モノリシックアプリケーションでもマイクロサービスでも、新たな変更による問題を素早く検出し、原因を高い精度で特定して、サービスのパフォーマンスを最適化することにより、問題解決を効率化します。
解決策
すべてのデータに対応できる統合型のオブザーバビリティプラットフォーム
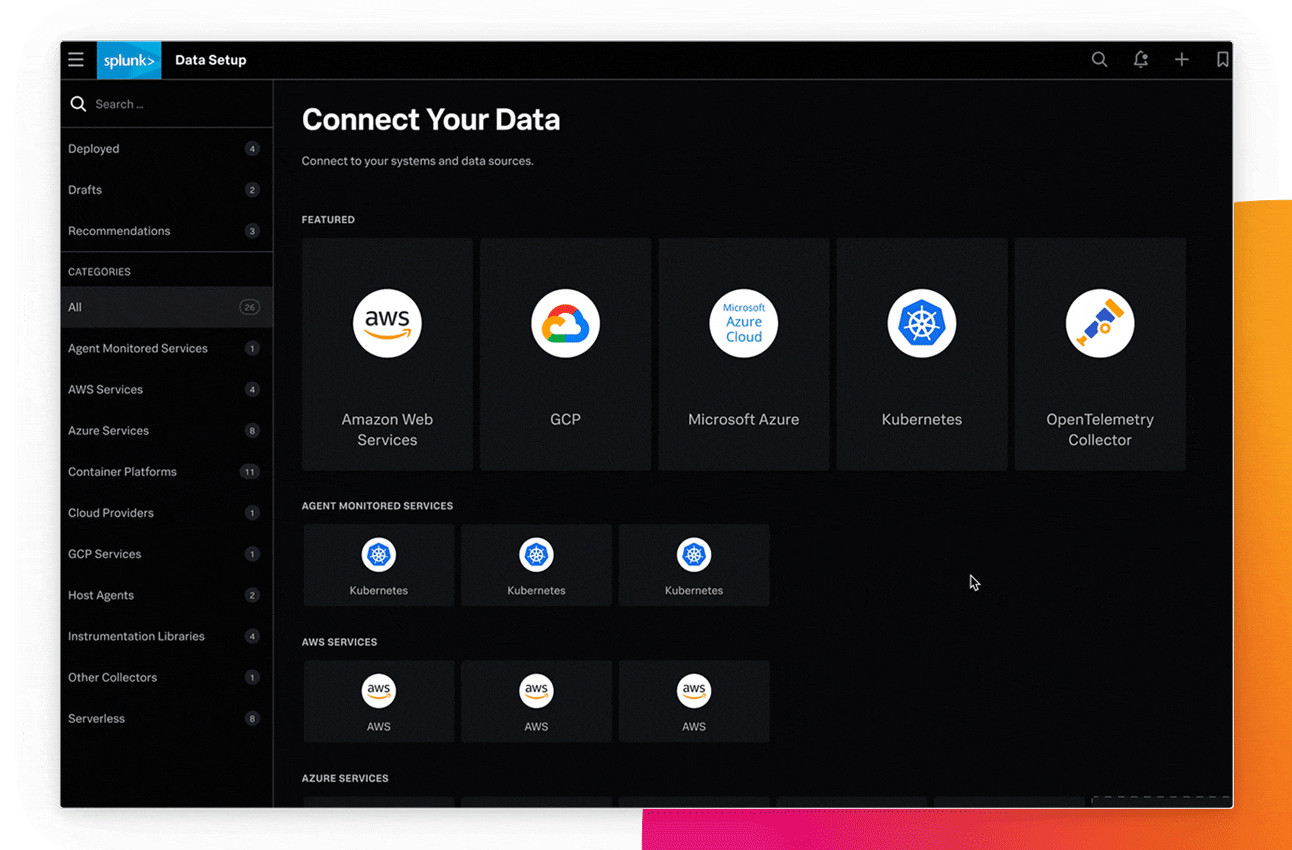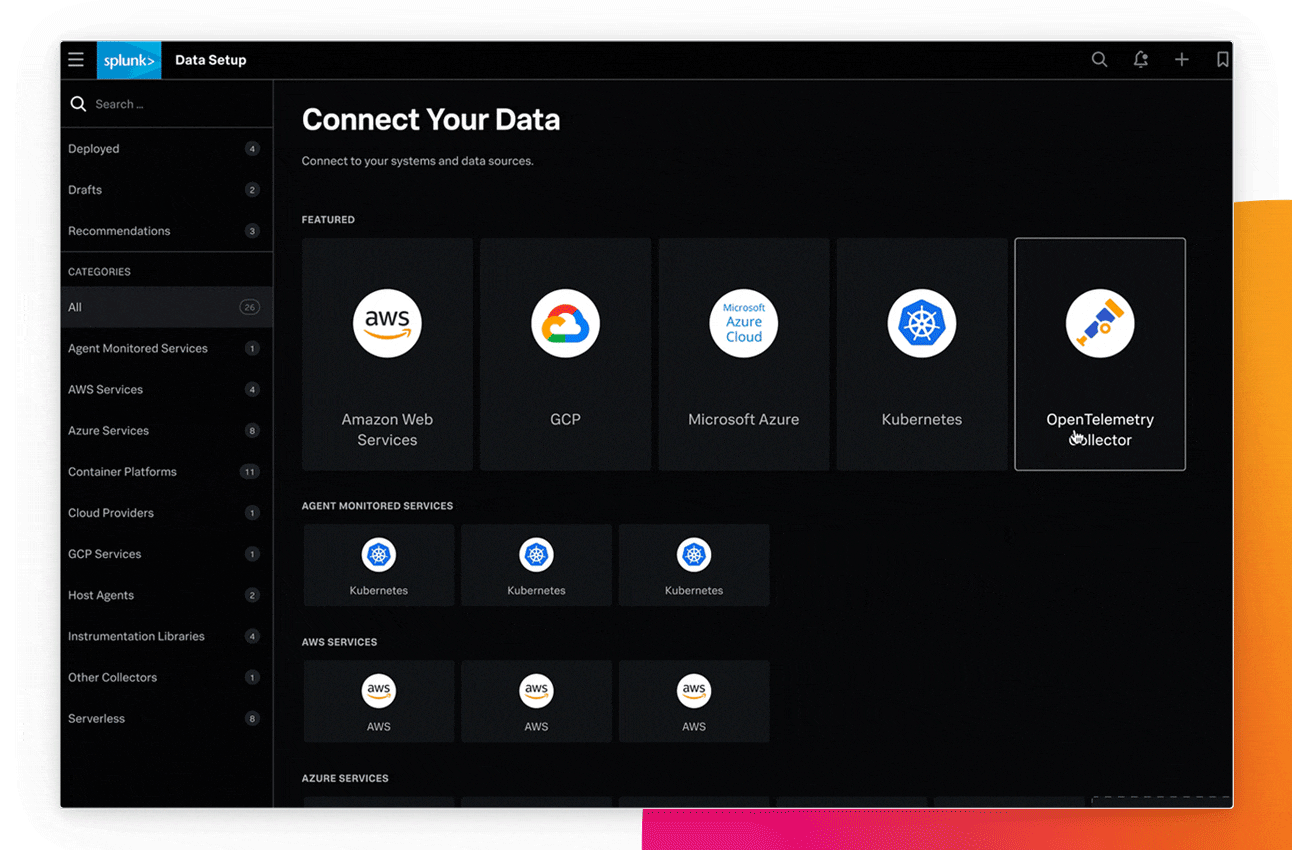