
La résilience numérique porte ses fruits
Téléchargez cet e-book pour découvrir l'impact de la résilience numérique dans les entreprises.

Dans la partie 1 et la partie 2 de cette série, nous avons étudié la philosophie de conception de Splunk Connect for Syslog (SC4S), ses objectifs et la nouvelle architecture de transport basée sur HEC, ainsi que les bases de la configuration de pointe. Nous allons maintenant nous intéresser aux spécificités de la configuration de SC4S, notamment l’agencement du système de fichiers local (monté) et les domaines dans lesquels vous allez travailler.
La configuration de SC4S se produit à cinq niveaux principaux, décrits ci-dessous :
Niveau de configuration | Fichiers | Utilisation type |
Paramètres globaux et requis | env_file |
|
Métadonnées Splunk | splunk_metadata.csv* |
|
Catégorisation des événements de fournisseur/produit | vendor_product_by_source.* |
|
Remplacements de conformité Sous-filtres d’événements | compliance_meta_by_source.* |
|
Extension de plateforme (chemins de log) | lp-.conf.tmpl d_.conf s_.conf .conf.tmpl d_Ajouter une nouvelle source de données à SC4SAjouter une nouvelle destination à SC4S | Ajouter une nouvelle méthode de collecte (source) à SC4S
|
Les répertoires et les fichiers affichés en
rouge font partie d’une configuration SC4S standard et couvrent les composants requis, tels que l’URL et le jeton pour le point de terminaison Splunk HEC (qui est la destination par défaut du trafic SC4S), ainsi que la configuration des métadonnées Splunk (index, etc.). Les fichiers contenus dans les répertoires bleus contiennent des configurations pour les méthodes de collecte configurées localement (sources), les destinations de sortie et, le plus souvent, les chemins d’accès aux logs (filtres) des sources de données que SC4S ne prend pas en charge. La création de chemins de log sera traitée dans la partie 4 de cette série de blogs.
Pour le reste de cet article, nous nous concentrerons sur les fichiers et répertoires en rouge ci-dessus. Commençons par la configuration la plus courante (et indispensable) en définissant les variables d’environnement dans le fichier env_file.
Pour configurer SC4S, il faut d’abord définir les paramètres requis et des paramètres facultatifs courants nécessaires au fonctionnement de base de SC4S, et ce à l’aide du fichier env_file. Le fichier contient, comme son nom l’indique, des variables d’environnement utilisées par le shell du conteneur au démarrage, puis consultées par le processus de modélisation (décrit en détail dans la partie 4 de cette série d’articles) pour créer la configuration syslog-ng finale qui pilote SC4S. Voici un exemple simple, mais bien souvent suffisant, de fichier env_file.

Vous verrez que la signification de la plupart de ces variables est contenue dans leur nom. Ces variables incluent autant les variables requises (URL et jeton HEC Splunk) que les variables facultatives typiques décrites dans la documentation. Toutefois, les variables optionnelles mentionnées ci-dessus sont couramment utilisées et méritent une explication :
Cette liste n’est en aucun cas exhaustive, la documentation couvre l’ensemble des variables disponibles pouvant être définies dans ce fichier.
La configuration env_file suffit à elle seule pour de nombreux déploiements, mais trois domaines clés ne sont pas couverts par ce fichier :
Le répertoire de contexte contient des recherches et des éléments de configuration syslog-ng qui permettent d’effectuer toutes ces personnalisations.
Nous allons maintenant nous plonger dans cette section avec quelques exemples, en commençant par le fichier qui servira à la plupart des utilisateurs en raison des besoins d’indexation uniques de la plupart des entreprises : les fichiers splunk_metadata.csv*, généralement situés dans le répertoire /opt/sc4s/local/context (diagramme). L’objectif de ces fichiers est d’affecter des métadonnées Splunk de manière appropriée en fonction d’une clé (première colonne) définie dans le chemin de log pour cette source de données. Ces fichiers fonctionnent de la même manière que les répertoires de fichiers de configuration « default » et « local » dans Splunk. Le fichier « example » est analogue au fichier de configuration par défaut et ne doit pas être édité directement. En effet, la version interne de l’exemple de ce fichier est copiée dans le répertoire local uniquement à des fins de référence. Voici une portion de ce fichier :

