オブザーバビリティ
Splunk Infrastructure Monitoring
オンプレミス、ハイブリッド、マルチクラウドを含むすべての環境を完全に可視化して、リアルタイムの監視とトラブルシューティングを実現し、インフラパフォーマンスの最大化を支援
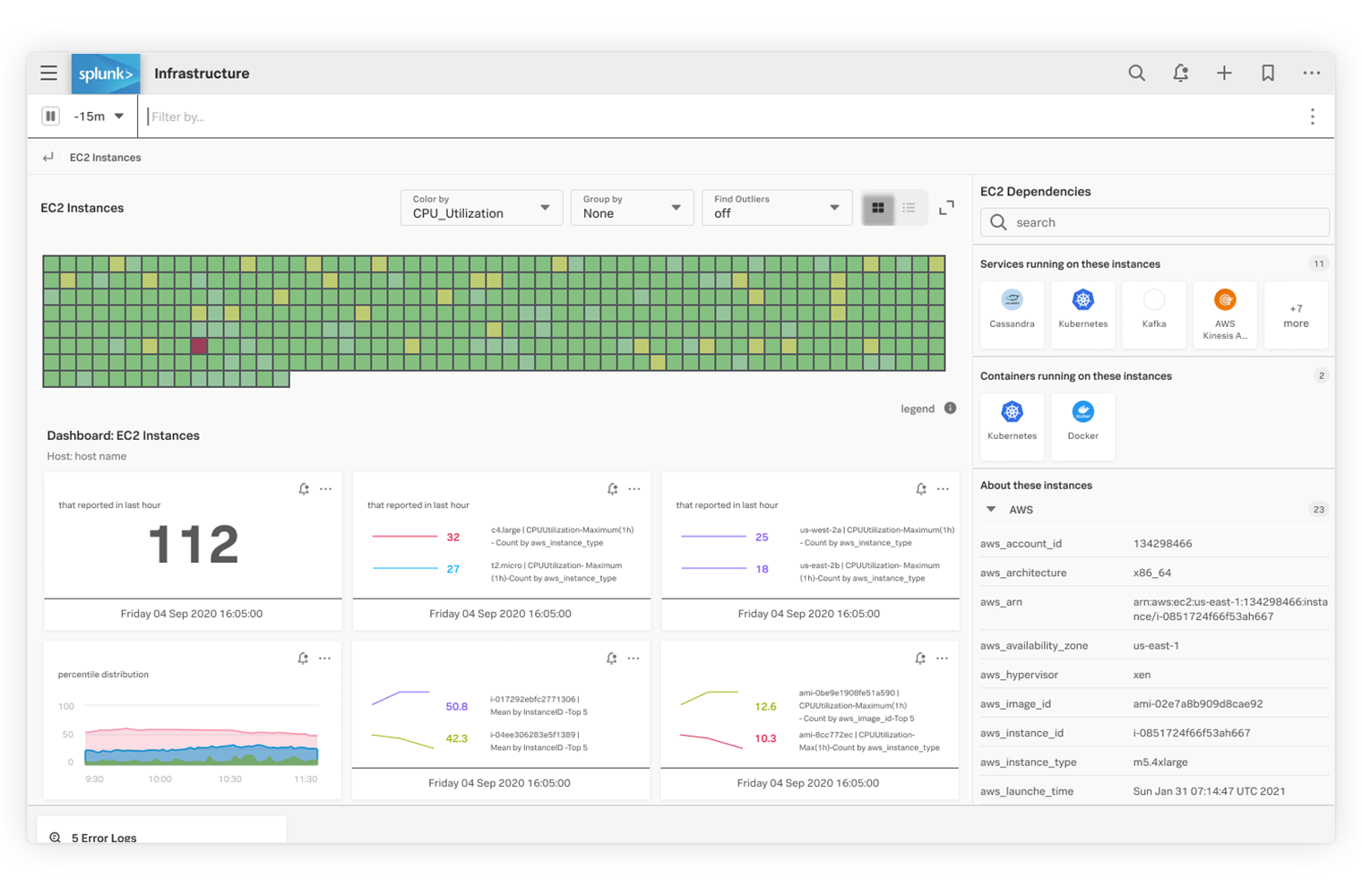
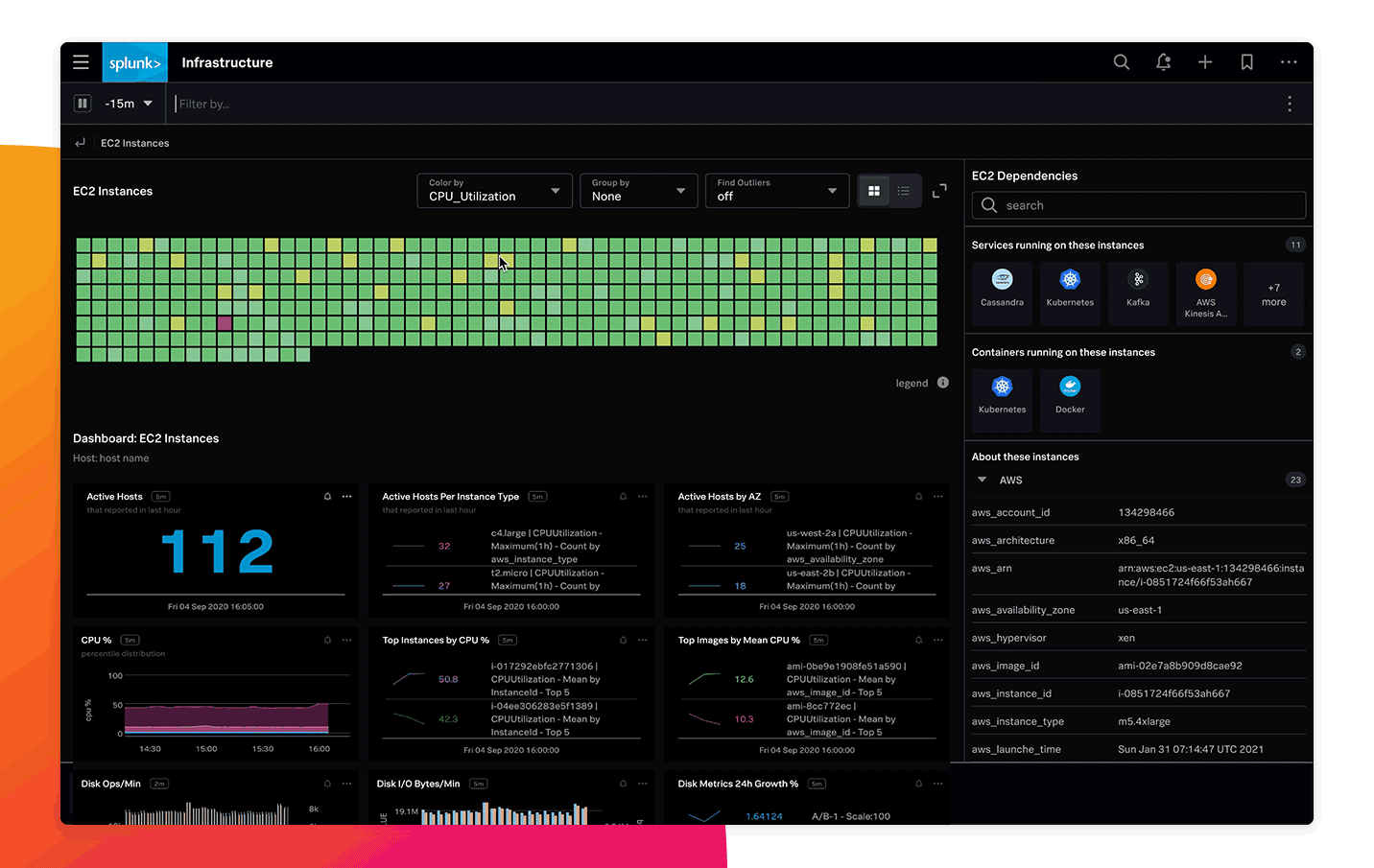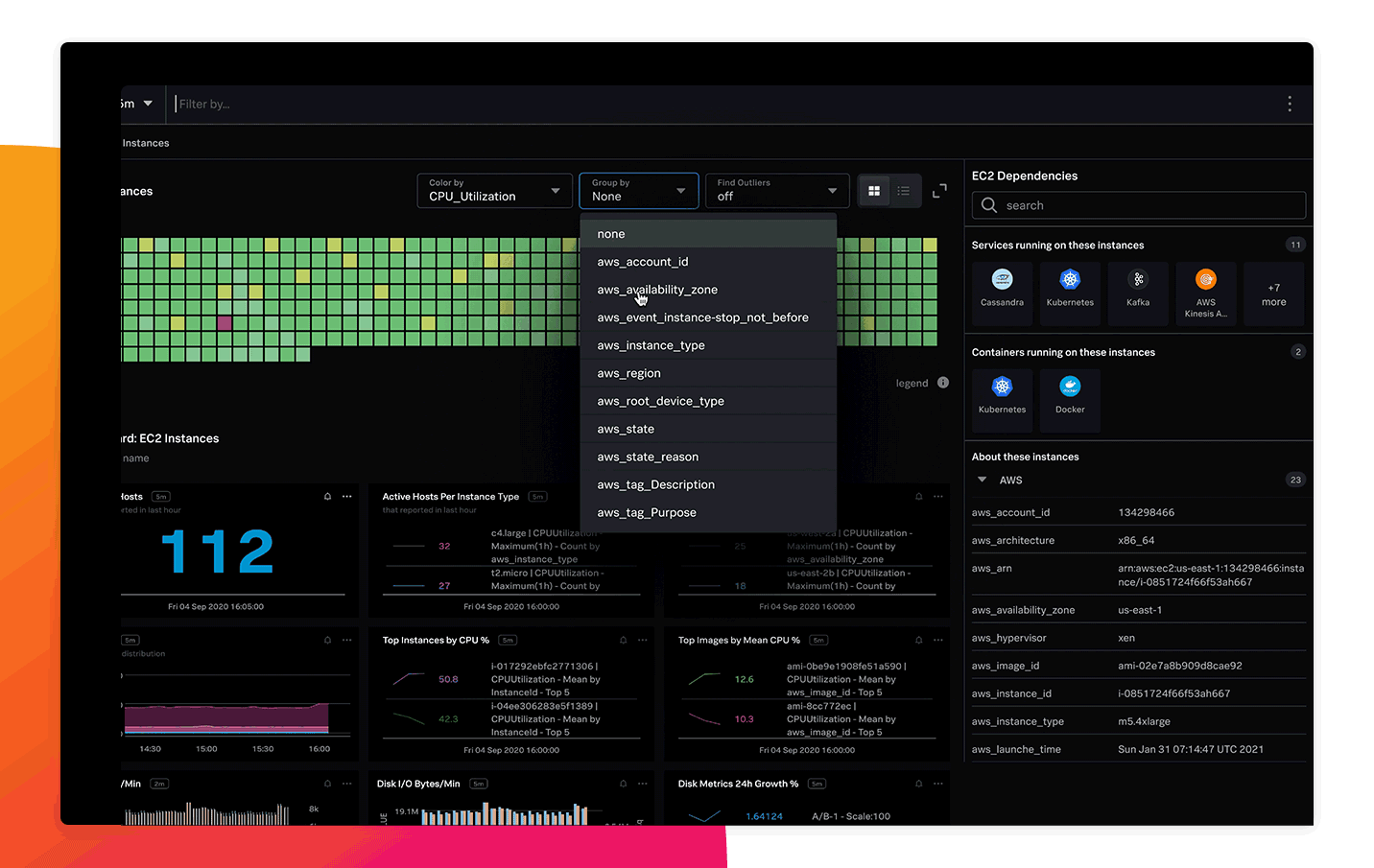