
最先端のオブザーバビリティプラクティスの構築
IT運用チームとエンジニアリングチームのためのSplunkを活用したデジタルレジリエンスの強化方法をご紹介します。

サーバーレス関数とは、サーバーレスコンピューティングにおける単一機能のプログラムのことで、適切に活用することでチームや組織に多くのメリットをもたらします。
この記事では、サーバーレス関数の仕組み、活用方法、組織にとってのメリットについて解説します。また、サーバーレス関数の導入方法とメリットを最大限に引き出す方法もご紹介します。
まずは背景について説明しましょう。
サーバーレスコンピューティングはクラウドコンピューティングモデルの1つであり、単に「サーバーレス」とも呼ばれます。このモデルでは、クラウドプロバイダーが顧客の要求に応じてコンピューティングリソースをプロビジョニングし、クラウドインフラを含むすべてのアーキテクチャを管理します。名前が「サーバーレス」となっていますが、実際にはクラウドと物理サーバーを利用してコードを実行します。どういうことかと言うと、ここで言う「サーバーレス」とは、開発者や運用担当者がサーバー、オペレーティングシステム、その他のインフラを直接扱うことがないという意味なのです。サーバーはどこか別の場所にあり、なくなったわけではありません。
サーバーレスアーキテクチャは、サーバーレスフレームワークとも呼ばれ、組織のソフトウェアアプリケーションをサードパーティのクラウドサービスプロバイダーがホストし、イベントドリブンで実行する形態を指します。これにより、組織はハードウェアやソフトウェアのインフラを管理する必要がなくなるとともに、ベンダーロックインを避けることができます。
インターネット上でアプリケーションを公開する場合、以前は、アプリケーションの実行に必要な物理サーバーまたは仮想サーバー、オペレーティングシステム、ネットワーク、その他のインフラコンポーネントを組織が自ら管理する必要がありました。その後、アマゾン ウェブ サービス (AWS)やMicrosoft Azureなどのクラウドサービスの登場により物理サーバーの管理は不要になりましたが、仮想サーバーのオペレーティングシステムやWebサーバーソフトウェアのプロセスなどは依然として組織が管理する必要がありました。
サーバーレスアーキテクチャでは、ハードウェア、仮想マシン(VM)のオペレーティングシステム、Webサーバーソフトウェアのいずれもプロバイダーが管理します。そのため、開発者はアプリケーションのコーディングにのみ集中できます。
サーバーレスアーキテクチャはFaaS (Function-as-a-Service)としての機能を提供するため、アプリケーションを個々の独立した機能の組み合わせとして構築できます。各機能はFaaSプロバイダーがホストし、トラフィックの増減に合わせて自動的にスケーリングされます。
ここで登場するのがサーバーレス関数です。
サーバーレス関数の実体は、ステートレス(データを保持しない)かつエフェメラル(不要になったら破棄される)という性質を持つ小規模なビジネスロジックです。特定の条件が満たされたときに実行され、場合によってはわずか数秒後に破棄されます。サーバーレス関数実行のトリガーとなるのは、次のようなアクションです。
API呼び出しをトリガーに実行できるものであれば、どのような機能でもサーバーレス関数として実装できます。わかりやすく説明するために、アプリケーション全体の仕組みから考えてみましょう。
アプリケーションのアーキテクチャは、通常、フロントエンドとバックエンドに分けられます。
たとえば、ユーザーがオンラインショッピングサイトにアクセスすると、そのWebサイトのフロントエンド、つまりテキスト、画像、検索バー、その他の入力フォームなどが表示されます。ユーザーが商品を検索すると、検索リクエストがWebサイトのバックエンドに送られ、それがトリガーとなって、データベースをチェックするコードが実行され、商品の在庫の有無、在庫数、価格などが確認されます。その後、検索結果のデータがバックエンドからフロントエンドに送られ、ユーザーに見やすい形で表示されます。
