Observability
Splunk On-Call
So macht On-Call Spaß. Kürzere Behebungszeiten, weniger Burnout und keine kostenintensiven Serviceausfälle.
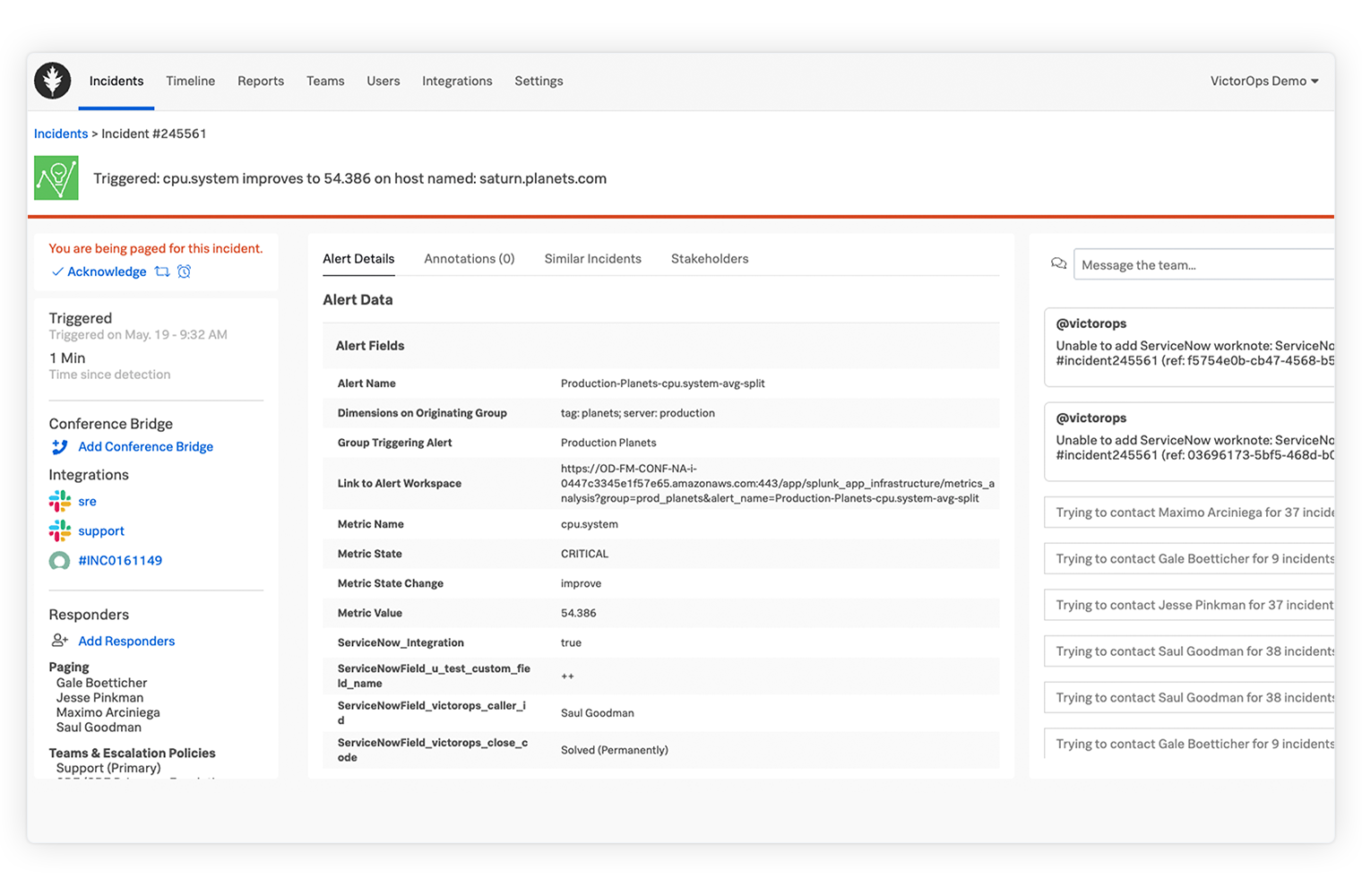
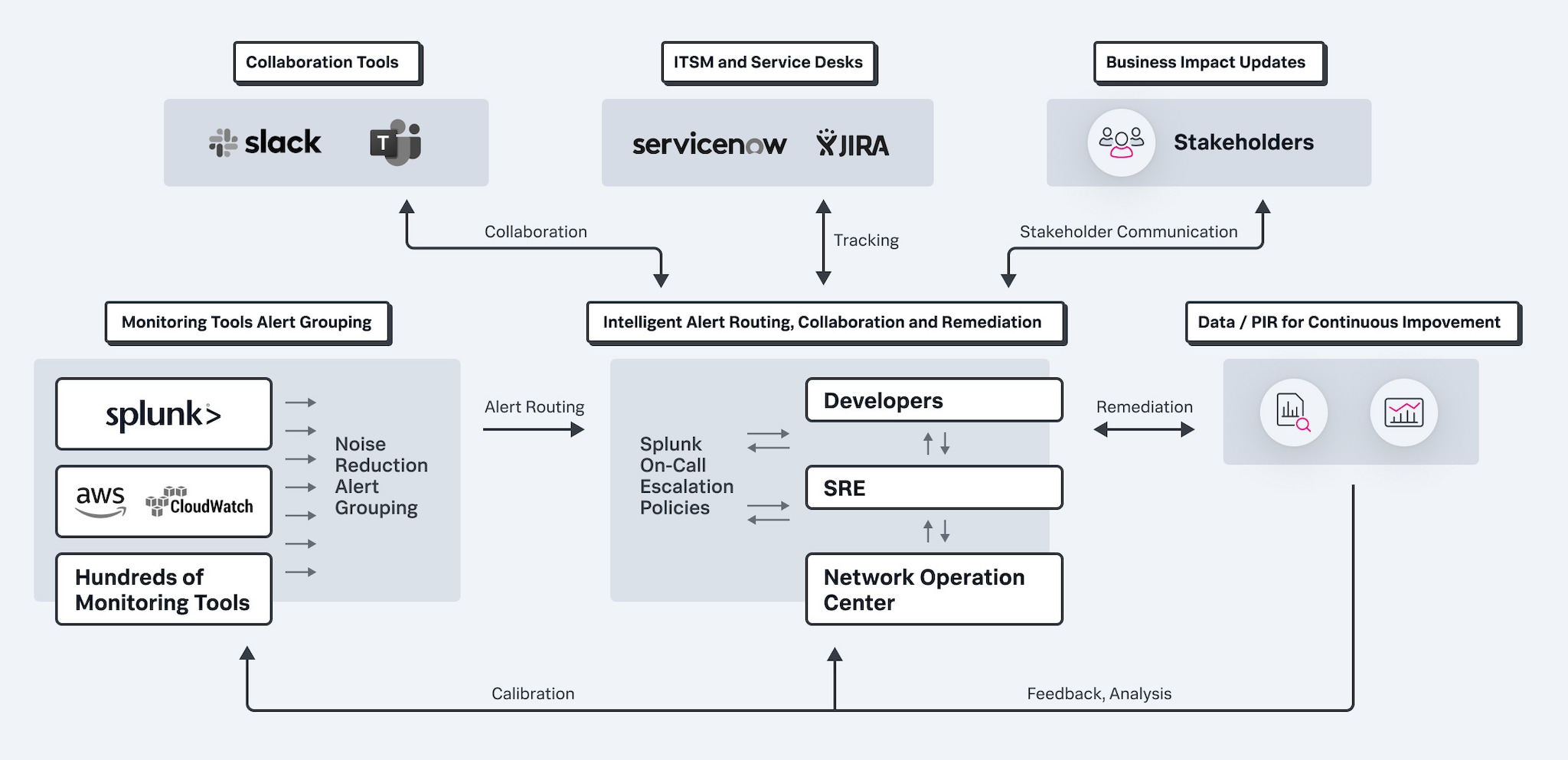
Anwendungsbereitstellung optimieren
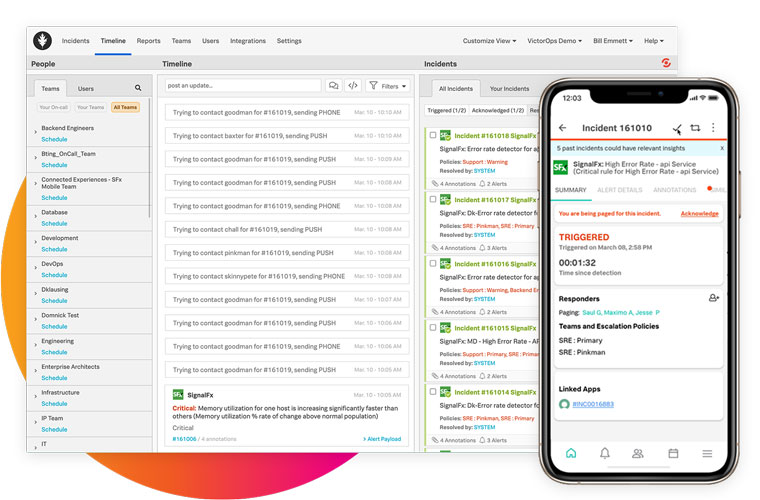
Mit Metadaten angereicherte Warnmeldungen empfangen Sie auf jedem Gerät. Dann können Sie direkt in der nativen