
オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。

動的しきい値とは、コンピューターサイエンス、具体的にはIT Service Intelligence (ITSI)で使用される用語であり、IT環境の履歴データを分析してKPI (主要業績評価指標)を判断するための値です。特に、KPIの異常値を管理し、より有意義で信頼できるパフォーマンス監視アラートを生成するために使用されます。
しきい値は、ITインフラが生成するデータに対して許容できる上限値と下限値を指定するもので、パフォーマンス監視に不可欠な要素です。ITSIでは、静的しきい値と動的しきい値の2種類を使用できます。静的しきい値を使用する場合は、ポリシーを使用して、1日または1週間のさまざまな時間のKPIに対して静的な値を設定します。一方、動的しきい値では、機械学習を使用してKPIの時間依存しきい値を動的に計算します。これにより、アラートと予想されるワークロードを時間単位でより厳密に一致させることができます。
Splunk IT Service Intelligence (ITSI)は、顧客に影響が及ぶ前にインシデントを予測して対応するための、AIOps、分析、IT管理ソリューションです。

AIと機械学習を活用して、監視対象のさまざまなソースから収集したデータを相関付け、関連するITサービスやビジネスサービスの状況を1つの画面にリアルタイムで表示します。これにより、アラートのノイズを低減し、障害を未然に防ぐことができます。
動的しきい値を使用すると、実行または停止の2値化ではなく、正常から異常へのグラデーションでサービスの状態を表示できます。たとえば、サービスが重大なしきい値に達した場合はアラートが必要ですが、しきい値が高ければ、状態が気になるとしてもアラートはおそらく必要ないでしょう。このように差異を識別できるようになることで、過剰なアラートを削減し、最も重要な問題に取り組むことができるようになります。
以下のセクションでは、動的しきい値の仕組み、使用方法、動的しきい値のさまざまな手法に加え、動的しきい値が組織のパフォーマンス監視戦略において重要である理由について説明します。
ITSI (Information Technology Service Intelligence)は、機械学習を活用して複雑なIT環境を監視し、IT運用を分析主導で管理できるようにするためのソフトウェアソリューションです。