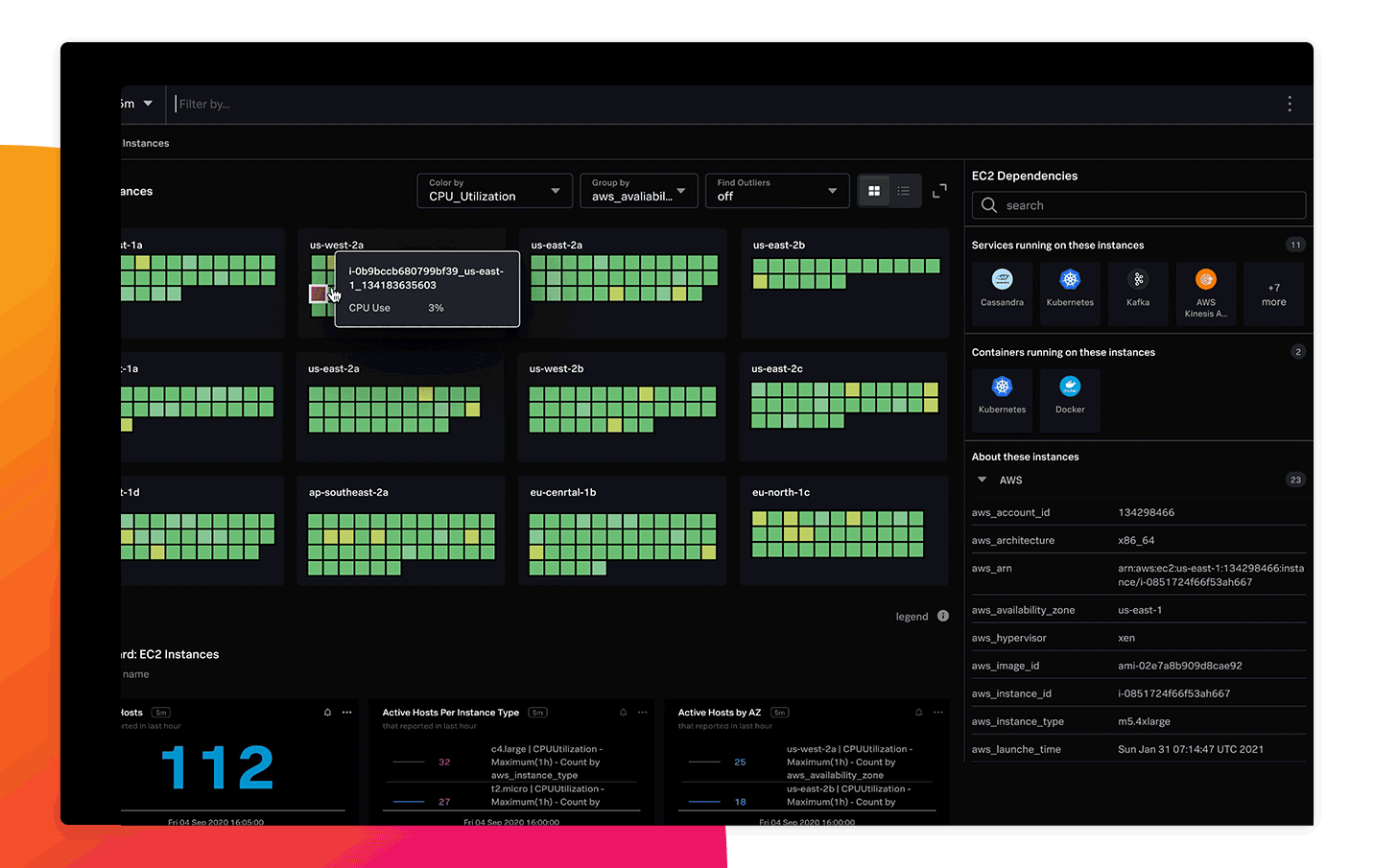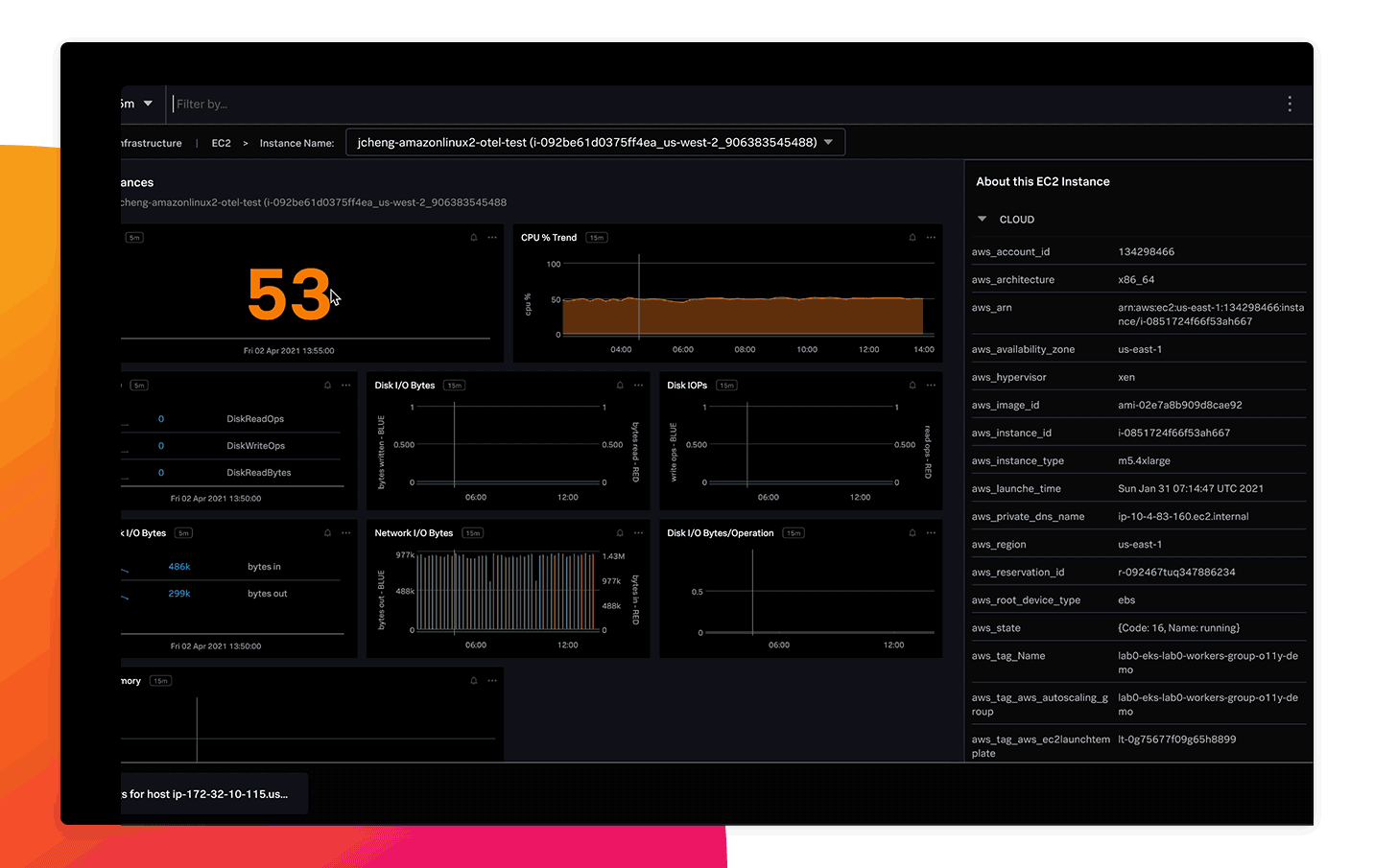
即座にインフラを可視化
250以上のクラウドサービスインテグレーションとすぐに使える構築済みダッシュボードを使用して、スタック全体をすばやく可視化し、価値を早期に実現できます。数分後にはクラウド環境、サービス、システムが自動的に検出され、監視、分析、グループ化、調査を開始できます。
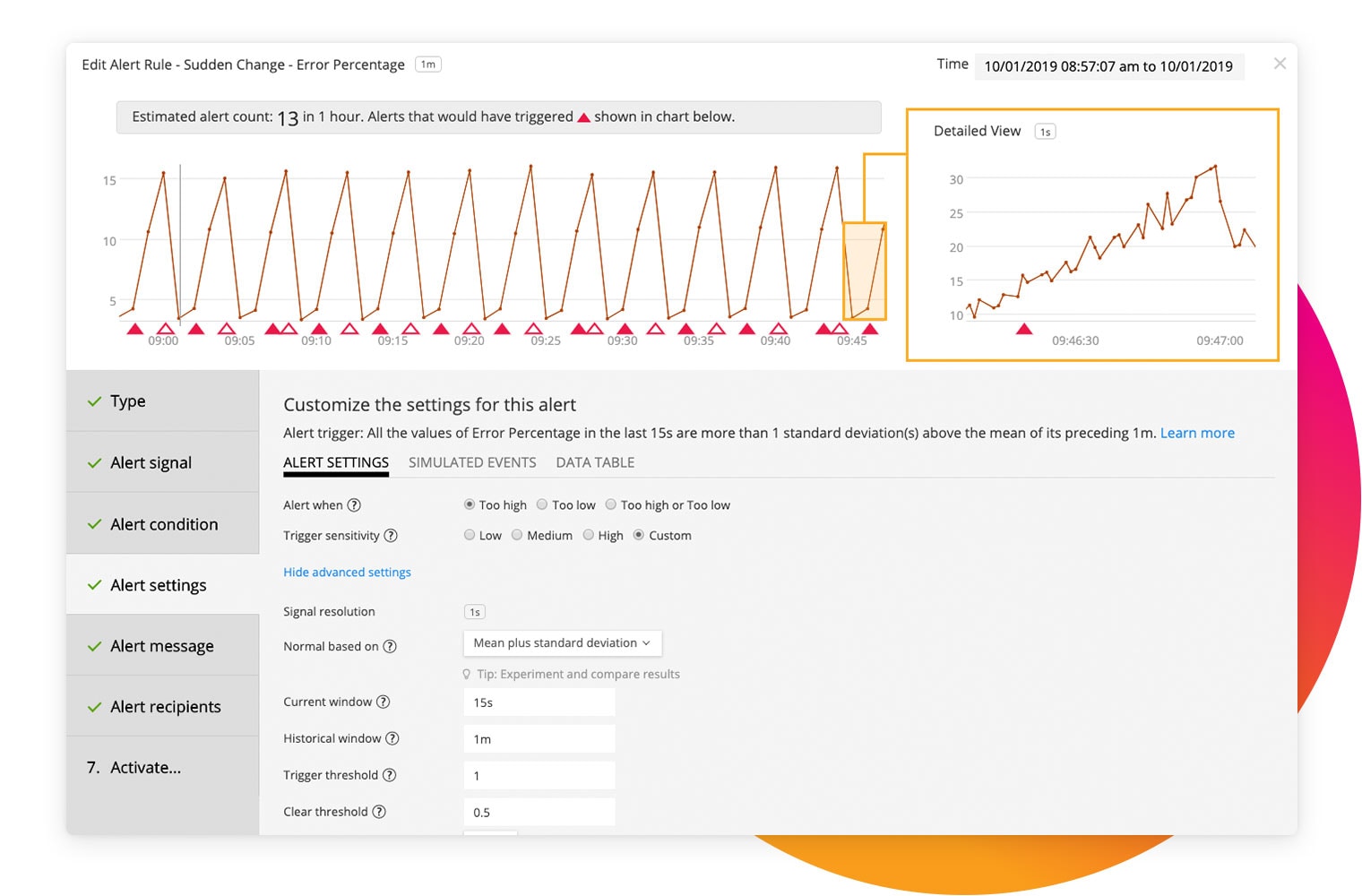
