Was ist ITOps? Definition von IT Operations

IT Operations (oder ITOps) bezeichnet die Prozesse und Dienste, die von der IT-Abteilung einer Organisation für interne oder externe Kunden verwaltet werden.
Jede Organisation, die Computer einsetzt, hat eine Methode, um die IT-Anforderungen ihrer Mitarbeiter oder Kunden zu erfüllen – unabhängig davon, ob sie es ITOps nennt oder nicht. In einer typischen Unternehmensumgebung gilt ITOps jedoch als eine eigenständige Gruppe innerhalb der IT-Abteilung.
Die IT-Operations-Gruppe spielt eine entscheidende Rolle beim Erreichen von Geschäftszielen. Sie trägt unter anderem dazu dabei, ein stabiles und zuverlässiges IT-Ökosystem aufrechtzuerhalten. Und sie stellt sicher, dass die IT die Mitarbeiter und das Management der Organisation in die Lage versetzt, die gewünschten Geschäftsergebnisse zu erzielen.
Da Unternehmen ihre Daten zunehmend vom Rechenzentrum in die Cloud verlagern, ändert sich auch die Wahrnehmung dieses Berufs. In diesem Artikel zeigen wir, was ITOps-Teams tun, wie sie sich von anderen Teams wie DevOps unterscheiden und wie sich der IT-Betrieb weiterentwickelt.
Splunk ITSI ist ein Branchenführer im Bereich AIOps
Splunk IT Service Intelligence (ITSI) ist eine AIOps-, Analyse- und IT-Management-Lösung, die Teams dabei unterstützt, Vorfälle vorherzusagen, bevor sie sich auf Kunden auswirken.