ITSIを使用すると、ネットワークイベントを監視および分析し、サービスの中断を予測して防止することができます。これにはAIアルゴリズムが使用されており、事前に修正しなければサービスの低下やダウンタイムを引き起こす可能性があるネットワークアクティビティのパターンや傾向を特定します。また、アラートに基づいて、サービスの中断や停止を防ぐための是正措置を講じることができます。
一般的にITSIツールでは次の4段階のプロセスを採用しています。
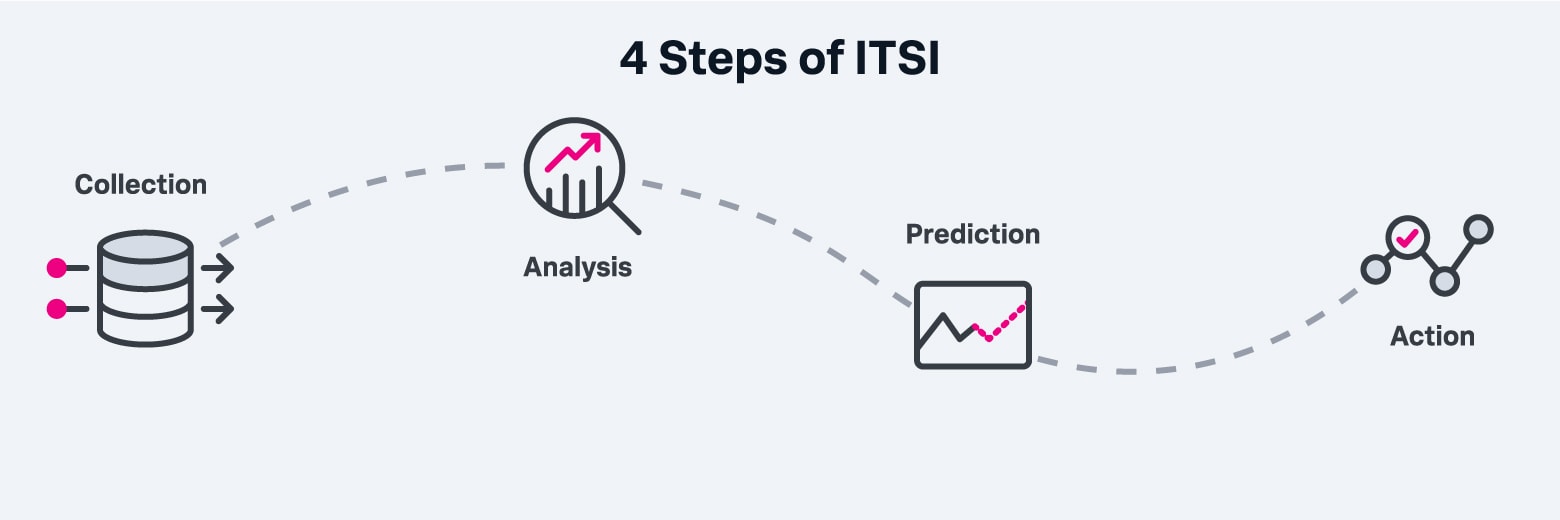
ITSIツールは、収集、分析、予測、対応の4段階のプロセスを採用しています。
KPI (Key Performance Indicator、主要業績評価指標)とは、ネットワークとそのコンポーネントのパフォーマンスを測定するためのベンチマークです。メトリクスとは異なり、KPIが結果を定義するのに対し、メトリクスはその結果に向けた進捗を測定するために組み合わせて使用されるデータポイントです。たとえば「信頼性」は、サービスが特定の期間内に必要な機能を実行する確率を表す一般的なKPIです。これは、2つの重要な障害メトリクスである、平均修復時間(MTTR)と平均故障間隔(MTBF)を使用して計算されます。
企業のKPIとして何を監視すべきかについての共通の基準はありませんが、サービスの全体的な状態を評価するために一般的に使用されるKPIには次のものがあります。
ITSIでは、KPIをCPUの負荷状況、メモリー使用率、応答時間などのITパフォーマンス指標値を返すサーチとして保存します。各KPIを特定のサービスと関連付けることで、KPIのサーチ結果に基づいて、サービスの健全性を監視したり、ITコンポーネントのステータスをチェックしたり、ITシステムの潜在的な問題を示す傾向を把握して解決したりできます。
さらに、KPIを組み合わせて使用することで、IT環境の全体的な健全性やパフォーマンスを判断することができ、ひいてはさまざまな目標や目的の進捗を測定できます。具体的には、KPIは次のことに役立ちます。
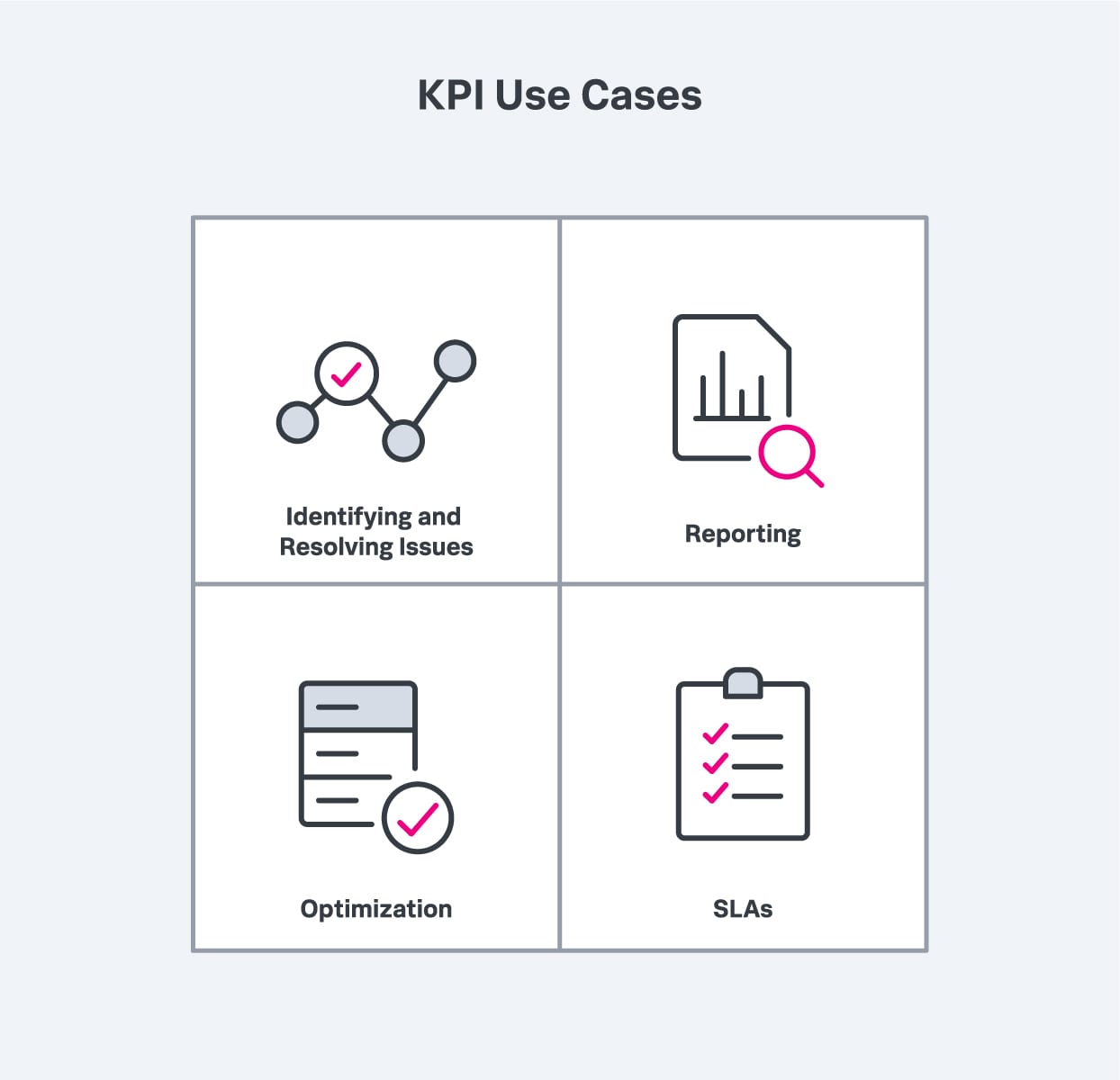
KPIを使用すれば、問題の特定と解決、パフォーマンスの傾向に関するレポートの作成、パフォーマンスの向上を実現できるだけでなく、SLAのパフォーマンス基準が満たされていることを確認できます。
動的しきい値は、機械学習を使用して履歴データ(ヒストグラムで表示されることもある)を分析し、環境の正常な状態を定義するのに役立つパターンを見つけます。さまざまなしきい値(強度値)を設定し、特定のKPIの現在の状態を判断して、より精度の高いアラートを生成します。グローバルしきい値の最も単純な形式はバイナリしきい値(thresh_binary)で、これは二者択一の結果になりますが、ほとんどのしきい値はグレースケールです。
