Qu’est-ce que la supervision synthétique ?


Splunk Synthetic Monitoring
La supervision synthétique s’intéresse aux performances des sites web. Elle simule un parcours de transaction entre un client et un serveur d’application, et supervise son déroulement.
L’objectif de la supervision synthétique est de comprendre quelle expérience peut vivre un utilisateur réel d’une application ou d’un site web.
Cet article analyse le sujet en profondeur. Vous apprendrez certainement quelques astuces pour rentabiliser au maximum vos outils et votre stratégie de supervision synthétique.
Qu’est-ce que la supervision synthétique ?
La supervision synthétique est un type de supervision informatique qui porte spécifiquement sur les performances des sites web. Il en existe d’autres types, comme la supervision des performances des applications et la supervision des utilisateurs réels. Chacune a ses points forts et ses points faibles.
La supervision synthétique peut être utilisée pour répondre à de nombreuses questions :
- Performance et disponibilité des sites web : « Est-ce que mon site fonctionne ? À quelle vitesse mon site se charge-t-il ? »
- Résolution des incidents : « Avons-nous corrigé les erreurs dans les transactions de panier d’achat ? »
- Possibilités d’optimisation : « Est-ce que les utilisateurs subissent un quelconque blocage à un stade de cette transaction ? De quelle façon ou à quel endroit puis-je l’optimiser ? »
Les meilleurs outils de supervision synthétique vous permettent de faire des tests à toutes les étapes du développement, d’opérer une supervision 24h/24 dans un environnement contrôlé, de faire des tests A/B en évaluant l’impact sur les performances, de faire des analyses comparatives par rapport à la concurrence et d’analyser les tendances de performance entre différentes régions.
(Découvrez Splunk Synthetic Monitoring, un outil de pointe pour les environnements d’entreprise.)
Comment fonctionne la supervision synthétique ?
Les fournisseurs de supervision synthétique délivrent une infrastructure distante (souvent mondiale). Cette infrastructure visite périodiquement un site web et enregistre les données de performance pour chaque exécution.
Il est important de souligner que le trafic mesuré n’est pas celui d’utilisateurs réels : il est synthétisé pour collecter des données sur les performances de la page.
Un outil simple de simulation de supervision synthétique comprend trois composants :
- Des nœuds d’agent qui sondent activement un composant de service web.
- Un composant de génération de scénario qui décrit les caractéristiques de l’environnement pour la transaction client-serveur.
- Un composant de service web dynamique qui simule la charge dans le contexte des caractéristiques environnementales définies.
Dans la supervision synthétique, vous pouvez programmer un script afin de générer un parcours de transaction client-serveur pour un éventail de scénarios, de types d’objet et de variables d’environnement. L’outil de supervision synthétique collecte et analyse les données de performance tout au long du parcours du client qui interagit avec votre application ou votre serveur web :
- Un agent synthétique sonde activement le composant de service web cible pour générer une réponse de transaction.
- Une fois la connexion établie avec la cible, l’outil collecte des données de performance sur les opérations typiquement réalisées par un utilisateur final.
(À lire également : Données synthétiques.)
Qu’inspecte la supervision synthétique ?
Des contrôles de supervision synthétique sont effectués à intervalles réguliers. La fréquence de ces vérifications dépend généralement de ce qu’on mesure. La disponibilité, par exemple, peut être vérifiée une fois par minute.
