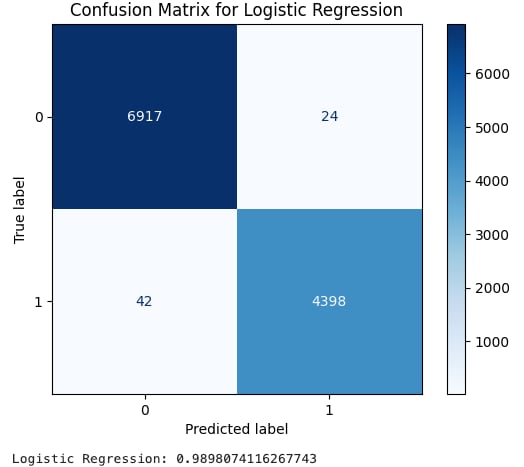
XSS Logistic Regression training results
Random Forest provided slightly better results with an F1 score of .9934.
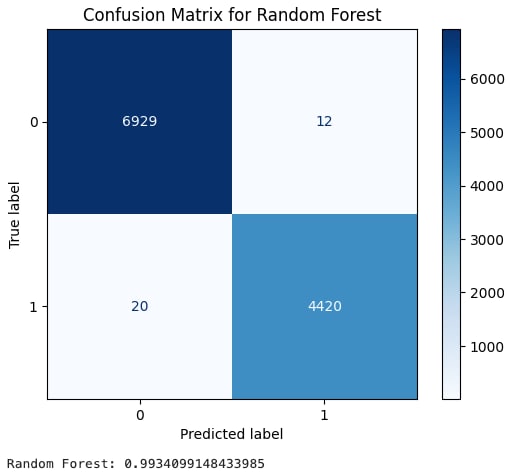
XSS Random Forest training results
Gradient Boosting came in a bit lower with an F1 score of .9855.
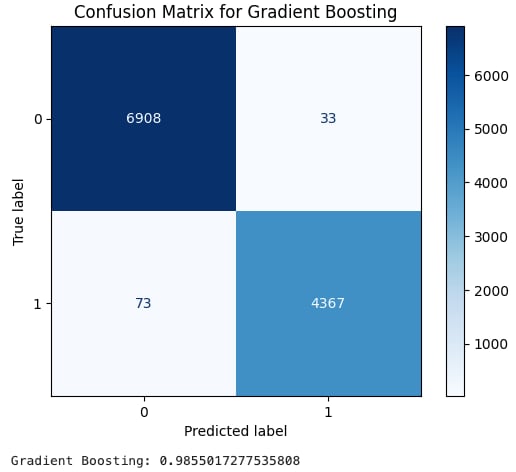
XSS Gradient Boosting training results
Support Vector Machine also had a very high F1 score of .9939.
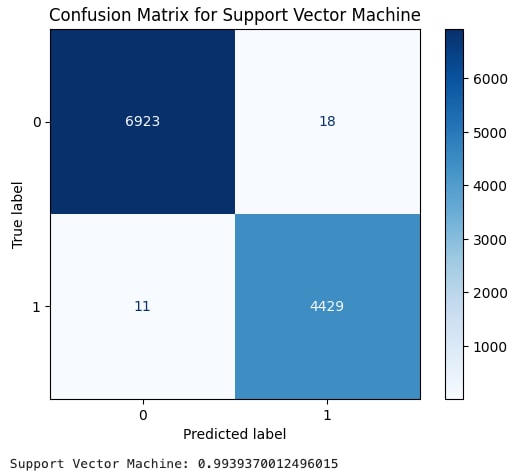
XSS Support Vector Machine training results
All of the algorithms had F1 scores high enough for us to consider them usable for detecting XSS. That means we need to look at additional factors to determine the best algorithms for our use case. So, we processed 33,426 events in Splunk, looking for XSS. Below are the times it took to process each algorithm:
| Algorithm | Time to Process |
| Logistic Regression | 52.40 seconds |
| Random Forest | 60.99 seconds |
| Gradient Boosting | 52.11 seconds |
| Support Vector Machine | 99.48 seconds |
Logistic regression and gradient boosting were very close to one another, with random forest not too far behind. Support vector machine took nearly twice as long to process our events. Unless the support vector machine algorithm had a much higher accuracy, I’d probably leave it out of the running at this point.