リアルタイムの実用的なアラート
インフラをモニタリングし、パフォーマンスの問題がエンドユーザーエクスペリエンスに影響を及ぼす前に、対策を講じることができます。動的なしきい値、複数の条件、複雑なルールに基づいて問題をすばやく検出し、正確なアラートを生成することで、アラートの大量発生を回避し、MTTD/MTTRを大幅に短縮できます。
統合的な組織管理
コンテキストに即してビジネス上重要な疑問の答えを見出し、サービスレベルの目標や指標をすばやく監視できます。トークンベースのアクセス制御や使用制御など、ビジネスKPIのカスタムメトリクスを追跡することもできます。
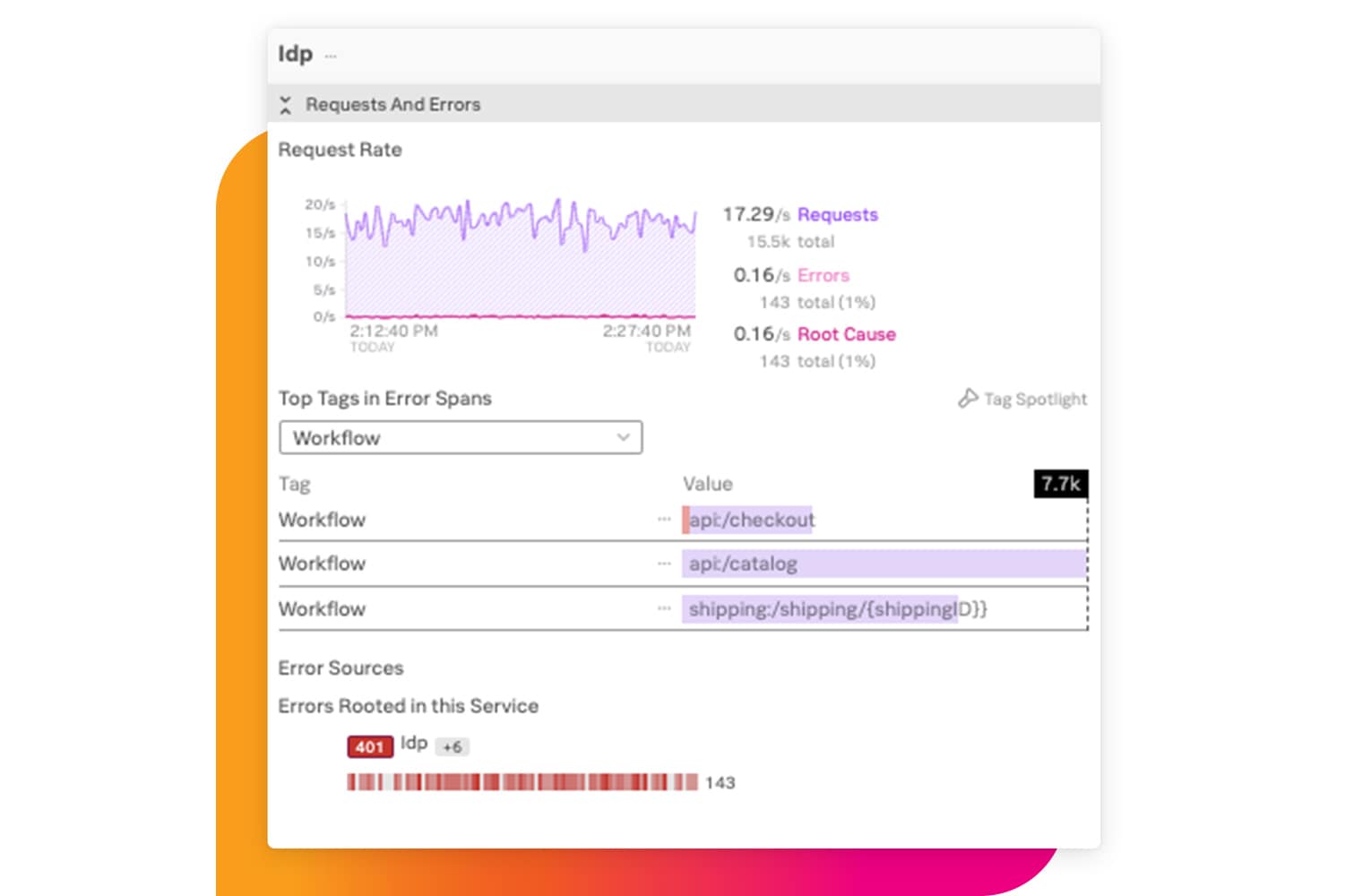
優れた拡張性
数千のマイクロサービスや数十億のイベントを見逃すことなく横断的に調査してトラブルシューティングできます。取り込む前にメトリクスを集約し、使用されていないメトリクスを時系列で削除することで、監視にかかるコストを気にせずアプリケーションの拡張に集中できます。
機能
卓越したスピード、拡張性、分析でハイブリッドインフラを監視
