
最先端のオブザーバビリティプラクティスの構築
IT運用チームとエンジニアリングチームのためのSplunkを活用したデジタルレジリエンスの強化方法をご紹介します。

ITシステム、アプリケーション、ソフトウェア、ユーザーが分散する今日の環境では、すべてのやり取りで何が起きているかを詳細に知るのは容易ではありません。それを可能にするのが分散トレーシング(Distributed Tracing)です。
分散トレーシングでは、アプリケーションでユーザーやフロントエンドデバイスがリクエストを送信してからバックエンドサービスやデータベースでそのリクエストが処理されるまでの一連の流れを追跡できます。
分散トレーシングを使えば、監視対象の任意のアプリケーションでリクエストやトランザクションを追跡して、可用性の向上、問題やインシデントの解決、継続的な最適化に役立つインサイトを獲得し、最終的にユーザーエクスペリエンスやカスタマーエクスペリエンスの向上につなげることができます。
このブログ記事では、分散トレーシングと、分散トレーシングを企業に導入するためのテクノロジーについて詳しく説明します。
分散するソフトウェア環境を管理する鍵を握るのが、ログ、メトリクス、トレースです。これらを総称して「オブザーバビリティの3つの柱」と呼びます(ここにイベントを含めて「MELT」と呼ぶこともあります)。いずれも、アプリケーションとその基盤となるインフラを可視化するために欠かせないデータソースです。通常、これらのデータを使ったIT監視を特に「アプリケーションパフォーマンス監視(APM)」と言います。
多くのIT運用チームやサイトリライアビリティエンジニアリング(SRE)チームにとって、3つの柱のうちログとメトリクスは馴染み深いものでしょう。チームは長年、以下の目的でログとメトリクスを分析してきたはずです。
一方で、トレースはあまり馴染みがないかもしれません。
トレースは新しい概念ではありません。アプリケーションとそれを構成するサービスで処理された、特定のユーザーまたはAPIのすべてのトランザクション(スパン)をまとめたものがトレースです。
トレースは、ユーザーがアプリケーションを操作した瞬間に始まります。ユーザーが最初のリクエストを送信すると(ショッピングカートに商品を追加するなど)、そのリクエストに一意のトレースIDが割り当てられます。1つのトレースがユーザーとの1回のやり取りを表します。ホストシステムでリクエストが処理される際、そのリクエストに対して実行された各処理(スパン)にいくつかの項目がタグ付けされます。
トレースは一連のスパンで構成され、各スパンは1つの処理を表し、以下の情報がタグ付けされます。
各スパンは、リクエストの処理全体の中の個々の処理を表します。そのため、各スパンには操作を実行するサービスに関する重要な情報が含まれます。たとえば以下のものがあります。
モノリシックアプリケーションを開発、管理するチームでも、アプリケーションの以下のようなパフォーマンス調査で以前からトレースを使用しているでしょう。
トレーシングの基本的な目的は常に、トランザクションを理解することです。ただし、その方法は変化しています。マイクロサービスのような分散型のソフトウェアアーキテクチャ上に構築されたアプリケーションでは、以前のやり方では十分な情報が得られません。
まずは、従来のトレーシングの概要、仕組み、今日のアプリケーション環境に適さない理由について見ていきましょう。
古くから使われているモノリシックアーキテクチャのアプリケーションでは、トレーシングは可能ですが、あまり必要とされません。アプリケーションでリクエストを処理する過程で変動要素が少なく、トレースする対象がほとんどないためです。
トレーシングツールは存在しますが、これらのツールでは確率的サンプリングが使われます。この手法では、すべてのトランザクションの中から少数のトランザクションが無作為に選ばれ、その分析結果から、処理に関するインサイトが抽出されます。そのため、インサイトが限定されます。対象がすべてのトランザクションではなく一部に絞られるため、処理状況を完全には可視化できません。たとえば、サンプリングによるトレーシングでITチームやSREチームができるのは以下のような調査にとどまります。
