
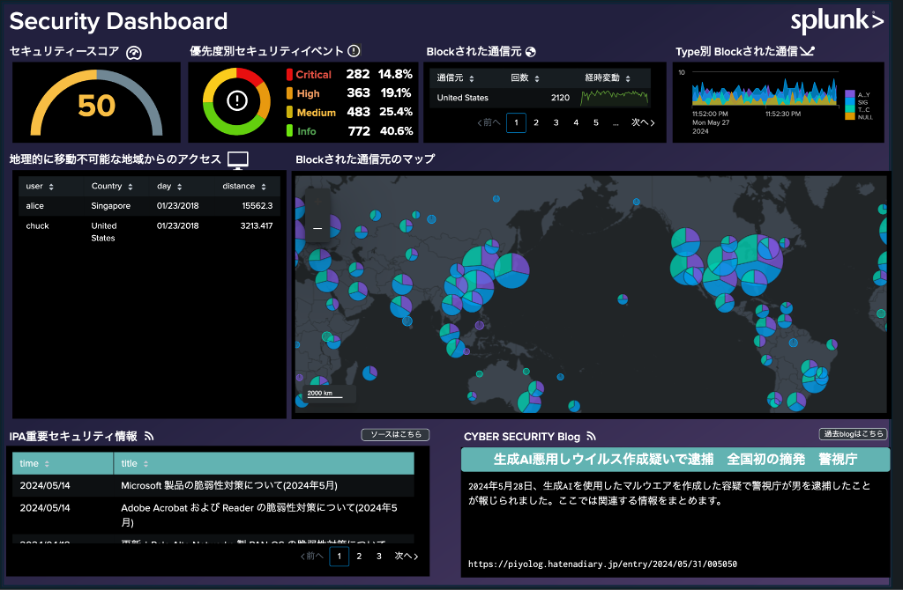
2025年のセキュリティの現状
強力でスマートな未来志向のSOCを構築
脅威の検出と対応に、生成AI、DaC (コードによる検出)、統合プラットフォームのアプローチを取り入れて、SOCの変革を推進している組織の取り組みをご紹介します。
本記事では、「Splunkでセキュリティダッシュボードを作成しよう!」シリーズにおける第3回として、ダッシュボードのソースであるデータの取り込み手順について紹介します。
第1回:全体概要(ゴールと内容の説明)
第2回:データの取り込み(その1)
第3回:データの取り込み(その2) ←今ここ
第4回:フィールド抽出と正規化
第5回:SPLの書き方(その1)
第6回:SPLの書き方(その2)
第7回:SPLの書き方(その3)