Unter Einsatz von KI und maschinellem Lernen korreliert ITSI Daten aus Überwachungsquellen und liefert eine einheitliche Echtzeitansicht relevanter IT- und Geschäftsdienste, reduziert die Alarmmenge und verhindert proaktiv Ausfälle.
Rollen und Verantwortlichkeiten im IT-Betrieb
IT-Operations-Zugehörige bieten technologische Beratung auf hohem Niveau und führen täglich routinemäßige Aufgaben zur Aufrechterhaltung der IT-Infrastruktur der Firma durch. Das ist wichtig, weil ITOps die Gesamtverantwortung für die von der IT-Organisation bereitgestellten Dienste, Systeme und Infrastrukturen trägt, die die Geschäftsprozesse einer Organisation unterstützen. Die Aufgabe besteht darin, die betriebliche Stabilität der Organisation aufrechtzuerhalten und gleichzeitig neue Initiativen zu unterstützen, um das Geschäft auf die nächste Stufe zu heben.
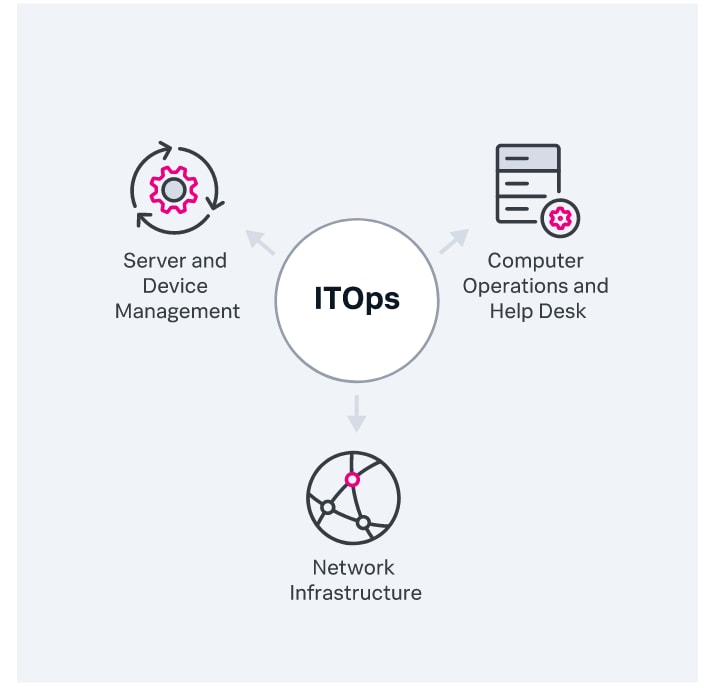
ITOps lässt sich auf die Bedürfnisse und Ressourcen jeder Organisation zuschneiden, was eine einheitliche To-do-Liste von Aufgaben unpraktisch macht. Funktionell lässt sich ITOps jedoch in drei zentrale Verantwortungsbereiche unterteilen. Welche und wie viele dieser Aufgaben ein einzelnes Team zu verantworten hat, variiert von Organisation zu Organisation. Zu diesen Aufgaben können gehören:
Netzwerkinfrastruktur
- Konfigurieren und Verwalten aller Netzwerkfunktionen für die interne und externe IT-Kommunikation
- Konfigurieren und Verwalten von Telekommunikationsleitungen
- Verwalten von Firewall-Ports, um dem Netzwerk die Kommunikation mit externen Servern zu ermöglichen
- Bereitstellen von sicherem Remote-Zugriff auf das Unternehmensnetzwerk für autorisierte Benutzer
- Monitoring von Netzwerkzustand und -Performance, Erkennen von Anomalien und Verhindern bzw. schnelles Beheben von Problemen: Dazu muss eventuell ein Network Operations Center (NOC) erstellt und verwaltet werden, also ein zentraler, physischer Standort, von dem aus ITOps-Teams ein Netzwerk kontinuierlich überwachen können.
Server- und Gerätemanagement:
- Konfigurieren, Warten und Verwalten von Servern für Infrastruktur und Anwendungen
- Verwalten von Netzwerk- und individuellem Speicher, um sicherzustellen, dass die Anforderungen der Anwendungen erfüllt werden
- Einrichten und Autorisieren von E-Mail- und Dateiservern
- Bereitstellen und Verwalten vom Unternehmen genehmigter PCs
- Bereitstellen und Verwalten von Mobiltelefonen und anderen Mobilgeräten
- Lizenzieren und Verwalten der Software für Desktop-, Laptop- und Mobilgeräte
Computer-Operations und Help Desk:
- Verwalten von Rechenzentrumsstandorten und -anlagen
- Betrieb des Help- und/oder Servicedesk
- Erstellen, Autorisieren und Verwalten von Benutzerprofilen auf Systemen des Unternehmens
- Bereitstellen von Audit-Informationen zur Netzwerkkonfiguration für Aufsichtsbehörden, Geschäftspartner und andere externe Einrichtungen
- Bereitstellen von Netzwerk-Fixes und -Upgrades
- Sicherstellen hoher Netzwerkverfügbarkeit und Pflege von Disaster-Recovery-Plänen
- Benachrichtigen von Benutzern bei gravierenden Incidents mit Auswirkungen auf Netzwerkservices
- Einrichten regelmäßiger Sicherungen, um Daten bei Bedarf leichter wiederherstellen zu können
Geschäftsbetrieb
- Verwaltung und Zusammenarbeit mit Lieferanten und externen Auftragnehmern
- Beschaffung und Bezahlung von Hardware, Software und Anwendungen
- Projektmanagement
Wie entwickelt sich der IT-Betrieb?
Wie alles andere in der Technologiewelt verhält sich ITOps nicht monolithisch oder statisch im Wortsinn. Mit der Weiterentwicklung der Technologie entstehen neue Betriebsansätze, die traditionelle IT Operations mit anderen Teams, Tools und Systemen kombinieren.
IT Operations
Lasst uns zunächst klären, wo ITOps hineinpasst.
Die breite und manchmal vage Beschreibung von ITOps kann den Eindruck erwecken, dass alles IT-Bezogene abgedeckt wird. Es stimmt, dass ITOps-Aktivitäten von Organisation zu Organisation erheblich variieren können. In allen Fällen sind sie jedoch für Bereitstellung und Wartung der für den Geschäftsbetrieb erforderlichen Technologie verantwortlich.
In der Praxis kann dies Aufgaben wie die Wartung von Netzwerken, die Verwaltung von Rechenzentren, die Gewährleistung von Sicherheit und regulatorischer Compliance, die Verwaltung des Helpdesks, die Lizenzierung und Verwaltung von Software sowie andere Aufgaben umfassen, die Mitarbeiter und den täglichen Geschäftsbetrieb unterstützen.
Bemerkenswerterweise umfasst der IT-Betrieb keine Programm- und Anwendungsentwicklung und damit verbundene Aufgaben.
DevOps
Bei DevOps handelt es sich um einen Ansatz zur Bereitstellung von IT-Diensten, der Menschen, Praktiken und Tools kombiniert, um Silos zwischen Entwicklungs- und Betriebsteams abzubauen. DevOps bezeichnet aber auch eine eigenständige IT-Rolle, die für die Entwicklung, Implementierung und Wartung von kundenspezifischen Anwendungen für den internen oder externen Gebrauch verantwortlich ist.
Wie der Name schon sagt, bringt DevOps die Berufsbilder von Entwicklung und IT-Betrieb zusammen. Im Kern basiert DevOps auf der Idee, dass Teams ihren Produktionssupport selbst in die Hand nehmen sollten. DevOps-Teams, die eine Reihe von DevOps-Praktiken anwenden, beschleunigen die Entwicklung von Anwendungen und Diensten mit einem reaktionsfähigeren Ansatz für die Verwaltung der IT-Infrastruktur. So gelingt es ihnen, bei IT-Produkten mit der Geschwindigkeit des modernen Marktes mitzuhalten und sie entsprechend zu aktualisieren.
DevOps dreht sich um zwei Schlüsselideen: Innovationen bei Apps und deren Optimierung bei gleichzeitiger Verkürzung des Software-Entwicklungszyklus und Beschleunigung der Markteinführungszeit.

