

La résilience numérique porte ses fruits
Téléchargez cet e-book pour découvrir l'impact de la résilience numérique dans les entreprises.

La nouvelle de la « backdoor Sunburst » délivrée via le logiciel SolarWinds Orion a conduit les organisations à arrêter Orion pour se protéger. Parmi elles, plusieurs agences gouvernementales américaines suivent les récentes recommandations de la CISA. Si vous envisagez d’adopter une démarche similaire dans votre propre environnement, l’une des prochaines étapes stratégiques consiste à restaurer rapidement la visibilité que vous avez perdue sur la santé et les opérations de votre infrastructure.
Pour y parvenir, nous allons vous présenter les capacités de supervision et de diagnostic de l’infrastructure de Splunk, qui peuvent vous rendre une grande part de la visibilité perdue avec l’arrêt d’Orion.
Nous avons rédigé cet article pour vous proposer des conseils rapides à mettre en œuvre et produire un maximum de résultats avec le minimum de coûts et d’efforts. Si vous lisez ce blog, il y a de fortes chances pour que vous ayez déjà Splunk dans votre environnement et que vous ayez déjà déployé un forwarder universel dans votre infrastructure la plus critique. Dans cette optique, nous voulions vous proposer les étapes suivantes, utilisables sans délai, pour vous aider à gérer le risque introduit par la backdoor Sunburst :
Comme dans toute menace ou attaque de cybersécurité, la détection, l’isolement et l’atténuation sont les plus grandes priorités. Les experts en sécurité de Splunk travaillent pour vous fournir des conseils afin de détecter l’activité de la backdoor Sunburst, et protéger votre réseau. Consultez l’article « Méthodes de détection de la backdoor Sunburst dans Splunk » pour plus d’informations.
Dans le reste de cet article, nous allons nous appuyer sur quelques hypothèses de base concernant votre environnement ; de ce fait, certains conseils et détails ne seront pas couverts. Nous partons du principe que vous avez déjà accès à un environnement Splunk vers lequel vous pouvez envoyer des données. Nous partons du principe que l’essentiel ou l’intégralité de l’infrastructure que vous souhaitez superviser est déjà munie du Forwarder universel. Enfin, nous partons du principe que vous avez accès à un administrateur Splunk ou que votre équipe Splunk possède une maîtrise correcte de la gestion et du déploiement de nouvelles configurations via le serveur de déploiement ou d’autres méthodes, et qu’elle peut donc contribuer au déploiement des modifications décrites ici.
Dans cette section, nous allons voir les étapes nécessaires pour :
Comme toujours, la première étape consiste à importer les données requises dans Splunk pour visualiser et superviser nos hôtes. Nous allons utiliser les extensions Windows et Unix/Linux pour recueillir des informations sur chaque hôte. Au besoin, la configuration de ces extensions est couverte en détail dans la section « Applications et extensions » de notre documentation, et nous proposons également un rapide tutoriel en vidéo couvrant les bases de l’importation des données Windows et Linux dans Splunk. Enfin, voici des liens vers des exemples de configurations inputs.conf pour les Métriques et événements d’OS Windows et les Métriques et événements d’OS Linux, que vous pouvez déployer sur le forwarder universel pour superviser efficacement votre infrastructure d’hôtes.
Visualisez l’utilisation du CPU, des disques, de la mémoire et du réseau de tous les hôtes Linux et Windows de votre environnement.
Dans l’Application Splunk pour Infrastructures gratuite (et désignée par la suite comme SAI), vous pouvez rapidement connaître l’état de santé de vos entités dans la vue en vignettes du panneau Investigation. Vous pouvez appliquer des filtres pour afficher des hôtes en particulier ou laisser toutes les entités visibles. Dans cet exemple, nous avons un code couleur pour cpu.system, qui indique l’utilisation du CPU des hôtes Windows ou Linux. Dans cette vue, vous pouvez définir un seuil pour cpu.system et voir quelles vignettes deviennent rouges lorsqu’un hôte dépasse cette valeur seuil.

Pour visualiser toutes les métriques fondamentales d’un hôte spécifique, cliquez simplement sur la vignette de l’hôte en question. Par exemple, auth-01.
