
La résilience numérique porte ses fruits
Votre organisation est-elle résiliente ? Découvrez le degré de maturité de votre résilience numérique dans ce guide gratuit.

Bienvenue dans l’épisode 5 de Data Talks, la série de Splunk dans laquelle des experts de la donnée décryptent pour nous les nouvelles tendances autour de la data. Nous retrouvons aujourd’hui un des spécialistes français de la donnée, Gilles Babinet.
Conseiller à l’Institut Montaigne sur les questions numériques et représentant de la France auprès de la Commission européenne pour les enjeux du numérique, il est également l’auteur d’un livre intitulé Big Data, penser l’homme et le monde autrement. Regardez la vidéo ci-dessous ou lisez l'article, à vous de choisir !
On peut déjà noter que le terme « Big Data » ne dispose pas d’une définition académique bien délimitée, mais on s’accorde généralement sur le fait qu’il suppose une croissance exponentielle des données ainsi que de nouvelles méthodologies et de nouveaux outils d’analyse. Les premiers d’entre eux sont apparus au début des années 2000, notamment Hadoop, qui a révolutionné le secteur en ouvrant la voie au traitement d’informations non structurées.
L’idée du Big Data est donc d’offrir la possibilité d’effectuer des corrélations entre des données structurées et non structurées. Pour expliquer simplement la différence, on peut dire que les premières sont issues de bases de données organisées et cohérentes, au contraire des secondes, qui peuvent prendre la forme de conversations ou de tout autre ensemble n’ayant pas forcément de suite linéaire. Cette culture du traitement des masses de données s’est ensuite profondément transformée à mesure que se sont développés les éléments méthodologiques et technologiques que nous utilisons aujourd’hui.
En parallèle, on a observé un effondrement proportionnel des coûts. Par exemple, ce qui pouvait nécessiter un million d’euros en 1995 n’en valait plus que 10 une quinzaine d’années plus tard. Et on peut imaginer à quel point cela a pu faire évoluer la culture de la donnée dans les organisations.
Peu après l’émergence du Big Data, vers le milieu des années 2000, on a vu apparaître un certain nombre d’innovations en matière d’intelligence artificielle et, plus généralement, au niveau des solutions utilisées pour automatiser le traitement des données massives. Les outils tels que le machine learning et les arbres décisionnels nous ont ainsi permis de révolutionner notre manière d’analyser ces informations et de dégager des modèles.
![]()
Le marketing automation offre des exemples innombrables dans ce domaine. À ce propos, John Wanamaker affirmait : « La moitié de l’argent que je dépense en publicité est gaspillée, mais je ne sais pas quelle moitié ! ». La technologie nous permet donc d’améliorer fortement la personnalisation des flux et le retour sur les investissements publicitaires.
Comme on l’a vu dans le cadre du Covid-19, le Big Data peut être un outil très puissant pour détecter des liens de causalité dans un environnement multifactoriel. On a ainsi pu dégager des modèles de propagation en fonction de différentes données telles que le climat, la distanciation ou la vaccination.
Il faut toutefois faire attention à ce que les corrélations observées soient bien causales. Avec l’émergence du Big data, on a en effet vu apparaître des déductions sans aucun lien logique, d’où l’importance d’une supervision humaine dans le machine learning. Car si l’opérateur n’effectue pas de tri, on peut se retrouver à montrer que les ventes de bicyclettes au Japon influent sur les épidémies de grippe en Europe, ce qui n’a absolument aucun sens.
Les assurances s’appuient depuis longtemps sur des modèles de risques pouvant s’appliquer à la plupart de leurs clients. Par exemple, il est commun d’adapter les polices automobiles en fonction de l’âge et du sexe du conducteur ou du lieu d’habitation.
Le Big Data a permis de personnaliser davantage ces paramètres afin de définir des tarifs individuels en fonction d’une multitude de facteurs. Toutefois, ce fantasme de l’assurance paramétrique n’est pas sans poser problème. Aux États-Unis, par exemple, les compagnies peuvent exiger que leurs assurés installent un boîtier de contrôle dans leur voiture afin d’adapter leurs primes et taux d’indemnisation. Et on peut imaginer comment cela peut se traduire pour ce qui touche à la santé. Dans ce domaine, les masses de données peuvent donc déséquilibrer encore davantage les rapports entre assurés et assureurs.
![]()
Le transport est un excellent exemple, car c’est un secteur qui produit énormément de data avec des facteurs multicorrélés et interdépendants, comme la météo, les événements sportifs ou les vacances. Le report modal d’un système de transport à un autre génère également des incidences en cascade. Par exemple, lorsque vous baissez les tarifs ferroviaires, un certain nombre d’usagers peuvent décider de limiter leurs déplacements en voiture. C’est donc un environnement complexe, mais les masses de données permettent tout de même de définir des patterns relativement clairs.