Vous pouvez parcourir ce fichier pour déterminer l’index (et autres métadonnées) qui sera défini par défaut dans SC4S (ces entrées sont également documentées). Le fichier présente le format suivant :
vendor_product, metadata, value
où vendor_product est une clé arbitraire spécifiée par l’auteur du chemin de log en utilisant la convention du fournisseur (p. ex. cisco) et du produit (p. ex. asa) séparés par un underscore. Dans la plupart des cas, la clé est en minuscules ; les exceptions sont les sources CEF et LEEF où ces valeurs sont dérivées de l’événement et ne sont pas un choix arbitraire de l’auteur du chemin de log. Pour toutes les sources de données prises en charge par SC4S, les clés (et les valeurs par défaut index/sourcetype) sont documentées dans la section source de la documentation. La liste complète des substitutions disponibles est accessible ici et inclut des modèles de sortie alternatifs (qui régissent la façon dont un événement apparaîtra dans Splunk) ainsi que des métadonnées traditionnelles. Une seule métadonnée peut être définie par ligne ; si vous devez définir ou remplacer plusieurs métadonnées pour une même source, vous pouvez réutiliser la même clé sur plusieurs lignes.
Si une métadonnée particulière doit être remplacée (le plus souvent l’index), il est possible de modifier le fichier splunk_metadata.csv (sans l’extension d’exemple). Le fichier local (différent du fichier d’exemple) peut également être utilisé pour spécifier les métadonnées par défaut des nouveaux chemins de logs (nous le verrons dans la partie 4 de la série de blogs) :

Semblable aux fichiers .conf locaux dans Splunk, celui-ci est beaucoup plus court que le fichier par défaut. Il comprend simplement un remplacement de l’index Cisco ASA, ainsi qu’une nouvelle entrée pour le périphérique « StealthINTERCEPT » qui n’existe pas du tout dans le fichier d’exemple (car il n’est pas fourni avec SC4S). Cette dernière entrée concerne notre nouveau chemin de log, que nous allons traiter dans la partie 4.
Lorsque les événements arrivent dans SC4S, ils doivent être classés correctement afin que les métadonnées sourcetype et Splunk appropriées puissent être appliquées. Si un événement est capturé sur son propre port TCP ou UDP unique, la catégorisation est facile. Mais le plus souvent, l’événement doit être capturé sur le port UDP 514 par défaut, qui est historiquement réservé au trafic syslog et recevra nécessairement les événements de nombreux types de périphériques différents. Dans ce cas, le contenu de l’événement (charge utile) est examiné afin d’acheminer l’événement vers le chemin de log approprié, ce qui analyse l’événement et attribue les métadonnées appropriées. Cette approche fonctionne pour une majorité de types de périphériques, il existe cependant un groupe réduit mais important de dispositifs dont la charge utile n’est pas assez spécifique pour être catégorisée avec certitude.
Pour en tenir compte, SC4S fournit un moyen de classer (filtrer) les événements en fonction du nom d’hôte ou de l’adresse IP/CIDR d’origine, bien avant que l’examen de la charge utile ne soit effectué. Le filtre repose sur le fait qu’une caractéristique d’un événement entrant est connue avec certitude (l’adresse IP source) et une autre avec quasi-certitude (le nom d’hôte) avant l’inspection approfondie de la charge utile. Lorsque le filtre (règle) se déclenche sur un événement avec un nom d’hôte et/ou une adresse IP source spécifiques, un fichier de lookup est consulté afin d’attribuer à une variable interne une chaîne unique composée du fournisseur et du type de produit. Cette variable est ensuite utilisée comme filtre (séparé) dans un chemin de log créé pour la combinaison fournisseur/produit en question, permettant d’acheminer l’événement vers le chemin de log correct, quel que soit le contenu de la charge utile. Dans un exemple plus bas, nous examinerons le lien entre le filtre de contexte, le fichier de lookup et le filtre de chemin de log.
Tout d’abord, un avertissement : ce niveau de personnalisation nécessite pour la première fois une compréhension rudimentaire de la syntaxe syslog-ng, car les règles elles-mêmes et la lookup qu’elles consultent sont des configurations syslog-ng actives, exposées dans l’arborescence des répertoires locaux. Si ces fichiers sont mal configurés, l’interpréteur de démarrage de syslog-ng signale les erreurs, les consigne et abandonne le processus. Mais ne craignez rien, il existe des fichiers d’exemple bien remplis qui peuvent servir de modèle pour la plupart des scénarios d’utilisation, et nous allons les voir maintenant.
Lançons-nous. Les fichiers de contexte primaires se trouvent dans /opt/sc4s/local/context et ils sont au nombre de deux :
vendor_product_by_source.conf
vendor_product_by_source.csv
L’utilisation de ces fichiers diffère de la convention Splunk « default/local » typique utilisée pour splunk_metadata.csv. Pour utiliser correctement ces fichiers, ils doivent être complets (en d’autres termes, les fichiers « example » ne sont pas consultés du tout). Par conséquent, il est préférable de copier le contenu des fichiers d’exemple dans les fichiers ayant les extensions normales avant de commencer à les utiliser et les éditer.
Voici le fichier vendor_product_by_source.conf :

