
ガートナー社 2024年 SIEM部門のマジック・クアドラント
Splunkが10回連続でリーダーに選出された理由をこちらからご確認ください。

同僚のAndrew Steinと私は最近、Splunk IT Service Intelligence (ITSI)ソリューションを使用しているお客様の新しい機械学習プロジェクトに参加しました。そこでお客様に「Splunkで機械学習を活用して重要なサービスの停止を予測する(先行指標を見付ける)にはどうすればよいか?」と尋ねられました。
さっそく私たちは、Splunk ITSIで機械学習を利用してその予測を実現できるかどうかを調査しました。結論から言うと、「できる」という答えになります。
その手順は以下のとおりです。
1. ITSIの主要業績評価指標(KPI)の品質を調査する
2. ITSIのサマリーインデックスを調査する
3. 統計を追加してサーチを改良する
4. Splunk Machine Learning Toolkit (MLTK)にデータセットを取り込む
5. 機械学習モデルを構築する
6. アラートを作成する
多くの機械学習プロセスでは、過去に収集した情報を使用して、将来発生する可能性のあるイベントを予測します。最初の課題は、ITSIの情報をもとに、機械学習アルゴリズムへの入力に適したデータセットを作成することです。
ITSIのデータを調査すると、KPIとそのレポートの履歴が保持されていることが判明しました。結果としてこれらの情報は、このプロジェクトにとって有用なデータソースとなりました。また、サービスの可用性と健全性に関するKPIは、お客様がすでに定義していました。これらのKPIから過去の情報を得ることで、機械学習を適用できることがわかりました。

次にITSIのサマリーインデックスを調査したところ、各サービスとそれぞれのKPIに関するナレッジが保存されていることがわかりました。また、これらのKPIは数値であることもわかりました。数値であることは、このプロジェクトに不可欠です。 さらに重要なのは、Splunk KVストアを使用してKPIが特定のサービスとマッピングされていたことです。これにより、各サービスの詳細のサーチと取得プロセスを効率化できます。
ITSIサマリーインデックスは、ITSIのWebストアサービスを介して調査しました。使用したサーチは以下のとおりです。
\code
index=itsi_summary
