
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

There are about 90 DNS resource record types (RR) of which many of them are obsolete today. Of the RR’s used, DNS TXT record offers the most flexibility in content by allowing user defined text. The TXT record initially designed to hold descriptive text (RFC 1035) is widely used for email verification, spam prevention and domain ownership verification. Besides well defined purposes of DNS TXT records, it is also used for malicious purposes to create DNS amplification attacks, injection of malware and exfiltrate data from the victim’s machine. The freedom of unstructured text poses a huge security threat because any base encoded non-text data like malware, executables or simple commands can be camouflaged as text.
While DNS traffic has been overlooked as trustworthy and secure, recent DNS threat research reports an increase in DNS Tunneling attacks over the past year. Several botnet attacks have also used DNS TXT based botnet communication. The SMLS team has developed a detection in the Enterprise Security Content Update (ESCU) app that monitors your DNS traffic looking for signs of DNS Tunneling using TXT payloads. The detection has an accuracy of 99.79% ensuring almost all suspicious DNS are detected. The model is deployed using the Splunk App for Data Science and Data Learning (DSDL) and further details can be found here.
Domain Name System (DNS) is a hierarchical distributed database that maps domain names to IP addresses and Tunneling is a communication protocol that securely transmits encapsulated data packets between networks. Since DNS protocol is foundational and crucial for network communication, it is allowed to move through firewalls without much scrutiny like HTTPS, FTP, SMTP for malicious activity. Malicious actors have successfully been able to exploit this advantage to create DNS Tunneling that allows data transfer between networks, which is beyond the original intention of DNS protocol.
DNS Tunneling allows attackers to establish a C2 channel where DNS requests from a victim act as a heartbeat indicating that malware is still running undetected. Another prominent use of DNS Tunneling is Command Injection where a DNS server sends binaries or control commands embedded in a DNS TXT record response that are then executed by the victim. For example, malware running on a client sends a DNS request to a malicious DNS server and the server under the control of malicious actors sends a DNS response with NOERROR code. Unlike NXDOMAIN or SERVFAIL response codes, NOERROR indicates the request was successfully processed and the response is usually an IP address of the domain requested. However, malicious actors send commands or files in the TXT record as an innocuous NOERROR response.

Since the TXT record is unstructured and has been extended for well defined purposes, it is necessary to differentiate between legitimate and suspicious uses of DNS TXT records. Categorization of DNS TXT records requires looking at historical DNS data and how this record is used in practice. A recent research paper considered DNS data containing 75 billion DNS TXT records spanning over years to analyze commonly occurring text patterns and recording new patterns of DNS TXT. The DNS TXT records were matched with an exhaustive list of regular expressions of various categories like those shown below and then similar categories were grouped into broader classes.
| Broad categories of DNS TXT records |
|---|
| Verification |
| Pattern |
| Hash/BaseN |
| Misc |
| Crypto |
| Others |
Based on text content analysis, 83.35% of DNS TXT records content conformed to standardized and non-standardized patterns like verification of email and domain. 15.48% contained innocuous content like DNS servers or dates. The remaining 1.17%, tail of DNS TXT records not matching any patterns were grouped into ‘Unknown’ category for further in-depth analysis of security implications.
After categorization, we noticed that the DNS TXT for a few records (ex: v =spf1 for email or MS = ms63477054 for verification) did not match a single expression in the list of regular expressions because there were extra spaces, case mismatch or even spelling errors. Additionally records containing dates with various formats were categorized incorrectly into ‘Other’. Since DNS TXT record is unstructured, it is more prone to inconsistencies and adding/modifying regex or pre-processing text can only slightly improve mis-categorization. This is where Machine Learning (ML) can be useful and robust in identifying patterns in the DNS TXT even if it is slightly distorted and help us classify a DNS TXT record accurately in near real-time.
The majority of DNS TXT records matched to well defined purposes, while the ‘Other’ category contained mostly unmatched and contained single char, base 64 mail, JavaScript, public/private keys, executables, and commands. We grouped all benign categories like email, verification, patterns, encoded and miscellaneous into one class with label is_unknown as 0 and the ‘other’ category with label is_unknown as 1. We approached the problem of detecting suspicious DNS TXT as a binary classification problem with 2 classes - is_unknown as 0 or 1. The next few sections will discuss in detail the model architecture and model evaluation.
We started the modeling process by building a baseline, a logistic regression model to classify DNS TXT records. The feature set is created by splitting each input text by spaces and then the characters occurring in each token by a sliding window of 1-4 characters. Although the model accuracy was at 99.70%, it had a high False Positive Rate (FPR) of 0.22%. We would prefer a model with a lower FPR because in the real scenario, only a small percentage of DNS responses contain TXT records and a higher FPR can cause detection to misfire.