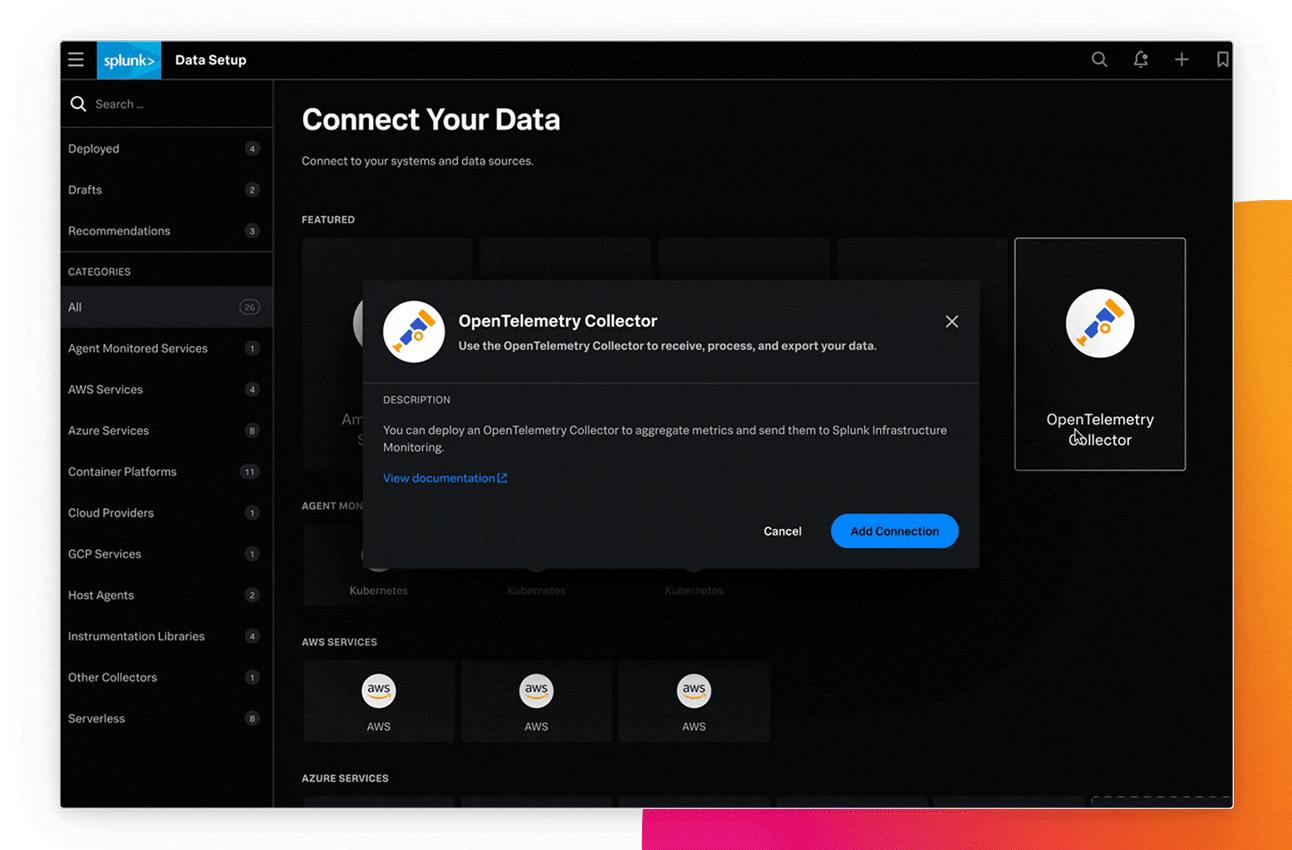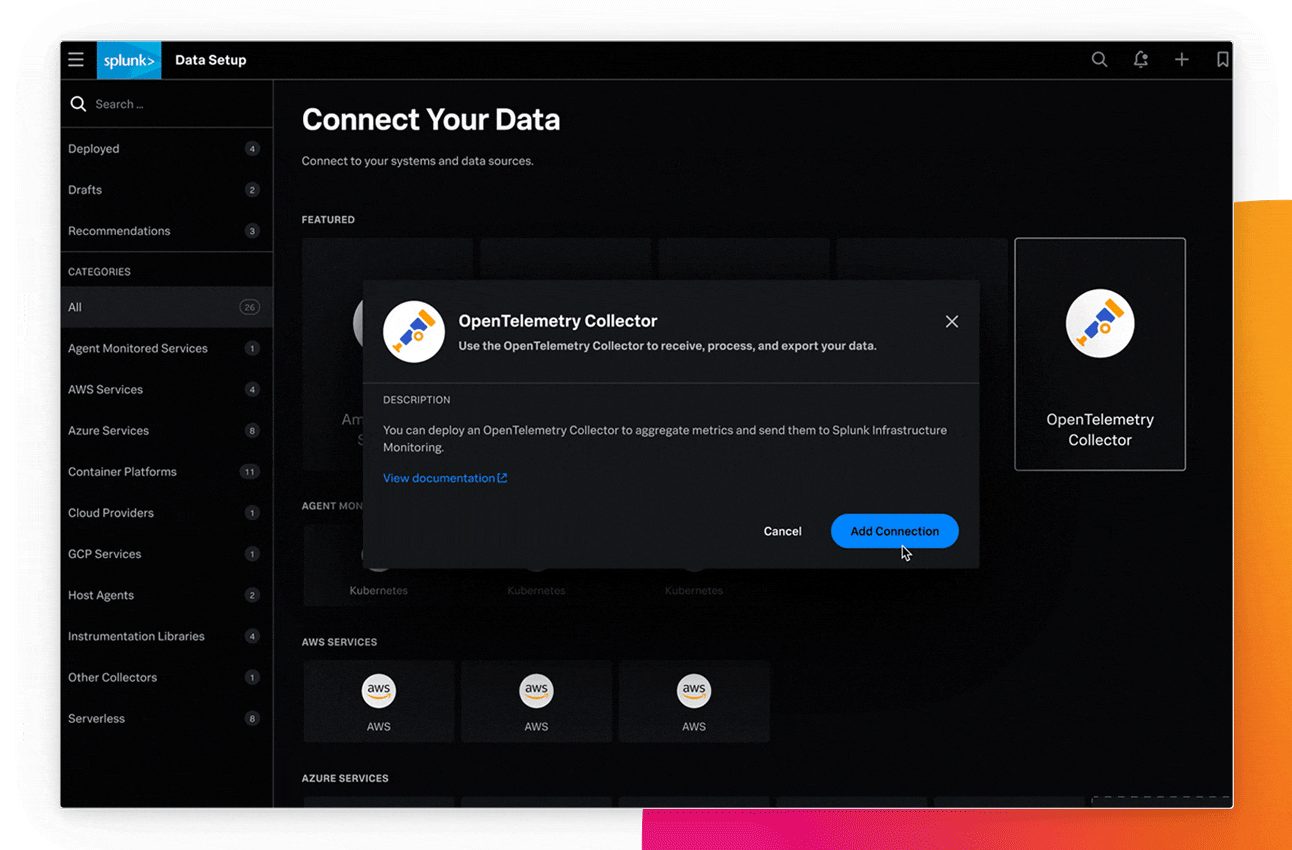
すべてのデータを1カ所で管理
問題のトラブルシューティングに必要なすべてのログ、メトリクス、トレースを1つの画面で確認
拡張性の高いカスタムメトリクス
独自のメトリクスをビジネスKPIに結び付け、重要な問題をアラートで通知