| join kpiid
[| inputlookup service_kpi_lookup
| rename _key as serviceid title as service_name
| eval kpi_info = mvzip('kpis._key', 'kpis.title', "==@@==")
| fields kpi_info service_name serviceid
| mvexpand kpi_info
| rex field=kpi_info "(?<kpiid>.+)==@@==(?<kpi_name>.+)"
| fields - kpi_info]
| search service_name="Web Store Service"
| timechart span=5m avg(alert_value) AS avg_value BY kpi_name
\code

このサーチによって、データセット(index=itsi_summary)とルックアップ(service_kpi_lookup)に保存されたフィールドレベルの詳細を取得できたことは大きな収穫でした。皆様もITSIでこのサーチを実行すれば、同様の粒度の情報を確認できます。
サービス

エンティティ

KPI名
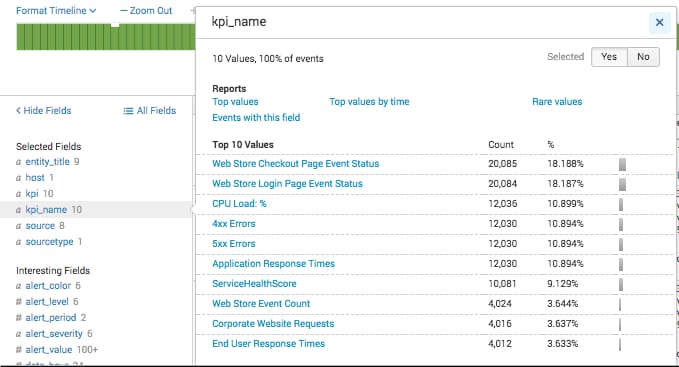
アラート値

このサーチ結果にはサービス健全性スコアも含まれます。これは、新しいサービスを定義すると自動で作成される追加のKPIです。この結果によって、機械学習を使ってサービス健全性スコアの将来の値を予測するのに十分な情報が得られました。
最初のサーチは高い成果をあげました。ただし、機械学習アルゴリズムを適用するには、さらに追加の統計が必要です。そこで、最小値、最大値、中央値と、曜日や時間などの文字列を追加して、機械学習アルゴリズムに入力する際の適合性を高めたデータセットを作成しました。
\code
index=itsi_summary
| join kpiid
[| inputlookup service_kpi_lookup
| rename _key as serviceid title as service_name
| eval kpi_info = mvzip('kpis._key', 'kpis.title', "==@@==")
| fields kpi_info service_name serviceid