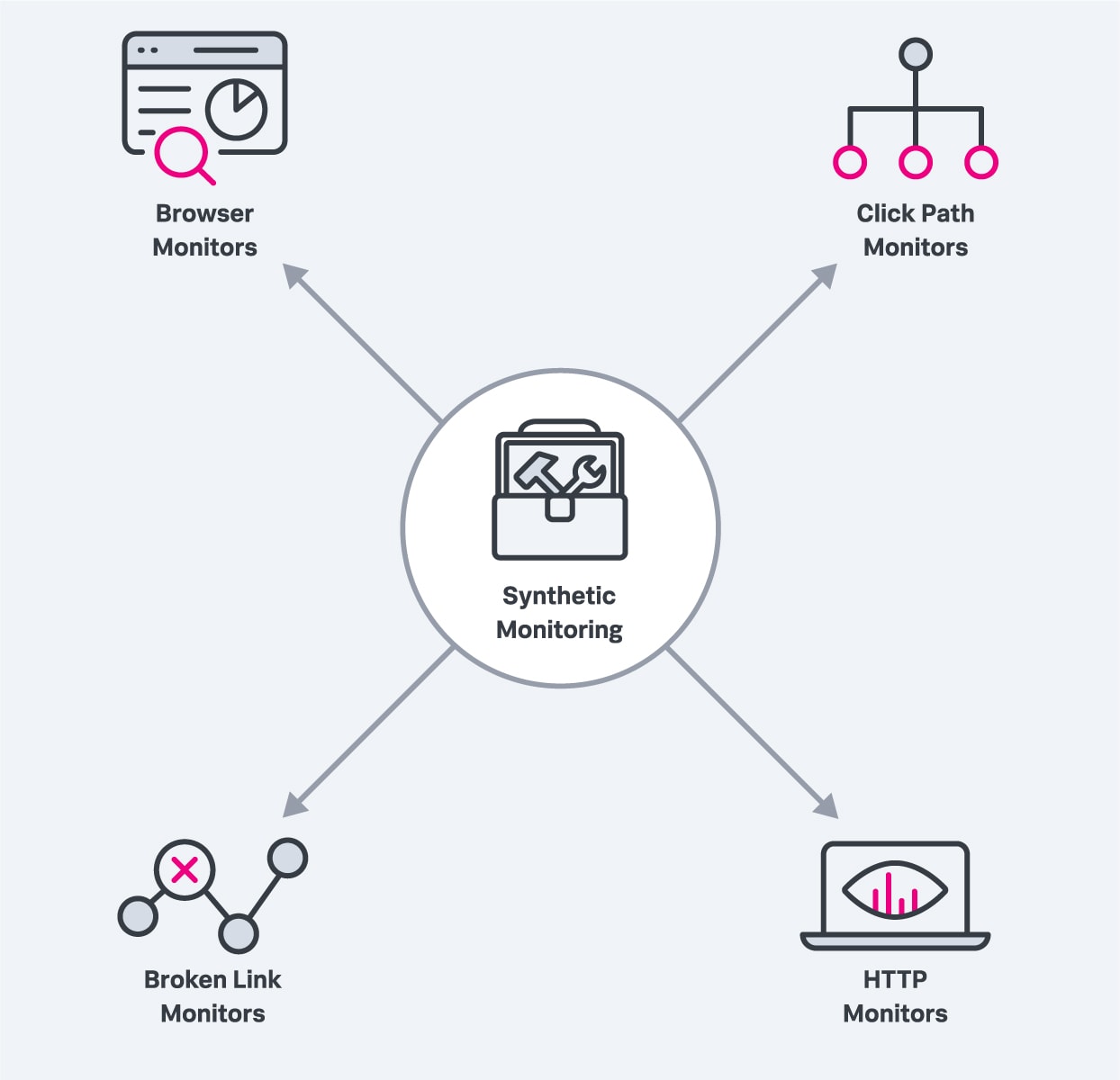
Vous pouvez configurer différents types de moniteurs :
Moniteurs de navigateur : un moniteur de navigateur réel simule l’expérience d’un utilisateur qui visite votre site web à l’aide d’un navigateur web moderne. Il peut être lancé très régulièrement à partir de différents emplacements et vous alerter en cas de problème :
- indisponibilité de votre site ou de votre application,
- dégradation des performances par rapport au profil de référence.
Moniteurs de parcours de clics : les moniteurs de parcours de clics simulent, eux aussi, la visite d’un utilisateur sur votre site, mais ils examinent des workflows spécifiques. Vous créez un script personnalisé qui navigue sur votre site web, qui supervise une séquence spécifique de clics et d’actions de l’utilisateur, et qui peut être exécuté à intervalles réguliers.
