Qu’est-ce que la modélisation prédictive ? Une introduction

La modélisation prédictive consiste à utiliser des résultats connus pour créer un modèle statistique exploitable à des fins d’analyse prédictive ou pour prévoir les comportements futurs. Cet outil entre dans le cadre de l’analyse prédictive, un domaine de l’exploration de données qui tente de répondre à la question : « Qu’est-ce qu’il est susceptible de se passer ensuite ? »
La numérisation a créé d’énormes volumes de données en temps réel dans tous les secteurs ou presque. Les données historiques peuvent être analysées afin de prévoir différents types d’événements futurs : risques financiers, défaillances mécaniques, comportement des clients et autres résultats. Cependant, les données produites par les produits numériques sont souvent « non structurées » (autrement dit, non organisées de manière prédéfinie), ce qui les rend trop complexes pour une analyse humaine. Les entreprises utilisent donc des outils de modélisation prédictive qui s’appuient sur des algorithmes de machine learning pour identifier et analyser, dans les données, des modèles qui peuvent suggérer quels événements sont susceptibles de se produire à l’avenir.
Cette fonction de « boule de cristal » s’applique dans toute l’entreprise. La modélisation prédictive sert à rendre les opérations plus efficaces, commercialiser les produits plus rapidement et améliorer les relations avec les clients, entre autres utilités. C’est un outil particulièrement puissant dans l’ITOps et le développement de logiciels, où il peut aider à anticiper les coupures du système, les défaillances d’applications et d’autres types de problèmes.
Splunk ITSI est un leader dans le domaine de l’AIOps
Splunk IT Service Intelligence (ITSI) est une solution d’AIOps, d’analytique et de gestion IT qui aide les équipes à anticiper les incidents avant qu’ils n’affectent les clients.

ITSI utilise l’IA et le machine learning pour corréler les données collectées auprès de nombreuses sources de supervision et offrir une vue unifiée des services IT et métiers pertinents. La solution a un double avantage : elle réduit les déluges d’alertes et permet la prévention des interruptions de service.
Nous allons voir comment fonctionnent les modèles prédictifs, les différentes techniques de modélisation prédictive et les avantages de l’analyse prédictive. Et nous vous donnerons des conseils pour bien choisir un modèle prédictif pour votre organisation.
Bases de la modélisation prédictive
Qu’est-ce que l’analyse prédictive ? L’analyse prédictive consiste à appliquer des modèles mathématiques à de grandes quantités de données dans le but d’identifier les modèles de comportements passés et de prédire les résultats futurs. La pratique combine la collecte de données, l’analyse de données, le machine learning et des algorithmes statistiques pour délivrer l’aspect « prédictif ».
L’analyse prédictive n’est qu’une pratique parmi un large éventail d’approches analytiques, dont voici les grandes catégories :
- Descriptive : type d’analyse le plus élémentaire, l’analyse descriptive identifie un problème ou répond à la question « Que s’est-il passé ? ». Elle est toutefois incapable de dire pourquoi quelque chose s’est passé, et c’est pourquoi on l’utilise généralement en tandem avec un ou plusieurs des autres types.
- Diagnostique : l’analyse diagnostique reprend là où l’analyse descriptive s’arrête et établit des corrélations qui expliquent pourquoi un événement s’est produit.
- Prédictive : l’analyse prédictive puise dans les données historiques pour identifier des modèles qui pointent vers des événements futurs probables.
- Prescriptive : c’est le type le plus sophistiqué. L’analyse prescriptive suggère la marche à suivre pour résoudre ou prévenir un problème.
Les outils d’analyse descriptive et diagnostique ont une valeur inestimable quand il s’agit d’aider les data scientists à prendre des décisions factuelles sur les événements actuels, mais ils ne suffisent pas à eux seuls. Les entreprises doivent être en mesure d’anticiper les tendances, les problèmes et d’autres événements pour rester compétitives. L’analyse prédictive s’appuie sur l’analyse descriptive et diagnostique en identifiant des modèles dans les sorties de données et en prévoyant les résultats possibles ainsi que leur probabilité. Les entreprises peuvent ainsi planifier avec plus de précision, éviter ou atténuer les risques, évaluer rapidement les options et prendre globalement des décisions métiers plus sûres.
