
最先端のオブザーバビリティプラクティスの構築
IT運用チームとエンジニアリングチームのためのSplunkを活用したデジタルレジリエンスの強化方法をご紹介します。

可用性とは、デバイスやサービスなどのITインフラが使用可能である時間、あるいはその利用可能性を意味する言葉です。システムの可用性は、システムが正常に動作しているかどうか、クラッシュや攻撃などの障害からどれだけ効果的に回復できるかを示すものであり、IT管理の最も重要な指標の1つと考えられているため、絶えず監視することが求められます。不可欠なハードウェアやサービスが1つでも利用できなくなれば、ビジネス全体が成り立たなくなってしまうかもしれません。
可用性はさまざまなビジネスプロセスや内外の要因の影響を受ける可能性があるため、その確保には困難が伴います。DoS攻撃、ハードウェアやITサービスの障害、さらには自然災害まで、あらゆるものが可用性に影響を与え、平均修復時間(MTTR)を引き延ばす可能性があります。サードパーティのサービスプロバイダーの共有クラウドサーバーに問題が生じた場合、ダウンストリームに連鎖して別の組織の可用性に影響するかもしれません。また、どのようなIT環境でも、多数のデバイスやサービスが相互に作用しており、1つのデバイスやサービスに発生した問題が、大規模な障害を引き起こす恐れがあります。たとえば、重要なデータベースが破損した場合、基盤となるハードウェア、オペレーティングシステム、ネットワークに影響がなくても、重要なWebサーバーを利用できなくなることがあります。
可用性は通常、パーセントで表され、以下の計算式で求めることができます。
可用性 = (サービス時間の合計 – ダウンタイム) / (サービス時間の合計)
この指標は、具体的な時間の単位で表すこともできます。たとえば、サーバーXの前月の目標の可用性(または約束された可用性)が99.999%(業界では「ファイブナイン」と呼ばれる)であったとすると、そのサーバーの最大ダウンタイムは1カ月あたり26秒となります。
この記事では、企業がさまざまな運用環境でどのようにすれば可用性を高めることができるのか、そしてそのメリットやコストについて考察します。
Splunk IT Service Intelligence (ITSI)は、顧客に影響が及ぶ前にインシデントを予測して対応するための、AIOps、分析、IT管理ソリューションです。

AIと機械学習を活用して、監視対象のさまざまなソースから収集したデータを相関付け、関連するITサービスやビジネスサービスの状況を1つの画面にリアルタイムで表示します。これにより、アラートのノイズを低減し、障害を未然に防ぐことができます。
高可用性を実現できるのは、システムが卓越した可用性、つまり優れたアップタイム、フォールトトレランス、レジリエンスを備えている場合です。
高可用性とは、通常、サービスにほとんど障害が発生しない状態を意味します。GoogleやAmazonといった大手のWebサイトは、ダウンタイムがまったくないわけではありませんが、信頼性が非常に高く、他のサービスの高可用性の基準となっています。このレベルの可用性を実現するには、広範囲で複雑かつ非常にコストのかかる一連のテクノロジーが必要です。電力、ガス、水道などの公益事業、航空機のフライトシステムのコンポーネント、病院の手術室で使われる機器なども高可用性の代表的な実例です。