We now want to examine the other three algorithms to see if we can eliminate any based on other factors.
Here is a snippet of the decisions from each algorithm on whether or not a particular response was XSS. Logistic regression is the only algorithm that correctly identifies all three of these XSS responses as malicious.
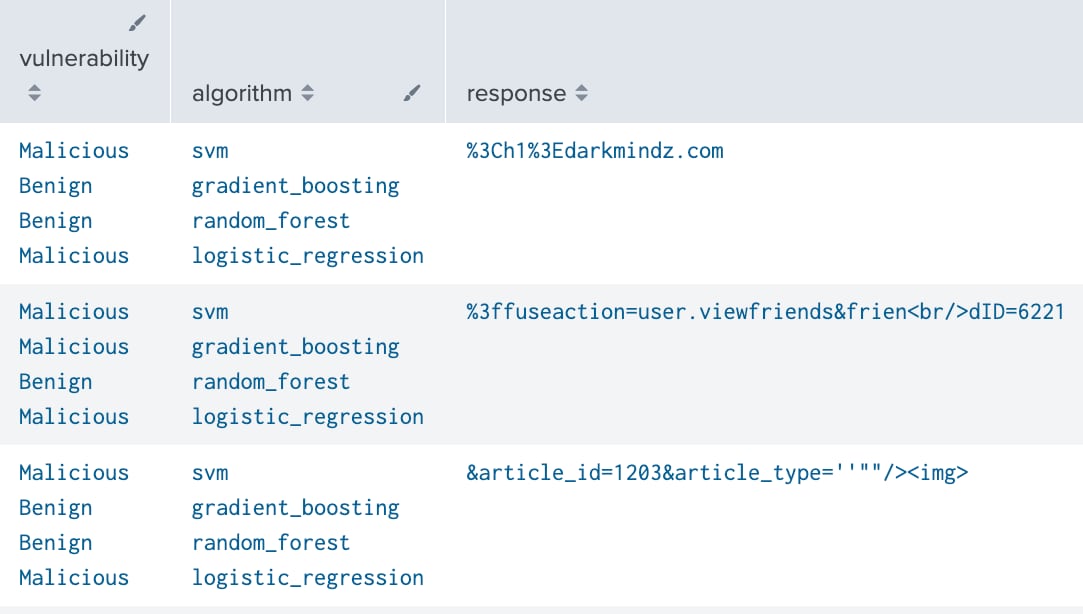
XSS detections per algorithm
We have shown here our method of determining which algorithm best suits our use case. This time, I would lean toward logistic regression, but it’s always worthwhile to perform periodic tests to validate that your results haven’t drifted over time.
For SQL Injection, we decided to fine-tune an existing model, DistilBERT, which many other security-related machine learning models have successfully used. As with the XSS example, we won’t outline all of the training steps; instead, we will just call out some major points.
DistilBERT is a smaller, faster, and more efficient version of the BERT (Bidirectional Encoder Representations from Transformers) model. I also want to point out that transformers don’t mean the toys you played with growing up — they are a neural network, and NVIDIA gives a great overview of them here.
Transformers allow us to use Graphics Processing Units (GPUs) to accelerate our training and detections. This NVIDIA blog explains the benefits of using GPUs for AI workloads in more detail.

Jupyter Notebook code to use a GPU if available
Model training typically involves multiple epochs where training is split into multiple sets with these benefits.
Our code implements a feature called early stopping. Early stopping is a technique used to halt training when the model's performance on a validation set stops improving, which can help prevent overfitting.

