

最先端のオブザーバビリティプラクティスの構築
IT運用チームとエンジニアリングチームのためのSplunkを活用したデジタルレジリエンスの強化方法をご紹介します。

オブザーバビリティのスタートはアプリケーションやインフラストラクチャの状態の可視化から、というのが一般的ですが、更に広げるとDevOpsの中のCI/CDサイクル自体も可視化・分析する事が可能です。Jenkinsに代表されるCI/CDツールも一つのシステムですので、データを取得し可視化や分析ができます。SplunkではJenkins用のインテグレーションを用意しており、Open Telemetry Collectorによるデータの取得とSplunk Observability Cloudに用意されたダッシュボードの利用で、誰でも簡単にCI/CDサイクル内に何が起きているかを明確にすることが可能になります。そして、そのJenkinsに対する高いオブザーバビリティはCI/CDサイクル自体の改善にもつながる重要なインサイトを与えてくれることになるでしょう。
クラウドネイティブな時代において、システムは常に変化し成長し続けるものですが、その変化や成長を支えるのがCI/CDのサイクルとも言えます。その意味においては、CI/CDサイクルの健全性を把握し、改善につなげられるようにする事は開発の効率性の向上にもつながる非常に重要な事だと考えられます。
以下「Jenkins, OpenTelemetry, Observability」の抄訳になりますが、これからDevOpsを計画しCI/CDツールを検討される日本のお客様にも役に立つ内容になっています。ぜひSplunk Observability Cloudでの高いオブザーバビリティがあるCI/CD環境を構築できるようご検討ください。
今日、多くの組織がJenkinsを使用しています。その用途は、デプロイのパイプライン構築から、APIの自動テスト、cronジョブの代替まで、多岐にわたります。
Jenkins(ジェンキンス)とは、Javaで作られているオープンソースのCI (継続的インテグレーション(CI)や継続的デリバリー(CD))ツールです。プラグイン機能が充実していることが特徴のひとつです。現在のところ2000近くのプラグインが提供されています。また、Jenkinsは汎用性が非常に高いことから、今後に期待されるCIツールです。
Jenkinsは、「ソフトウェアのリリーススピードの向上」「開発プロセスの自動化」「開発コストの削減」といった目的とするオープンソースのツールです。現在、プロジェクトはLinux Foundationによって管理されています。
現在のJenkinsでのトレーシングとAPMは、OpenTelemetryプロジェクトの取り組みとOpenTelemetry Jenkinsプラグイン(保守管理者:Cyrille Le Clerc氏)の登場によってかなり容易になっています。設定が完了すれば、Jenkinsジョブからワンクリックで、パイプライン全体の実行状況を示す詳細なウォーターフォール図を表示できます。
OpenTelemetry (OTEL)、Jenkins、Splunk APMの能力を組み合わせれば、粒度の高い分散トレーシングを実現して、以前は把握が難しかったJenkinsの使用状況を詳細に監視すると同時に、データをフル活用できます。