アプリケーションのバックエンドはさまざまな機能で構成されます。サーバーレスコンピューティングでは、開発者は個々のバックエンド機能を、独立して実行する単一用途のコードモジュールとして構築できます。これらは、Java、Python、PowerShell、Rubyをはじめ、代表的なプログラミング言語を使って、関数として実装できます。また、サーバーレスプラットフォームで使用できるそのほかの言語も継続的に追加されています。
サーバーレス関数について唯一厳格なルールは、外部のソフトウェアやコードに依存せずに実行できるようにすることです。この自己完結性のおかげで、アクティブ化、実行開始、停止をすばやく行うことができるのです。
サーバーレス関数を使用するには、関数のコードを記述して、マネージド環境にデプロイする必要があります。サーバーレス関数の一般的なプロセスは次のとおりです。
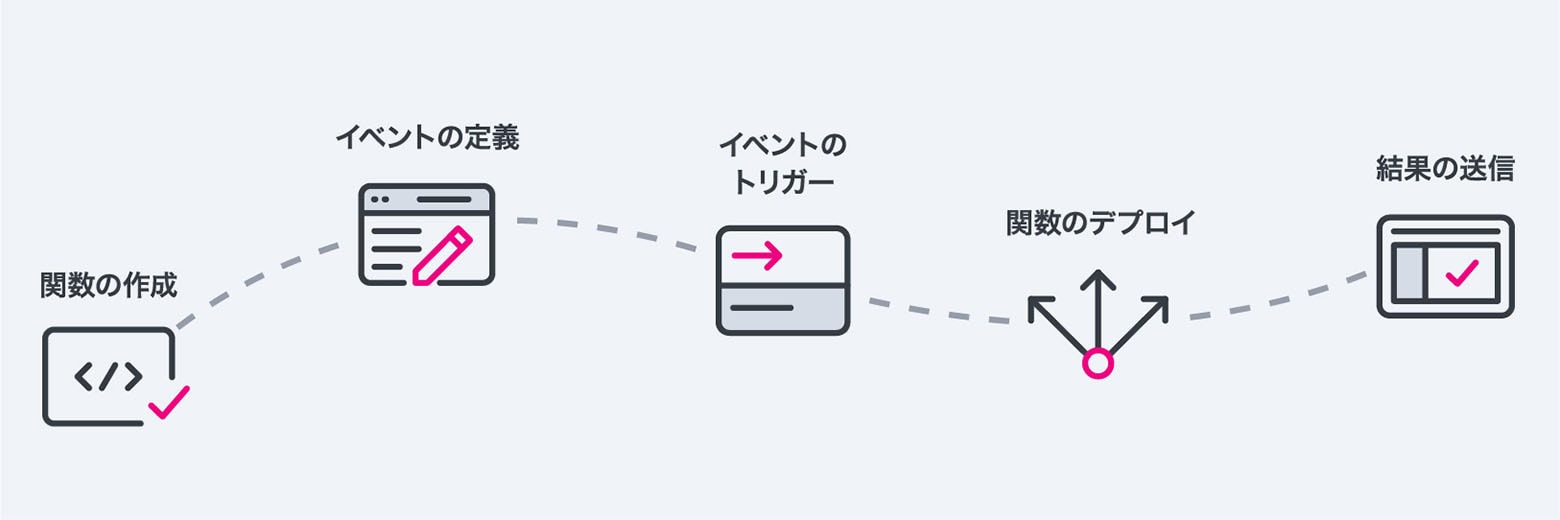
サーバーレス関数の一般的なプロセス
クラウドサービスプロバイダーは、関数の実行だけでなく、リソースの割り当ても行います。たとえば200件のリクエストが同時に発生した場合は、クラウドプラットフォームによって200以上のインスタンスが用意されます。同時リクエスト数が50件に減ると、インスタンス数もそれに応じて減らされます。クラウドサービスを利用する組織は、関数実行のために実際に使用されたリソース分のみの料金を支払うことになります。
サーバーレスフレームワークは柔軟性が非常に高く、アプリケーションに関する幅広い問題に対応できます。一般的なユースケースには以下のものがあります。
サーバーレス関数のユースケースはほかにもたくさんありますが、どのような目的に使用できるかは大体おわかりいただけたと思います。サーバーレスは拡張性にも優れているので、サーバーレス関数は今後登場するほぼあらゆる用途に対応できると考えてよいでしょう。

サーバーレス関数を使用すれば、IoTセンサーのデータのフィルタリング、ログの収集、応答を自動化できます。
サーバーレス関数を使用することにはいくつかの大きなメリットがあります。サーバーレス関数を使用すれば、開発者はアプリケーションの機能向上とコードの品質改善に集中することができます。コードのデプロイやスケーリングなどのインフラの定型的な管理作業は、サーバーレスプロバイダーが行ってくれるためです。組織全体でも、コンピューティングリソースの料金は使用した分だけ支払えばよいため、物理ハードウェアに対する過剰なプロビジョニングや、使用していないクラウドインスタンスの支払いが発生する心配もなく、コストを節約できます。
以下に示すように、多くのメリットがあります。
インフラの管理が不要:ハードウェアとソフトウェアを管理する大きな負担をサーバーレスプロバイダーに引き受けてもらうことができるため、開発者はその分コーディングに時間をかけて、アプリケーションの品質を向上させることができます。
多言語での開発:通常、アプリケーションを開発するときはチーム内でプログラミング言語を統一しますが、一部のメンバーがその言語に不慣れな場合もあるでしょう。サーバーレス関数なら、メンバーそれぞれが好きな言語やフレームワークを使ってコードを記述できます。
バックエンドコードのシンプル化:サーバーレスなら、1つの機能を独立して実行する自己完結型のシンプルな関数を作成すればよいため、複雑なコードを書く負担を解消できます。
コストの削減:サーバーレスプラットフォームの利用料はリクエスト量に応じて課金されるため、関数の実行に使用されたリソース分のみの料金を支払えばよく、高いコスト効果が得られます。CPUのアイドル時間や未使用の領域には料金が発生しないため、全体としてコストを大幅に節約できます。