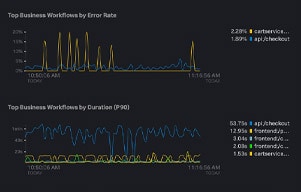
すべてのトランザクションを確認
問題の再現は不要。問題が通知されたら、関連するトランザクションをシンプルに検索
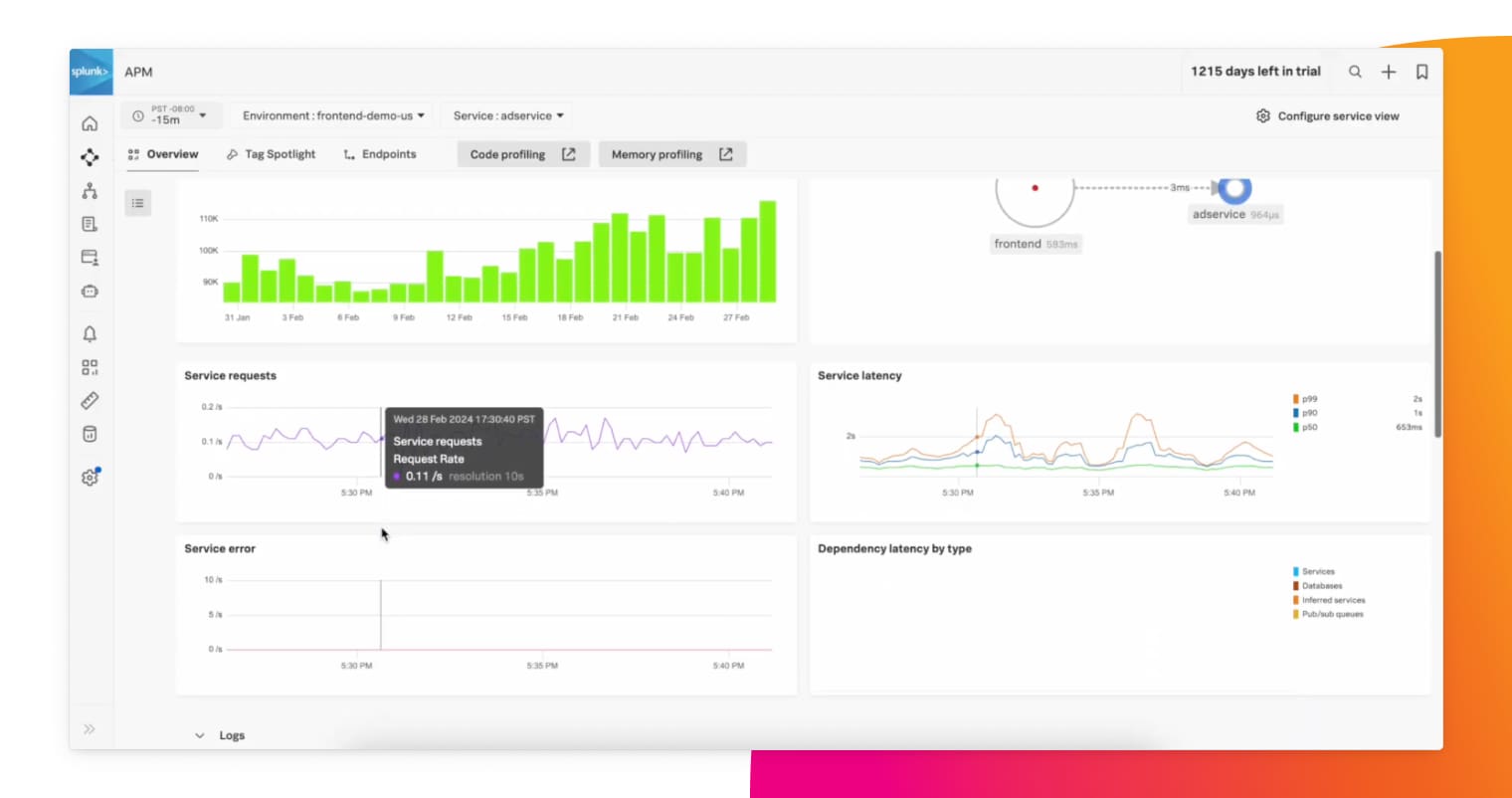
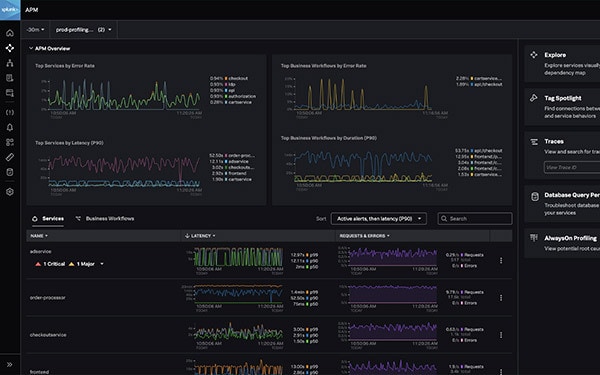
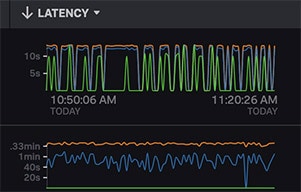