iOS- oder Android-App reagieren, Lösungen finden, Benachrichtigungen umleiten und sogar per Schlummerfunktion zurückstellen.
Rasch reagieren
Zeitkritische Aktionen wie Eskalationen, Krisensitzungen und Überprüfungen nach einem Incident lassen sich einfach automatisieren, damit sich Ihre Teams ganz darauf konzentrieren können, Vorfälle zu beheben.
Innerhalb von 12 Monaten sank unsere Mean Time to Acknowledge von 4 Stunden auf 20 Minuten. Jetzt sind wir 3 Jahre dabei und liegen unter 2 Minuten.
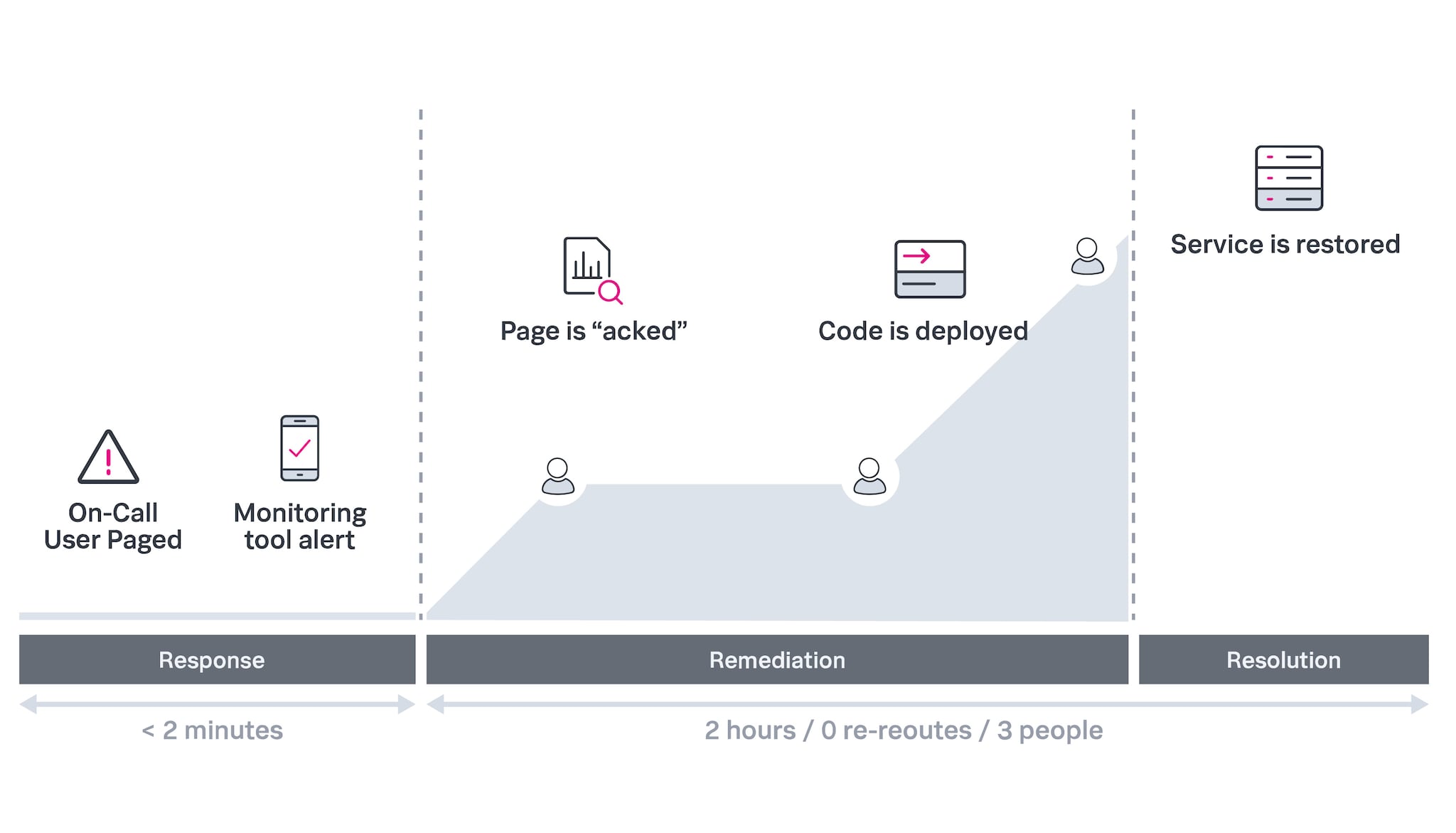
Mit robustem Reporting alles im Griff
So dämmen Sie die Warnmeldungsflut ein und verbessern die Incident-Analyse. Leicht abrufbare Berichte zu Incident-Häufigkeit, MTTA/MTTR und Incident-Nachbereitungen ermöglichen eine schnelle Lösungsfindung, senken die Burnout-Gefahr und geben Anstöße zu Innovationen.