容易なスケーリング:サーバーレスでは需要に応じて関数が自動的にスケールアップ/ダウンされるため、キャパシティ管理の手間はほとんどかかりません。また、従量課金のため、過剰または不十分なプロビジョニングによるコストを心配したり、ベンダーロックインによるコストの高止まりに悩まされたりすることもありません。
コードの削減:サーバーレスなら、開発者がコードの記述に専念できるだけでなく、管理するコードの量自体を減らすことができます。
Webアプリケーションフレームワークの知識が不要:サーバーレス関数を使用する場合は、サーバーの管理が不要で、新しいアーキテクチャの仕組みや命名規則を覚えたり、リクエストパイプラインを構築したりする必要がなく、コードの実行に集中できます。
市場投入までの時間短縮:サーバーレスアーキテクチャでは、デプロイプロセスがシンプルであり、コードを断片的に追加または修正するのも簡単です。そのため、アプリケーションのバグ修正や新機能の追加をすばやく行えます。
サーバーレス関数の問題を調査するには、サードパーティのサーバーレス監視ソリューションが必要です。サーバーレスプラットフォームではそれぞれ独自の監視ソリューションが提供されていますが(AWS LambdaならCloudWatchなど)、通常、これらのソリューションでは関数が問題の兆候を示し始めたときのトラブルシューティングに必要なメトリクスは収集されません。
サーバーレス監視ソリューションやオブザーバビリティツールは、以下の点について関数レベルでの重要なメトリクスを収集できます。
アプリケーションのパフォーマンスが最適な状態に保たれているかどうかを確認するには、アプリケーションが生成するメトリクスを監視します。これはサーバーレス関数でも同じです。
個々の関数に問題があると、アプリケーション全体に影響が及び、パフォーマンスの低下やダウンタイムにつながります。そのため、サーバーレス関数のエラーや障害を監視することは非常に重要です。サーバーレス関数の場合、トラブルシューティングしようとした時点で関数のインスタンスが消失している可能性があるため、完全忠実なデータを収集することが欠かせません。
サーバーレスアプリケーションの監視には、従来のアプリケーションの監視にはないさまざまな問題があります。まず、サーバーレス関数では、その管理のほとんどをアプリケーションオーナーではなくサーバーレスプロバイダーが担うため、トラブルシューティングのための情報収集が難しくなります。また、関数の実行時にのみサーバーが起動するため、エラーの追跡と特定も容易ではありません。さらに、このエフェメラルな性質によって、リソースの使用状況の追跡も困難になります。
従来の監視ツールは、サーバーレスアプリケーションの複雑さを想定していません。そこで近年は、ステートレス環境の重要なメトリクスを収集できるサーバーレス監視ソリューションが登場しています。
監視要件は、ビジネスニーズや使用するプラットフォームによってさまざまです。たとえば、AWS LambdaとMicrosoft Azureで監視すべきメトリクスには以下のものがあります。
Lambdaでは、関数が呼び出されると、関数実行のためのコンテナがAWSで起動されます。しかし関数がしばらく呼び出されずにいると、コード実行の待機状態のコンテナが破棄されることがあります。この場合、関数の実行時にコンテナの生成に数百ミリ秒から数秒の時間がかかり、アプリケーションのパフォーマンスが遅く感じられます。
そのため、この「コールドスタート」を監視することは、関数のパフォーマンスを可視化して改善策を探るために重要です。
サーバーレス監視ツールでは、以下の2つの重要なデータを追跡できる必要があります。