Dans le secteur du retail, l’analyse prédictive peut prévoir la valeur des clients à long terme. Elle va aussi aider les professionnels de la santé à déterminer le traitement le plus efficace et les enseignants à repérer les élèves qui ont besoin d’un soutien spécifique, pour ne citer que quelques scénarios d’utilisation.
L’analyse prédictive a été particulièrement transformatrice dans l’IT. La complexité accrue de l’architecture, liée à la virtualisation, au cloud, à l’Internet des objets (IoT) et à bien d’autres avancées technologiques, augmente de manière exponentielle le volume de données à interpréter – et donc les retards dans le diagnostic et la résolution des problèmes. Soutenue par le big data et l’intelligence artificielle (IA), l’analyse prédictive surmonte ces difficultés. En identifiant des modèles, elle peut créer des « prédicteurs » axés sur les problèmes de performances, les défaillances de réseau, l’épuisement des capacités, les failles de sécurité et une foule d’autres problèmes d’infrastructure. Grâce à ces prédictions, une organisation peut améliorer ses performances, réduire les temps d’arrêt et accroître globalement la résilience de son infrastructure.
Comment fonctionnent les modèles d’analyse prédictive
Les modèles d’analyse prédictive exécutent des algorithmes de machine learning sur des ensembles de données pertinentes. La création d’un modèle prédictif est un processus en plusieurs étapes qui commence par la définition d’un objectif métier clair. Souvent formulé comme une question, cet objectif permet de déterminer la portée du projet et le type de modèle de prédiction à utiliser. Il faut ensuite suivre une série d’étapes, qui sont décrites ci-dessous.
- Préparez vos données historiques pour l’analyse statistique. Dans la plupart des organisations, les données sont réparties sur de nombreuses sources : entrepôts de données, bases de données en ligne et appareils connectés. Elles doivent être collectées et « nettoyées » pour supprimer les données en double, incomplètes, corrompues ou inexactes, puis organisées dans un format défini à des fins d’analyse.
- Divisez les données en deux ensembles de données : les données d’entraînement et les données de test. Les données d’entraînement correspondent à des résultats connus ; elles sont transmises à l’algorithme de machine learning pour qu’il les évalue et puisse faire des prédictions à partir de nouvelles données. Les données de test seront utilisées pour confirmer que le modèle sait faire des prédictions précises.
- Exécutez un ou plusieurs algorithmes sur l’ensemble de données. Une fois que vous avez déterminé le type de modèle et les algorithmes appropriés, vous pouvez créer et déployer le modèle prédictif.
La modélisation prédictive est un processus itératif. Une fois qu’un modèle d’apprentissage est créé et déployé, ses performances doivent être supervisées et améliorées. Autrement dit, il doit être continuellement actualisé avec de nouvelles données, entraîné, évalué et géré pour rester à jour.
Techniques de modélisation prédictive
Il existe plusieurs techniques courantes de modélisation prédictive, que l’on peut classer en deux catégories : analyse de régression et analyse de classification. L’analyse de régression examine une variable dépendante (l’action) et plusieurs variables indépendantes (les résultats) et évalue la force de la relation entre elles. Elle peut être utilisée pour prévoir des tendances, prédire l’impact d’une action particulière ou déterminer si une action et ses résultats sont corrélés. Une fois que vous décidez d’utiliser l’analyse de régression, vous avez le choix entre plusieurs types. Voici les plus courants :
- Régression linéaire simple : c’est la forme la plus élémentaire d’analyse de régression. La régression linéaire établit la relation entre deux variables. Pour utiliser un exemple simple, un magasin peut utiliser la régression linéaire pour déterminer la relation entre le nombre de vendeurs qu’il emploie et le montant des revenus qu’il génère.
- Régression linéaire multiple : elle peut être utilisée pour établir la relation entre la variable dépendante et chacune des variables indépendantes. Dans le domaine de la santé, un chercheur peut utiliser cette technique pour déterminer l’impact de facteurs comme le tabagisme, l’alimentation et l’exercice sur le développement des maladies cardiaques, par exemple.