| mvexpand kpi_info
| rex field=kpi_info "(?<kpiid>.+)==@@==(?<kpi_name>.+)"
| fields - kpi_info]
| search service_name="Web Store Service"
| timechart span=5m max(alert_value) AS max_value min(alert_value) AS min_value avg(alert_value) AS avg_value median(alert_value) AS mean_value BY kpi_name
| eval this_date_hour = strftime(_time, "%H")
| eval this_date_day = strftime(_time, "%w")
| eval this_date_day = this_date_day."_"
| eval this_date_hour = this_date_hour."_"
\code
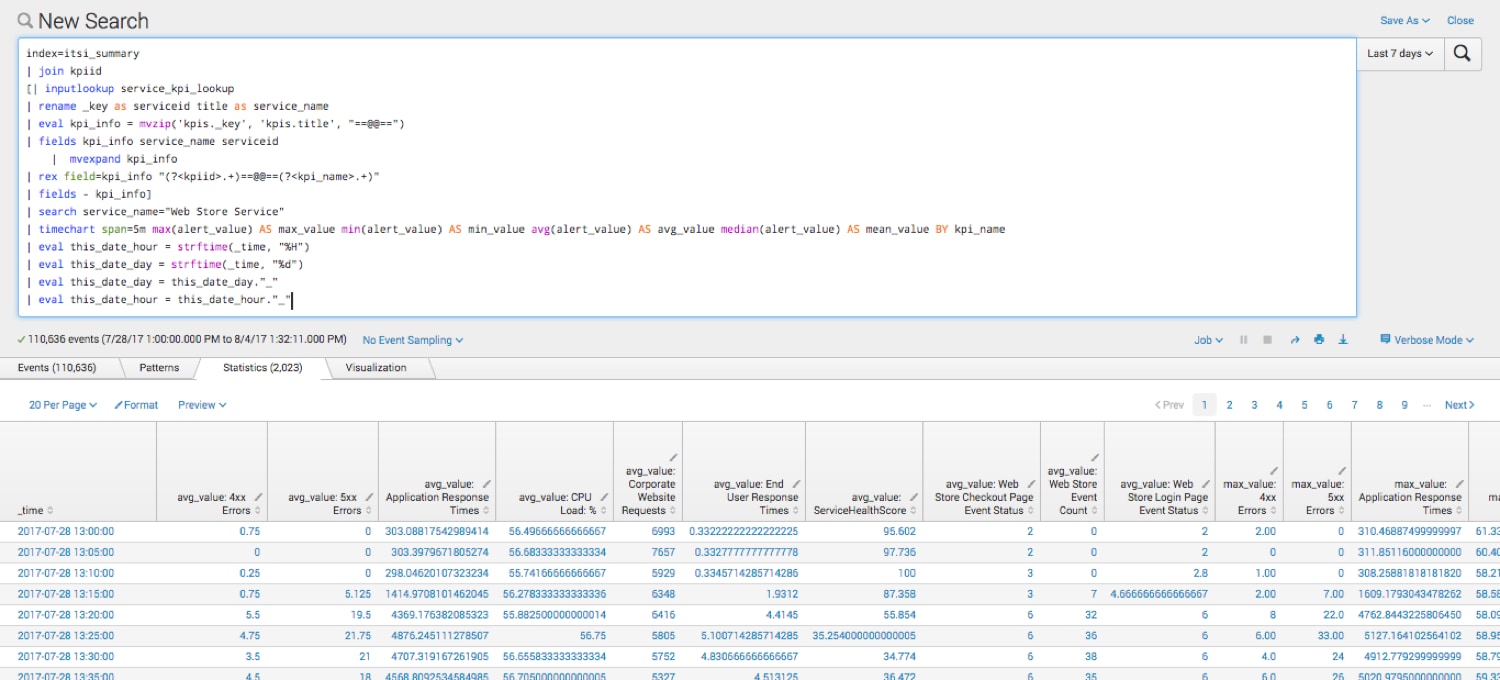
これで、サービス健全性スコアを予測するために機械学習アルゴリズムに入力する、包括的なデータセットが完成しました。次の課題は、予測のためのフィールドを用意し、データセットに予測を組み込むことです。そのためにはどうすればよいでしょうか。
最良の方法はstreamstatsコマンドを使用することです。具体的には、|streamstats windows= 6を指定します。現在のタイムフレームは5分間隔なので、6つ使えば30分先を予測することになります。続いてServiceHealthScoreFromFuture(30分後のサービス健全性スコア)という名前の新しいフィールドを作成し、reverseコマンドでタイムスタンプを逆順にすることで、テスト用に将来の値をプッシュします。
\code
index=itsi_summary
| join kpiid
[| inputlookup service_kpi_lookup
| rename _key as serviceid title as service_name
| eval kpi_info = mvzip('kpis._key', 'kpis.title', "==@@==")