Vous pouvez voir qu’il s’agit d’une série de filtres syslog-ng qui peuvent être filtrés selon n’importe quelle « macro » (champ) syslog-ng, mais l’hôte et le masque de réseau sont les seuls utilisés car, comme nous l’avons vu plus haut, ce sont les seuls qui peuvent être exploités avec certitude avant un traitement plus approfondi de la charge utile. Ces filtres (règles) sont vérifiés très tôt dans le parcours des données via SC4S, juste après l’exécution des interpréteurs syslog rudimentaires et avant tout filtrage de charge utile.
Dans cet exemple, nous voyons à la ligne 11 un filtre pour les unités Juniper NetScreen dont les noms d’hôte sont jpns-* (le type « glob » indique qu’il s’agit d’un caractère générique et non d’une expression rationnelle). Dans ce cas, le masque de réseau est commenté, mais il est facile de l’appliquer s’il est connu. Vous verrez que ce fichier ne donne aucune indication quant à la catégorisation à appliquer, c’est là que le deuxième fichier (lookup), vendor_product_by_source.csv, entre en jeu :

Cette recherche présente la même structure à 3 colonnes que le fichier splunk_metadata.csv utilisé pour les métadonnées Splunk, mais les champs et les valeurs définis sont très différents et ne font pas directement référence aux métadonnées Splunk. Le secret de ces fichiers réside dans la façon dont la clé de lookup est utilisée : vous pouvez voir que le nom du filtre dans le fichier conf (ligne 11) correspond à une ou plusieurs clés du fichier csv de lookup (ligne 7). Lorsque le filtre du fichier conf se déclenche, ce lien définit un champ interne appelé fields.sc4s_vendor_product. Cette variable est ensuite utilisée dans un filtre simple qui vérifie la valeur de cette variable dans un chemin de log créé pour cette combinaison fournisseur/produit spécifique, ici Juniper NetScreen :

Vous vous demandez peut-être pourquoi nous n’utilisons pas simplement le filtre d’origine du chemin de log principal (mentionné juste au-dessus) plutôt que cette approche indirecte utilisant un champ interne. Il s’agit de permettre à l’administrateur de définir des filtres hostname/CIDR en utilisant une quantité minimale de code syslog-ng (reproductible), et surtout de ne pas avoir besoin d’accéder au chemin de log principal, qui est inaccessible à l’intérieur du conteneur. Dans ce cas, il n’est jamais nécessaire de modifier la ligne 43 du chemin de log principal (caché dans le conteneur) : elle est en effet pilotée par les filtres et les lookups des fichiers vendor_product_by_source.*.
On configure ensuite un deuxième ensemble de filtres de contexte, de la même manière que les filtres de contexte primaires décrits ci-dessus. La principale différence réside dans l’endroit où l’opération de filtrage a lieu : à un stade très avancé du chemin de log, longtemps après que la combinaison fournisseur/produit a été déterminée. Cela permet à l’administrateur de poursuivre la configuration, encore une fois à l’aide du nom d’hôte/bloc CIDR, mais aussi à l’aide d’autres macros (champs) syslog-ng qui pourraient avoir été créées en interne, dans le chemin de log lui-même. Ces remplacements (sous-filtres) peuvent être très utiles dans les cas d’usage de conformité, lorsqu’il faut étiqueter ou rediriger un sous-ensemble d’un type de périphérique (sourcetype) donné.
Une fois encore, les deux fichiers se trouvent dans le même répertoire /opt/sc4s/local/context/ :
compliance_meta_by_source.conf
compliance_meta_by_source.csv
Comme pour le premier ensemble de fichiers de contexte de fournisseur/produit abordé ci-dessus, il est préférable de dupliquer les versions « example » avant de commencer. Cet ensemble de fichiers étant généralement bien plus court que le premier ensemble, les fichiers d’exemple peuvent être simplement utilisés comme référence.
Voici les deux fichiers compliance_meta_by_source :
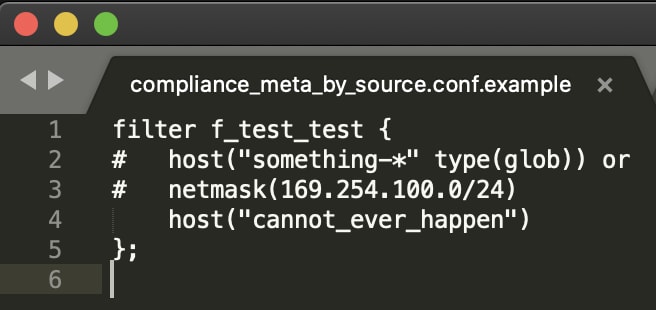