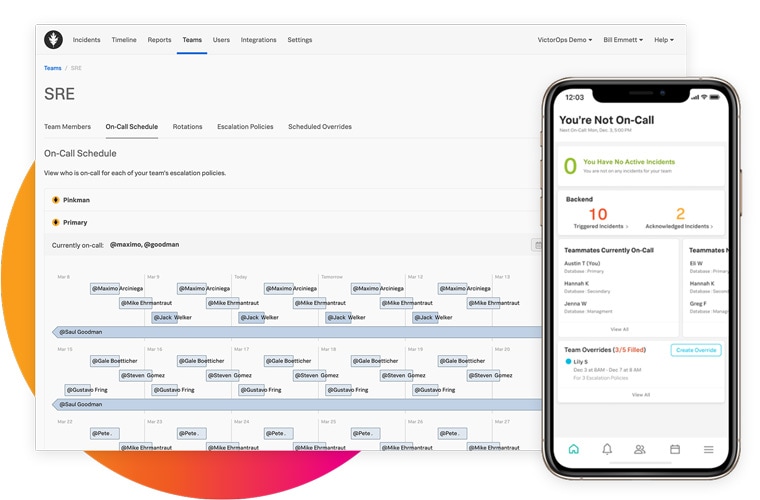
Bereitschaftsplanung leicht gemacht
Mit Splunk On-Call wird alles einfacher, vom Schichtwechsel bis zu Überschreibungen, weil Sie alle wesentlichen Schritte automatisieren können, einschließlich Bereitschaftsplänen und Eskalationsrichtlinien.
Splunk On-Call hat den nachhaltigsten Bereitschaftsplan, den ich je erlebt habe.