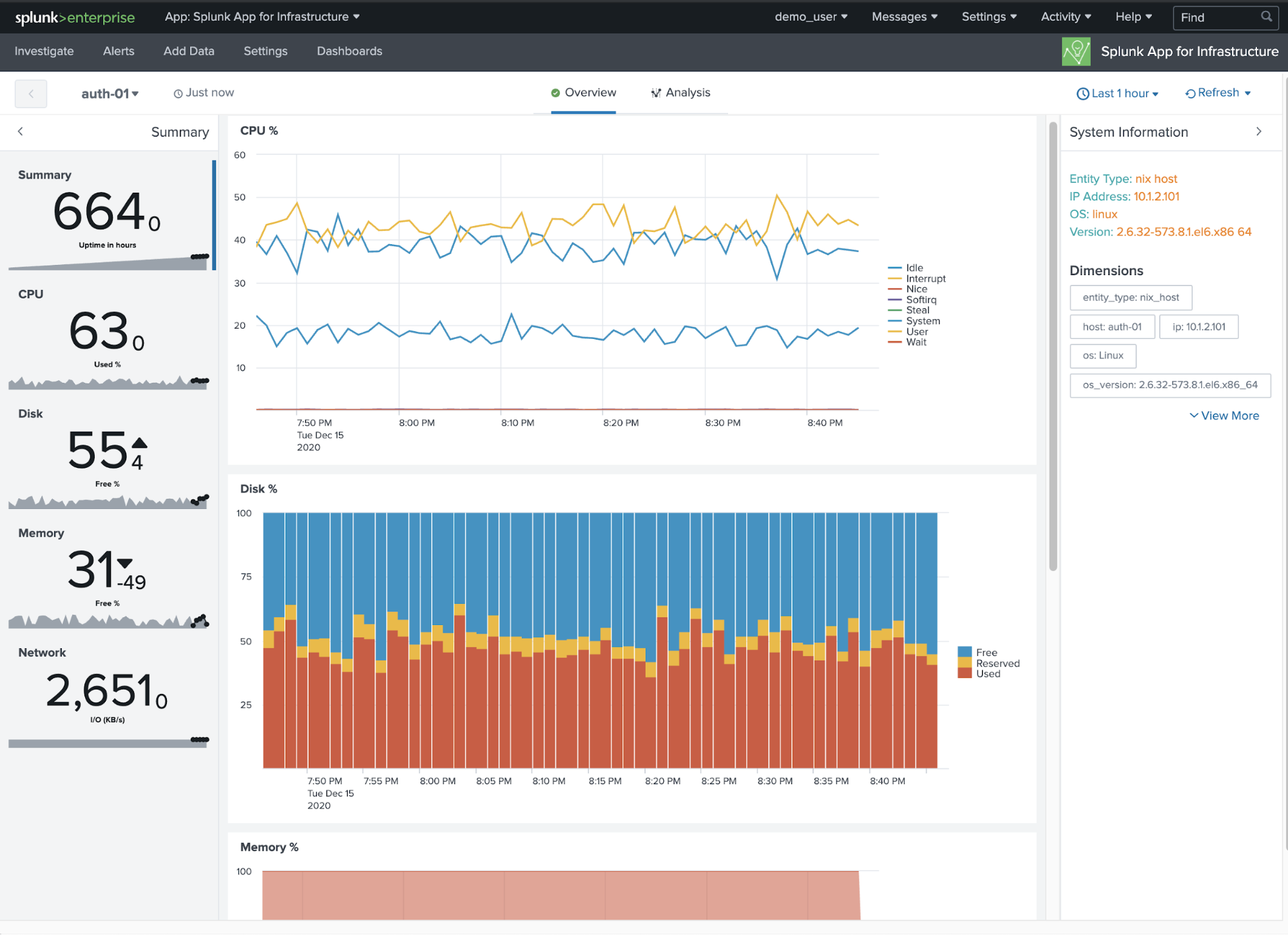
Si les métriques vous permettent d’isoler les hôtes problématiques et de déterminer à quel moment ces problèmes sont survenus, ce sont souvent les logs et les événements qui contiennent les informations nécessaires pour parvenir à la véritable cause du problème. Utilisez Splunk pour isoler les logs et les événements provenant de l’hôte et recherchez les indicateurs courants de problèmes, tels que « error » ou « failed ».
index=* host=* sourcetype=* (error OR fail*) |

Une utilisation importante du CPU peut être le signe que l’hôte rencontre un problème. Si l’utilisation du système est excessive, cela signifie que sa capacité n’est pas à la hauteur de la demande exercée sur le CPU. Utilisez des indicateurs pour détecter les utilisations importantes du CPU avant qu’elles n’affectent les performances du système, puis créez une alerte quand cette métrique dépasse un seuil défini.