このアプローチでは、パフォーマンスに関する微妙な変化は読み取れません。また、増減のあるコンテナ環境で運用される多数の分散サービスを測定するうえで求められる拡張性もありません。そのため、以下のような問題が起こります。
(特に、分散システムの「エフェメラル(一時的)」という特性の下では、従来のトレーシングの欠点がすぐに露呈します。本質的な問題についてアラートされず、トラブルシューティングが阻害される可能性があります。たとえば、EC2ノードで障害が発生し、別のノードに処理が引き継がれた場合を考えてみましょう。その影響を受けたのが1件のユーザーリクエストのみであった場合、アラートするほどの問題ではないと判断されるはずです。その結果、大規模な障害に発展するまでチームが問題に気づかない可能性があります。)
静的でモノリシックな環境であれば、これでも問題ないかもしれません。しかし、今日一般的な環境はずっと複雑で、絶えず変化します。
1回のユーザートランザクションには数十や数百のマイクロサービスが関わり、そのそれぞれがバックエンドのデータストアにデータを要求したり、APIを介して互いに通信したり、インフラの他の部分とやり取りしたりします(ソフトウェアを使用するソフトウェアと考えてもよいでしょう)。
設計として、マイクロサービスは互いに独立してスケーリングします。そのため、1つのサービスの複数のインスタンスが異なる場所の異なる環境にある異なるサーバーで同時に実行されることもよくあります。しかも、各マイクロサービスは通常、以下の要素で構成される多層のスタックで実行されます。
この場合、トランザクションをサンプリングし単体のコードのみに注目する従来の監視では不十分です。クモの巣のように張り巡らされたマイクロサービスでのリクエストの流れを理解するには、以下のような補足データを収集する必要があります。
トレースがさまざまなサービスに分散するため、このようにスパンにタグを付けてスパンを相互に関連付ける必要があります。このプロセスを「分散トレーシング」と呼びます。
数百万人のユーザーがプレイする人気のオンラインビデオゲームを想像してみてください。このゲームでは、各プレイヤーの位置、プレイヤー同士のやり取り、各プレイヤーがゲーム内で獲得したアイテムなど、プレイの中で生成されるさまざまなデータを常に把握する必要があります。従来のトレーシング方法では、ゲームを円滑に進行させるのはまず無理でしょう。しかし、分散トレーシングなら可能です。
分散トレーシングでは、マイクロサービスアーキテクチャ内の複数のサービス間を移動するリクエスト(トランザクション)の経路が記録されるため、その経路をたどってサービスのリクエスト元(ユーザー向けのフロントエンドアプリケーション)を特定できます。
分散トレーシングの例として、多数のマイクロサービスで構成される今日の標準的なアプリケーションについて考えてみましょう。
この場合、分散トレースは、最初のフロントエンドサービスでリクエストの状態に関する情報(ユーザーが入力したデータと、そのデータを他のサービスに転送するのにかかった時間)を記録することから始まります。
次の記録ポイントは、入力データを受け取って、ETL (最近ではELT)など、必要なデータ処理を実行するバックエンドサービスです。処理が完了すると、そのデータがバックエンドサービスからデータベースサービスに送られ、保存されます。
シンプルなクライアント/サーバーアプリケーションを例にします。
クライアントから見ると1つのアクションが発生しています。クライアントはリクエストを送信して応答を得ているだけです。しかし、このクライアントリクエストの結果として複数のサーバーリクエストが生成され、それぞれが1つのスパンになります。さらにこのアプリケーションでクライアントがサーバーと複数回やり取りすると、さらに多くのスパンが生成されます。これらのスパンを相互に関連付けるために、トレースコンテキストが使われます。
トレースコンテキストによって複数のスパンが1つにまとめられます。この例では以下のスパンが含まれます。
重要なのは、トレースコンテキストが常に同じであることです。これによって、複数のスパンが結び付けられ、各スパンが同じトランザクションに属することをインフラが認識できます。