第8回:Dashboard Studioでダッシュボードを作成(その1)
第9回:Dashboard Studioでダッシュボードを作成(その2)
第10回:Dashboard Studioでダッシュボードを作成(その3)
前回までに、データを取り込むためのApp/Add-onとしては以下が必要だということがわかりました。まずはこれらをインストールします。
Splunkにログインした後、画面左上の「App」より、「Appの管理」を選択します。
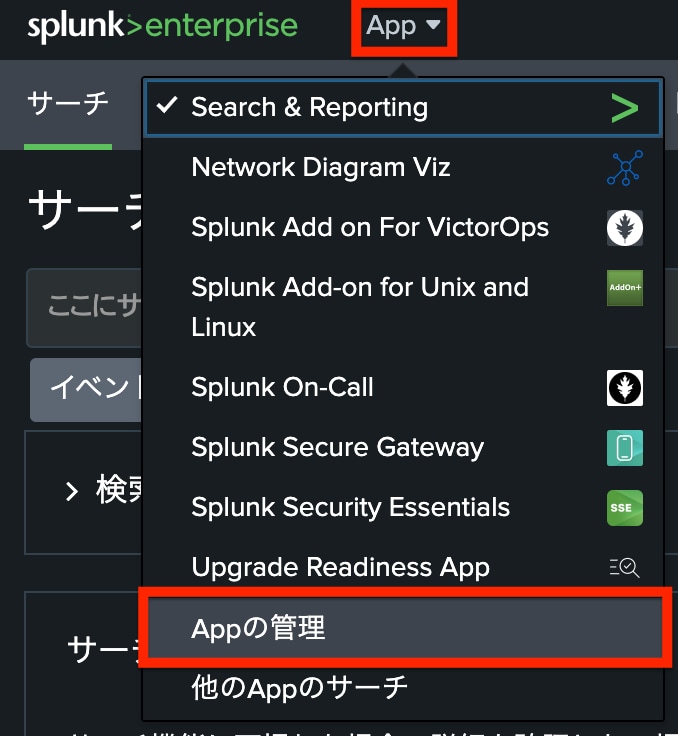
「App」画面では、画面右上の「他のAppを参照」を選択します。

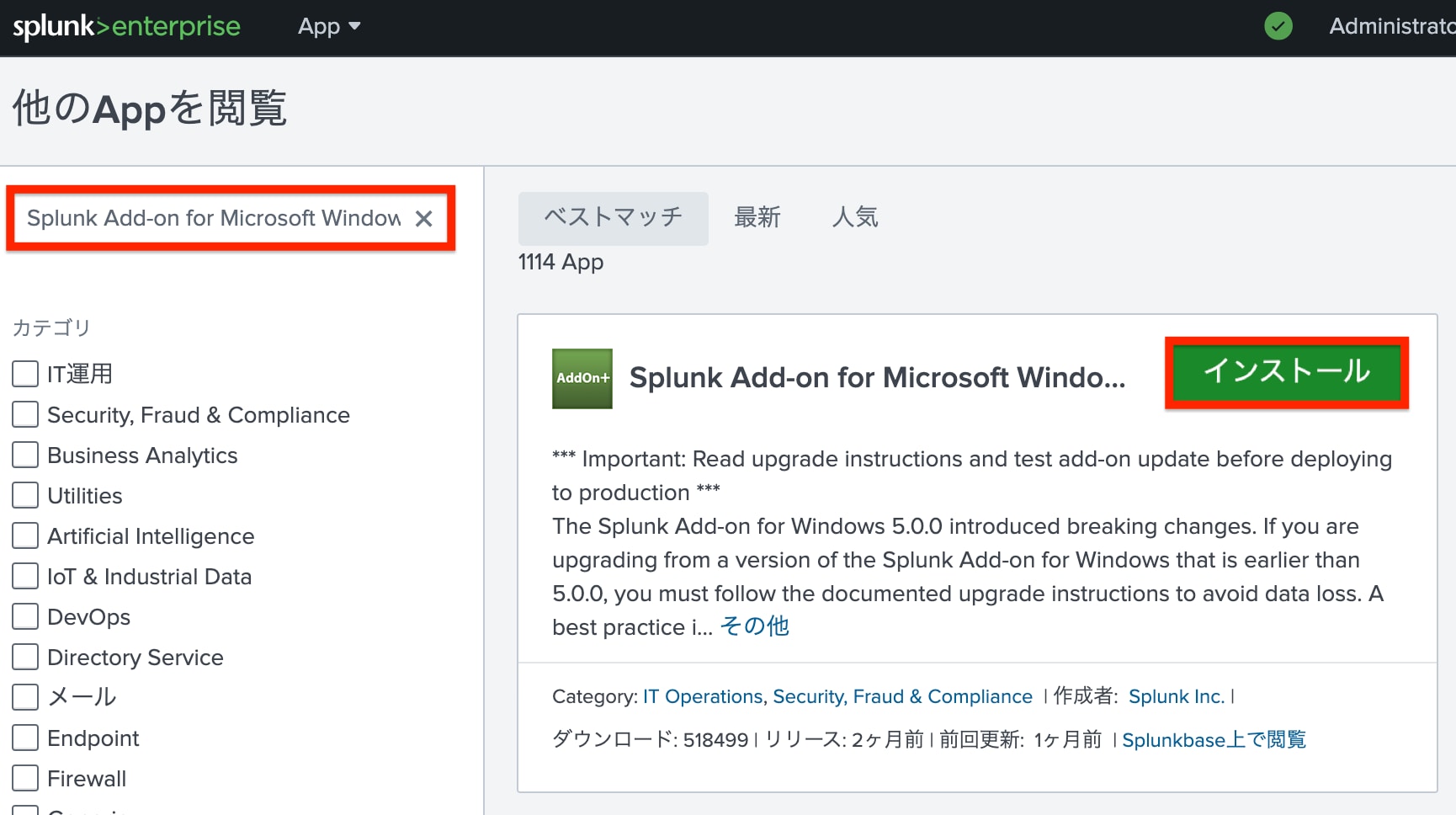
「他のAppを閲覧」画面にて、検索バーにAdd-on名を入力して検索し、「インストール」を選択します。