高可用性は応答性にも関係しています。サービスが稼動していても、動作が遅くてエンドユーザーに不満を抱かせるようでは、可用性が疑問視されるかもしれません。可用性は、アップタイムを2つの状態(サービスがオンラインかオフラインか)のいずれかとして考える上記の式でも正式に測定することはできますが、応答時間やエラー率などの関連するメトリクスと併せて考えると、より正確に評価できるようになります。
真の高可用性の絶対的基準として広く知られているのが99.999%の可用性であり、これは一般に「ファイブナイン」と呼ばれています。前述の通り、99.999%の可用性は、ダウンタイムが1カ月あたり26秒、つまり1年あたり5.5分であることを意味します。停電後にコンピューターを再起動する際のダウンタイムを考えれば、ファイブナインの可用性を達成することがいかに困難であるかがわかります。
高可用性を実現するには、それを目的として設計されたテクノロジーを使用する必要があります。コンピューティングシステムでは、以下のような戦術とツールによって高可用性を実現します。
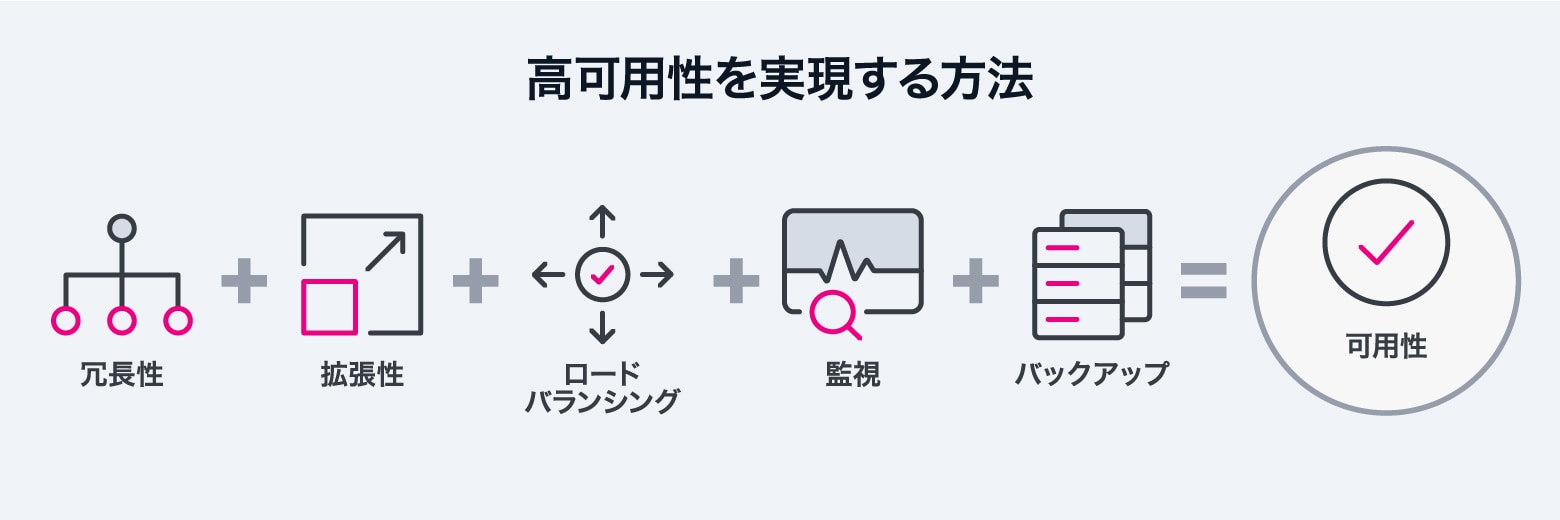
高可用性を実現するためには、すべてのシステムをスムーズかつ最適に動作させるための多くのツールが必要です。
高可用性とフォールトトレランスは密接に関係していますが、1つだけ大きな違いがあります。ダウンタイムが非常に少ないのが高可用性システムであるのに対し、ダウンタイムがゼロになるように設計されているのがフォールトトレラントシステムです。ダウンタイムをゼロにすることは可能ですが、そのためには極めて高いコストがかかり、複雑さも増します。フォールトトレラントシステムには、ハードウェアコンポーネントやソフトウェアコードなど、インフラ各部の障害に耐えられるような特別な設計が施されています。
通常、フォールトトレランスが実装されるのは大規模なクラウド環境です。たとえば、アマゾン ウェブ サービス(AWS)、Azure、Google Cloudはすべて、複数のアベイラビリティーゾーン(データセンターが存在する地理的地域)で運用されています。複数のアベイラビリティーゾーンで同時にオペレーションを実行することで、フォールトトレラントなアプリケーションを設計できます。これにより、1つのゾーンで問題が発生しても、他の複数のゾーンでそれを補完できます。これは、多くの高可用性サービスで採用されている方法に似ていますが、さらに複雑です。高可用性設計では、アプリケーションのセカンダリコピーが削除され、そのために、たとえばサーバーのプライマリインスタンスがオフラインのときにアプリケーションへの書き込みが制限されることがありますが、フォールトトレラントシステムではそのようなことはありません。場合によっては、使用されているすべてのデータベースの正確なリアルタイムコピーなど、アプリケーションの正確なコピーをすべてのアベイラビリティーゾーンで同時に実行する必要があります。
とはいえ、どれだけしっかりと設計されたシステムでも、完全なフォールトトレランスを実現するには非常に高額な投資が必要になります。そのため最大手のサービスプロバイダーであってもそこまでの投資を行っていない場合もあります。