Vous pouvez voir en effet qu’il s’agit de données fictives et observer également une autre caractéristique intéressante : la deuxième colonne du fichier csv n’est pas limitée aux métadonnées Splunk, mais peut être définie sur n’importe quelle macro syslog-ng. Elle peut en fait être employée pour définir une paire champ=valeur indexée arbitraire (par exemple, compliance=pci) qui peut être envoyée à Splunk, ce qui peut être très utile pour des questions de conformité. Toutefois, dans le cadre de cette flexibilité, les entrées de métadonnées Splunk doivent comporter le préfixe .splunk. utilisé en interne (par exemple .splunk.index) pour remplacer l’index. Ces détails sont abordés dans la section de configuration de la documentation.
Après avoir terminé toutes les étapes de configuration des sources de données existantes, nous allons pouvoir passer à notre tâche finale dans la prochaine partie (partie 4). Nous couvrirons l’extension de la plateforme SC4S en analysant le processus de modélisation et la création de nouveaux « chemins de log » pour inclure des sources de données non prises en charge au départ. Il s’agit du niveau le plus élevé de personnalisation de SC4S ; bien qu’une expérience avec syslog-ng soit utile, vous verrez que le processus de modélisation facilite considérablement la tâche !
Splunk Connect for Syslog est entièrement pris en charge par Splunk et publié comme logiciel open source. Nous espérons motiver une communauté vivante qui nous apportera ses commentaires et des idées d’amélioration, et nous aidera à communiquer et surtout à créer des chemins de log (filtres) ! Nous encourageons une participation active via les dépôts git, où vous pourrez faire des requêtes formelles d’inclusion de fonctionnalités (en particulier de chemin de log/filtres), de suivi de bug, etc. Au fil du temps, il devrait y avoir de moins en moins de « filtres locaux » car les efforts de la communauté seront encapsulés dans les configurations prêtes à l’emploi des conteneurs.
De nombreuses ressources sont à votre disposition pour vous aider à réussir avec SC4S ! En plus du dépôt principal et de la documentation, vous pouvez également consulter :
Tous nos vœux de réussite avec SC4S. Impliquez-vous, essayez, posez des questions, proposez de nouvelles sources de données et rencontrez de nouvelles personnes !
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.

La plateforme Splunk élimine les obstacles qui séparent les données de l'action, pour donner aux équipes d'observabilité, d'IT et de sécurité les moyens de préserver la sécurité, la résilience et le pouvoir d'innovation de leur organisation.
Fondée en 2003, Splunk est une entreprise internationale. Ses plus de 7 500 employés, les Splunkers, ont déjà obtenu plus de 1 020 brevets à ce jour, et ses solutions sont disponibles dans 21 régions du monde. Ouverte et extensible, la plateforme de données Splunk prend en charge les données de tous les environnements pour donner à toutes les équipes d'une entreprise une visibilité complète et contextualisée sur l'ensemble des interactions et des processus métier. Splunk, une base solide pour vos données.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2025 Splunk LLC Tous droits réservés.
© 2005 - 2025 Splunk LLC Tous droits réservés.