Add-onをインストールするために、Splunkアカウントとパスワードを入力して、「インストール」を選択すればAppがインストールされます。
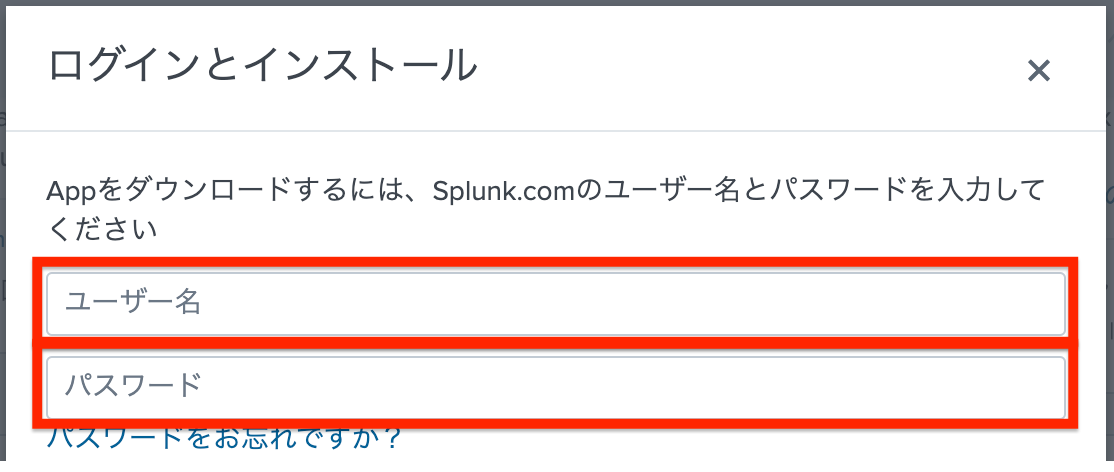
以上を3つのAdd-onに対して繰り返します。インストール後、Splunkを再起動してください。
画面上の「設定」より「サーバーコントロール」を選択すると、ログインしているSplunkサーバーの再起動を選択することができます。(再起動中は、ログインやスケジュールドサーチの実行などができなくなりますので、業務に影響がないことを確認してから作業してください)
次に、ログデータの取り込みを行います。今回は、サンプルログを使用して取り込みを行うことにします。以下のGitHub上にサンプルログを保管していますので、実際に実機を触って試してみたい方は、サンプルログをダウンロードして使ってください。