- Régression logistique : ce type d’analyse de régression est utilisé pour déterminer la probabilité qu’un ensemble de facteurs aboutisse à ce qu’un événement se produise ou ne se produise pas. Les banques, par exemple, l’utilisent souvent pour prédire si le demandeur d’un prêt risque ou non de faire défaut.
- Régression de crête : cette technique est utilisée pour analyser plusieurs ensembles de données de régression linéaire qui présentent un degré élevé de corrélation entre les variables indépendantes.
L’analyse de classification trie les données en catégories en vue d’une analyse plus précise. Elle utilise plusieurs techniques mathématiques :
- Arbres de décision : cette technique reproduit le processus de prise de décision en prenant pour point de départ une seule question ou idée. Elle analyse ensuite différents plans d’action et leurs effets possibles à travers un processus de « ramification » pour parvenir à une décision.
- Réseaux de neurones : inspirée du cerveau humain, cette technique regroupe et classe les données afin d’identifier des modèles et des tendances trop complexes pour d’autres techniques. Les sites de vente en ligne s’en servent pour recommander des produits en fonction des achats antérieurs d’un utilisateur.
Analyse prédictive et analyse prescriptive : quelle différence ?
La modélisation prescriptive consiste à analyser des données pour suggérer un plan d’action en temps réel. Elle s’appuie essentiellement sur les informations produites par d’autres modèles d’analyse pour envisager les ressources disponibles, les performances passées et actuelles et les résultats potentiels, afin de proposer la prochaine mesure à prendre. Dans un contexte informatique, par exemple, la modélisation prescriptive peut proposer des améliorations d’infrastructure sur la base des données de surveillance et de maintenance, et même permettre au système de faire lui-même les ajustements nécessaires selon un script préenregistré.
L’analyse prescriptive est une extension de l’analyse prédictive. Si l’analyse prédictive peut vous dire quel problème va probablement se produire, quand et pourquoi, l’analyse prescriptive va plus loin et suggère des actions spécifiques pour le résoudre. Les deux types d’analyses vous permettent de prendre des décisions plus éclairées, mais c’est l’analyse prescriptive qui exploite le mieux vos données en vous permettant d’optimiser les processus et les systèmes à court et à long terme. En savoir plus sur les différences entre analyse prédictive et analyse prescriptive.
Choisir le bon modèle prédictif
Il en existe plusieurs. La plupart sont conçus pour des applications spécifiques, mais certains peuvent être utilisés dans diverses situations :
- Modèles de prévision : il s’agit sans doute du type le plus courant de modèle d’analyse prédictive. Les modèles de prévision tirent des informations des données historiques pour estimer les valeurs de nouvelles données. Les modèles de prévision peuvent être utilisés pour déterminer le nombre d’appels qu’un agent du service client peut traiter en une journée ou le nombre d’exemplaires d’un best-seller qu’un libraire doit commander pour la période de vente à venir, par exemple.
- Modèles de classement : ces modèles utilisent des données historiques pour catégoriser les informations, afin de répondre à des questions et de produire des analyses plus larges pour faciliter les prises de décisions importantes. Populaires dans un large éventail de secteurs, ils sont particulièrement performants pour répondre à des questions fermées telles que « Ce demandeur de prêt est-il susceptible de faire défaut ? »
- Modèles de clustering : ce type de modèle trie les données autour d’attributs communs. La segmentation de la clientèle en est une application courante : le modèle peut regrouper les données d’un client d’une entreprise autour d’attributs et de comportements communs. Les modèles de clustering utilisent deux types de clustering : dur et souple. Dans le clustering « dur », les données appartiennent ou non à une catégorie. Le clustering souple, quant à lui, ne place pas chaque donnée dans un cluster distinct : il lui attribue une probabilité d’appartenance à chaque cluster.