Dans ce contexte, on voit apparaître de plus en plus de plateformes MaaS (Mobility as a Service), qui permettent de connecter les différents systèmes de transport. Les pays scandinaves s’appuient aussi sur ces environnements pour effectuer des arbitrages en fonction des conditions du trafic.
![]()
Pour répondre à cette question, on peut prendre l’exemple de la supply chain, qui représente environ 80 % des émissions de notre économie. Dans ce secteur clé, de nombreuses décisions sont prises sans tenir compte des contraintes environnementales. Il suffirait donc d’introduire un prix du carbone dans les chaînes d’approvisionnement pour influer sur ces arbitrages. Par exemple, une mesure comme celle-ci pourrait favoriser les transports par bateau ou train plutôt que par avion.
Pour répondre à cette exigence, certains fournisseurs de solutions d’intégration de supply chain, comme SAP, commencent à introduire un carbon calculator tenant compte des nombreuses variables en jeu, comme le prix, la sécurité, l’unicité de l’offre, le carbone et la rapidité. Des solutions comme celles-ci contribuent à la mise en place des processus décisionnels reposant tout autant sur du Big Data que du machine learning.

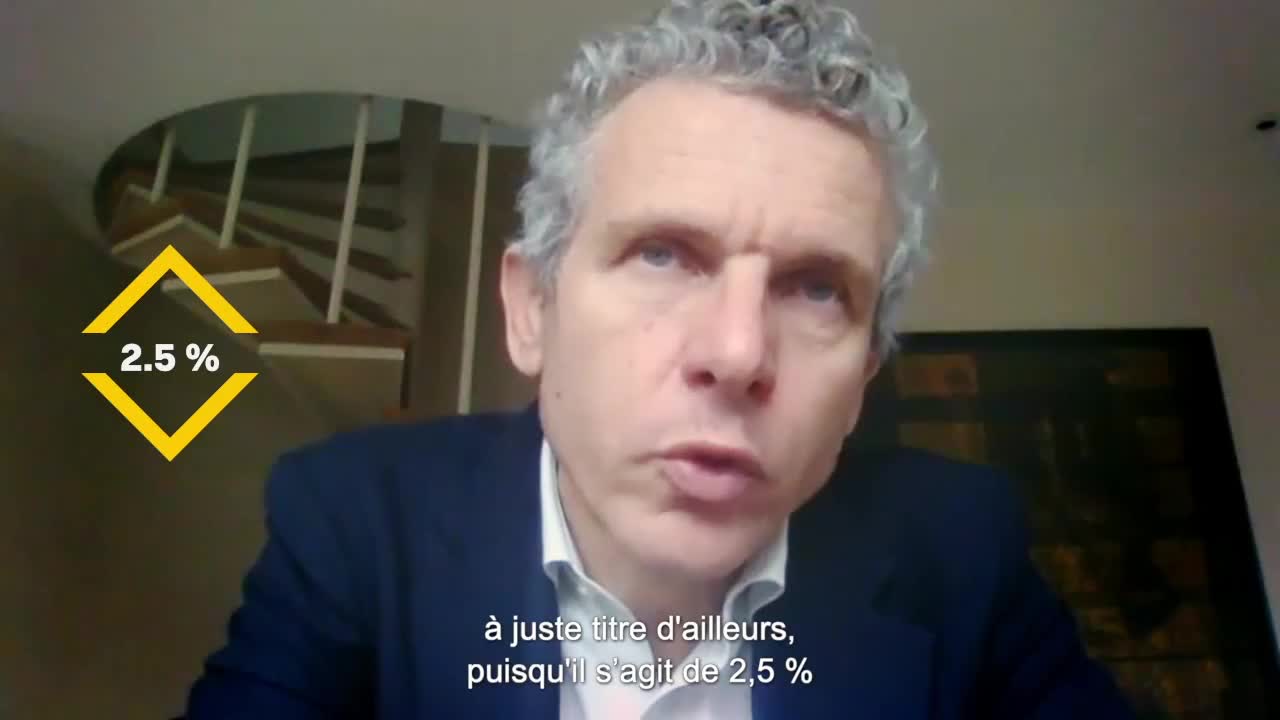
Les émissions du numérique sont aujourd’hui souvent pointées du doigt, à juste titre d’ailleurs, puisque le secteur représente environ 2,5 % de l’utilisation primaire de l’énergie, soit à peu près le niveau de l’avion, même si les conséquences en matière d’émissions de CO2 sont tout de même moins importantes. Mais il faut également prendre en compte l’impact positif du numérique, comme l’amélioration du taux de remplissage des transports, ou l’optimisation de l’utilisation des infrastructures.