もしご自身の環境でAzureのsigninログや、Juniperのアラートログが用意できるのであればそちらを使っていただいても構いません。
本記事では、簡易化のためにサンプルログを使うこととし、またこれらログをSplunkにファイルアップロードしてダッシュボードを作成することにします。上記のサンプルログが保管されているGitHubから、「tenantdomains.txt」と「juniper.txt」をダウンロードしてローカルPCに保管してください。
その後、Splunk Webにログインし、「設定」から「データの追加」を選択します。
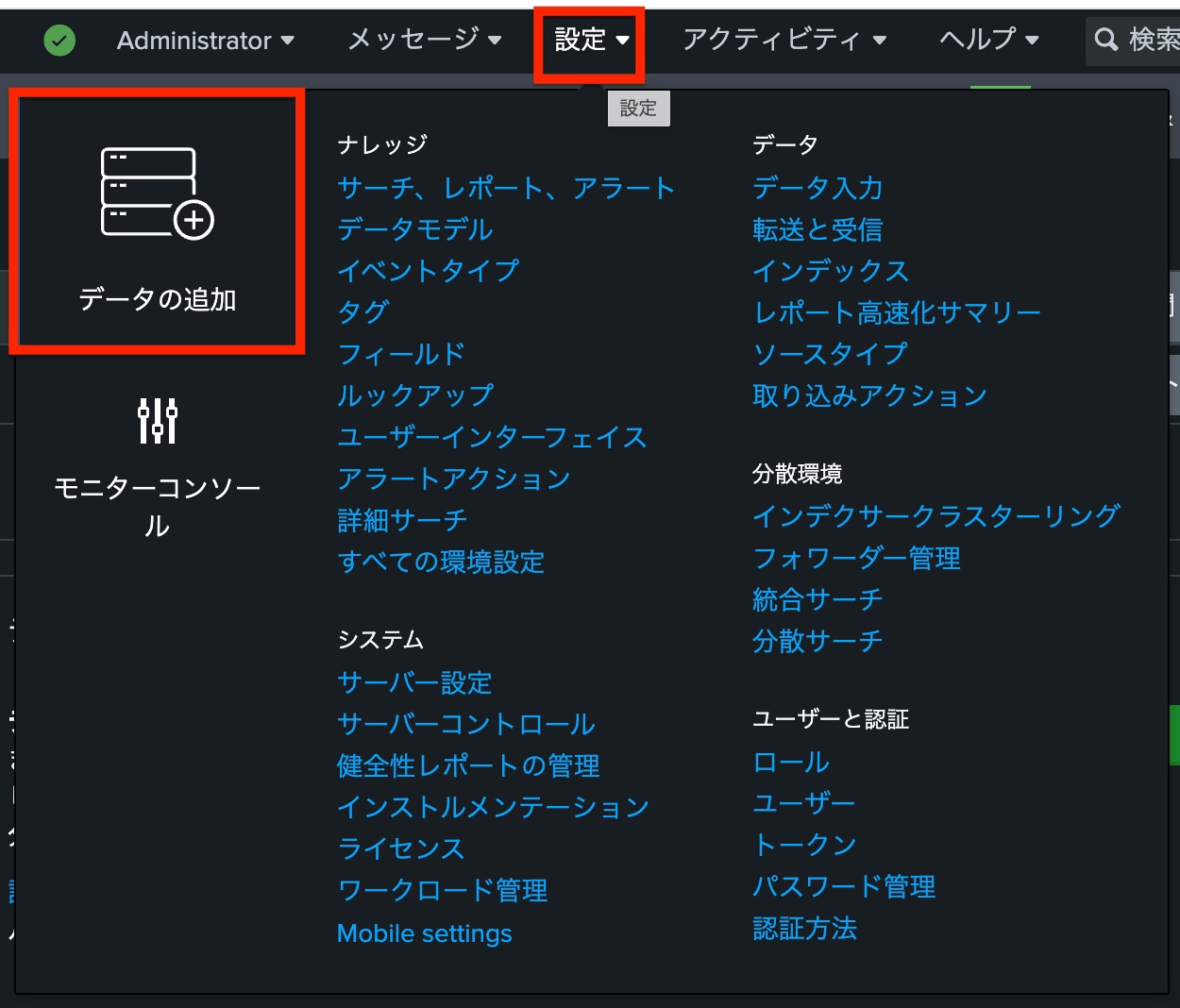
「データの選択」画面で「アップロード」を選択します。