高可用性とフォールトトレランスのどちらを実装するかは、多くの場合、コストとシステムの重要性の問題に行き着きます。ダウンタイムが1カ月に26秒などというレベルを実現できるでしょうか。より現実的な目標は、スリーナイン、つまり1カ月に45分程度かもしれません。1カ月に26秒のダウンタイムであれば、どのような状況であっても許容できるのでしょうか。このダウンタイムを回避することに、クラウドサービスのコストを大幅に増やす価値があるでしょうか。また、ダウンタイムがいつ発生するかという問題もあります。ユーザーが特定の地域に集中している場合、利用されていない時間帯であってもアプリケーションがダウンしたと見なすべきでしょうか。これらの質問に対する答えは、問題となるアプリケーションと、各企業固有のリスクレベルによって異なります。
高可用性は、クラウドコンピューティングの強みです。クラウドではリソースがより流動的なため、冗長性とロードバランシング機能を備えるシステムを容易に設計でき、コストも抑えられます。クラウド運用では、クラスターと呼ばれる設計によってこれを実現します。クラスターとは基本的に仮想サーバーのグループであり、それぞれに本番環境のコピーが含まれています。クラスターは、ロードバランシング機能とフェイルオーバー機能を提供することに特化して設計されています。1つのサーバーのアプリケーションに障害が発生しても、クラスター内の他のサーバーが即座にそれを補完します。高負荷環境では、1つのクラスター内で数十、あるいは数百のサーバーが実行されることもあります。
クラウドシステムには、統合されたロードバランシング機能、サービスに負荷がかかった場合のシームレスな拡張性、データバックアップシステムなど、高可用性の実現に欠かせない他の多くの機能も含まれています。多くの場合、クラウドプロバイダーはこれらをすぐに利用できる構成オプションとして提供しています。通常、指定した可用性レベルはクラウドサービスプロバイダーのサービスレベル契約(SLA)に組み込まれ、可用性がSLAで指定されたレベルを下回った場合、顧客には返金を受ける権利があります。ただし、契約書をよく読み、サービスプロバイダーが「下回る」の定義をどのように解釈しているのかを理解しておきましょう。
物理インフラやエンタープライズアーキテクチャでは、ロードバランシング機能とフェイルオーバー機能を提供することに特化して設計されたソフトウェアや冗長ハードウェアを利用して高可用性を実現できます。ストレージシステムは、1台のハードドライブに障害が発生してもストレージが正常に動作し続けるように、ミラー化されたドライブやRAIDアレイを使用して高可用性を実現するよう設計できます。電源と冷却システムを冗長化しておけば、プライマリユニットに障害が発生した場合でも他のユニットに引き継がせることができます。無停電電源装置(UPS)システムと発電機は、停電時のバックアップ電源として利用できます。
クラウドの場合と同様に、クラスタリングとロードバランシングをオンプレミス環境で実現することもできますが、コストは大幅に高くなります。この場合、それぞれにデータベースのコピーやアプリケーションなどの必要なソフトウェアが含まれる複数のサーバー(クラスターとも呼ばれる)が並行して実行されます。ロードバランシングハードウェア(またはソフトウェア)は、受信したリクエストをクラスター内の最も可用性の高いサーバーに転送し、これらのリクエストをできるだけ均等に分散させます。これにより、1台のサーバーに負荷をかけすぎることなく、リクエストを最高速度で処理できるようになります。何らかの理由でサーバーが利用できなくなった場合、ロードバランサーはそのサーバーを自動的にローテーションから外し、修復が終わるまで残りのデバイスにリクエストを分散させます。