AIOps
Ständige Iterationen und sich weiterentwickelnde Technologie prägen sowohl DevOps als auch ITOps – und vielleicht hat nichts einen so großen Einfluss gehabt wie künstliche Intelligenz. Unter AIOps verstehen wir die Praxis, KI-Analysen und maschinelles Lernen anzuwenden, um IT-Betriebsabläufe zu automatisieren und zu verbessern.
AIOps-Plattformen sind für heutige Netzwerke konzipiert und können große Datensätze über die gesamte Umgebung hinweg erfassen, während sie gleichzeitig die Datenqualität für umfassende Analysen garantieren. Sie können auch Lösungen vorschlagen, Antworten automatisieren und Algorithmen verändern, um den Umgang mit zukünftigen Problemen zu verbessern.
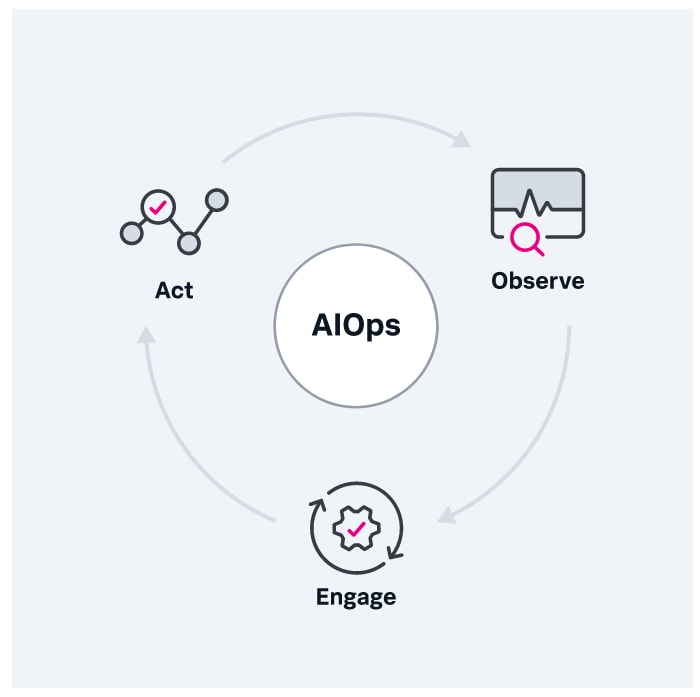
In der Praxis ist AIOps ein Prozess aus den drei Schritten „Beobachten“, „Informieren“ und „Handeln“, die in einem kontinuierlichen Kreislauf ausgeführt werden:
- Beobachten: Zunächst verarbeitet die AIOps-Plattform Echtzeitdaten aus verschiedenen Quellen, einschließlich beispielsweise traditioneller IT-Überwachung und Protokollereignisse. Die KI-Algorithmen nutzen Anomalien in den Daten, um automatisch größere Schwierigkeiten zu erkennen, zu analysieren und zu gruppieren.
- Eingreifen: Die AIOps-Plattform alarmiert die relevanten IT-Teams bei Anomalien. Da sie nach Typ gruppiert sind, gibt es weniger Benachrichtigungen.
- Handeln: AIOps-Plattformen können die Weiterleitung von Arbeitsabläufen mit oder ohne menschliches Eingreifen automatisieren und aus den Antworten des IT-Teams lernen, um mit der Zeit immer präziser zu agieren. Letztendlich können sie lernen, Probleme zu lösen, bevor das Unternehmen sie bemerkt – und bevor sie Endnutzer negativ beeinträchtigen.
(Es gibt auch andere „Ops“-Trends, wie NoOps oder CloudOps, die ihr weiter erforschen könnt.)
Die Zukunft von ITOps
In einer sich rasch entwickelnden Technologielandschaft spielen IT-Betriebsabläufe (ITOps) eine zentrale Rolle bei der Aufrechterhaltung stabiler IT-Ökosysteme, die geschäftlichen Erfolg ermöglichen. Im Zuge des technologischen Fortschritts verschmelzen ITOps und DevOps. Das mündet in AIOps, um durch KI und Automatisierung die Effizienz zu steigern. Diese Entwicklung unterstreicht den dynamischen Charakter von ITOps, der für Unternehmen entscheidend ist, um sich anzupassen und zu florieren.
Ihr habt einen Fehler entdeckt oder eine Anregung? Bitte lasst es uns wissen und schreibt eine E-Mail an ssg-blogs@splunk.com.
Dieser Beitrag spiegelt nicht zwingend die Position, Strategie oder Meinung von Splunk wider.

Ähnliche Artikel
Über Splunk
Weltweit führende Unternehmen verlassen sich auf Splunk, ein Cisco-Unternehmen, um mit unserer Plattform für einheitliche Sicherheit und Observability, die auf branchenführender KI basiert, kontinuierlich ihre digitale Resilienz zu stärken.
Unsere Kunden vertrauen auf die preisgekrönten Security- und Observability-Lösungen von Splunk, um ihre komplexen digitalen Umgebungen ungeachtet ihrer Größenordnung zuverlässig zu sichern und verbessern.

Den Splunk-Blog abonnieren
Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.