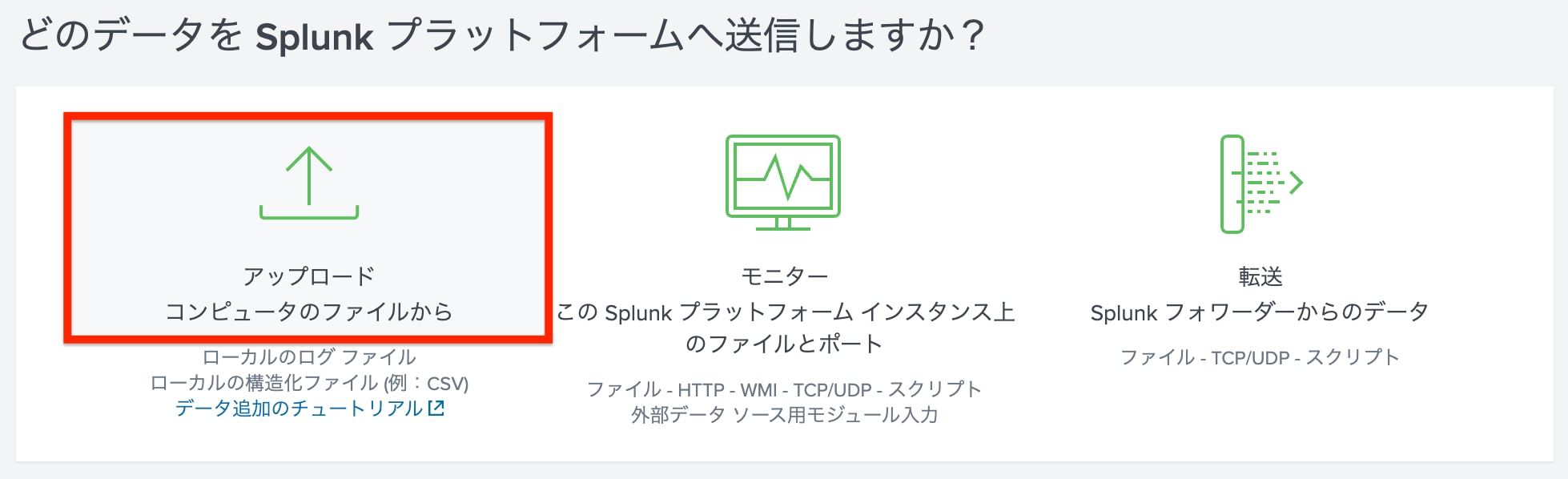
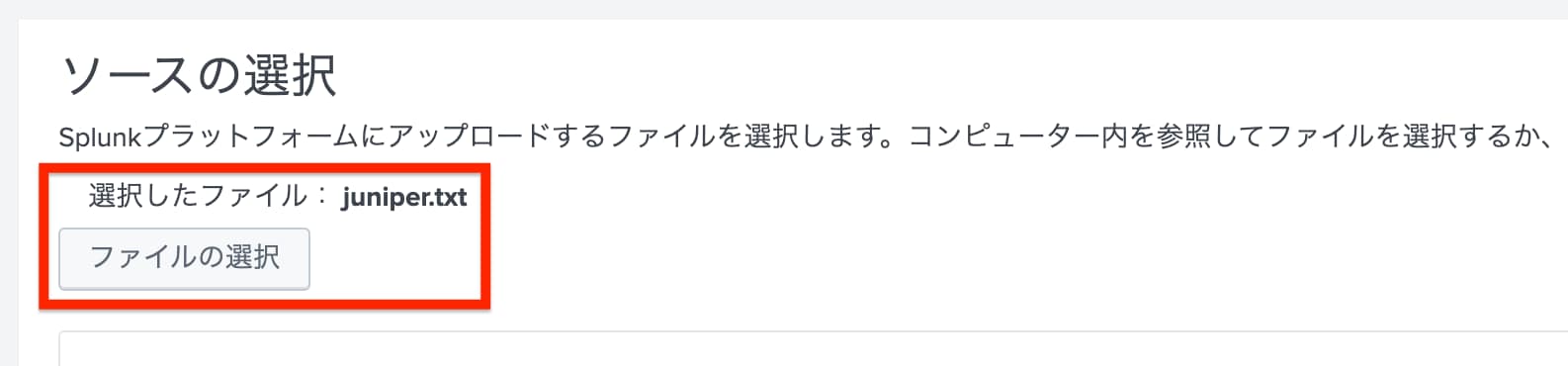
「ソースの追加」画面では、「ファイルの選択」を選択して、先ほどローカルPCに保存したサンプルログファイルを選択し、「次へ」を選択します。
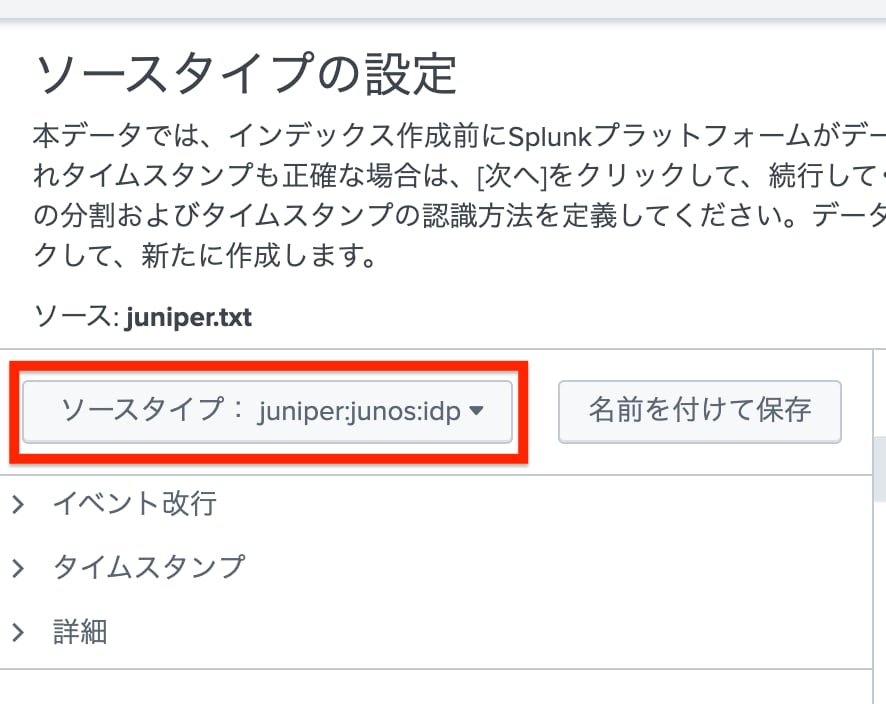
「ソースタイプの設定」画面では、ソースタイプを指定します。ソースタイプとは、簡単にいえば、Splunkにおけるログのフォーマットのことを指します。Splunkは、デフォルトでいくつかのソースタイプを定義していますが、Add-onを導入することによってより広い範囲のログフォーマットに対応できるようになります。このために、前回Add-onを導入していたというわけです。