Toutefois, selon moi, nous constaterons le véritable avantage du numérique lorsque nous instaurerons un prix carbone. Si nous chiffrons les conséquences environnementales des produits que nous achetons, les entreprises mettront sans aucun doute en œuvre des stratégies pour limiter leurs frais. Par exemple, si le coût du carbone est inclus dans les achats effectués par un constructeur automobile, qui recourt à de nombreux tiers, il aura nécessairement tendance à réduire l’empreinte carbone de ses commandes.
Il faut donc créer une toute nouvelle économie et, dans ce domaine, la data est déterminante. Elle nous permettra notamment d’alimenter les systèmes d’informations qui nous aideront à opérer ces arbitrages.
L’éthique du Big Data est une question qui devient centrale avec le très récent Data Governance Act (DGA) de la Commission européenne. Ce texte s’interroge notamment sur les règles que nous pouvons mettre en place pour sortir d’un modèle qui s’est en quelque sorte construit par hasard, sous l’influence californienne et la croyance que le marché allait s’autoréguler.
On constate au contraire qu’il a généré un grand nombre d’externalités négatives en matière d’attention, d’environnement ou d’utilisation abusives des données. Ces travers sont toutefois en train d’être corrigés. Le DSA et le DMA ont constitué un premier pas, et on voit que l’éthique prend une place centrale dans le DGA.
 Le dernier DESI (Digital Economic and Social Index), un indice généralement publié chaque année, montre que la France est particulièrement bien positionnée en matière de Big Data, puisqu’elle atteint la deuxième marche du podium dans ce domaine, mais très mal en ce qui concerne le machine learning. Je n’ai pas mené de recherches sur le sujet, mais d’après moi, cela pourrait venir de nos formations fortement orientées vers les mathématiques, qui génèrent plus d’engouement pour le Big Data que pour l’apprentissage machine.
Le dernier DESI (Digital Economic and Social Index), un indice généralement publié chaque année, montre que la France est particulièrement bien positionnée en matière de Big Data, puisqu’elle atteint la deuxième marche du podium dans ce domaine, mais très mal en ce qui concerne le machine learning. Je n’ai pas mené de recherches sur le sujet, mais d’après moi, cela pourrait venir de nos formations fortement orientées vers les mathématiques, qui génèrent plus d’engouement pour le Big Data que pour l’apprentissage machine.
Il existe tout d’abord un certain nombre de MOOC ouverts qui traitent du Big Data. On peut notamment citer une formation de l’université de Stanford dans laquelle intervient Doug Cutting, le « pape du Big Data », ou des vidéos sur YouTube qui expliquent comment utiliser des outils comme Spark, par exemple. On trouve également de nombreux ouvrages.
Du côté de la formation académique, des écoles comme l’ENSAE (École nationale de la statistique et de l’administration économique) et HEC proposent aussi des curriculums qui ont su se mettre à jour sur les thèmes du Big Data et du machine learning.
![]()
Nous allons inévitablement assister à une très forte intégration dans les outils de machine learning. Cette tendance est très claire, mais on voit aussi apparaître de nouvelles écoles, notamment autour du Small Data, qui est très lié à l’apprentissage machine. Il s’agit donc de se défaire des data sets et des prétraitements extrêmement volumineux comme ceux de GPT-4 de l’OpenAI Initiative. On observe également de plus en plus d’approches no code, qui s’affranchissent totalement des langages de programmation classiques et qui peuvent se révéler très intéressantes, même si elles présentent bien évidemment des limites.
Enfin, si le DGA se montre pertinent, il pourrait être source d’une grande création de valeur au niveau européen. Le chemin est long, mais élargir l’accès à la data pourrait nous ouvrir de nombreuses possibilités. Aujourd’hui, il est en effet très difficile de travailler sur certains sujets par manque de données, alors que ces informations se trouvent nécessairement quelque part. Elles ne sont tout simplement pas diffusées. Dans un domaine comme l’isolation thermique des bâtiments, par exemple, un outil comme Copernicus pourra nous renseigner sur des captations satellites en masse, mais il reste très difficile d’obtenir des données concernant les équipements par secteur. Les personnes qui en sont propriétaires refusent souvent de les partager, ce qui nous empêche de dégager des corrélations qui pourraient se révéler particulièrement pertinentes. C’est justement là l’objectif du DGA : libérer la data en assurant aux acteurs qu’elle ne sera pas utilisée contre leurs intérêts. Et si cette démarche est bien menée, le potentiel en matière de création de valeur et d’externalités sociales peut être considérable.
***
Nous allons suivre cette question de près…
En attendant notre prochain épisode de Data Talks, n’hésitez pas à retrouver les premiers épisodes de la série Data Talks pour tout savoir sur ces tendances autour de la data :

Les plus grandes organisations mondiales font confiance à Splunk, une filiale de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.