このプロセスがどのように機能するかをより詳しく理解するためには、サービス健全性スコア、KPI、および依存サービス(サブサービスとも呼ばれる)など、いくつかのITSIの概念を理解する必要があります。
これらの概念は、階層型として設計されています。環境内の各サービスは、そのサービスに対して定義されたKPIとサブサービスの状態に基づいて計算された健全性スコア(adaptive_thresh_mean_c)を受け取ります。すべてのKPIにはしきい値の設定が必要であり、KPIの状態と健全性スコアを継続的に監視するITSIでは、6種類の重大度(正常、致命的、高、中、低、情報/通知)を設定できます。あるサービスのKPIの重大度が、そのサービスの健全性スコアの変化と連動して規定のレベルに達した場合、潜在的な問題を示すためにアラートがトリガーされます。
しきい値とアラートを設定する場合は、しきい値をシンプルにしておくことをおすすめします。以下に、ベストプラクティスをいくつかご紹介します。
このような場合は、すべてのKPI結果に「情報」の重大度を選択することができます(サービスの健全性スコアに影響を与えません)。
動的しきい値は、ITSIで重大度レベルのしきい値を設定するために使用され、これによって特定のKPIの現在の状態が判断されます。KPIの値が、しきい値の条件を満たすか超過すると、KPIの状態が変化します。たとえば「高」から「致命的」になると、サービスに問題が発生している可能性があります。KPIのしきい値をサービスの健全性スコアなどの他の設定と一緒に使用すればより関連性の高いアラートを提供することができ、ITチームがパフォーマンスの問題をプロアクティブにトラブルシューティングして解決できるようになります。
動的しきい値は、クラウドIT環境の監視における課題を解決するために重要です。クラウドサービスプロバイダーにより、インフラの基盤となるハードウェアが抽象化されているため、利用者のITチームがパフォーマンスの問題の根本原因を特定するのは至難の業です。そのため、最新のパフォーマンス監視ツールは、機械学習を利用してテラバイト規模のデータを収集、相関付け、解釈し、アプリケーションパフォーマンス、サービスの可用性、遅延とスループット、クラウド環境の健全性に関するその他の指標に関して、インサイトを取得しています。