「tenantdomains.txt」に対しては「ms:add:signin」をソースタイプとして指定します。「juniper.txt」に対しては「juniper:junos:idp」をソースタイプとして指定します。ソースタイプを指定できたら「次へ」を選択します。
次の「入力」設定画面では、特に何も指定せず、「次へ」を選択します。
「確認」画面にて、ファイル名とソースタイプが指定した値となっていることを確認したら「実行」を選択するとアップロードが開始されます。
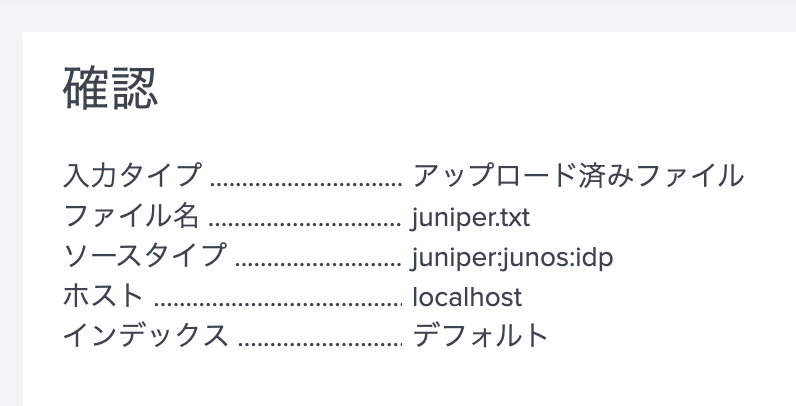
以上を2つのファイルに対して繰り返します。
RSSについては、実際にIPAおよびpiyologの情報を取得して表示させるようにします。
最後に、RSSの取り込み設定を行います。「設定」から「データの追加」を選択します。