分散トレーシングツールは、すべてのスパンのデータを相互に関連付けた後、その結果を視覚的な情報にまとめて、以下の方法で提供します。
トレースを収集するには、まずアプリーションのインストルメンテーション(計装)を行う必要があります。それには、OpenTelemetryなど、トレースを生成してアプリケーションのパフォーマンスを測定するためのフレームワークを使用します。収集した情報は非常に役立ちます。たとえば、この情報に基づいてボトルネックをすばやく簡単に特定できます。
OpenTelemetryのような、ベンダーに依存しないフレームワークを使用すれば、インストルメンテーション作業は1回で済みます。
アプリケーションのインストルメンテーションが完了したら、コレクターを使ってテレメトリを収集します。
そのための優れたツールの1つがSplunk OpenTelemetry Collectorです。このコレクターでは、アプリケーションテレメトリの受信から、処理、分析ツールへのエクスポートまでを一元的に行うことができます。たとえば、分析ツールとしてSplunk APMを使えば以下のことができます。
通常、アプリケーションエラーの根本原因になっているマイクロサービスを特定するのは容易ではありません。Splunkなら、原因を特定するだけでなく、情報をさらに掘り下げて、問題のあるサービスのバージョンを確認することもできます。
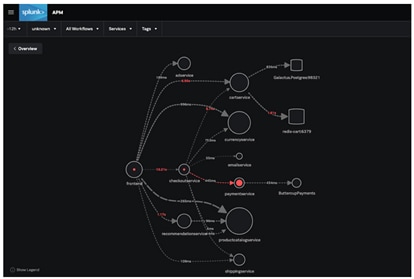
分散トレーシングの主なメリットは、実際のユーザーのトランザクションを1カ所で可視化できることです。環境がどれだけ複雑であっても問題ありません。この包括的なアプローチには以下のメリットもあります。
すべてのサービスについてリクエストの状態やパフォーマンスの状況を監視することで、パフォーマンスの問題の原因をピンポイントで特定できます。個々のサービスの中で具体的にどのような問題が起きているかを詳しく追跡することもできます。たとえば、以下のような原因を特定できます。
マイクロサービスアーキテクチャにはそもそも相互のまとまりがないため、モノリシックアプリケーションと比べて、パフォーマンスの問題の追跡や解決を含むアプリケーションパフォーマンス監視に時間もコストもかかります。
また、マイクロサービス内での障害データの配信方法もわかりやすいとはいいがたく、開発者がエラーメッセージや難解なステータスコードから問題を読み解かなければならないことも少なくありません。分散トレーシングなら、分散システムを包括的に可視化して、以下のように生産性を向上できます。
これにより、最終的にMTTR (平均復旧/修復時間)を短縮できます。
マイクロサービス環境では、通常、プロセスごとに担当チームが決まっています。そのため、エラーを特定してどのチームが修復を担当すべきかを判断するのが難しくなりがちです。分散トレーシングは以下の点で役立ちます。
分散トレーシングツールは、さまざまなアプリケーションやプログラミング言語に対応しているため、ほぼあらゆるシステムに組み込むことができ、1つのトレーシングアプリケーションでデータを包括的に把握できます。
Splunkの分散トレーシングツール:Splunk APMについてはこちらからご覧ください。
コードトレーシングとは、アプリケーション内の各コード行の結果を解釈し、その影響を記録するプロセスを(自動で実行するデバッガではなく)プログラマーが手作業で行って、プログラムの実行をトレースすることを言います。
トレーシングするのが小さなコードブロックの場合は、わずかな編集の影響を特定するためにプログラム全体を実行しなくて済むため、手作業の方が効率的なことがあります。
データトレーシングは、重要なデータ要素(CDE:Critical Data Element)の正確さやデータ品質を確認したり、ソースシステムに遡ってトレースしたり、統計的手法を使って監視や管理を行うのに役立ちます。一般に、正確さを確認するには、操作を開始時点までトレースしてソースデータとの検証を行うのが最善です。しかし、大規模な操作プロセスの場合、この方法はコスト面で見合いません。
プログラムトレースは、「スタックトレース」とも呼ばれ、アプリケーションの実行中に実行される命令と参照されるデータのインデックスです。プログラムトレースには、プログラムの名前、言語、実行されたソースステートメントなどの情報がその他のデータとともに表示され、デバッグプロセスで使用することができます。