Moniteurs de liens cassés : cette fois, vos scripts vont tester tous les liens d’une URL spécifique. L’outil produit un rapport des échecs pour vous permettre de corriger les liens cassés.
Moniteurs HTTP : les moniteurs HTTP envoient des requêtes HTTP pour déterminer la disponibilité d’endpoints ou de ressources d’API spécifiques. Ils doivent vous permettre de définir des seuils de performance et vous alerter lorsque les performances chutent en dessous du seuil de référence.
Supervision synthétique et supervision des utilisateurs réels
- Plutôt que d’utiliser les données de vrais utilisateurs ou d’interactions réelles, la supervision synthétique génère des données de trafic synthétique pour obtenir des informations sur les performances d’une page.
- La supervision des utilisateurs réels (RUM) injecte un agent sur chaque page d’un site web ou d’une application. Cet agent rapporte des données de chargement réelles pour chaque requête effectuée par un utilisateur, sur chaque page.
Scénarios de retards dans les communications client-serveur
Imaginons différents scénarios de retards dans les communications client-serveur.
- Un retard global peut être causé par une défaillance du réseau ou un problème de dépendance. L’anomalie entraîne un prolongement significatif du temps de réponse pour tous les utilisateurs. Cela peut se produire, par exemple, au moment de la publication d’une nouvelle fonctionnalité qui introduit une requête de base de données particulièrement lente que le QA n’a pas détectée.
- Il arrive également qu’un retard n’affecte qu’une partie de l’infrastructure de services web. C’est le cas, par exemple, si un problème matériel affecte le système d’équilibrage de charge : tous les serveurs enregistrent alors un retard partiel dû à un problème sur un seul d’entre eux.
- Un retard périodique se produit de façon répétitive, parfois selon des intervalles irréguliers. C’est ce qui se produit, par exemple, lorsque des sauvegardes de données régulières occupent la bande passante du réseau et introduisent des retards pendant les périodes de pointe.
L’agent de supervision synthétique émule le comportement d’un utilisateur réel et permet à l’outil de supervision de recueillir des données sur des métriques prédéfinies, comme la disponibilité et le temps de réponse. Cet agent suit une routine de test programmable. La configuration de cette routine comprend différents paramètres :
- les identifiants des composants de service web à tester,
- la séquence de processus, activités et interactions entre l’agent et le service web,
- l’intervalle d’échantillonnage des données et la durée des tests.
Le composant de génération de scénario injecte un éventail de scénarios de test reflétant une dégradation de performance ou des défaillances du réseau. Il peut également définir la façon dont sont répartis les agents pour simuler l’accès d’une base d’utilisateurs mondiale accédant à un même service web depuis différents datacenters, ainsi que des évolutions des caractéristiques de cette base d’utilisateurs.
Comment exploiter les résultats de la supervision synthétique
Les rapports de supervision synthétique peuvent être graphiques ou se présenter sous la forme de données de séries chronologiques. Vous pouvez ensuite analyser ces résultats à l’aide de diverses méthodes d’analyse statistique et de machine learning.
Les analystes étudient généralement :
- Les pics, qui signalent des problèmes de performance extrêmes face à une augmentation brutale du trafic de données.
- Les indicateurs périodiques, comme des retards réguliers dans la réponse à une requête émise par un agent client à un service.
- Les tendances, qui suggèrent une évolution graduelle mais constante au fil des observations de données chronologiques.
- Les données aberrantes, qui peuvent être considérées comme un comportement anormal. Il peut être nécessaire d’effectuer d’autres analyses pour déterminer l’importance de ces valeurs aberrantes, mais aussi d’étudier le rapport coûts-bénéfice de leur correction.
- L’analyse exploratoire, qui évalue l’évolution des observations chronologiques avant et après un problème ou une action de l’agent.
- L’analyse des points de changement, qui détermine une moyenne mobile des données ; ces informations sont souvent évaluées en relation avec l’analyse des tendances. Elles permettent aux analystes d’évaluer les changements importants survenant au fil de l’expérience de l’utilisateur.