- Modèles de valeurs aberrantes : ces modèles identifient et analysent les entrées anormales dans un ensemble de données. Ils sont généralement utilisés dans les situations où des anomalies non reconnues peuvent coûter cher à l’entreprise, ce qui est le cas dans la finance et dans le retail. Par exemple, un modèle de valeurs aberrantes peut identifier une transaction frauduleuse en évaluant le montant, l’heure, le lieu, l’historique d’achat et la nature de l’achat.
- Modèles de séries chronologiques : ces modèles utilisent le temps comme paramètre d’entrée pour prédire les tendances sur une période spécifique. Un centre d’appels, par exemple, peut utiliser ce modèle pour déterminer le nombre de demandes d’assistance qu’il peut s’attendre à recevoir au cours du mois à venir, en fonction du nombre d’appels reçus au cours des trois mois précédents.
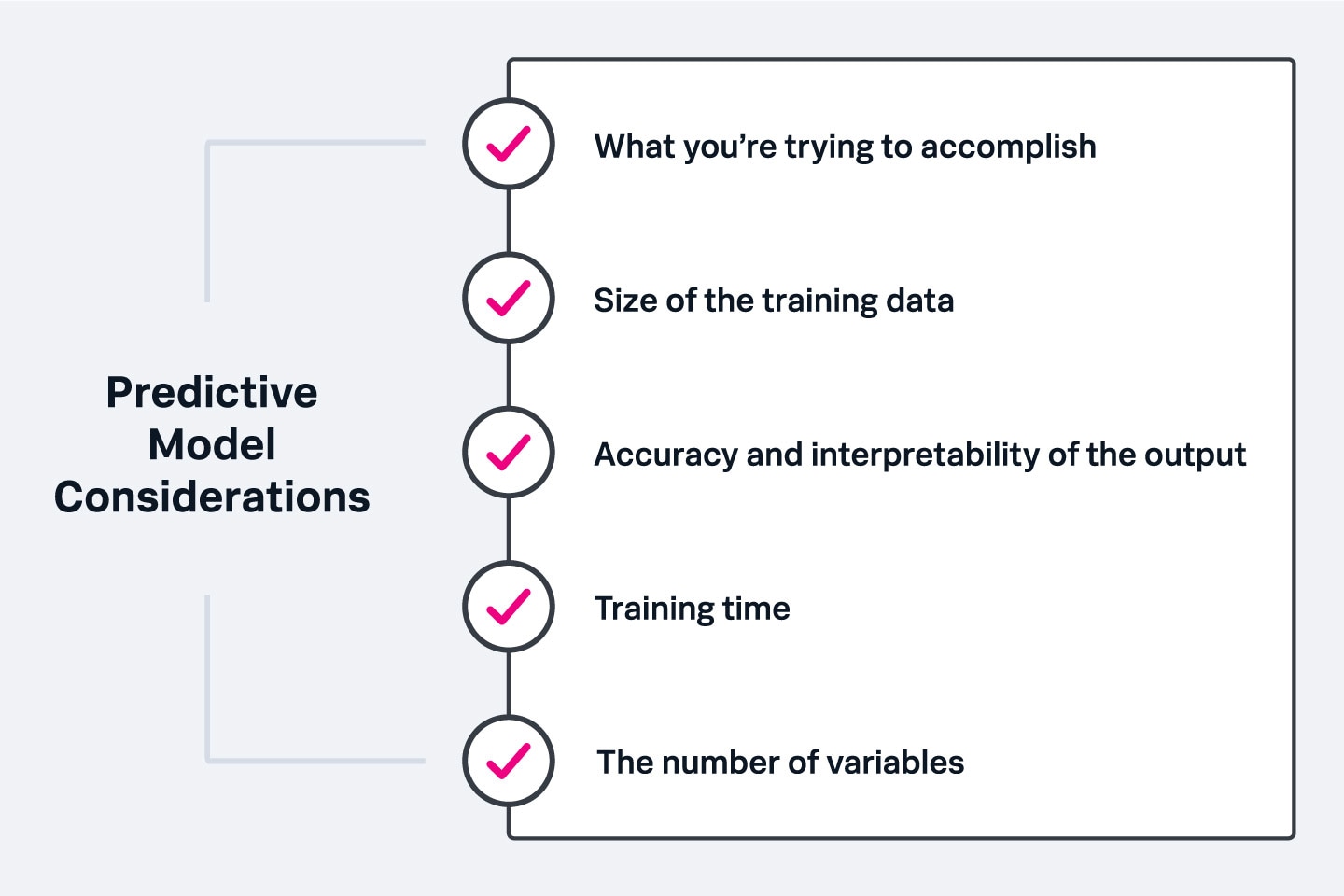
Plusieurs facteurs doivent être soupesés pour bien choisir un modèle prédictif :
- Objectif poursuivi : les modèles de prévision sont parfaits pour prédire les événements futurs en fonction des événements passés, tandis que les modèles de classification s’imposent si vous souhaitez explorer des possibilités de résultats pour vous aider à prendre une décision importante. Le bon modèle dépendra en grande partie de ce que vous essayez d’apprendre de vos données.
