
ガートナー社 2024年 SIEM部門のマジック・クアドラント
Splunkが10回連続でリーダーに選出された理由をこちらからご確認ください。

Splunk Enterprise、Splunk Cloud Platform、そしてそれらを基盤とするプレミアム製品はオープンなプラットフォームであり、サードパーティ製品でSplunk内のデータを利用して新たなユースケースを開発できます。このブログでは、サードパーティのAmazon SageMakerでSplunk内のデータを使って将来のリスクスコアを予測するための不正検出ユースケースの強化方法をご紹介します。
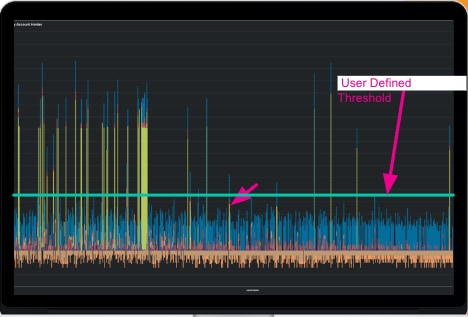
私は少し前のブログで、ルール違反のリスクスコアの結果をリスクインデックスに集約することで、Splunkプラットフォームで効率的に不正を検出する方法をご紹介しました。おさらいすると、Splunkでは、さまざまなタイプの悪質なアクティビティを検出し、各アクティビティのリスクスコアを算出してから、エンティティ(顧客、ユーザー、アカウントIDなど)ごとにリスクスコアを集計して、しきい値と比較できます。エンティティのリスクスコアの集計がユーザー定義のしきい値を上回った場合、そのエンティティは不正行為をしているか、広い意味での金融犯罪に関わっている可能性が高いと判断できます。Splunkレポートでは、その結果をグラフで確認できます。
 エンティティごとのリスクスコアの集計が表示されたSplunkレポート
エンティティごとのリスクスコアの集計が表示されたSplunkレポート
ユーザー定義のしきい値の線に注目してください。この期間の集計リスクスコアの中でしきい値を超えているものは不正とみなすことができます。その根拠は、特定のエンティティのさまざまなアクティビティのリスクスコアを集計したものが、不正を示すしきい値を超えているからです。これにより、1つのルール違反のみを基準とすることで生じやすい誤検知を回避し、不正判定の精度を向上させることができます。このようにSplunkでは、Splunk Enterprise Securityのリスクベースアラート(RBAとSplunk App for Fraud Analytics)を使用している場合でも、Splunk EnterpriseまたはSplunk Cloud Platform内で独自のリスクフレームワークを構築している場合でも、最新の手法で不正を検出できます。
レポートにはもう1つ小さい矢印があります。何を指しているのでしょうか?集計リスクスコアがしきい値を超えてはいないものの、そこにかなり近いエンティティがいくつかあることがわかります。これらのエンティティはこれから不正を犯そうとしているのでしょうか?その可能性はあります。しかし、現在のアプローチでは、しきい値を超えていないため不正とはみなされません。解決策の1つは、しきい値を下げることです。これで、しきい値近くの外れ値がしきい値を超えるようになります。ただし、しきい値を下げれば、その分、誤検知が発生する可能性が高くなります。誤検知が多すぎると、顧客や社内の不正対策チームに余計な負担がかかってしまいます。
もう1つの解決策は、機械学習やAIを使って、しきい値近くのスコアが近い将来しきい値を超える可能性があるかどうかを予測することです。これにより、深刻な違反が発生する前に、不正の可能性がある行為に対処できます。簡単な例を挙げましょう。しきい値が58で、あるエンティティの3日間の集計リスクスコアが54、55、56だったとします。担当者がこの上昇傾向のスコアを検出して対応することもできますが、エンティティが何十万もある場合は、すべてのレポートをチェックして問題を見つけ出すことは困難です。そこでこの記事では、不正のしきい値をまだ超えていない過去のリスクスコアに基づいてエンティティが今後不正を犯すかどうかを予測する手法について説明します。