- Les cycles/boucles de feedback, qui permettent de prévoir les prochains scénarios de supervision sur la base des connaissances obtenues à partir des observations présentes.
L’analyse active par des agents permet de superviser différents aspects : API, composants, performances et tests de charge, entre autres.
L’idée clé consiste à émuler un scénario du monde réel à la demande. Ces interactions peuvent être rares et sporadiques.
Pour la grande entreprise : les fonctions de supervision synthétique incontournables
Maintenant que nous comprenons mieux de quoi il s’agit, nous pouvons vous aider à choisir le meilleur outil pour vos besoins. Nous avons dressé la liste des fonctionnalités que doit posséder tout outil de supervision synthétique robuste et professionnel. Passons-la en revue.
Scripts de flux utilisateur et de transactions commerciales
L’un des grands avantages de la supervision synthétique réside dans la possibilité de définir les actions spécifiques à tester afin de parcourir les itinéraires clés de votre application (paiement ou inscription, par exemple) afin de vérifier qu’ils sont opérationnels et performants. C’est ce qu’on appelle la rédaction de scripts. Les fonctions de script d’un outil déterminent directement son utilité.
En matière de script, un outil doit proposer plusieurs fonctionnalités essentielles :
- Comment enregistre-t-on les scripts ?
- Existe-t-il un enregistreur basé dans le navigateur ?
- Faut-il rédiger du code ou des étapes à la main ?
- Peut-on modifier manuellement des tests enregistrés ou faut-il les réenregistrer entièrement ?
- Quel niveau de compétence technique faut-il posséder pour enregistrer un script ?
- Est-ce que l’outil permet d’importer des scripts dans un format standard (comme celui de l’IDE Selenium) ?
Naturellement, comme les sites web des entreprises changent quotidiennement et que les scripts peuvent cesser de fonctionner, il faut également que l’outil possède des fonctions de dépannage :
- Peut-on tester un script ?
- Est-ce que l’outil indique quelles étapes ont échoué et pourquoi ?
- Est-ce qu’il enregistre des captures d’écran ou des vidéos de l’exécution du script pour que vous puissiez voir ce qui se passe à l’écran lorsqu’un bouton ou un champ de formulaire est introuvable ?
- Peut-on exporter le script dans un format standard pour pouvoir le dépanner dans un autre contexte au besoin ?
À titre d’exemple, voici ce que l’enregistreur de l’IDE Selenium affiche lorsqu’il teste un « flux utilisateur de paiement » critique.

Mesurer et comparer les performances
Un grand avantage des outils synthétiques est qu’ils vous permettent d’expérimenter différents scénarios pour évaluer leur impact sur les performances. Vous devez avoir des options flexibles pour évaluer de façon simple et claire l’impact de vos initiatives de performance.
Quelques exemples classiques :
- tester votre site avec et sans réseau de livraison de contenu (CDN), ou avec différents CDN,
- exclure des tiers spécifiques et évaluer l’impact sur les performances,
- comparer les performances mobiles aux performances de bureau, ou même les performances de différents environnements mobiles,
- déterminer l’impact des points de défaillance uniques,
- comparer les performances de différents groupes de test A/B,
- tester de nouvelles fonctionnalités qui ne sont pas déployées auprès de tous les utilisateurs,
- utiliser différents emplacements pour déterminer si la localisation géographique accentue des problèmes de performance.
Les possibilités d’un outil de supervision synthétique dépendent essentiellement du contrôle que vous pouvez exercer sur un test. Voici quelques options de configuration utiles pour évaluer les résultats d’expériences courantes sur les performances web :
- Pouvez-vous configurer le test de manière à exclure les requêtes de certains domaines ou URL ?
- Pouvez-vous surcharger les DNS ou les noms d’hôte afin qu’ils pointent vers d’autres adresses IP ?
- Pouvez-vous précharger des cookies spécifiques pour effectuer un test ?
- Pouvez-vous faire des tests avec une connexion 4G, 5G ou autre ?
- Pouvez-vous ajouter des en-têtes HTTP personnalisés aux requêtes ?
- Pouvez-vous spécifier l’appareil, la taille d’écran ou l’agent utilisateur employés ?