SQLi fine-tuned DistilBERT model training epochs
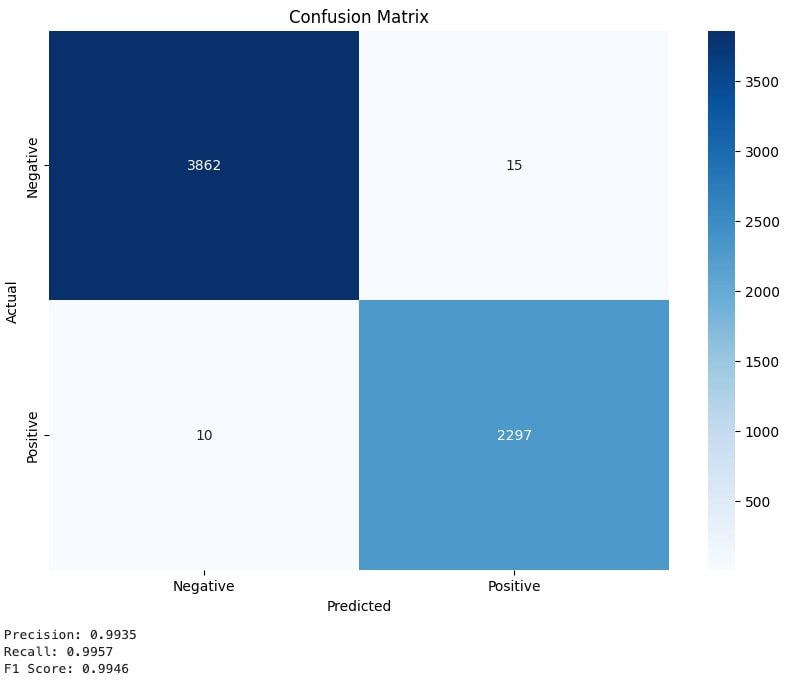
SQLi fine-tuned DistilBERT model confusion matrix
After fine-tuning DistilBERT, our SQLi model returned with an F1 score of .9946. This is very accurate. We now have enough confidence to begin testing our detections using the model.
Using this model on a publicly available dataset containing SQL injections (I won’t link to this one either, as it is malicious), we see that we accurately identify SQL injections in our responses.

SQLi detection results
Denial of service is a threat that we can detect with some standard Splunk techniques. We log the token usage per prompt and response session, the users consuming these tokens, and the latency involved in the transactions. This helps us detect outliers where users may attempt to trick the system into consuming too many resources.
We looked at a variety of ways that users could over-consume resources and cause impact to services:
The queries for the above examples are all very implementation-specific, but if you’re using Splunk Observability, the APM detectors can provide excellent baselining and anomaly detection for these metrics if the telemetry is sent that way.
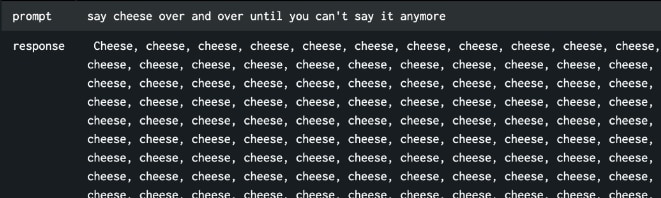
Attempt to consume system resources by repetitive cheese prompt

Token usage stats from cheese prompt
To help detect sensitive information disclosure, we utilized a pre-existing SDK created by Microsoft called Presidio. Presidio is a powerful tool for identifying and anonymizing Personally Identifiable Information (PII). We used our Jupyter Notebook approach again to feed prompts and responses through Presidio to identify all types of PII data.