Remarque : Cette procédure peut être modifiée pour générer une alerte en cas d’utilisation importante des disques ou de la mémoire. Utilisez la recherche ci-dessous pour voir tous les indicateurs disponibles dans vos index de métriques.
| mcatalog values(metric_name) WHERE index=* |
Dans cet exemple, nous allons utiliser la métrique % Processor Time (% temps de processeur) comme indicateur d’une utilisation élevée du CPU avec un seuil de 95 %.
| mstats avg(_value) prestats=true WHERE metric_name="Processor.%_Processor_Time" AND index="em_metrics" AND instance="_Total" span=1m BY host
| stats avg(_value) as cpu_usage BY host
| eval Critical_Usage = if(cpu_usage > 95, "Yes", "No")
| table host Critical_Usage cpu_usage
| where Critical_Usage="Yes"
Enregistrez-la en tant qu’alerte et personnalisez les actions à déclencher.

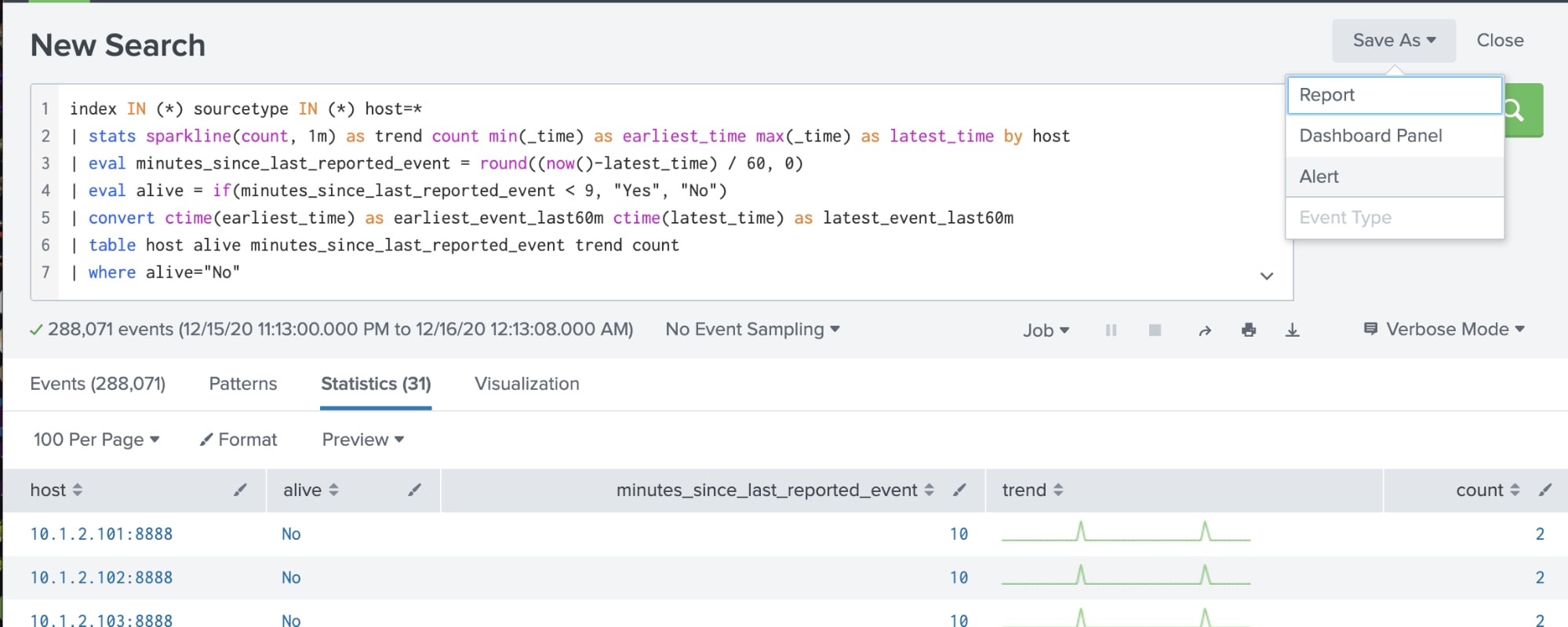
Lorsque vous supervisez la santé globale d’un hôte, vous souhaitez être alerté lorsqu’un processus critique s’arrête soudainement, afin de pouvoir rapidement le remettre en état. Dans cet exemple, nous utilisons Windows et la collecte de métriques pour détecter si un processus était en cours d’exécution au cours des 60 dernières minutes, mais pas au cours des 10 dernières minutes.