近い将来のリスクスコアの予測方法について説明する前に、Splunkでこのデータがどのように作成および収集されるかをおさらいしましょう。
 リスクスコアの流れ
リスクスコアの流れ
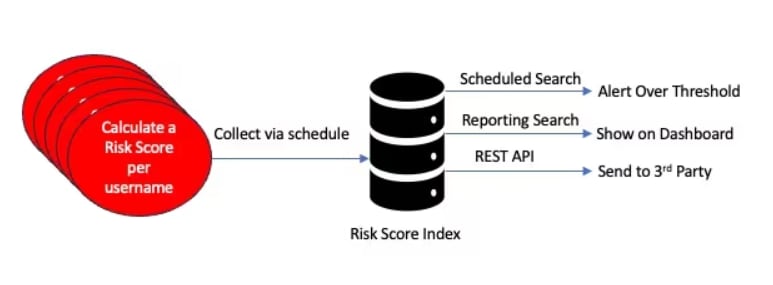
ルールに対してスケジュールサーチが実行され、トランザクションデータに基づいて不正検出のためのリスクスコアが計算された後、メタデータとともにサマリーインデックスに保存されます。この時点で、ネイティブSplunk Appまたはサードパーティアプリケーションでリスクインデックスからデータを読み込んで詳細分析を実行できるようになります。
今回は、Splunkからサードパーティ製品のAmazon SageMakerにデータを送信し、高度な手法と機械学習を使ってリスクスコアを予測します。ここで、無料のSplunk Machine Learning Toolkit (MLTK)でも同じようなことができると考えた方もいらっしゃるかもしれません。たしかに、そのとおりです。Amazon SageMakerを使用する理由の1つは、アマゾン ウェブ サービス(AWS)が広く普及しており、シチズンデータサイエンティスト向けに設計されたこのソリューションを使い慣れている利用者も比較的多いためです。Splunkをデータの集約と分析に使用し、他のツールでそのデータを活用できるようにすることで、より高度なオープンシステムを構築し、機械学習を使った問題解決方法の選択肢を広げることができます。
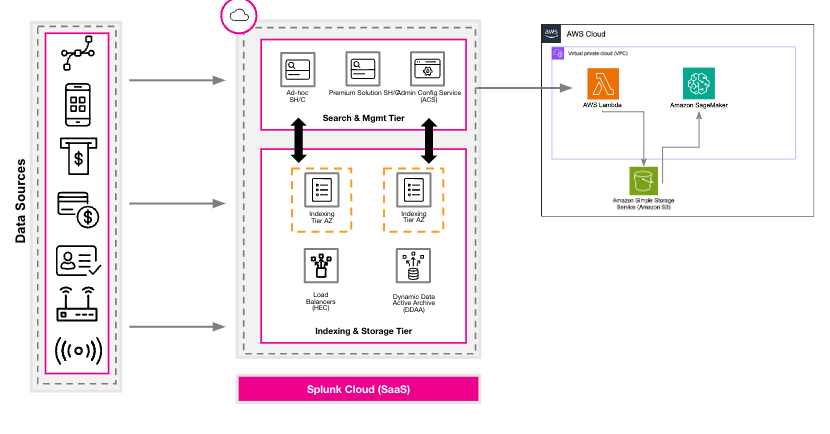
この手法については、SplunkのBrett RobertsがAmazon SageMakerの基本的なテクニックをすぐに習得して、今年のAWS re:inventでデモを披露しました。実は、Splunkは2つのシアターセッションでこのユースケースを紹介しました。基本的な考え方としては、まず、AWSで定期的に実行されるAWS (Lambda)関数を使って、REST API経由でSplunkの集計リスクスコア(とタイムスタンプ、ルール名、エンティティ名などのメタデータ)を照会し、結果をAmazon (S3)バケットに保存します。その後、Amazon SageMakerからS3バケットを照会して、エンティティごとの将来のリスクスコアを予測するモデルを作成します。このアプローチを図にすると次のようになります。
 Splunk CloudからAWS SageMakerへのデータの流れ
Splunk CloudからAWS SageMakerへのデータの流れ
右側の囲いがAWSで、Splunk Cloud Platformと同じクラウドインスタンスを使用している場合は、Splunk Cloud PlatformからAWSへのデータ送信コストは発生しません。データを収集したら、Amazon SageMakerを使ってモデルを作成し、時系列データに基づいて数値予測を行います。次の図に、Amazon SageMakerを使って将来のリスクスコアを予測するユースケースの大まかな手順を示します。

最も興味深いステップは4と5です。モデルの作成後、リスクスコアの予測に着手します。ここでは、今回のユースケースの肝となるステップ4について詳しく見ていきましょう。
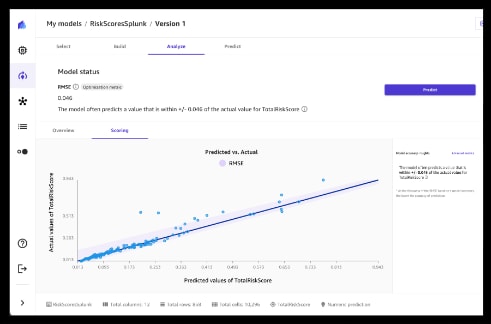
グラフの線は予測値を表します。いくつかの実測値(点)が予測値のすぐ下にあることに注目してください。これらのエンティティは、リスクスコアの予測値がしきい値を上回った場合、不正を犯す可能性があるとみなされます。これがこのブログの要点です。
まず、エンティティごとの集計リスクスコアを予測するために使われたアルゴリズムを確認しましょう。提供された属性に基づいてリスクスコアを予測するために線形回帰のアルゴリズムがいくつか使われています。また、大規模なデータセットであれば、ここでニューラルネットワークとディープラーニングが使われることもあるでしょう。