| fields kpi_info service_name serviceid
| mvexpand kpi_info
| rex field=kpi_info "(?<kpiid>.+)==@@==(?<kpi_name>.+)"
| fields - kpi_info]
| search service_name="Web Store Service"
| timechart span=5m max(alert_value) AS max_value min(alert_value) AS min_value avg(alert_value) AS avg_value median(alert_value) AS mean_value BY kpi_name | eval this_date_hour = strftime(_time, "%H")
| eval this_date_day = strftime(_time, "%w")
| eval this_date_day = this_date_day."_"
| eval this_date_hour = this_date_hour."_"
|reverse
|streamstats window=6 current=f first(‘max_value: ServiceHealthscore’) as ServiceHealthScoreFromFuture
|reverse \code
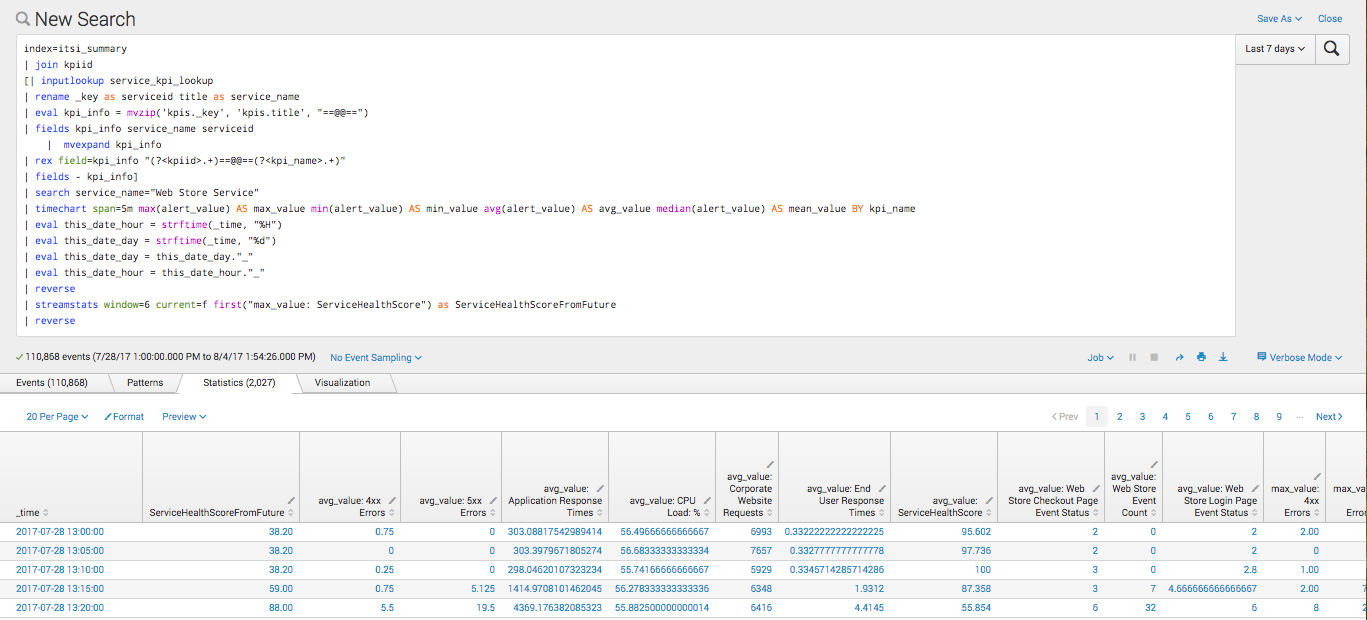
これでデータセットが準備できました。次に、Splunk Machine Learning Toolkitを使用して機械学習アルゴリズムを設定します。この操作は数回クリックするだけで済みます。ここではMLTKのPredict Numeric Fields (数値フィールドの予測)アシスタントを選択し、LinearRegression (線形回帰)アルゴリズムを選択しました。
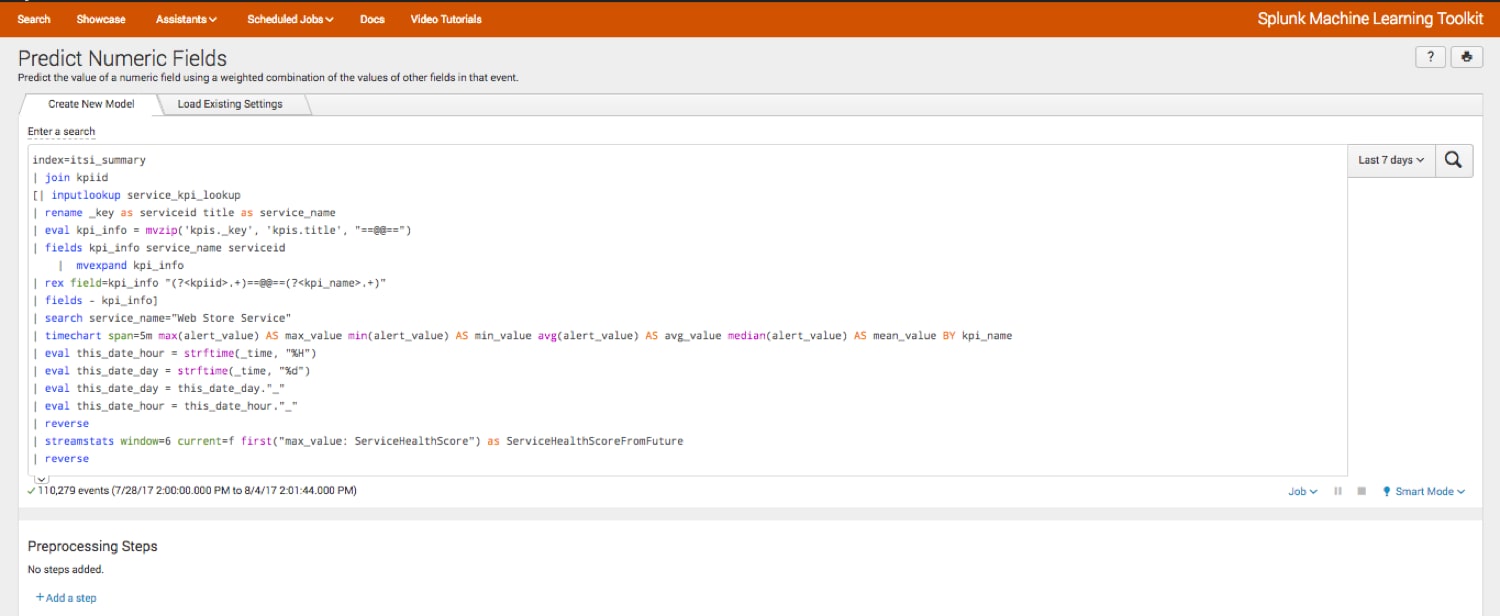
結果は良さそうですが、データを正規化する必要があるため、MLTKのPreprocessing Steps (事前処理ステップ)を使用します。