サービスの問題に関する詳細で正確なアラート
カスタムメトリクスをインストルメンテーションすることで、サービス内の問題の検出と切り分けを効率化できます。メトリクスは詳細であればあるほど問題の理解に役立ちます。Splunkのメトリクスエンジンは、大規模な導入環境を想定してゼロから構築されています。
Splunk Observabilityは、複雑な環境を可視化し、データを行動につなげることで、お客様がより優れた製品をより迅速に提供できるようにするという当社のミッションを支えています
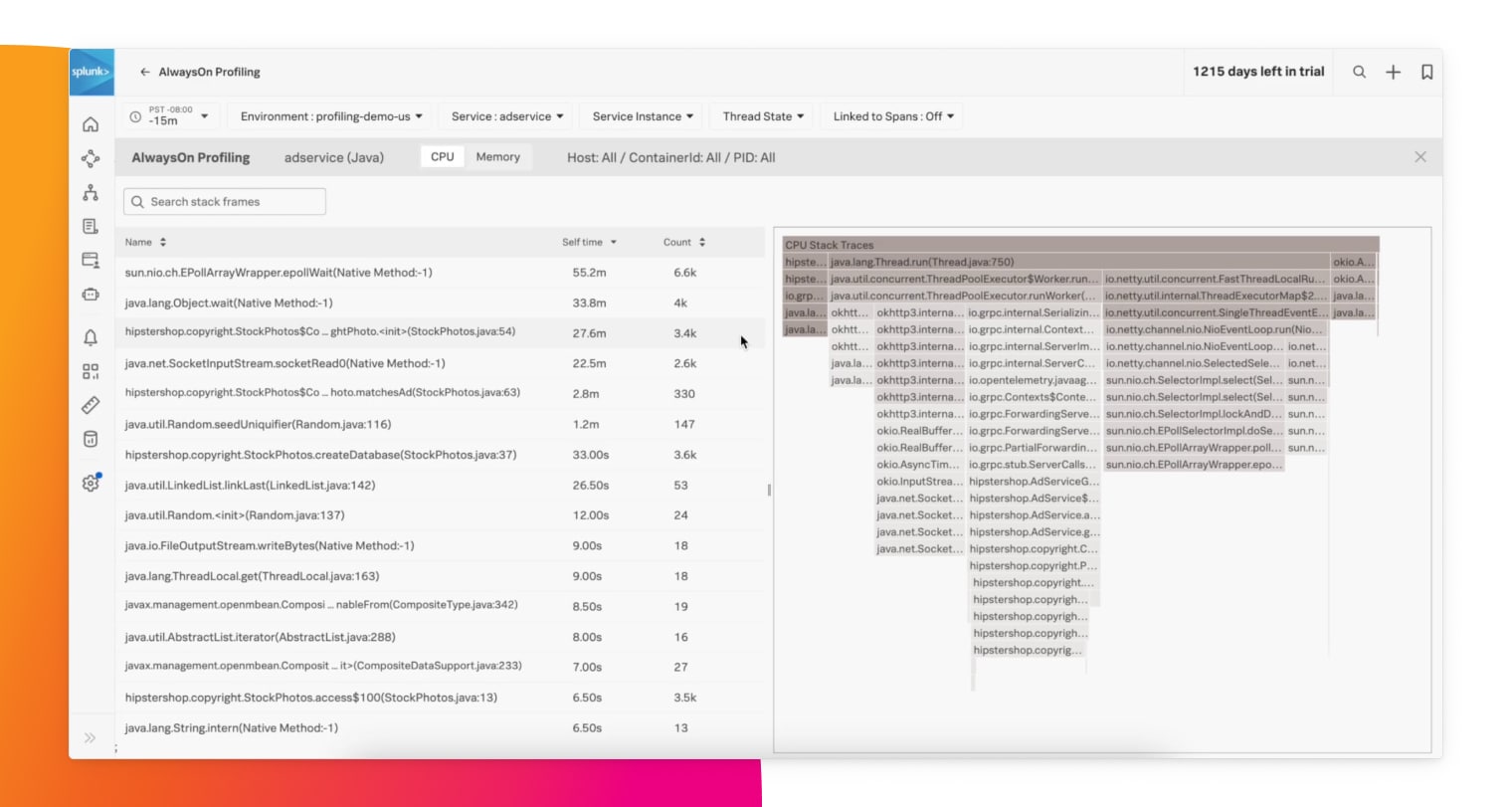
サービス内の根本原因を正確に診断
問題がインフラ、ネットワーク、サードパーティのサービスのいずれに起因するものか、あるいはデータベースクエリの不適切な使い方によって生じているのかといった原因をクリックするだけで確認できます。また、AlwaysOn Profilingによるコードプロファイリングを使用すれば、コードが消費しているメモリとCPUの量を行ごとに確認し、問題のあるコードを見つけることができます。
Splunk Observabilityのおかげで、重要なアラートにのみ注意を払って、問題対応の優先順位を正しく判断できます。技術関連、ビジネス関連、運用関連など、あらゆるアラートをSplunk Observabilityに集約することで、問題の発生箇所を正確に特定し、修復に集中できるようになりました