今回試してみて興味深かった点の1つは、エンティティごとの集計リスクスコアに最も影響した不正検出ルールのアクティビティが明らかになったことです。この場合は「過剰なログイン失敗とそれに続くログイン成功」でした。この検出ルールが他のルールよりも不正に関係が深いのであれば、エンティティごとの集計リスクスコアを計算する際に、このルールのリスクスコアに1.5などの重みを掛けて、重要度を50%上げてもよいでしょう。
最後にもう1つ注目すべきは、Amazon SageMakerが、機械学習モデルの一般的な形式であるOpen Neural Networks Exchange (ONNX)に対応している点です。Amazon SageMakerで使用するモデルをONNX形式にエクスポートすれば、SplunkのMachine Learning Toolkit (MLTK)にインポートして推論を実行できます。これにより、相互運用性をある程度確保できるため、SplunkのMLTKを使い慣れている場合は、他のフレームワークで作成したモデルをMLTKで引き続き利用できます。さらに、データサイエンティスト向けの無料のSplunk App for Data Science and Deep Learning (DSDL)を使用すれば、ディープラーニングモデルを組み込んだより包括的なユースケースを開発して、ソリューションの幅を広げることができます。
この記事では、不正検出に使用するデータをサードパーティ製品に送信して追加の処理を行い、ユースケースの付加価値を高める方法をご紹介しました。もちろん、高度なユースケースのいくつかはSplunkだけでも実現できますが、この方法を使えば、Splunkで開発したユースケースを、お客様が使い慣れた製品を使って強化できます。Amazon SageMakerを現在ご利用であれば、AWS上のSplunk EnterpriseまたはSplunk Cloud Platformインスタンスに保存されているデータを使って不正検出のユースケースを強化することをぜひご検討ください。Splunkをまだ不正検出に使用していない場合は、こちらの情報を参考に始めてみてください。Splunk MLTKでも幅広いニーズに対応できますが、Splunkのデータプラットフォームとしてのオープン性を活かすことで、既存のソフトウェアエコシステムの活用範囲を広げて、目的の成果を達成することもできます。不正の検出と防止では、1つの製品だけに頼るよりも、複数のアプローチやベンダーを組み合わせた方が検出精度が向上しやすく、選択肢も増えます。
このユースケースの開発にご協力いただき、AWS re:inventで発表の機会を与えてくださったAWS社に感謝いたします。特に、今回の作業でご支援いただいたAWS社のScott Mullins氏、Nick Dimtchev氏、Dan Kasun氏にお礼申し上げます。
このブログはこちらの英語ブログの翻訳、中里 美奈子によるレビューです。

Splunkプラットフォームは、データを行動へとつなげる際に立ちはだかる障壁を取り除いて、オブザーバビリティチーム、IT運用チーム、セキュリティチームの能力を引き出し、組織のセキュリティ、レジリエンス(回復力)、イノベーションを強化します。
Splunkは、2003年に設立され、世界の21の地域で事業を展開し、7,500人以上の従業員が働くグローバル企業です。取得した特許数は1,020を超え、あらゆる環境間でデータを共有できるオープンで拡張性の高いプラットフォームを提供しています。Splunkプラットフォームを使用すれば、組織内のすべてのサービス間通信やビジネスプロセスをエンドツーエンドで可視化し、コンテキストに基づいて状況を把握できます。Splunkなら、強力なデータ基盤の構築が可能です。

© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