- Quantité de données d’entraînement : en général, plus vous collectez de données d’entraînement, plus les prédictions sont fiables. Si vous avez peu de données, ou si ce que vous essayez de mesurer n’apparaît que rarement dans un ensemble de données, vous ne choisirez pas des algorithmes prévus pour traiter un vaste ensemble de données avec beaucoup de variables.
- Précision et interprétabilité du résultat : l’exactitude désigne la fiabilité des prédictions du modèle, et l’interprétabilité est la facilité avec laquelle vous allez les comprendre. Idéalement, votre modèle doit offrir un bon équilibre entre ces deux facteurs.
- Temps d’entraînement : plus vous avez de données d’entraînement, plus il vous faudra de temps pour entraîner l’algorithme. Vous allez également avoir besoin de prolonger l’entraînement pour obtenir une plus grande précision. Dans de nombreuses entreprises, ces deux facteurs peuvent devenir les plus importants dans le choix d’un modèle.
- Linéarité des données : toutes les relations ne sont pas parfaitement linéaires, et des structures de données plus complexes peuvent limiter vos options à des techniques telles que les réseaux de neurones.
- Nombre de variables : les données comportant un grand nombre de variables ralentissent certains algorithmes et prolongent la durée de l’entraînement, ce qui doit être pris en compte dans le choix du modèle.
En fin de compte, vous devrez sans doute exécuter plusieurs algorithmes et modèles prédictifs sur vos données et évaluer les résultats pour trouver la formule qui répond le mieux à vos besoins.
Quelques avantages métiers de la modélisation prédictive
Chaque entreprise, quel que soit son secteur d’activité, s’appuie sur les données pour prendre de meilleures décisions métiers. La modélisation prédictive renforce votre confiance dans les décisions en présentant les effets les plus probables de l’action que vous envisagez.
La pratique offre plusieurs avantages concrets :
- Amélioration de la prise de décision : en anticipant les résultats à venir, les entreprises prennent des décisions plus informées. Qu’il s’agisse de l’affectation des ressources, de la création de campagnes marketing ou de la sélection des prospects à cultiver, les informations prédictives offrent de précieux conseils.
- Économies : les modèles prédictifs peuvent aider les entreprises à anticiper et gérer les risques, à réduire le gaspillage des ressources et à optimiser les processus. Par exemple, prédire les défaillances des machines peut permettre d’intervenir au bon moment pour éviter les temps d’arrêt coûteux.
- Augmentation des revenus : en s’appuyant sur l’analyse prédictive, les entreprises peuvent mieux comprendre le comportement des clients, segmenter leur marché et cibler les opportunités les plus prometteuses. Elles peuvent notamment prédire quels clients sont les plus susceptibles de mettre fin à leur relation et ainsi intervenir de façon proactive.
- Efficacité opérationnelle : prédire la demande permet de mieux gérer l’inventaire, d’optimiser les processus de la chaîne d’approvisionnement et de répondre aux besoins des clients sans conserver un stock inutile.
- Expérience client : les modèles prédictifs aident les entreprises à mieux interpréter les besoins et les préférences de leurs clients, ce qui ouvre la voie à des recommandations personnalisées, des messages marketing individualisés et davantage d’efficacité lors des interactions avec le service client.