ネットワーキングにおける高可用性とは、ネットワークインフラがオンラインで稼動し続ける状態にあることを意味します。ネットワークの可用性は、オンプレミスかクラウドかに関係なく、ユーザーとすべてのリソースとを結ぶ物理的な生命線であるため極めて重要です。他の可用性と同様に、ネットワークの可用性も、冗長性、ロードバランシング、拡張性を可能にするシステムを活用することで実現できます。
高可用性ネットワーク設計の中心となるのは、企業内の冗長ネットワーキングハードウェアと、複数のISPを使用することです。簡単な例で説明すると、2台のルーターを使用して2つの異なるISPに接続することで、4通りの組み合わせが実現します(ルーターAとISP A、ルーターAとISP B、ルーターBとISP A、ルーターBとISP B)。これにより、ルーターが1台故障し、1つのISPに障害が発生しても、ネットワーク接続が途切れることはありません。これは非常に基本的な例であり、企業の規模が拡大し、信頼性へのニーズが高まるにつれ、高可用性トポロジーは非常に複雑になる可能性があります(たとえば、先ほどの例が、2つのISPと4台のルーター、4つのISPと8台のルーターのようになることが考えられます)。また、バックアップの接続方法を検討することも必要です。すべての接続が脆弱で被害を受けやすい単一の中継点を経由しているとしたら、ISPが1つであろうと10個であろうとリスクは同じです。
高可用性には、以下のようなさまざまなメリットがあります。
高可用性の実現を困難にしたり、実装後の維持を難しくしたりするような障壁がいくつかあります。たとえば、以下のような課題です。
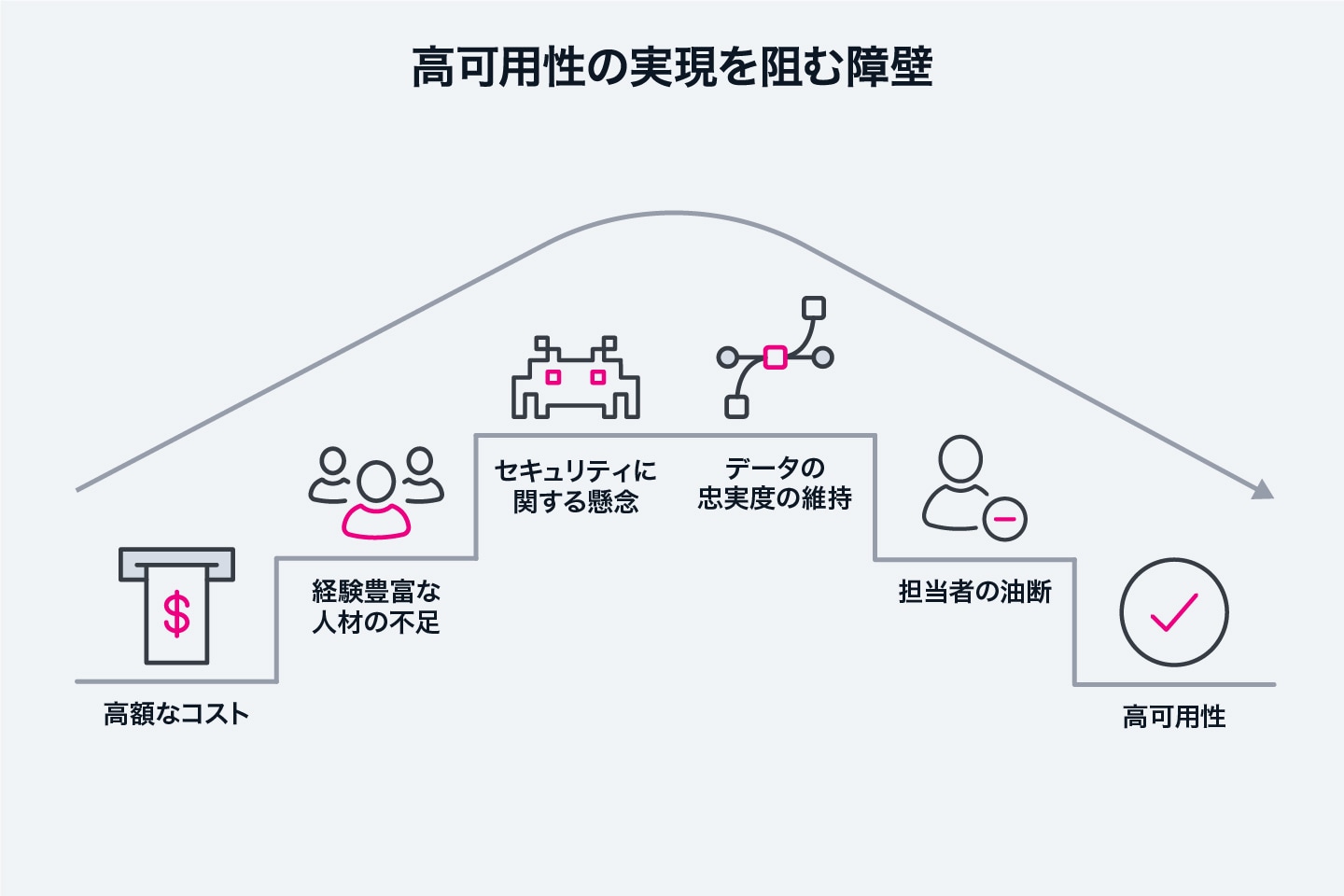
高可用性の実現を阻む障壁には、経験豊富な人材の不足や油断などの人的要因が含まれていることが少なくありません。
高可用性の実現には膨大なコストがかかることがあります。高可用性システムには、製品やサービスの直接的なコストに加えて、従来のコンピューティングシステムよりも継続的なメンテナンスや監視が必要であり、これらはすべて、組織のビジネスに大きな影響を与える可能性があります。
必要なコストに対して、稼動率の向上は十分に達成できているでしょうか。最終的には、これはリスクとメリットのバランスです。企業はダウンタイムによって生じるコストの総額を把握し、ダウンタイムをなくすためのコストと比較する必要があります。ダウンタイムの発生を防ぐために高可用性サービスを提供するコストが、オフラインになることで生じるコスト(売上損失など)を上回る場合、高可用性に投資する価値はないかもしれません。しかしこのような場合でも、一定程度の高可用性を提供するためにコストを投じる価値はあるでしょう。たとえばファイブナインではなくフォーナインに高可用性のレベルを下げて投資するという選択もあります。