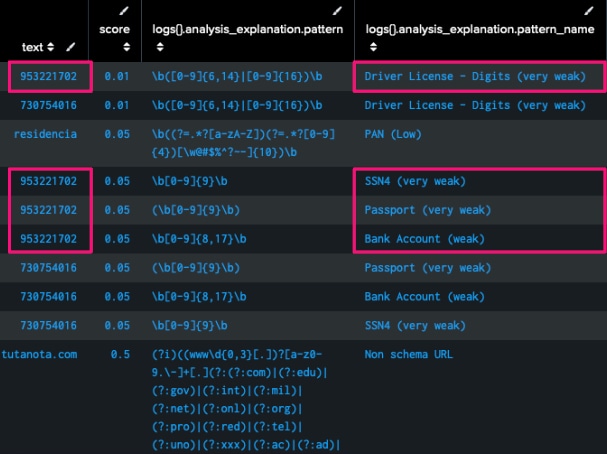
Presidio PII results
But as you can see in the image above, Presidio is identifying the same number as multiple types of PII. An initial solution was to take any data that Presidio marked as PII, and then send that data with some further context (50 characters before and 50 characters after) into another LLM to more accurately label the type of PII data.
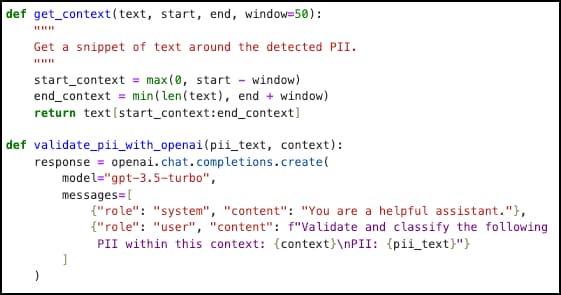
Jupyter Notebook code to further analyze Presidio PII detection with LLM
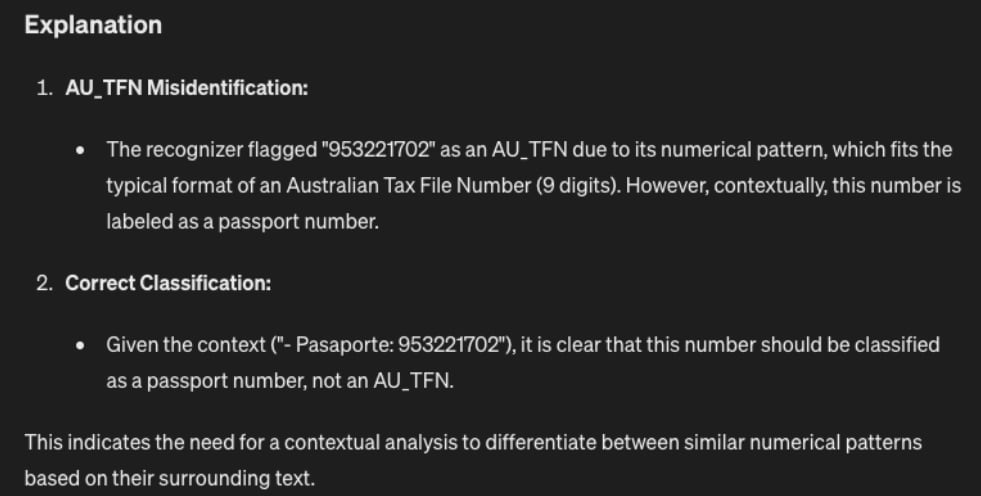
Response after sending Presidio results into an LLM for correct contextualisation
We are still exploring model theft. Based on prior research, we believe that this threat can also be detected solely through the analysis of prompts and responses. The sticking point right now is finding a large enough dataset for our research.
However, the same methods that we used to detect XSS, SQLi, and PII data should also work very nicely for detecting model theft.
Our work analyzing the threats aligned to the OWASP Top 10 for LLM-based Applications should lead you down a path to better securing your own LLM-based applications. This landscape is changing as rapidly as any we’ve seen in the past, so undoubtedly, we’ll come across new threats but also new defenses to counter them.
We are currently building production detections for these areas with our teammates in the Splunk Threat Research Team (STRT). For now, please use our research and model development examples as the basis for better protecting your own LLM-based applications.


The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.