Splunk Infrastructure Monitoringは、大規模なクラウド環境のリアルタイム監視要件に対応する、メトリクス処理に特化したプラットフォームです。
スタック全体の可視化
ハイブリッドインフラとマイクロサービスをシームレスに相関付けて状況を明確に可視化し、インスタントトラブルシューティングでツールを切り替えることなくコンテキストに即してインサイトを獲得
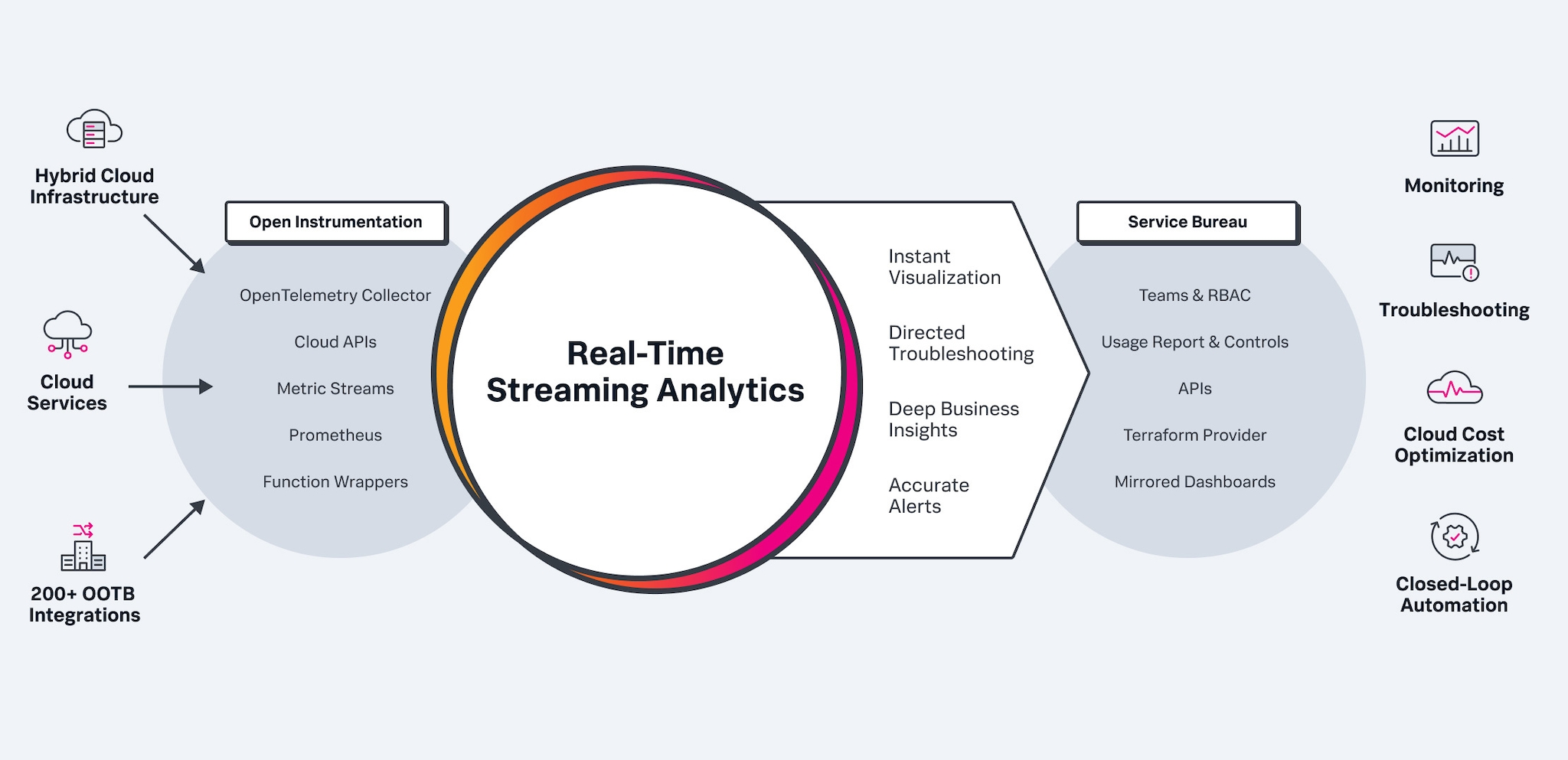
リアルタイムのストリーミング分析
Pub/Subバスを使用してストリーミング中のデータを分析。