可用性監視とは、オンプレミスとクラウドのどちらで運用しているかに関係なく、重要なテクノロジーシステムの稼動状況を監視することを指します。ごくシンプルな可用性監視ツールでは、指定されたスケジュールに従ってサービスに対して定期的にポーリングし、応答があることを確認することで、システムの現在の稼動状況が報告されます。高度なツールでは、より複雑なテストを実行して、詳細情報の収集、世界各地からサービスにアクセスできるかどうかの確認、応答速度の測定、エラーの通知、障害の原因究明などを行うこともできます。可用性監視では、リアルタイム性と予測性が重要です。この両方を備えたツールを使えば、問題にすばやく対応して、大きな事態に発展するのを防ぐことができます。
可用性監視は、可用性管理の一部です。可用性管理とは、ITサービスを、計画から、実装、運用、レポート作成まで包括的に監視および管理するためのITプロセスを指します。可用性が低いと、組織全体に大きな影響が及び、多くの場合、収益や利益、顧客満足度、評判の低下といった損害につながります。高い可用性を維持するためのベストプラクティスとしては、組織レベルの障害を引き起こす可能性のある主なリスク源を特定することや、ストレステストの計画を立てて定期的に実行すること、可能な限り作業を自動化することが挙げられます。
可用性監視は、可用性管理の一部です。可用性管理は、ITサービスを計画、分析、運用、監視するためのプロセスで、可用性の向上を目的とする、可用性監視よりも包括的な取り組みです。サービスの可用性を監視するだけでなく、可用性を積極的に改善することを目指します。
可用性管理は、ITサービス管理(ITSM)、オブザーバビリティ、アプリケーションパフォーマンス監視(APM)など、他のIT領域と密接に関係しています。APMでは、外形監視、サーバー監視、クラウド監視、ネットワーク監視、リアルユーザー監視(RUM)など、さまざまな監視ソリューションが使われます。その中でもRUMは、Webサイトやアプリケーションでエンドユーザー操作のタイミング、エラー、測定データを収集、分析して、ユーザーエクスペリエンスを可視化する点で、可用性監視に新たな視点をもたらします。
可用性管理は、広く使われているITILフレームワークにも含まれます。ITILは、ITサービスを最適化してサービス障害の影響を最小化するための標準プロセスとベストプラクティスを規定するフレームワークです。可用性管理の目的の1つは、可用性監視と同様に、組織が常に最大限の能力を発揮できるようにすることですが、その最終目標は、継続的な改善を促進することにあります。
可用性監視は、テクノロジー製品やサービスが期待どおりに稼動し、動作していることを確認する手段を提供します。今日、ほぼすべての組織でテクノロジーはビジネスの生命線になっています。たとえば、Webサイトのパフォーマンス監視について考えてみましょう。AmazonやFacebookなどのホームページがダウンしたら、短時間のうちにさまざまな問題が連鎖的に起こるはずです。障害を知らせるページが表示される場合でも、接続すらできない場合でも、顧客は不満を感じ、収益は事実上ゼロになり、最終的にはユーザーが別のサイトに移行し始めて、組織の評判と経営状態に悪影響を及ぼす可能性があります。