クラウド環境の監視において中核となるのは、クラウドで実行するアプリケーションとサービスの健全性を継続的に評価し、最適なワークフローを確保することです。動的しきい値は、組織がKPIの現在の状態を把握し、問題を示す可能性のある状態の変化にプロアクティブに対応できるという点で、非常に重要なツールといえるでしょう。これにより、顧客の不満や収益の損失につながるダウンタイムを回避することができます。
インフラデータにはさまざまな種類が存在するため、ITSIでは標準偏差、分位数、範囲ベースの3種類の動的しきい値アルゴリズムをサポートしています。
動的しきい値は、ITチームがKPIの状態を継続的に監視し、より精度の高いアラートを生成するのに役立ちます。クラウドIT環境の監視とトラブルシューティングのために機械学習主導の分析を導入できる、ITSIの重要なコンポーネントです。
動的しきい値において機械学習が重要なのは、機械学習がパターンを見つけ、推論を導き、予測することができるためです。クラウドIT環境では、日々テラバイト規模のデータが生成されます。これは人間が手作業で解析できる量をはるかに超えています。機械学習アルゴリズムは、これらのタスクを効率よく正確に実行するため、パフォーマンス監視のあらゆる側面で欠かせないツールといえます。
一般的に動的しきい値は、データのパターンを見つけ、それに基づいて予測を行うために、回帰と分類という2つの機械学習手法を使用します。
回帰分析では、従属変数(行動)といくつかの独立変数(結果)を調べ、それらの間の関係の強さを評価します。これは通常、傾向の予測、特定の行動による影響の予測、行動と結果に相関性があるかどうかの判断を行うために使用されます。回帰分析には、単純な線形回帰、ロジスティック回帰、リッジ回帰など、一般的に使用されるいくつかのアルゴリズムが含まれます。
分類では、より正確な分析のためにデータをカテゴリ別に分類します。判定ツリーやニューラルネットワークなど、さまざまな数学的手法が使用されます。
クラウド環境は、企業に数多くのビジネス上のメリットをもたらしますが、その複雑さゆえに、高いノイズレベルや過剰なアラートが生まれ、パフォーマンスの問題の迅速な特定と対応ができない場合があります。動的しきい値は、サービスの監視を強化し、パフォーマンスが低下する前に問題を回避できるようにするうえで欠かせない手法です。
このブログはこちらの英語ブログの翻訳です。
この記事について誤りがある場合やご提案がございましたら、splunkblogs@cisco.comまでメールでお知らせください。
この記事は必ずしもSplunkの姿勢、戦略、見解を代弁するものではなく、いただいたご連絡に必ず返信をさせていただくものではございません。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
