
組織のデジタルレジリエンス強化に向けたロードマップ
デジタル時代に組織が成功を掴むための、Splunkのセキュリティとオブザーバビリティの統合プラットフォームの活用方法をご紹介します。

データ辞書は、あらゆるデータドリブンな組織にとって欠かせないツールですが、構築するのは複雑で手間のかかる作業のように思われがちです。データ辞書の定義を理解するだけでなく、その構成要素、メリット、そして作成方法を知る必要があります。
この記事では、データ辞書の目的に関する十分な基礎知識を身に付けられるよう、データ辞書についてのあらゆることを徹底的に解説します。
では、詳しい説明に入っていきましょう。
データ辞書とは、使用されるデータについての包括的な説明を提供する、構造化されたメタデータのリポジトリです。
データ辞書は、管理用データベースの初期の形態として1960年代に登場しました。その後、データ辞書は単なるファイルカタログから包括的なメタデータリポジトリへと進化し、現代のデータ分析とガバナンスを支えています。
今日、データ辞書の主な目的は、共通の言語を提供して以下の内容を理解できるようにすることです。
簡単に言えば、データ辞書とは、アナリストがデータをよりよく理解できるように、各データポイントについての補足的なコンテキストや情報を提供するものです。
先に進む前に、データ辞書、データカタログ、ビジネス用語集といった関連用語の違いを明確にしておきましょう。これらはすべて、データを管理したり理解したりする上で重要なツールです。
データ辞書 | データカタログ | ビジネス用語集 | |
|---|---|---|---|
焦点 | 主にデータの技術的な詳細に焦点を当てている。 | データ資産全体に焦点を当てている。 | ビジネスに関連する定義と用語に焦点を当てている。 |
対象者 | 主に、開発者やデータアナリストなどの技術系ユーザー向け。 | 技術系ユーザーに加えて、ビジネスアナリストやデータサイエンティストなどの非技術系ユーザーも使用できる。 | 従業員やビジネス関係者。 |
| 目的 | データの詳しい定義を提供することでユーザーを支援する。 | データの管理機能と検索機能を提供する。 | ビジネスの概念を統一して伝える。 |
一般に、データ辞書はアクティブとパッシブの2種類に分類できます。
アクティブデータ辞書とは、データベース内のデータに変更が加えられるたびに更新する必要があるドキュメントを指します。
通常、IT部門によって管理されるこのタイプのデータ辞書は、データベースやシステム内の各データに関する最新の定義を提供し、データの完全性に不整合や変更が生じないよう、積極的に防止します。
パッシブデータ辞書とは、通常手動で更新され、システムやデータベースに関連付けられていない静的なドキュメントを指します。このタイプのデータ辞書は、一般にアナリストがさまざまなデータポイントの意味とそれらの相互関係を理解する必要がある分析プロジェクトなどで参照するために使用されます。
パッシブデータ辞書はデータベース内に自動で作成されないため、データベースに変更が加えられるたびに不整合が発生しがちです。しかし、この静的なドキュメントはアナリストが参照するためだけに作成されているため、不整合が生じていたとしても、素早く情報を共有する目的で臨機応変に使用されます。
筆者がデータアナリストとして働いていたとき、基本的なパッシブデータ辞書の構築と保守を担当し、データアナリストの同僚と共有していました。この辞書にはエラーが多いものの、情報が明確に定義されているため、探索的データ分析を行ってデータの理解を深める際に非常に役に立ちました。
データ辞書はいくつかの基本的なコンポーネントに分解できます。
上記の要素は、データ辞書に必要な一般的なコンポーネントのほんの一部です。データ辞書はビジネスニーズによってそれぞれ異なります。
データ辞書の設定には一定の労力が必要です。そこで、詳細なデータ辞書を作成することで得られるメリットをいくつか見てみましょう。
明確に定義されたデータ辞書があると、組織全体でデータに対して同じ言葉を使用して、共通の認識を持てるようになるため、全員が効果的に意思疎通を図りやすくなります。また、各利害関係者がさまざまな種類のデータについて話し合うときに同じドキュメントを参照できるため、データについてのコミュニケーション上の行き違いや誤解を防げます。
データ辞書は信頼性の高いデータ定義を提供するため、データベースに正確で一貫性のある情報を確実に保持するのに役立ちます。
これにより、データベース全体の品質が向上し、データベースで分析を実行する際に、信頼性が高く有用なインサイトを得ることができます。
定義されたデータ辞書があると、データベースの保守と変更の追跡がはるかに簡単になります。特に、新しいデータ要素を追加したり、既存のデータ要素を更新したりする必要がある場合は便利です。データ辞書を参照することで、変更内容を全員が明確に理解できます。
適切にインデックス化されたデータ辞書を使用すると、必要なデータ要素を簡単に検索できます。
このため、アナリストは特定の情報を探す際の時間と労力を節約でき、データベース全体を手動で調べる必要性が減ります。
データ辞書を作成するには、次の5つの手順に従います。
まず、データベース内のさまざまなデータ要素をリストアップします。要素ごとに次のような情報を収集します。
次に、データベースの構造を文書化して、データベース内のさまざまなデータ要素がどのように関連付けられているかを理解します。データ要素間のすべての関係をリストアップして、データベース全体を明確に把握できるようにします。
データ要素ごとに、目的、ドメイン値、およびその他の必要な項目を定義します。そうすることで、すべての利害関係者がデータ要素について共通の理解を持つことができます。
検証ルールは、データベースに正確な情報が入力されるようにするのに役立つため、必ずデータ辞書内に記録します。
データ辞書は、データベースに加えられた変更を反映して最新の状態に保つ必要があります。したがって、監視と更新の責任者を配置することが重要です。
次のような役割のユーザーが、データ辞書を更新できます。
さまざまな領域でのデータ辞書の使用例について見てみましょう。
データ辞書がどうあるべきかをより詳しく理解できるよう、ヒントとなる例をご紹介します。
MicroStrategy社のデータ辞書には、Intelligence Serverに関連するさまざまなパフォーマンスメトリクスとオブジェクトが含まれています。この辞書では、各メトリクスの定義と、そのメトリクスをより詳しく理解するために必要なメモや説明を参照できます。
たとえば、「STG_CT_DEVICE_STATS」という名前のデータ辞書には、モバイルクライアントとモバイルデバイスに関する情報が格納されています。
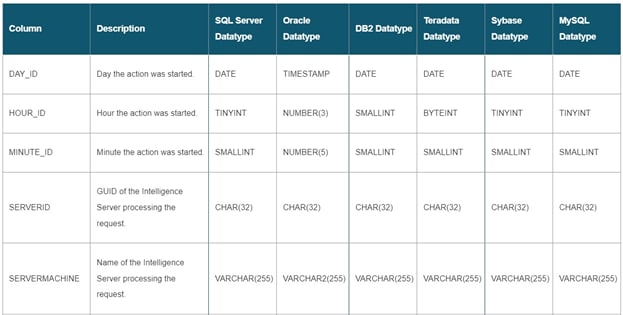
この例では、データ要素の名前、説明、およびデータ型があります。
米国労働統計局によるAmerican Time Use Survey Data Dictionary (米国生活時間調査のデータ辞書)には、この調査で使用されるさまざまなデータ項目が説明されています。これにより、研究者は変数のコード化に関する内容や、各項目の意味をより詳しく理解することができます。
たとえば、2021年のATUS (米国生活時間調査)インタビューのデータ辞書では、変数「TRTEC」は「高齢者介護に費やした合計時間(分単位)」と説明されています。また、「Min Value (最小値)」は0、「Max Value (最大値)」は1440という検証ルールも含まれています。