Hence, given the size of the dataset and the nature of text data, we experimented with various deep learning (DL) architectures that tend to perform better with text data by harnessing the value from word embeddings. Below is the model architecture of designed model
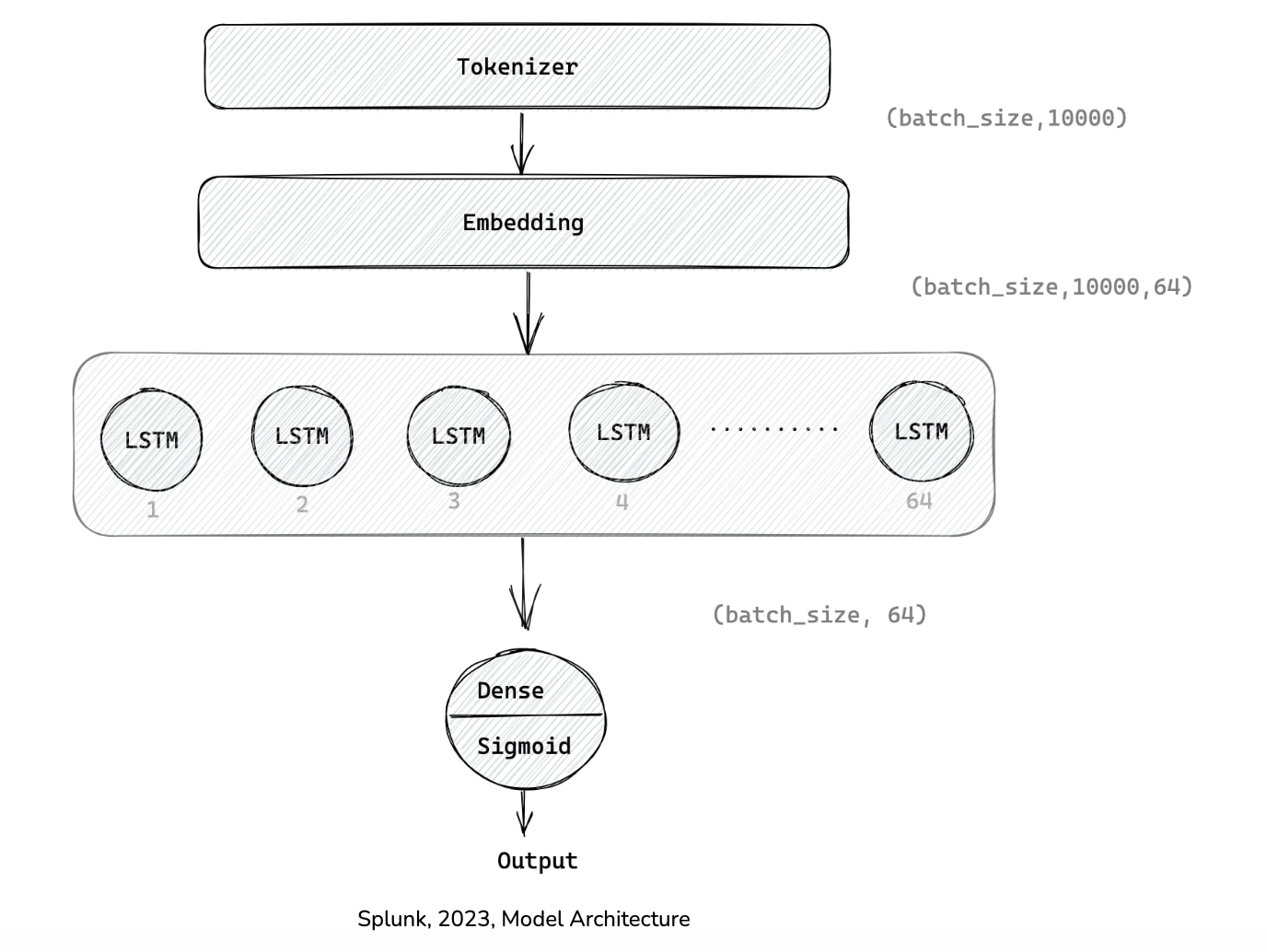
Firstly, the DNS TXT record is minimally processed to remove trailing spaces, quotes and converted to lowercase before sending it to the Tokenizer layer. The Tokenizer breaks down the text into multiple words and creates tokens in a sliding window of size 1 to 4 characters within each word. Since most of the DNS records match well-defined purposes, top 10000 words capture commonly occurring words in those DNS TXT records. The output of the Tokenizer layer (batch_size, 64000) is then passed through an ‘Embedding layer’. One-hot encoding technique for each word in the vocabulary creates a sparse vector but it does not capture semantic similarity. Embeddings, on other hand, creates a dense vector with real values for a word that is similar to words occurring in the similar contexts. Since the neural network learns representations of the features, the weights are learned while training on dense layers. The output of the Embedding layer adds a new axis to the input, resulting in the dimension (batch_size, 10000, 64).