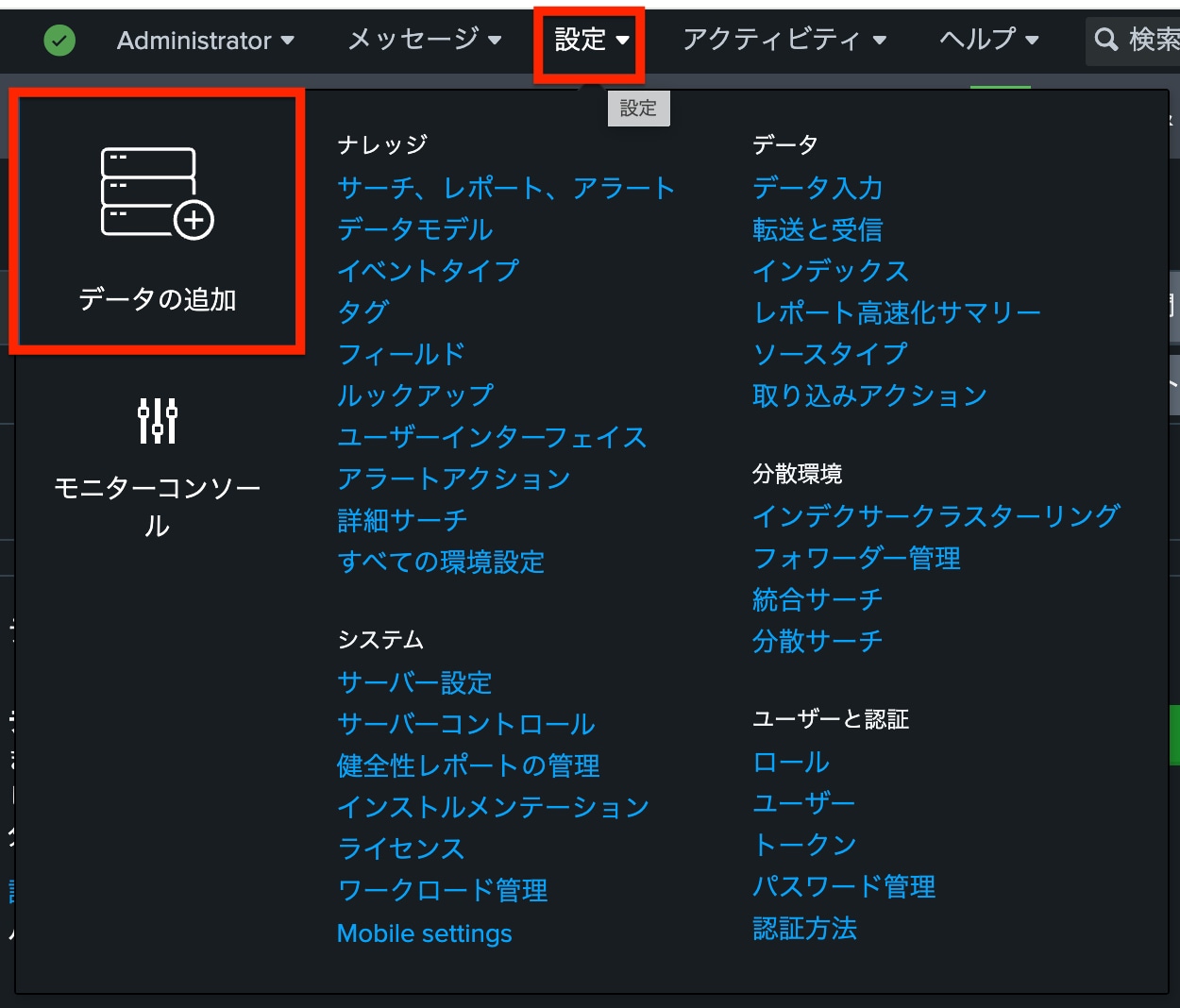
「データの選択」画面で「モニター」を選択します。

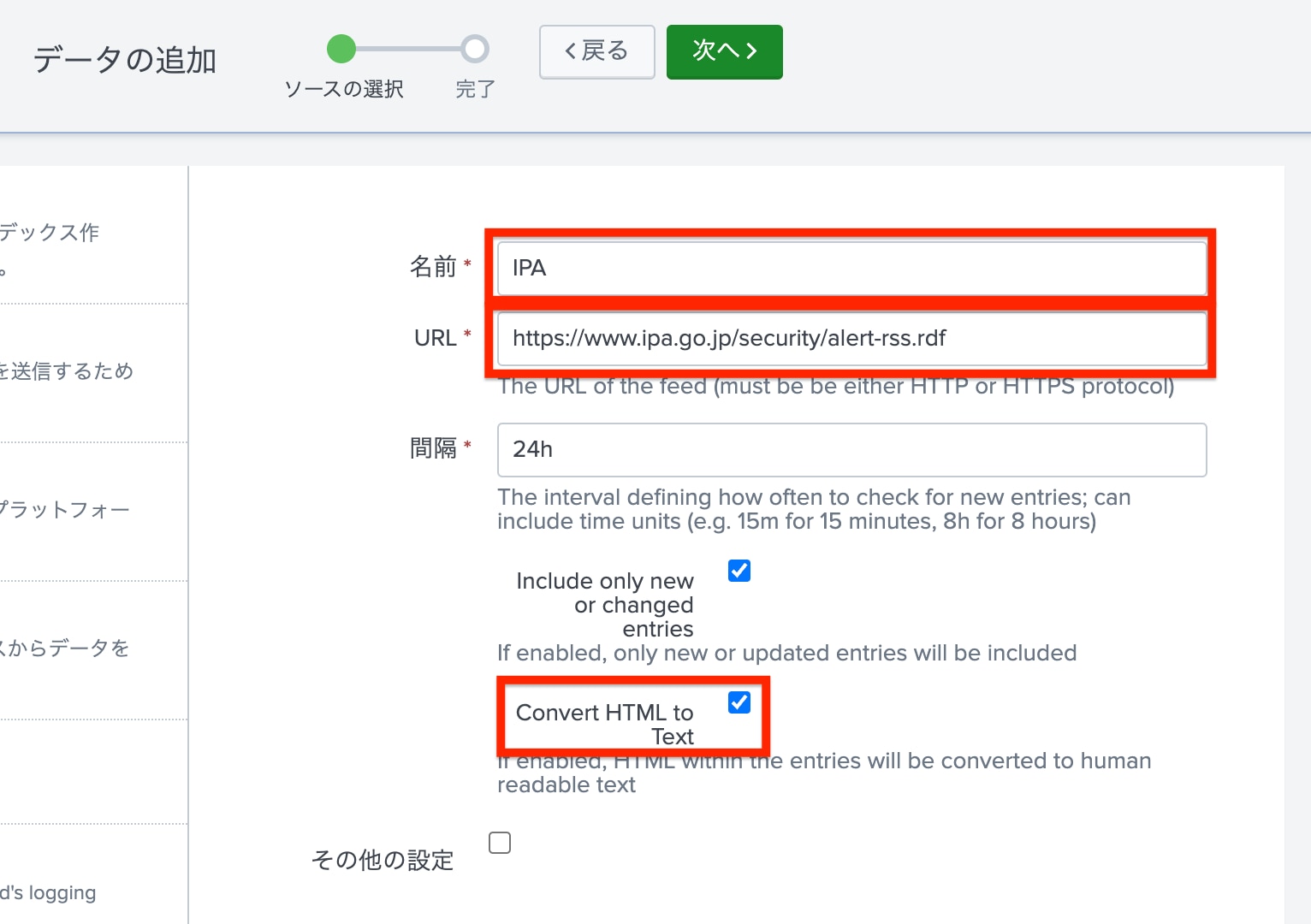
「データの追加」画面では、画面左下より、「Syndication Feed (RSS, ATOM, RDF)」を選択した後、右上にRSSの名前とURLを入力し、Convert HTML to Textにチェックを入れます。それ以外の項目はデフォルト設定のままです。
IPAの場合の指定項目:
| 名前 | URL |
|---|---|
| IPA | https://www.ipa.go.jp/security/alert-rss.rdf |
| Convert HTML to Text | チェックを入れる |
piyologの場合の指定項目:
| 名前 | URL |
|---|---|
| piyolog | https://piyolog.hatenadiary.jp/rss |
| Convert HTML to Text | チェックを入れる |
入力が完了したら「次へ」を選択すると設定が完了します。
以上を2つのURLに対して繰り返します。以上でAppのインストール、データの取り込みが完了しました。
今回はデータの取り込みのための作業手順の紹介が主となりました。次回は、これらデータがSplunk内部でどのように扱われているのか、フィールド抽出の仕組みや、正規化のためのCIM(Common Information Model)について説明していきたいと思います。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