Jenkinsで処理時間が異常に長いビルドやステップをすばやく特定できます。
JenkinsのAPMデータをSplunk Log Observer経由で送信すれば、データがAPMの対象期間を過ぎた後でも、すべてのステップの時系列メトリクスを生成して、すべてのジョブの個々のステップにかかった処理時間の増減を簡単に可視化できます。
gitのチェックアウトに平均以上の時間がかかっているか、特定のAPIのレスポンスタイムが徐々に長くなっている可能性があります。Splunk APMのTag Spotlightを使用すれば、パイプライン内での外部サービスの呼び出しにかかる時間をP50、P90、P99値で可視化して、時間がかかっている処理を特定できます。
デプロイにディテクターを設定して、ダッシュボードでイベントマーカーを表示すれば、他のチームのデプロイが自身のサービスのパフォーマンスに影響しているかどうかをすばやく確認できます。
APMや分散トレーシングは、特定のプロセス(この場合はJenkinsデプロイ)のライフサイクル全体を通じて処理の流れを把握するための強力なツールです。Jenkinsデプロイの各ステップにかかった時間が一目でわかるウォーターフォール図を参照できるだけでなく、より一般的な時系列メトリクスや従来のビルドログに取り込むことのできる追加データも提供されます。Jenkinsのトレースデータを次のような新しい方法で活用すれば、組織内のさまざまなチームが問題を解決できます。
Splunk APMなら、ツールが増加してもJenkinsに関するこれらの課題に1カ所からすばやく対応できます。複数のツールの異なるインターフェイスを行き来することなく、Jenkinsやログを管理し、データを監視して、状況を正確に把握することができます。
すばやくセットアップするには、GitHubリポジトリでOpenTelemetry Collectorの設定例、ドキュメント、2つのSplunk Observability Cloudダッシュボードのエクスポートを確認してください。これらのアーティファクトとOpenTelemetry Collectorを導入すれば、Jenkinsに関する詳細なインサイトをすぐに取得して、IT運用、CI/CD、DevOpsに役立てることができます。
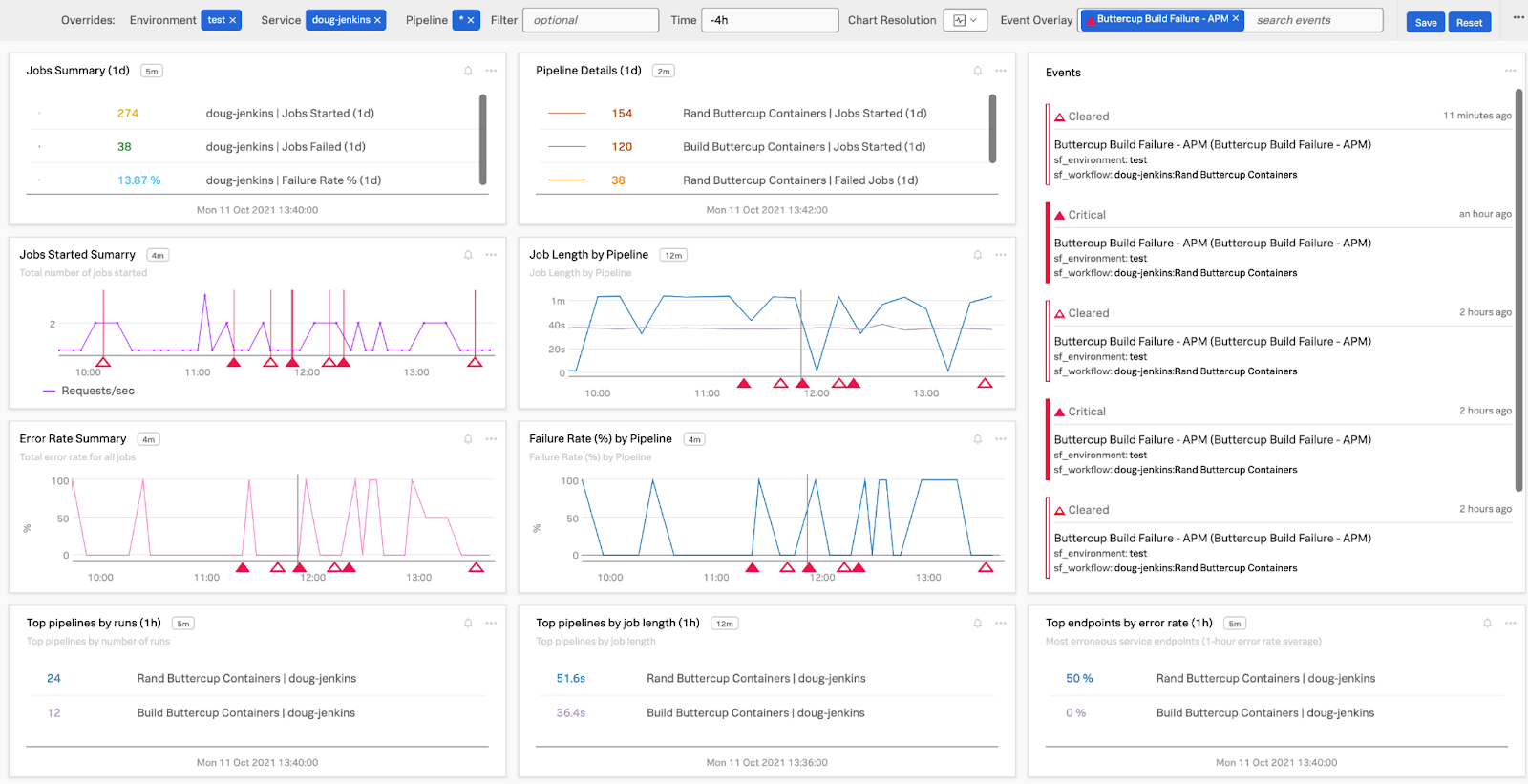
図1-1.JenkinsのAPMデータから取得したJenkinsパイプラインの詳細なメトリクス
こちらのGitHubリポジトリには、個々のJenkinsパイプラインとJenkins全体の健全性を把握するための2つのダッシュボードが用意されています。これをそのまま使用することも、カスタマイズしてより詳細なデプロイダッシュボードを作成することもできます。
このGitHubリポジトリには、デプロイの失敗を通知するようにディテクターを設定するための手順とSignalFlowの例も記載されています。このタイプのディテクターは、デプロイ自体の問題だけでなく、デプロイの失敗(または成功)によって発生した上流の依存サービスの問題を検出するためにも役立ちます。関連するイベントをダッシュボードに表示することで、ツールを新たに導入しなくても詳細なコンテキストを取得できます。