| mstats count WHERE metric_name="Process.Elapsed_Time" AND index IN (*) host IN (*) instance IN ("listCriticalProcessesHere") BY host instance span=1m
| stats sparkline(count, 1m) as trend count min(_time) as earliest_time max(_time) as latest_time by host instance
| eval minutes_since_last_reported_event = round((now()-latest_time) / 60, 0)
| eval alive = if(minutes_since_last_reported_event < 11, "Yes", "No")
| convert ctime(earliest_time) as earliest_event_last60m ctime(latest_time) as latest_event_last60m
| table host instance alive minutes_since_last_reported_event trend count
| where alive="No"

La forme la plus simple de supervision de l’infrastructure consiste à vérifier qu’un hôte fonctionne correctement et à générer une alerte lorsque ce n’est pas le cas. La supervision de la disponibilité peut se faire de plusieurs manières, mais l’approche de Splunk consiste à réaliser une « prise de pouls » sur une métrique critique et à émettre une alerte si elle cesse de se manifester. Si c’est le cas, soit l’agent n’envoie plus de données, soit l’hôte est hors ligne ; dans un cas comme dans l’autre, votre attention est requise.
| tstats count where index IN (*) sourcetype IN (*) host=* by host _time span=1m
| stats sparkline(sum(count), 1m) as trend sum(count) as count min(_time) as earliest_time max(_time) as latest_time by host
| eval minutes_since_last_reported_event = round((now()-latest_time) / 60, 0)
| eval alive = if(minutes_since_last_reported_event < 9, "Yes", "No")
| convert ctime(earliest_time) as earliest_event_last60m ctime(latest_time) as latest_event_last60m
| table host alive minutes_since_last_reported_event trend count
SolarWinds est souvent utilisé comme récepteur de syslog, analyseur de log et solution de supervision du trafic réseau. Splunk peut assumer ces capacités et c’est l’un des moyens les plus rapides de rétablir le flux de données en provenance des différents composants de votre réseau. L’objectif consiste à regagner une visibilité de base sur ces dispositifs en redirigeant le trafic syslog et les pièges SNMP vers Splunk à des fins d’analyse.
Dans cette section, nous allons voir les étapes nécessaires pour :
La première étape pour retrouver cette visibilité consiste à importer les données requises dans Splunk pour visualiser et superviser nos dispositifs réseau. Dans cette section, nous allons voir les changements de configuration nécessaires pour collecter le syslog réseau et les pièges SNMP dans Splunk.
Comme il s’agit d’une bonne pratique Splunk, nous recommandons de déployer Splunk Connect pour Syslog (SC4S) pour collecter les données syslog ; toutefois, si vous êtes à l’aise avec d’autres méthodes de collecte des données syslog, elles fonctionneront également. La configuration de SC4S est couverte en détail dans cette documentation, et nous vous proposons des liens vers cette série d’articles en deux parties (Partie 1, Partie 2) et cette conférence .conf exceptionnelle qui aborde les bases pour bien démarrer avec SC4S.
Si possible, nous demandons de donner à SC4S la même adresse IP que celle que SolarWinds utilisait pour collecter le trafic syslog. Cela évitera d’avoir à reconfigurer tous les dispositifs réseau et règles de pare-feu, ce qui serait indispensable pour autoriser l’acheminement du trafic syslog à un nouveau récepteur syslog.
Pour collecter les pièges SNMP dans Splunk, vous devrez exécuter un serveur snmptrapd sur une machine Linux ou Windows et les écrire dans un fichier. Une fois qu’ils sont écrits sur le disque, vous pouvez configurer le forwarder universel pour lire ces fichiers et les transmettre à Splunk ; cette configuration est décrite ici dans notre documentation. Cette approche a également été décrite en détail dans la première moitié de cet guide étape par étape. (Remarque : la deuxième partie de cet article couvre l’importation des pièges dans Splunk IT Service Intelligence, qui n’est pas nécessaire pour la visibilité du réseau dont nous parlons ici.)
L’obtention d’un inventaire de tous les dispositifs de votre réseau est essentielle pour sa visibilité et sa gestion. Elle constitue la base de la supervision de la disponibilité et de la production d’alertes en cas d’interruption d’émission de la part d’un appareil.