- Pouvez-vous préciser l’emplacement géographique ? Avec quel degré de précision ? (Est-ce que je fais un test depuis le « Canada » ou depuis « Vancouver, Colombie-Britannique, au Canada » ?)
Vous l’aurez compris, la configuration des différentes options du test n’est qu’une partie de la bataille. Dans tous ces scénarios, vous allez recueillir des données de performance sur vos sites et vos applications dans différentes conditions, puis vous devrez les comparer.
Il est essentiel que votre solution synthétique vous permette de comparer les données et de visualiser les différences, car c’est ce qui vous donnera rapidement et facilement des résultats. Une petite sélection des « incontournables » :
- Pouvez-vous comparer deux mesures spécifiques ?
- Pouvez-vous obtenir l’amélioration absolue et relative ? Par exemple : le temps d’affichage complet s’est amélioré de 400 ms ou 24 %.
- Pouvez-vous comparer les vidéos ou les cascades côte à côte ?
- Pouvez-vous obtenir plusieurs échantillons de chaque configuration et les comparer sur un graphique ?
À titre d’exemple, voici un rapport comparatif dans Splunk Synthetic Monitoring :

Des fonctions d’alerte et des intégrations robustes
La supervision synthétique est l’un des meilleurs moyens de détecter les pannes et les problèmes de disponibilité parce qu’elle teste activement votre site depuis l’extérieur. Mais pour remplir correctement cette fonction essentielle, elle doit permettre de définir les conditions de défaillance et envoyer des notifications.
Quelques critères utiles :
- Pouvez-vous exécuter des tests depuis différents points d’une grande région où se trouvent la plupart de vos visiteurs ?
- Quelle est la fréquence des tests ?
- Pouvez-vous vérifier la présence ou l’absence de texte ?
- Pouvez-vous vérifier le code de réponse ?
- Est-ce que les problèmes de connexion (DNS, TCP, etc.) déclenchent une condition de défaillance ?
- Est-ce que des problèmes de certificat SSL peuvent déclencher une condition de défaillance ?
Des difficultés d’accès au site ne traduisent pas nécessairement une défaillance. Les faux positifs peuvent entraîner une insensibilisation aux alertes. Pour l’éviter, voici quelques fonctionnalités plus sophistiquées à rechercher également :
- Est-ce que l’outil présente une capture d’écran ou le code source du contexte de l’erreur ?
- Est-ce que l’outil retente automatiquement un test qui a échoué pour vérifier la présence d’une défaillance ?
- Pouvez-vous faire des tests depuis plusieurs emplacements ?
- Est-ce que l’outil utilise les résultats de plusieurs sites pour distinguer automatiquement les défaillances régionales des défaillances globales ?
Voici par exemple une capture d’écran (affichée dans Splunk Synthetic Monitoring) d’une page ayant renvoyé une erreur :

Une fois que votre solution de supervision synthétique a détecté une défaillance, il faut qu’elle informe votre équipe. La méthode de notification dépend de vos workflows, mais l’e-mail et le SMS sont un minimum vital.
Au-delà de ça, recherchez des options de notification que vous pouvez intégrer aussi étroitement que possible aux workflows et au style de votre équipe. Vous optimiserez ainsi la vitesse à laquelle votre équipe verra et réagira à un problème.
Pensez notamment aux options suivantes :
- Vous avez des équipes mobiles dans plusieurs pays ? Vous aurez besoin d’un outil qui envoie des notifications push.
- Des équipes décentralisées ? Est-ce que l’outil peut envoyer des messages à des équipes ou des canaux dans des applications de messagerie (Slack, Microsoft Teams, etc.) ?
- Vous utilisez déjà un outil pour vos opérations ? Cherchez une solution offrant des intégrations prêtes à l’emploi.
- Est-ce que la solution propose une option d’alerte « envoyer un webhook » générique ? C’est une méthode pratique qui permet de connecter la solution au reste de votre processus, quels que soient les outils qui le composent.