2021年秋、Facebookとその傘下のWhatsAppおよびInstagramで同時に障害が発生し、6時間にわたってアクセスできなくなりました。この間にFacebookのアプリやサービスをまったく利用できなかったユーザーは1400万人以上にのぼります。識者の試算では、このダウンタイムの1分あたりのコストは16万3565ドル、当日の収益損失額は合計で6000万ドルに達しました。
さらに、ダウンタイムの発生時には、迅速に問題を修正してサービスを回復する必要があるため、ITスタッフが総出で対応に当たることになり、それによって生産性低下のコストも生じます。
可用性監視の目的の1つは、重要なテクノロジーサービス(エンドポイントのWebサイトだけでなくすべてのハードウェアとソフトウェア)の稼動状況を期待どおりに保つことで、こうした大規模な損害を回避することです。
可用性監視には、外部テクノロジープロバイダーのサービスレベル契約(SLA)のパフォーマンスを監視するという重要な側面もあります。サービスプロバイダー(インターネットサービスプロバイダー、クラウドテクノロジープロバイダーなど)と利用契約を結ぶ場合、その契約書には通常、プロバイダーが最小限維持すべき可用性が、主に特定期間(1カ月など)の稼動率という形で指定されます。この場合、利用側の組織は稼動時間を監視するなどの方法で、実際の可用性を把握する必要があります。利用側の可用性監視ソリューションで測定した結果、SLAを満たせなかった場合は、返金や利用料の減額を申請できます。

ダウンタイムは顧客離れや大きな収益損失につながることがよくあります。
企業がオンプレミスコンピューティングからクラウドに移行した現在でも、可用性は優れたIT管理を実現するための重要な要素です。消費者が日常生活の中でインターネットやその他のネットワークテクノロジーを利用する機会が増えるにつれて、可用性の重要度はさらに高まっていくでしょう。すべてのミッションクリティカルなサービスにおいて顧客を失望させたり収益を失うことがないように、企業は高可用性ツールや高可用性戦術の活用を検討する必要があります。
このブログはこちらの英語ブログの翻訳です。
この記事について誤りがある場合やご提案がございましたら、ssg-blogs@splunk.comまでメールでお知らせください。
この記事は必ずしもSplunkの姿勢、戦略、見解を代弁するものではなく、いただいたご連絡に必ず返信をさせていただくものではございません。

Splunkプラットフォームは、データを行動へとつなげる際に立ちはだかる障壁を取り除いて、オブザーバビリティチーム、IT運用チーム、セキュリティチームの能力を引き出し、組織のセキュリティ、レジリエンス(回復力)、イノベーションを強化します。
Splunkは、2003年に設立され、世界の21の地域で事業を展開し、7,500人以上の従業員が働くグローバル企業です。取得した特許数は1,020を超え、あらゆる環境間でデータを共有できるオープンで拡張性の高いプラットフォームを提供しています。Splunkプラットフォームを使用すれば、組織内のすべてのサービス間通信やビジネスプロセスをエンドツーエンドで可視化し、コンテキストに基づいて状況を把握できます。Splunkなら、強力なデータ基盤の構築が可能です。

© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2025 Splunk LLC 無断複写・転載を禁じます。