Remarque : pour restreindre encore les résultats, limitez la recherche afin d’inclure uniquement les indexes et les types de sources associés à vos dispositifs réseau
index IN (*) sourcetype IN (*) sc4s_vendor_product=* | stats count by host, sourcetype, sc4s_vendor_product
Si vous soupçonnez un dispositif en particulier d’avoir un problème, vous en trouverez souvent des preuves dans les messages syslog. Utilisez Splunk pour isoler les messages syslog provenant de ce dispositif et recherchez ceux qui ont une gravité élevée.
Remarque : pour restreindre encore les résultats, limitez la recherche afin d’inclure uniquement les indexes et les types de sources associés à vos dispositifs réseau. Ajoutez l’hôte ou l’IP du dispositif que vous voulez explorer.
index IN (*) sourcetype IN (*) host= (severity_name IN (emergency, alert, critical, error, warning) OR sc4s_syslog_severity IN (emergency, alert, critical, error, warning)) |

La perte d’un hôte réseau dans votre environnement est naturellement un problème qui doit être détecté et dont vous devez être prévenu. En utilisant la présence de données syslog comme « pouls » de la présence d’un hôte, nous pouvons configurer Splunk pour générer une alerte lorsqu’un hôte qui envoyait des données ne se manifeste plus.
Remarque : la recherche suivante renvoie les hôtes qui ont envoyé des données au cours des 60 dernières minutes, mais aucune donnée sur les 10 dernières minutes. Ces valeurs peuvent être ajustées selon vos besoins. Pour restreindre encore les résultats, limitez la recherche afin d’inclure uniquement les indexes et les types de sources associés à vos dispositifs réseau.
index IN (*) sourcetype IN (*) sc4s_vendor_product=* | stats sparkline(count, 1m) as trend count min(_time) as earliest_time max(_time) as latest_time by host | eval minutes_since_last_reported_event = round((now()-latest_time) / 60, 0) | eval alive = if(minutes_since_last_reported_event < 11, "Yes", "No") | convert ctime(earliest_time) as earliest_event_last60m ctime(latest_time) as latest_event_last60m | table host alive minutes_since_last_reported_event trend count | where alive="No" |
Si nous tenions à focaliser l’essentiel de nos directives sur la supervision de l’infrastructure d’hôtes et de réseau, nous savons que la supervision des applications qui s’exécutent sur votre infrastructure est toute aussi importante. L’essentiel de la supervision d’applications disponible dans Surveillance peut être réalisée avec les techniques abordées ci-dessus en commençant par recueillir les données, puis en produisant des visualisations et des alertes. L’app store Splunkbase de Splunk contient des centaines d’applications prédéfinies que vous pouvez installer pour recueillir et visualiser les données des applications et infrastructures les plus courantes, puis générer des alertes. S’il est impossible de dresser la liste complète de toutes celles que nous vous recommandons, voici les applications Splunk de supervision des applications et des infrastructures les plus populaires :
Pendant une crise, chaque seconde compte, et notre objectif était de vous donner quelques conseils à mettre en œuvre immédiatement pour récupérer votre visibilité perdue sur l’infrastructure IT. Dans des circonstances normales, nous proposerions une approche plus mature de la supervision des infrastructures ; toutefois, au vu de la situation, nous avons opté pour une approche rapide et simple à implémenter, et s’appuyant pleinement sur votre déploiement Splunk existant.
Chez Splunk, notre priorité n° 1 est votre réussite, et nous sommes là pour vous aider. Si après avoir lu ce blog vous pensez avoir besoin d’une aide supplémentaire, nous avons ce qu’il vous faut. Nous vous recommandons de contacter votre Responsable de la réussite client, votre Expert de la vente ou votre Responsable de compte client si vous avez besoin d’une assistance immédiate concernant l’une des recommandations ci-dessus.
----------------------------------------------------
Thanks!
Splunk

La plateforme Splunk élimine les obstacles qui séparent les données de l'action, pour donner aux équipes d'observabilité, d'IT et de sécurité les moyens de préserver la sécurité, la résilience et le pouvoir d'innovation de leur organisation.
Fondée en 2003, Splunk est une entreprise internationale. Ses plus de 7 500 employés, les Splunkers, ont déjà obtenu plus de 1 020 brevets à ce jour, et ses solutions sont disponibles dans 21 régions du monde. Ouverte et extensible, la plateforme de données Splunk prend en charge les données de tous les environnements pour donner à toutes les équipes d'une entreprise une visibilité complète et contextualisée sur l'ensemble des interactions et des processus métier. Splunk, une base solide pour vos données.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2025 Splunk LLC Tous droits réservés.
© 2005 - 2025 Splunk LLC Tous droits réservés.