Voici à quoi ressemble un webhook personnalisé classique. Vérifiez que l’outil synthétique que vous choisirez possède une fonctionnalité similaire :

Test en pré-production
L’une des grandes forces des solutions de supervision synthétique est qu’elles vous aident à évaluer les performances et l’expérience utilisateur (UX) d’un site sans attendre qu’un grand nombre d’utilisateurs réels ne génèrent du trafic.
Autrement dit, les outils de supervision synthétique peuvent être utilisés dans les environnements de pré-production et intermédiaires (préparation, UAT, QA, etc.) pour vous permettre de comprendre les performances de votre site pendant la phase de développement. Cela s’avère extrêmement puissant pour utiliser les performances comme critère décisionnel et éviter les régressions au fil du temps.
Pour cela, votre solution doit pouvoir atteindre vos environnements de travail et y collecter des données de performance. Elle doit également s’adapter à certaines nuances de configuration propres aux environnements de test. Voici quelques questions à vous poser si vous voulez accéder aux environnements de pré-production :
Est-ce que le site de test se trouve à l’extérieur de votre environnement ? Aurez-vous besoin d’autoriser certaines adresses IP ? Quelle quantité de travail est-ce que cela représente pour votre équipe de sécurité ?
- Pouvez-vous ignorer les erreurs de certificat SSL (parce que vous utilisez une autorité de certification interne ou un certificat auto-signé) ?
- Pouvez-vous installer quelque chose dans votre environnement pour exécuter des tests ? Avez-vous besoin d’ouvrir des ports pour que cela fonctionne correctement ?
- Est-ce que le système est physique ou virtuel ? Si l’environnement est virtualisé, quelle est la technologie employée (VM, Docker, paquet logiciel) ?
- Quelles ressources faut-il pour exploiter l’emplacement de test interne ?
- Combien de tests simultanés pouvez-vous exécuter, et comment pouvez-vous augmenter ce chiffre ?
À titre d’exemple, Splunk Synthetic Monitoring fournit des instructions à copier-coller pour lancer une instance de Docker afin de tester les sites de pré-production :

Benchmark compétitif et sectoriel
L’un des grands intérêts des outils synthétiques est qu’ils permettent de comparer dans le détail les performances de vos applications à celles des autres acteurs de votre secteur.
Et c’est une spécificité de la supervision synthétique ! En effet, les autres outils comme la RUM et l’APM nécessitent d’insérer une balise JavaScript sur le site ou d’installer un agent logiciel dans l’infrastructure de back-end – et vous ne pouvez pas le faire sur le site d’autres entreprises que la vôtre.
Avec un outil synthétique, il est aussi facile d’évaluer le site d’un concurrent que le vôtre : indiquez simplement l’URL, c’est tout !
Il faut tout de même savoir que différents produits de sécurité web peuvent s’interposer et bloquer le trafic des outils de test synthétique en même temps que celui des adversaires, des robots et autres agents frauduleux. Vous découvrirez souvent que les adresses IP des fournisseurs de cloud et des datacenters utilisés par les fournisseurs de supervision synthétiques sont bloquées. Pour bien choisir votre solution de supervision synthétique, vous devez donc vous demander :
Pouvez-vous exécuter des tests depuis des emplacements que vos concurrents ne bloquent pas ?
Si les produits de sécurité de vos concurrents bloquent les tests synthétiques, cela peut également être dû à l’agent utilisateur. Si l’agent utilisateur est différent de ce qu’utilise un navigateur classique, vous pouvez être bloqué. D’où cette autre fonctionnalité à rechercher :
Pouvez-vous personnaliser l’agent utilisateur pour éliminer tout ce qui peut identifier un outil de tests synthétiques ?
Une fois que vous pouvez collecter des données de performance et d’expérience utilisateur chez un concurrent, vous avez tout ce qu’il vous faut pour comparer ses résultats à ceux de votre site. Vous aurez alors besoin de savoir :
- Pouvez-vous facilement comparer plusieurs concurrents dans la même vue ?
- Existe-t-il un moyen simple d’expliquer à des personnes qui n’ont pas un profil technique en interne quel site est « le meilleur » et pourquoi ?