予測したいフィールド(ServiceHealthScoreFromFuture: 30分後のサービス健全性スコア)を選択し、正規化されたフィールド(SS_で始まるフィールド、_time、this_date_day、this_date_hour)を使用して、標準偏差アルゴリズムによってモデルを作成し、my_ITSI_WebService_Test.eと名付けました。

モデルフィッティング後の結果は次のとおりです。
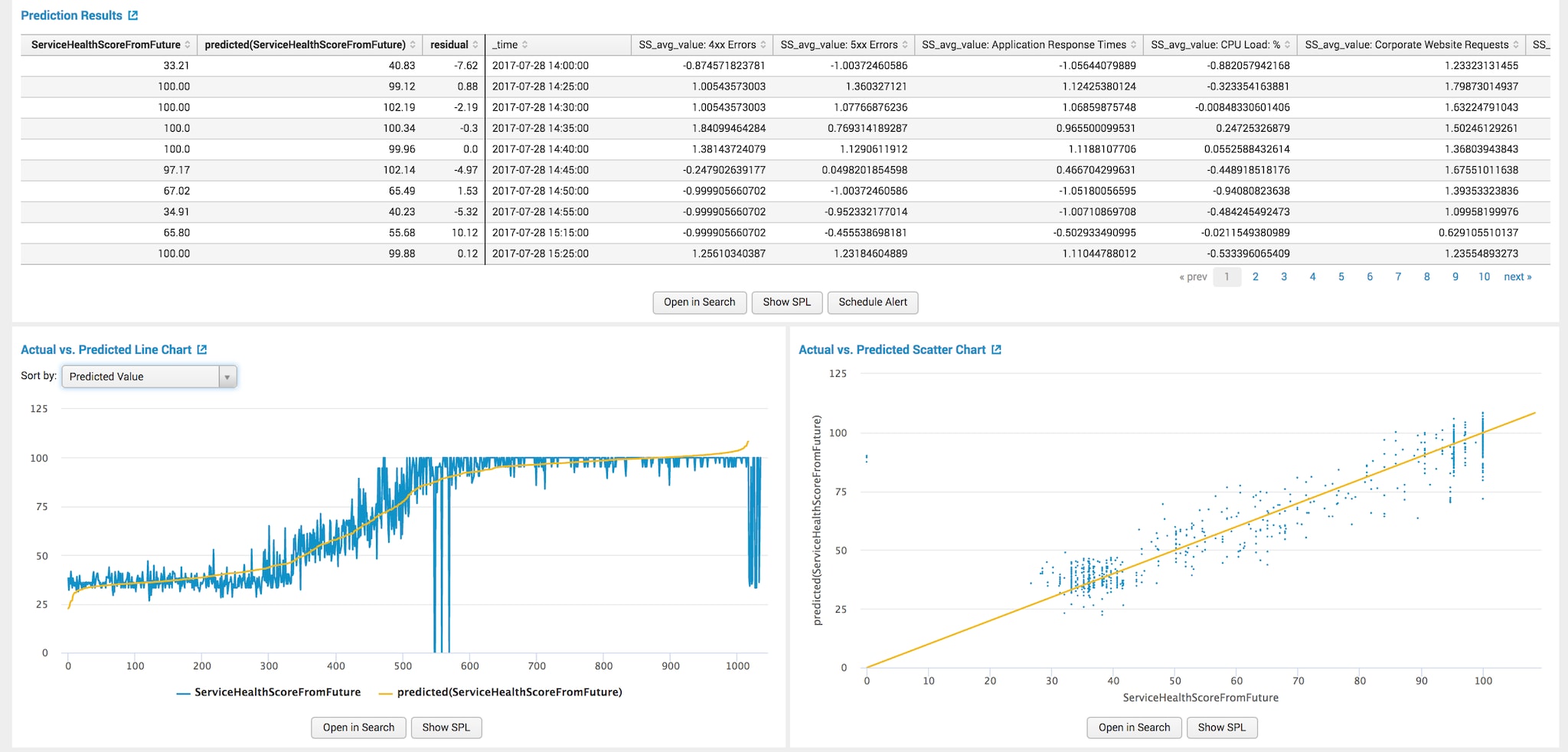
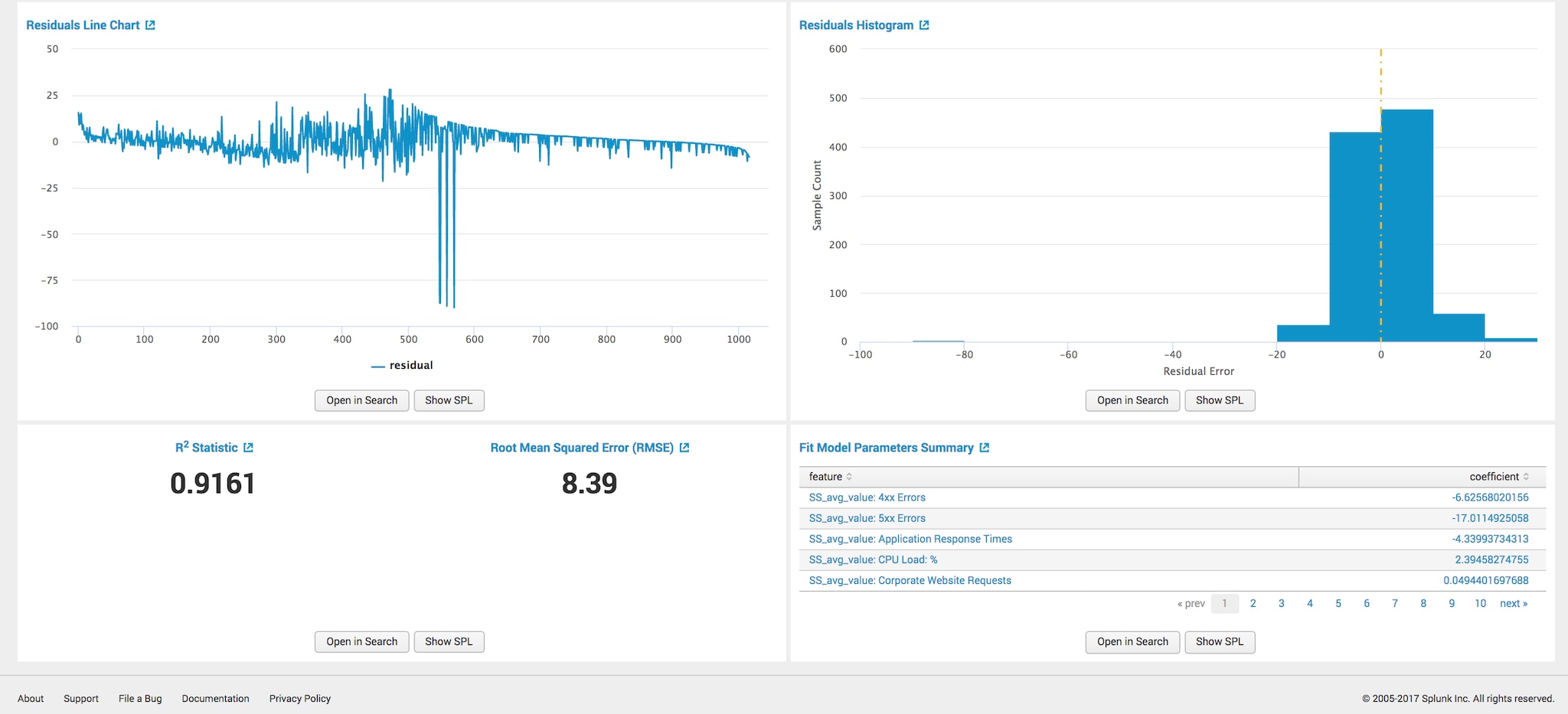
モデルの完成度はかなり高いと思われます。
次に、MLTKのアラート機能を使用して、ServiceHealthScoreFromFuture(30分後のサービス健全性スコア予測値)の値が70を下回った場合にアラートを生成するようにスケジュールします。この例で70に設定した理由を説明します。Webストアサービスの健全性スコアの予測値が80~100の範囲にあるときは、パフォーマンスが良好だとわかっています。そのため、そこから10ポイント外れた場合にアラートを生成するように設定したのです。
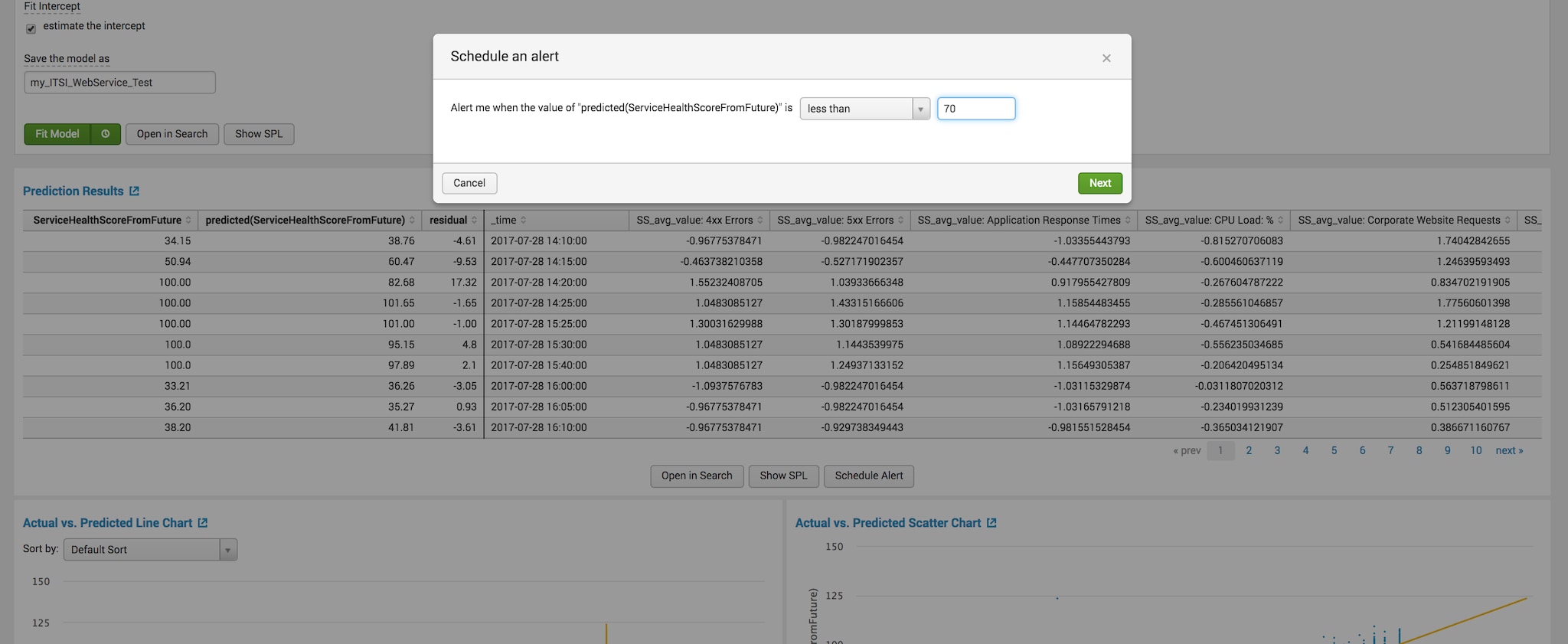
アラートは30分ごとに実行するようにスケジュールしましたが、必要に応じて5分ごとや特定のタイムフレームに設定できます。適用したモデルに対して各種の間隔でアラートを実行するには、次のサーチを使用します。
\code
index=itsi_summary
| join kpiid
[| inputlookup service_kpi_lookup
| rename _key as serviceid title as service_name
| eval kpi_info = mvzip('kpis._key', 'kpis.title', "==@@==")
| fields kpi_info service_name serviceid
| mvexpand kpi_info
| rex field=kpi_info "(?<kpiid>.+)==@@==(?<kpi_name>.+)"
| fields - kpi_info]
| search service_name="Web Store Service"
| timechart span=5m max(alert_value) AS max_value min(alert_value) AS min_value avg(alert_value) AS avg_value median(alert_value) AS mean_value BY kpi_name