関数の実行時間は、イベントによって実行が開始されてから関数内の処理が終了するまでのわずかな間であるため、リソースの使用状況を把握および予測することが困難です。呼び出しに応じて関数が実行を開始してから終了するまでの時間を監視すれば、プロバイダーの利用コストを管理するために役立ちます。
関数がビジネスやカスタマーエクスペリエンスの向上にどのくらい貢献しているかを知るためのメトリクスを監視することも重要です。たとえば、ユーザーリクエストの総数や地域ごとの売上などがあります。
以下のベストプラクティスを実践すれば、サーバーレスアーキテクチャを最大限に活用できます。
サーバーレス関数を導入するための第一歩は、サーバーレスプラットフォームプロバイダーのアカウントを作成することです。人気があるのはAWS Lambda、Google Cloud Functions、Microsoft Azure Serverless Computing/Azure Functions Serverless Computeですが、ほかにもたくさんのプロバイダーがあります。プロバイダーを選ぶときは、開発予定のソフトウェアのタイプや組織の目標など、さまざまな要因を考慮します。クラウドへの移行が進んでいる場合よりも、レガシーアプリケーションをサーバーレス化する場合の方が、幅広い選択肢があります。
技術的な要件についても検討する必要があります。たとえば、サポートされる言語やデプロイ、依存関係の管理、永続的ストレージリソース、トリガーのタイプなどです。これらのサポート状況はプラットフォームによって異なるため、適切なプロバイダーを選べるようによく調べておくことが重要です。
プラットフォームが決まって登録が完了したら、開発予定の中でできるだけシンプルな関数を最初に実装します。主要なプロバイダーはチュートリアルを提供しているので、サーバーレス環境やプラットフォームの仕様を学んでおくとよいでしょう。
クラウドプラットフォームを利用する前に、ローカル環境でサーバーレスコードを実行する方法もいくつかあります。たとえば、AWS Serverless Application Model (AWS SAM)には、Lambdaのコードをオフラインでテストするための機能があります。
サーバーレス関数を導入すれば、インフラ管理の負担を軽減して、開発者が最も重要な仕事、つまり優れたアプリケーションの開発に集中できるようになります。組織全体にも、複雑さの解消、コストの低減、俊敏性の向上といったメリットがあります。サーバーレス関数を導入することで新たな課題も生まれますが、適切なプラットフォームと適切なサーバーレス監視ツールを組み合わせれば、この革新的なテクノロジーがもたらすメリットを余すところなく享受できます。
このブログはこちらの英語ブログの翻訳です。
この記事について誤りがある場合やご提案がございましたら、ssg-blogs@splunk.comまでメールでお知らせください。
この記事は必ずしもSplunkの姿勢、戦略、見解を代弁するものではなく、いただいたご連絡に必ず返信をさせていただくものではございません。

Splunkプラットフォームは、データを行動へとつなげる際に立ちはだかる障壁を取り除いて、オブザーバビリティチーム、IT運用チーム、セキュリティチームの能力を引き出し、組織のセキュリティ、レジリエンス(回復力)、イノベーションを強化します。
Splunkは、2003年に設立され、世界の21の地域で事業を展開し、7,500人以上の従業員が働くグローバル企業です。取得した特許数は1,020を超え、あらゆる環境間でデータを共有できるオープンで拡張性の高いプラットフォームを提供しています。Splunkプラットフォームを使用すれば、組織内のすべてのサービス間通信やビジネスプロセスをエンドツーエンドで可視化し、コンテキストに基づいて状況を把握できます。Splunkなら、強力なデータ基盤の構築が可能です。

© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