世界各地に分散するプログラマーが異なるプログラミング言語で作成したマイクロサービスを使用する分散アーキテクチャのアプリケーションの場合、インストルメンテーションには、ベンダーに依存しないオープンソースのフレームワークが役立ちます。
ほとんどのフレームワークでは手動でのインストルメンテーションが必須ですが、OpenTelemetryは、多くの言語で自動インストルメンテーションが可能です。
JaegerとZipkinは、どちらも人気のあるオープンソースのリクエストトレーシングツールで、コンポーネント(コレクター、データストア、クエリーAPI、Webユーザーインターフェイス)にあまり違いはありません。
どちらも、アプリケーションと連動して送信リクエストをトレースし、続いてコレクターがさまざまなトレースのデータを記録して相互に関連付け、データベースに送信します。ユーザーは、データベースに保存されたデータに対して、クエリーや分析を実行できます。
JaegerとZipkinは、アーキテクチャとサポートするプログラミング言語が違います。JaegerはGoで、ZipkinはJavaで実装されています。Zipkinは、ほぼあらゆるプログラミング言語をサポートし、Java、Javascript、C、C++、C#、Python、Go、Scalaやその他の言語向けの専用ライブラリがあります。Jaegerは、サポートする言語がZipkinよりも少なく、C#、Java、Node.js、Python、Goをサポートしています。
Kafkaは、リアルタイムのデータフィードを処理する、高スループットかつ低レイテンシーな分散イベントストリーミングプラットフォームで、マイクロサービスアーキテクチャでよく使われます。Kafkaでは以下のことができます。
Kafkaは、「トピック(レコードがパブリッシュされる先のカテゴリ(フィード名))」を使用してレコードのストリームを抽象化します。また、トピックごとにパーティション分割されたログを維持しています。パーティションは、継続的に追加されるレコードのシーケンスで、順番が付けられており、分散システムの外部コミットログとして機能します。
今日、クラウドベースアプリケーションでマイクロサービスを使用するのが当たり前になっています。分散リクエストトレーシングは、サービスを中断する可能性のある問題を特定するために、従来の干し草の山の中に埋もれた針を探すようなアプローチよりもはるかに優れた機能を提供します。
このパワフルなテクノロジーを導入すれば、マイクロサービスベースのシステムの管理作業を大幅に効率化できます。Splunk Observabilityは分散トレーシングに対応しています。無料のトライアル版で、トレーシングテレメトリをリアルタイムで可視化して問題をすばやく解決するメリットをぜひ実感してください。
このブログはこちらの英語ブログの翻訳です。
この記事について誤りがある場合やご提案がございましたら、ssg-blogs@splunk.comまでメールでお知らせください。
この記事は必ずしもSplunkの姿勢、戦略、見解を代弁するものではなく、いただいたご連絡に必ず返信をさせていただくものではございません。

Splunkプラットフォームは、データを行動へとつなげる際に立ちはだかる障壁を取り除いて、オブザーバビリティチーム、IT運用チーム、セキュリティチームの能力を引き出し、組織のセキュリティ、レジリエンス(回復力)、イノベーションを強化します。
Splunkは、2003年に設立され、世界の21の地域で事業を展開し、7,500人以上の従業員が働くグローバル企業です。取得した特許数は1,020を超え、あらゆる環境間でデータを共有できるオープンで拡張性の高いプラットフォームを提供しています。Splunkプラットフォームを使用すれば、組織内のすべてのサービス間通信やビジネスプロセスをエンドツーエンドで可視化し、コンテキストに基づいて状況を把握できます。Splunkなら、強力なデータ基盤の構築が可能です。

© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