Features
Kernprozesse automatisieren, Probleme schneller lösen
Bei einem Incident identifizieren Sie rasch die Person, deren Erfahrungs- und Kenntnisprofil jeweils am besten für die Bearbeitung geeignet ist. Außerdem können Sie Ihre Bereitschaftspläne und Eskalationen optimieren.
Apps für iOS und Android
Ihr Team bekommt sämtliche Incident Response-Funktionen vollumfänglich auf das Mobilgerät. Dann können alle Mitglieder dort arbeiten und einsatzbereit sein, wo sie wollen.
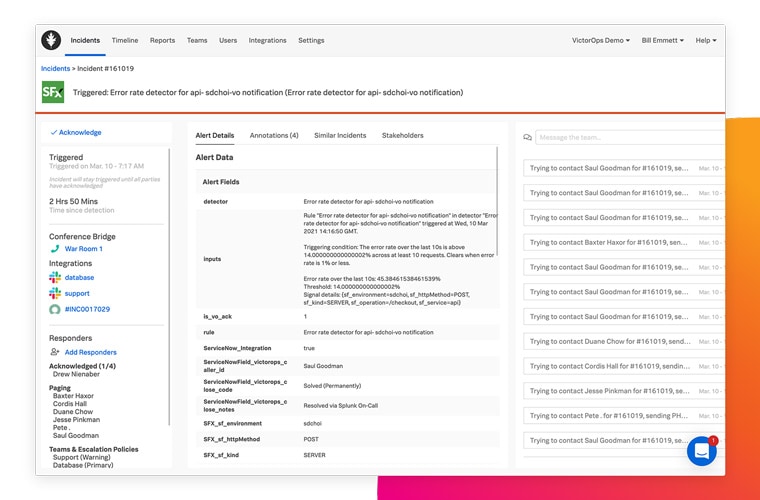
Incident-Kontext und Audit-Trail
Mithilfe von historischen Erkenntnissen und Audit-Trails erkennen Sie Incidents, die einander ähnlich sind, und verbessern die aktive Vorfallbehebung.
Regelmodul
Sie verstehen Incidents im Kontext und greifen einfach auf Ressourcen wie Runbooks, Artikel und Dashboards zu, was den Erstreaktionskräften die Sichtung und die schnelle Vorfallbehebung erleichtert.
ML-gestützte Reaktionsempfehlungen
So finden Sie bei Incidents rasch die Responder mit der entsprechenden Erfahrung und können ihnen Informationen aus vergleichbaren Vorfällen mitgeben, sodass Probleme effektiver behoben werden.

ERFOLGSGESCHICHTE
PSCU sorgt mit Splunk für Zuverlässigkeit und Sicherheit
Egal, was Sie tun, es wird immer wieder zu Ausfällen kommen. Je eher Sie es wissen, desto eher können Sie es reparieren und desto besser schützen Sie Ihre User Experience.




ÄHNLICHE PRODUKTE
Eine zentrale Plattform für Ihre gesamten Observability-Anforderungen
Splunk Synthetic Monitoring
Bei Web- und Mobilanwendungen Probleme schneller erkennen und beseitigen, ehe Kunden sie zu spüren bekommen – dank voller Transparenz der End User Experience.
Logs in Observability
Anwendungs- und Infrastruktur-Logs in Minutenschnelle untersuchen, damit Sie herausfinden, warum sich Ihre Software so verhält, wie sie sich verhält.
Splunk Infrastructure Monitoring
Die Performance der Hybrid-Cloud optimieren – durch sofortige Sichtbarkeit und Benachrichtigungen in Echtzeit.
Splunk Synthetic Monitoring
Performance-Probleme über User Flows, Transaktionen und APIs hinweg proaktiv finden und beheben.
Splunk Application Performance Monitoring
Erkenntnisse über Ihre Anwendungen gewinnen, egal ob Cloud-nativ, Microservice-basiert oder monolithisch – mit dezentralem NoSample Tracing und Transparenz auf Code-Ebene.