| eval this_date_hour = strftime(_time, "%H")
| eval this_date_day = strftime(_time, "%d")
| eval this_date_day = this_date_day."_"
| eval this_date_hour = this_date_hour."_"
| reverse
| streamstats window=6 current=f first("max_value: ServiceHealthScore") as ServiceHealthScoreFromFuture
| reverse | apply my_ITSI_WebService_Test_StandardScaler_0 | apply "my_ITSI_WebService_Test" | eval residual = 'ServiceHealthScoreFromFuture' - 'predicted(ServiceHealthScoreFromFuture)' | table "ServiceHealthScoreFromFuture", "predicted(ServiceHealthScoreFromFuture)", residual, "_time" "SS_avg_value: 4xx Errors" "SS_avg_value: 5xx Errors" "SS_avg_value: Application Response Times" "SS_avg_value: CPU Load: %" "SS_avg_value: Corporate Website Requests" "SS_avg_value: End User Response Times" "SS_avg_value: ServiceHealthScore" "SS_avg_value: Web Store Checkout Page Event Status" "SS_avg_value: Web Store Event Count" "SS_avg_value: Web Store Login Page Event Status" "SS_max_value: 4xx Errors" "SS_max_value: 5xx Errors" "SS_max_value: Application Response Times" "SS_max_value: CPU Load: %" "SS_max_value: Corporate Website Requests" "SS_max_value: End User Response Times" "SS_max_value: ServiceHealthScore" "SS_max_value: Web Store Checkout Page Event Status" "SS_max_value: Web Store Event Count" "SS_max_value: Web Store Login Page Event Status" "SS_mean_value: 4xx Errors" "SS_mean_value: 5xx Errors" "SS_mean_value: Application Response Times" "SS_mean_value: CPU Load: %" "SS_mean_value: Corporate Website Requests" "SS_mean_value: End User Response Times" "SS_mean_value: ServiceHealthScore" "SS_mean_value: Web Store Checkout Page Event Status" "SS_mean_value: Web Store Event Count" "SS_mean_value: Web Store Login Page Event Status" "SS_min_value: 4xx Errors" "SS_min_value: 5xx Errors" "SS_min_value: Application Response Times" "SS_min_value: CPU Load: %" "SS_min_value: Corporate Website Requests" "SS_min_value: End User Response Times" "SS_min_value: ServiceHealthScore" "SS_min_value: Web Store Checkout Page Event Status" "SS_min_value: Web