他の方法でこれだけのインサイトを取得するのは容易ではありません。
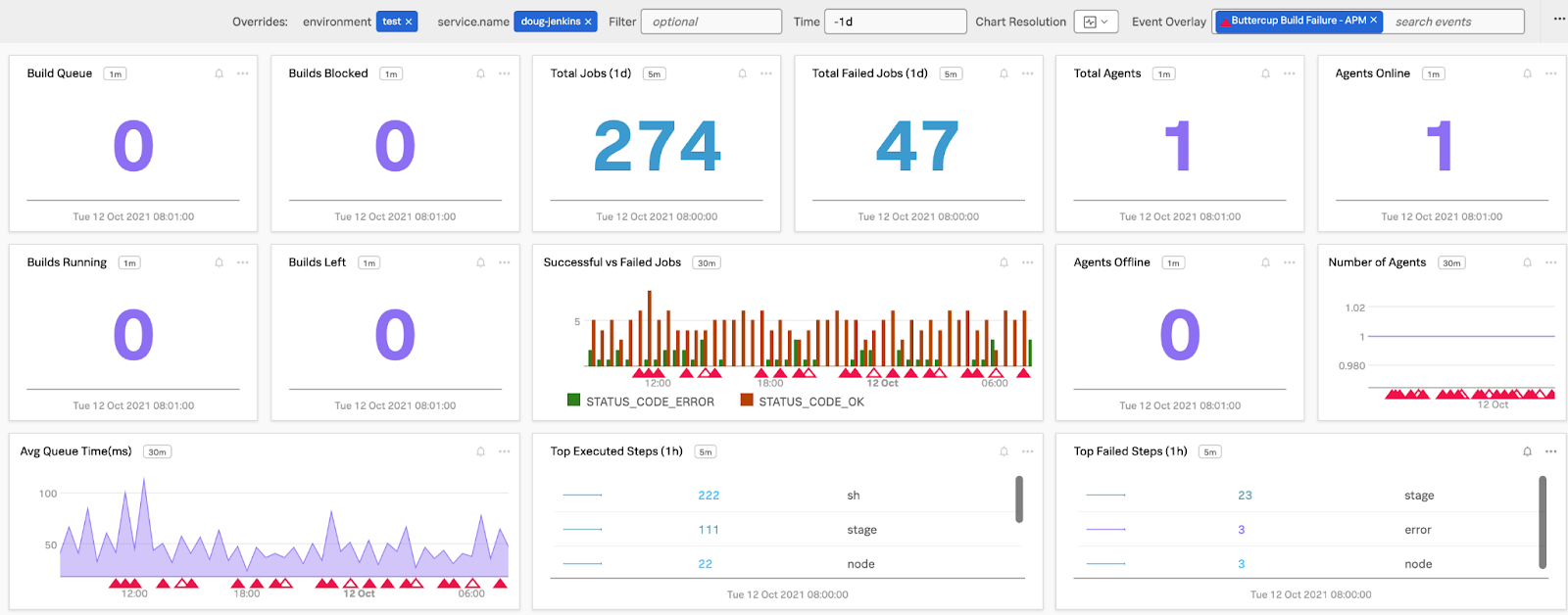
図1-2.Jenkins全体の健全性:Jenkinsの重要エージェント、ビルドキュー、ステップの詳細メトリクス(Log Observer経由)を1つの画面で監視
OpenTelemetry、APM、Infrastructure Monitoringは一体であり、ツールとして現状は別々であっても、サービスの状況を把握するためにはいずれも欠かせません。それぞれの能力を1つのツールに統合すれば、デプロイの影響やJenkinsのパフォーマンスをすばやく把握し、ソフトウェアのビルドやリリースが原因で発生したサービスの問題を各チームに迅速に伝えることができます。しかも、それだけではありません。Jenkinsについてより多くのインサイトを取得できれば、メトリクスに基づいて、組織のDevOpsプロセス全体に対する影響をより正確に把握することもできます。
DORA (DevOps Research and Assessment)メトリクスは、DevOpsのアクティビティやパフォーマンスの測定に関する基本的なニーズに対応します。Jenkinsの追加コンテキストが有用または必要な場合のDORA関連の重要なメトリクスには以下の4つがあります。
新しいJenkinsメトリクスとAPMデータをもっと活用して、パイプラインの状況を正確に把握し、デプロイを評価して、組織全体でDevOps Magic™を最大限に引き出しましょう!
Jenkinsデプロイの監視能力を短期間で高めたいなら、Splunk Observability Cloud製品スイートの無料トライアルをぜひお試しください。
このブログ記事はSplunkのオブザーバビリティフィールドソリューションエンジニアであるJeremy Hicksが執筆しました。ご協力いただいた以下の同僚に感謝申し上げます(敬称略):Doug Erkkila、Adam Schalock、Todd DeCapua、Tom Martin、Marie Duran、Joel Schoenberg
----------------------------------------------------
Thanks!
加藤 教克

Splunkプラットフォームは、データを行動へとつなげる際に立ちはだかる障壁を取り除いて、オブザーバビリティチーム、IT運用チーム、セキュリティチームの能力を引き出し、組織のセキュリティ、レジリエンス(回復力)、イノベーションを強化します。
Splunkは、2003年に設立され、世界の21の地域で事業を展開し、7,500人以上の従業員が働くグローバル企業です。取得した特許数は1,020を超え、あらゆる環境間でデータを共有できるオープンで拡張性の高いプラットフォームを提供しています。Splunkプラットフォームを使用すれば、組織内のすべてのサービス間通信やビジネスプロセスをエンドツーエンドで可視化し、コンテキストに基づいて状況を把握できます。Splunkなら、強力なデータ基盤の構築が可能です。

© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