- Est-ce que l’outil propose un score composite, à l’instar du score de performance Google Lighthouse, pour comparer plus facilement un site à un autre ?
Pour exemple, voici un tableau de bord Benchmark compétitif dans Splunk Synthetic Monitoring :

Pour extraire un maximum de valeur de votre solution synthétique, posez-vous les questions suivantes :
- Pouvez-vous facilement configurer des tests, et les contrôles sont-ils suffisamment flexibles pour faire différentes expérimentations ?
- La solution est-elle facile à intégrer dans votre workflow d’alerte existant ?
- Pouvez-vous facilement l’intégrer dans vos environnements de test en pré-production ?
- Pouvez-vous facilement visualiser et comparer différents tests et tendances au fil du temps ?
Les défis de la supervision synthétique
L’un des grands défis de la supervision synthétique réside dans la validité des hypothèses qui sous-tendent l’élaboration d’un scénario d’utilisation. En effet, on ne peut pas prédire ce qu’un utilisateur va faire. Dans un contexte réel, les utilisateurs se comportent parfois de façon inattendue. Le composant de génération de scénarios, décrit plus haut, ne sera pas forcément capable d’émuler un ensemble exhaustif de scénarios réels complexes.
Vous pouvez toutefois dépasser ces limites. En associant la supervision synthétique et la supervision des utilisateurs réels, vous obtiendrez une visibilité idéale : vous aurez à la fois les données produites par la supervision synthétique et les informations de la supervision des utilisateurs réels, ce qui vous permettra de réaliser des analyses statistiques éclairées et réalistes.
Splunk Synthetic Monitoring
Splunk Synthetic Monitoring supervise les performances et l’UX côté client et vous indique comment améliorer et optimiser vos applications. Vous pouvez même intégrer cette pratique à vos workflows CI/CD : automatisez les tâches manuelles et opérationnalisez la performance dans toute l’entreprise.
- Supervision IT
- Application Performance Monitoring
- APM et supervision des performances du réseau
- Supervision de la sécurité
- Supervision du cloud
- Supervision des données
- Supervision des endpoints
- Supervision DevOps
- Supervision de l’IaaS
- Supervision de l’infrastructure Windows
- Supervision active et supervision passive
- Supervision multicloud
- Supervision du réseau cloud
- Supervision des bases de données
- Supervision de l’infrastructure
- Supervision de l’IoT
- Supervision Kubernetes
- Supervision du réseau
- Supervision de la sécurité du réseau
- Supervision RED
- Supervision des utilisateurs réels
- Surveillance des serveurs
- Supervision des performances des services
- Supervision SNMP
- Supervision des systèmes de stockage
- Supervision synthétique
- Outils et fonctionnalités de la supervision synthétique
- Supervision synthétique et RUM
- Supervision du comportement des utilisateurs
- Supervision des performances des sites web
- Supervision des logs
- Supervision continue
- Supervision sur site
- Supervision, observabilité et télémétrie
Une erreur à signaler ? Une suggestion à faire ? Contactez-nous à l’adresse ssg-blogs@splunk.com.
Cette publication ne représente pas nécessairement la position, les stratégies ou l’opinion de Splunk.


Articles connexes
À propos de Splunk
La plateforme Splunk élimine les obstacles qui séparent les données de l'action, pour donner aux équipes d'observabilité, d'IT et de sécurité les moyens de préserver la sécurité, la résilience et le pouvoir d'innovation de leur organisation.
Fondée en 2003, Splunk est une entreprise internationale. Ses plus de 7 500 employés, les Splunkers, ont déjà obtenu plus de 1 020 brevets à ce jour, et ses solutions sont disponibles dans 21 régions du monde. Ouverte et extensible, la plateforme de données Splunk prend en charge les données de tous les environnements pour donner à toutes les équipes d'une entreprise une visibilité complète et contextualisée sur l'ensemble des interactions et des processus métier. Splunk, une base solide pour vos données.

Abonnez-vous à notre blog
Recevez les derniers articles de Splunk par e-mail.