Store Event Count" "SS_min_value: Web Store Login Page Event Status" "this_date_day" "this_date_hour" | where 'predicted(ServiceHealthScoreFromFuture)' > 70
\code
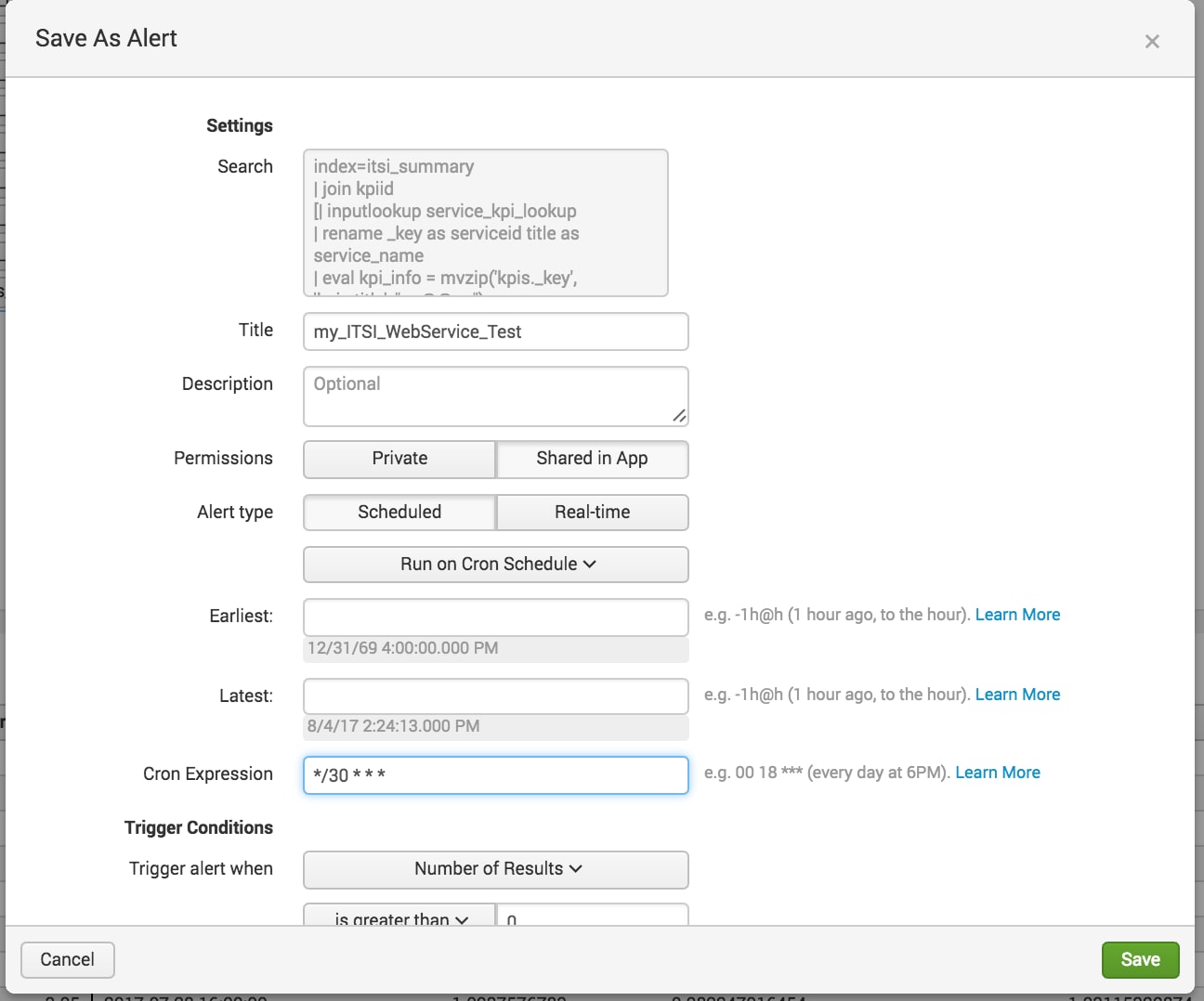
このアラートをITSIの重要なイベントと分析に追加して、ITSI Webストアサービスの重要サービスに影響する可能性のある先行指標をチームに通知することもできます。
お客様はとても感心されていました。この仕組は、ITSIのKPIを使用してMLTKで予測モデルを作成し、MLTKとITSIの重要インベントフレームワークの2重のアラートシステムを使用してサービス低下の兆候の先行指標をチームに通知するというものです。
ぜひこの記事を参考に、IT運用分析に新しい手法を取り入れてみてください。
Splunkのメリットをどうぞお試しください。
『翻訳レビュー者追記: ここで紹介された手法は、最新のITSIにおいては 『Predictive Analytics』として標準機能として搭載されています。本Blogは、当該機能がどのようなITSI内部処理により実現されているのかをご理解頂くために有用と考え、公開しています。』
このブログはこちらの英語ブログの翻訳、沼本 尚明によるレビューです。

Splunkプラットフォームは、データを行動へとつなげる際に立ちはだかる障壁を取り除いて、オブザーバビリティチーム、IT運用チーム、セキュリティチームの能力を引き出し、組織のセキュリティ、レジリエンス(回復力)、イノベーションを強化します。
Splunkは、2003年に設立され、世界の21の地域で事業を展開し、7,500人以上の従業員が働くグローバル企業です。取得した特許数は1,020を超え、あらゆる環境間でデータを共有できるオープンで拡張性の高いプラットフォームを提供しています。Splunkプラットフォームを使用すれば、組織内のすべてのサービス間通信やビジネスプロセスをエンドツーエンドで可視化し、コンテキストに基づいて状況を把握できます。Splunkなら、強力なデータ基盤の構築が可能です。

© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