The output of the Embedding layer is then passed to the Long Short Term Memory (LSTM) layer, a variant of Recurrent Neural Network (RNN). LSTM are sequence models that capture unidirectional dependencies between tokens using hidden states. Since our goal was to reduce false positives, we configured a relatively simple single LSTM layer with 64 units. Additionally, drop out rate is set at 0.5, which allows the network to temporarily drop a node and its connections forward and backward while training. This creates variations of the network that alleviates overfitting.
The final layer is a dense layer that consumes the output of the LSTM layer (batch_size,64). This single unit is like a logistic regression model that applies a sigmoid activation function on a linear combination of input features to generate an output in the scale of 0-1. The output is a probability score that indicates how likely the input is of ‘unknown’ class.
As there are many hyper-parameters used in designing a DL model (e.g., number of layers, number of units, activation functions and drop out rate), we performed hyper-parameter tuning. Hyper-parameter tuning evaluates variations of models using a combination of parameter values in a specified range and selects one of the model variants having optimal performance.
For training and testing purposes, we divided the dataset into train, validation and test datasets of sizes 80%, 10%, 10% respectively. Since training DL models on large datasets can take hours, we leveraged GPUs which are specialized at performing advanced mathematical transformations for our model computation.
A confusion Matrix describes the classifier performance by comparing actual and predicted values. Comparing the DL model performance with the baseline, the LSTM DL model has performed very well with 99.79% accuracy. It has significantly reduced the FPR from 0.22% to 0.11%. The True Positive Rate (TPR) is 99.05% for 0.11% FPR indicating we misfire on very few instances. The True negative rate of 99.89% indicates we are able to identify the majority of benign DNS TXT records with a very low misclassification error.

The pretrained model is available here and can be easily deployed using the Splunk App for Data Science and Deep Learning (DSDL). Check out the instructions to deploy the model using DSDL here.
Once the model is deployed, the pretrained model can be easily used within your SPL search by appending ‘| apply detect_suspicious_dns_txt_records_using_pretrained_model_in_dsdl. The pretrained model takes input DNS TXT Response as ‘text’ and outputs ‘is_suspicious_score’, a probability score that tells how likely the TXT response is suspicious. Rather than having to write complex SPL commands for creating input features, the LSTM model accepts raw text input and does all the processing on the text as discussed above.
For Enterprise Security customers, the ESCU detection for detecting suspicious DNS TXT records using the pretrained model is readily available in ESCU v.3.57.0. The detection uses the answer field from the Network Resolution data model with message type ‘response’ and record_type as ‘TXT’ as input to the model. The detection results in DNS responses that have ‘is_suspicious_score’ > 0.5. The threshold is set at 0.5 and is tunable.
| tstats `security_content_summariesonly` count min(_time) as firstTime max(_time) as lastTime from datamodel=Network_Resolution where DNS.message_type=response AND DNS.record_type=TXT by DNS.src DNS.dest DNS.answer DNS.record_type
| `drop_dm_object_name("DNS")`
| rename answer as text
| fields firstTime, lastTime, message_type,record_type,src,dest, text
| apply detect_suspicious_dns_txt_records_using_pretrained_model_in_dsdl
| rename predicted_is_unknown as is_suspicious_score
| where is_suspicious_score > 0.5
| `security_content_ctime(firstTime)`
| `security_content_ctime(lastTime)`
| rename src as "Source IP", dest as "Destination IP", text as "DNS Answer", record_type as "DNS Record Type"
| table "Source IP","Destination IP","DNS Answer","DNS Record Type", firstTime, lastTime,is_suspicious_score
| `detect_suspicious_dns_txt_records_using_pretrained_model_in_dsdl_filter`
The detection generates risk events for every suspicious DNS TXT record detected. The risk events are then processed by the Risk-Based Alerting (RBA) framework of Enterprise Security to generate notables. Read through our recent blog post that talks in detail.
With wide availability of tunneling tools and the intentionally extensible nature of DNS protocol, DNS Tunneling attacks are on the rise, specifically using command injection through DNS TXT response. To successfully detect these attacks, it is imperative to differentiate between legitimate and suspicious uses of DNS TXT records by analyzing textual content of the record. In this post, we discussed how we categorize DNS TXT responses into well defined categories and then use a ML based approach to accurately classify TXT responses as suspicious or not. Despite the nature of free text, the LSTM deep learning model accurately detects 99.05% of all suspicious DNS TXT records with a very low FPR of 0.11%, thereby reducing false alarms. The model accuracy of 99.79% indicates that there is good confidence in predictions. The LSTM model has been trained on a large representative dataset and tuned for optimal performance. The pre-trained model can be deployed using DSDL and used with a simple command ‘apply’ in SPL searches.
Any feedback or requests? Feel free to put in an issue on GitHub and we’ll follow up. Alternatively, join us on the Slack channel #security-research. Follow these instructions if you need an invitation to our Splunk user groups on Slack.
Special thanks to Splunk Threat Research and the Splunk Product Marketing Team.
This blog was co-authored by Abhinav Mishra (Principal Applied Scientist), Kumar Sharad (Senior Threat Researcher) and Namratha Sreekanta (Senior Software Engineer)

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.