
2025年のオブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。

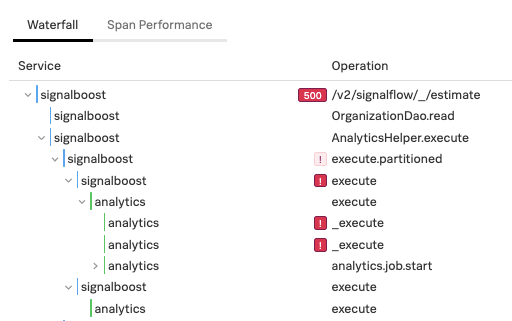
NoSample™による正確な分散トレーシングと制限のないカーディナリティ調査では、サンプリングでは見逃しまうアプリケーションパフォーマンスの低下も確実に捕らえることができます。そのため、遅延やエラーに関連する問題を実証する処理を記録すると、詳細に調査および分析できます。さらにトレースデータを活用して、エンドポイントの遅延率やエラー率のスパイクや異常値を特定することで、どの時点を詳細に調査すべきかを判断することもできます。これらすべてを可能にするのが、Splunk APMと、新たにリリースされたμAPMアラートです。

スパイクからトレースへ
このブログ記事では、μAPMアラートの内部構造と、それを支えるいくつかの統計原則について説明します。

さらに、
4つの動的なしきい値のうち定性的なオプションを除いて、アラートの感度は、ベースラインとの必然的な差異と時間枠の長さ(基礎となるプログラムで現れる期間)の影響を受けます。[Sudden Change]と[Historical Anomaly]のアラートは、インフラストラクチャー監視で使われる同名のアラートと性質が似ていますが、実装は多少異なります。次のセクションでその詳細を説明します。
遅延とエラー率のいずれについても、μAPMの静的しきい値ディテクターではトリガーとクリアそれぞれのしきい値(および期間)に基づいて比較が行われるため、アラートの大量発生を防ぐことができます。これに対してインフラストラクチャーの静的しきい値ディテクターでは、SignalFlow APIを使用すればアラートのクリア条件を設定できますが、現在のところSignalFx UIからは設定できません。重要なのは、シグナルがしきい値前後で推移した場合、区別のためのクリア条件を設定していれば、それが複数のインシデントではなく1つのインシデントとして扱われることです。
異常検出では、通常、分布が比較されます(直前の5分間の値と過去1時間の値を比較するなど)。ヒストグラムを利用できる場合、これは分位比較、つまり中心と広がり、多くの場合は中央値と四分位範囲(75パーセンタイルと25パーセンタイルの差で、IQRとも表記されます)によるロバスト統計を使用して行われます。
[Sudden Change]と[Historical Anomaly]の遅延アラートでは、「標準偏差」の定義が一般とは異なるため(インフラストラクチャー監視の条件で使用されるものとも異なります)、詳しい説明が必要でしょう。この場合の「偏差」は、遅延の分布の特性に合わせて、90パーセンタイルと50パーセンタイルの差を示します。
具体例として、トラフィックの多いある一般的なエンドポイントでの数時間の処理の分布について考えます。IQRは62msですが、中央値の前後の分布は非対称的で、75パーセンタイルが68ms、25パーセンタイルが6msです。さらに、このエンドポイントの90パーセンタイルは中央値よりも約2 IQR高い一方、正規分布では90パーセンタイルと中央値の差は1 IQR未満です。また、このエンドポイントの99パーセンタイルは中央値よりも約29 IQR高い一方、正規分布では99パーセンタイルと中央値の差は2 IQR未満です。