次に、関連する質問をいくつか見てみましょう。
データ辞書は、データベース内のデータ要素とその関係に関する追加の情報を提供し、データベースの理解と管理に役立ちます。
いいえ、データ辞書はスキーマと同じではありません。スキーマがデータベースの構造と編成を指すのに対し、データ辞書はデータベース内の各要素を補足する詳細情報を提供します。
スキーマはテーブルとその関係を記述し、データ辞書は各項目の意味と、それをどのように利用すべきかを説明します。
ソフトウェアエンジニアリングにおいて、データ辞書とは、システムとそのコンポーネントに関する一連の情報を含むものです。たとえば、次のような情報が含まれます。
迅速なアプリケーション開発において、データ辞書はデータの構造、明確な定義、および関係に関する情報を提供することで設計プロセスを効率化する重要な役割を果たします。また、チームメンバーのコラボレーションを促進し、実装中に発生する可能性のあるエラーを減らすのに役立ちます。
データ辞書を利用してシステム内の各項目の構造と属性を文書化することで、理解と管理が容易になります。また、正確性と一貫性を維持するために、データ辞書にはデータ要素やプロセスに関連するルールも含まれています。ソフトウェア開発者は、開発者、プロダクトマネージャー、エンジニア、データ管理者向けの参照情報としてデータ辞書を使用します。
さらに、データ辞書は、多様なクラウドサービスにおけるメタデータの管理、データ定義の標準化、データ交換の改善、そしてコラボレーションとガバナンスの確立を通じて、クラウドコンピューティングの統合を強化します。
データ辞書を正確かつ最新に保つことは、大規模なデータセットやデータベースのデータを管理したり、操作したりする場合に特に不可欠です。データ辞書は、変更内容を誰もが明確に理解できるようにするための参照情報として機能すると同時に、検索の容易化や精度の向上といった大きなメリットをもたらします。
包括的なデータ辞書があることで、意思疎通が円滑になり、データの品質が向上し、保守も容易になります。
このブログはこちらの英語ブログの翻訳です。
この記事について誤りがある場合やご提案がございましたら、ssg-blogs@splunk.comまでメールでお知らせください。
この記事は必ずしもSplunkの姿勢、戦略、見解を代弁するものではなく、いただいたご連絡に必ず返信をさせていただくものではございません。

Splunkプラットフォームは、データを行動へとつなげる際に立ちはだかる障壁を取り除いて、オブザーバビリティチーム、IT運用チーム、セキュリティチームの能力を引き出し、組織のセキュリティ、レジリエンス(回復力)、イノベーションを強化します。
Splunkは、2003年に設立され、世界の21の地域で事業を展開し、7,500人以上の従業員が働くグローバル企業です。取得した特許数は1,020を超え、あらゆる環境間でデータを共有できるオープンで拡張性の高いプラットフォームを提供しています。Splunkプラットフォームを使用すれば、組織内のすべてのサービス間通信やビジネスプロセスをエンドツーエンドで可視化し、コンテキストに基づいて状況を把握できます。Splunkなら、強力なデータ基盤の構築が可能です。

© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