1秒も無駄にしたくない場合でも、ストリーミングアーキテクチャならリアルタイムでデータを取り込み、分析して、数秒以内にアラートを生成
一元管理
プログラム可能なAPIと監視のコード化(Monitor-as-Code)によって監視をCI/CDパイプラインの初期段階から組み込み、セルフサービス型デプロイでの透明性と組織管理を維持
ログに基づくコンテキストに即したトラブルシューティング
あらゆるソースからあらゆる規模で完全忠実なデータを取り込むことができ、データの処理後は、関連コンテンツをクリックすることで根本原因を詳細に分析。Splunkなら、将来のデータニーズの拡大を見据えた投資が可能に
Kubernetesベースのネットワークを容易に可視化
クラウドネットワークの問題が発生しても、推測に頼ることなく問題の発生源とネットワーク停止の影響を簡単に判断して、MTTDと本番環境のダウンタイムを短縮します。
Kubernetesの高度な監視
Kubernetesオブジェクトを自動的に検出し、その健全性とパフォーマンスを即座に表示。表示するダッシュボードやグラフをカスタマイズすることも可能

お客様事例
Lenovo社:Splunk Observabilityで快適なeコマースエクスペリエンスを実現
運用効率を大幅に向上させ、チームのコラボレーションを促進してくれたSplunkは、私たちにとって大きな価値をもたらしてくれました。このすばらしいツールのおかげで、運用チームは以前よりもずっとすばやく問題を解決できるようになりました
5分以下のMTTR
以前の30分から短縮
100%の稼働率
オンライントラフィックが300%増加しても維持


ビジネスとITサービスの監視
インテリジェントなイベント管理とITSMとの統合により、サービスの健全性を監視して、サービスレベル契約の遵守を支援