正の非対称分布は、遅延の分布ではかなり典型的です。分布の大部分は、比較的迅速で正常な処理で構成されます。そのため、低いパーセンタイルは凝集される一方、高いパーセンタイルはかなり広がります。このような非対称性があるため、中央値について対称な統計ではなく、右裾のデータに重点を置いた分布の散布度を表しています。
また、現在のP50が過去のP50よりも高いとき、その差が過去の(P90 - P50)を少しでも上回ると、現在のP50が過去のP90よりも大きくなることに注意してください。そのため、P50が(P90 - P50)からどのくらい離れたかに基づいてアラートを生成することは、現在のP50と過去のP90の比較(変化検出の分位比較手法)の自然な一般化と言えます。
パーセンタイルの分析は、エンドポイントの健全性について重要な情報を示すものの、それは不完全であり、上記の計算のみに依存するとアラートにノイズが混ざりやすくなります。このため、μAPMディテクターでは、SignalFlowを利用して複合アラート条件(「AかつB」形式の条件でアラートをトリガーするなど)を設定できるようにし、アラートをトリガーするタイミングの基準として、エンドポイントが受信するトラフィックの量も簡単に条件に組み込めるようにしています。これにより、まばらなデータに基づくアラートを抑制できます。
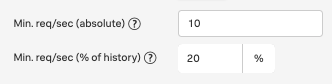
エラー率ディテクターでもリクエストボリュームの条件を設定できます。この条件を使用すれば、たとえばエンドポイントがほんの数件のリクエストを受信し、エラーが1つだけだった場合はアラートをトリガーしないように設定できます。
アラートパターンは他のシナリオにも適用できます(遅延に関するアプローチは、分布データやカウントデータを利用できるシナリオに広くに適用可能で、エラー率に関するアプローチは他の率を使用するシナリオにも適用できます)。ただし、インフラストラクチャー監視のアラートを強化する目的と比べて、その方法はかなり専門的になります。
SignalFlowライブラリのapmモジュールは、μAPMアラート条件の下にあります。他のSignalFlowモジュールと同様に、apmには、状況を可視化したり他のアラート手法で利用したり(既に組み込まれた条件とカスタムしきい値を組み合わせるなど)する場合に便利ないくつかの中間計算が含まれます。たとえばerror_rate関数では、指定した一連の処理における指定した期間でのエラー率が計算されます。
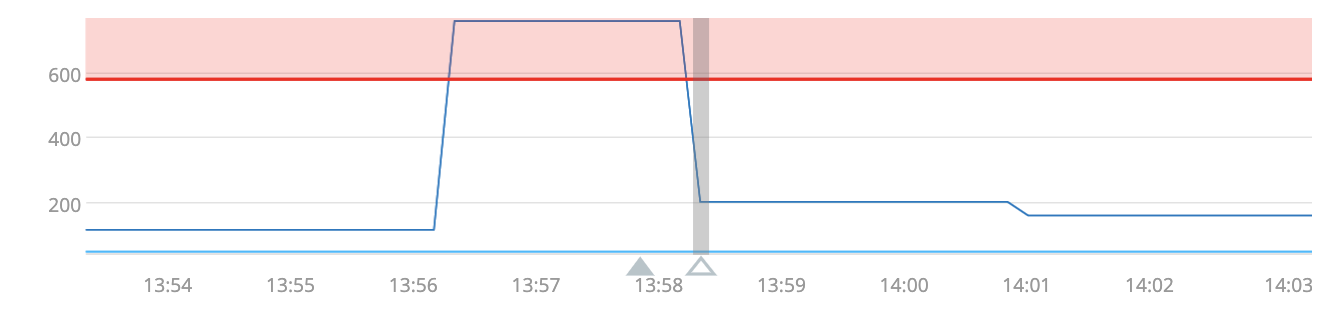
μAPMディテクターでは、インシデント状態でのデータの可視化を強化しています。次の図にその例を示します。
13:56から上昇している現在の遅延は紺色で示され、履歴に基づくベースライン(この例では過去の中央値)は水色で示され、しきい値(この例では履歴の中央値+履歴の偏差5個分)は赤で示されています。また、従来どおり、塗りつぶされた三角形がインシデントの開始時点、空の三角形が終了時点を示します。履歴に基づくベースラインの表現が新しくなり(Infrastructureの内蔵の条件では性質が似た統計方法論をもとにした表現です)、コンテキストが増えたため、アラートを迅速に評価できます。
SignalFxのリアルタイムストリーミング分析エンジンとNoSample™の正確な分散トレーシングを基盤とするSplunk APMアラートなら、すばやく問題を検出し、関連する処理トレースを特定できます。
このブログはこちらの英語ブログの翻訳です。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