- Gestion des risques : les institutions financières utilisent la modélisation prédictive pour évaluer le risque des prêts, les déclarations de sinistre et les activités potentiellement frauduleuses. En prédisant quelles transactions peuvent être frauduleuses, elles peuvent réduire le risque de pertes financières.
- Avantage stratégique : en obtenant des informations sur l’évolution de l’état des marchés, sur le paysage de la concurrence et sur les préférences des clients, les entreprises peuvent optimiser leur positionnement et acquérir un avantage concurrentiel.
Défis, risques et idées reçues
Les prédictions effectuées de façon mathématique sur la base d’ensembles de données ne sont pas infaillibles. En règle générale, les problèmes liés à la modélisation prédictive se résument à quelques facteurs. Le premier est le manque de bonnes données. Pour faire des prédictions précises, il vous faut un grand ensemble de données, contenant de nombreuses variables appropriées pour établir vos prédictions. Mais bien souvent, les organisations ne sont pas équipées d’une plateforme de données robuste, capable de centraliser toutes leurs données, d’analyser les informations à un niveau granulaire et d’en extraire des informations exploitables. Or des échantillons de données restreints ou incomplets peuvent facilement nuire à la fiabilité des prédictions.
Autre obstacle majeur à l’efficacité de la modélisation prédictive : l’idée selon laquelle l’avenir restera à l’image du passé. Les modèles prédictifs sont bâtis à partir de données historiques, mais les comportements évoluent avec le temps, ce qui peut invalider brutalement des modèles utilisés depuis longtemps. Selon les situations, des variables inédites ou uniques suscitent de nouveaux comportements et approches que les modèles antérieurs ne pourront pas toujours anticiper. C’est pourquoi les modèles prédictifs doivent être constamment actualisés à l’aide de nouvelles données pour suivre l’évolution des comportements et baser des prédictions précises dessus.
Autre problème majeur : la dérive de modèle. La dérive de modèle désigne la tendance d’un modèle à perdre sa capacité prédictive au fil du temps. Généralement due à des changements statistiques dans les données, elle peut dégrader la qualité des prévisions si elle n’est pas détectée, et donc nuire à l’entreprise qui les exploite.
Votre entreprise peut-elle compter sur la modélisation prédictive ?
La modélisation prédictive est une science des données robuste, mais elle n’est pas omnisciente. Aucun modèle prédictif n’aurait pu prévoir la pandémie de Covid-19 ni son impact sur le comportement des consommateurs à une si grande échelle, par exemple. En dehors de ces circonstances uniques, la modélisation prédictive est un moyen très efficace d’éclairer les décisions métiers dès lors que vous disposez de la bonne solution et des bonnes équipes, mais aussi que vous actualisez continuellement votre modèle avec de nouvelles données.
Pour bien démarrer
Commencez par bien définir les problèmes que votre organisation cherche à résoudre. Si vous établissez clairement l’objectif à atteindre, vous obtiendrez un résultat précis et utilisable, tandis qu’adopter une approche ad hoc sera beaucoup moins efficace.
Ensuite, évaluez les lacunes en matière de compétences et de technologie dans votre entreprise. Certes, les solutions logicielles font une grande partie du travail, mais la modélisation prédictive a besoin d’expertise pour être efficace. Assurez-vous de disposer du personnel, des outils et de l’infrastructure nécessaires pour identifier et préparer les données que vous utiliserez dans votre analyse.
Enfin, réalisez un projet pilote – idéalement, un projet de petite envergure sans enjeu stratégique, mais tout de même intéressant pour l’entreprise. Identifiez votre objectif, choisissez les indicateurs que vous utiliserez pour l’atteindre et établissez une méthode pour en quantifier la valeur. Une fois votre premier succès en main, vous aurez une base sur laquelle bâtir des projets de modélisation prédictive plus importants.
Conclusion
La modélisation prédictive est l’outil ultime de l’arsenal analytique. Elle permet aux organisations de toutes tailles d’accroître la fiabilité et l’impact de leurs décisions métiers. Muni d’une approche systématique et de la bonne solution logicielle, vous pouvez commencer à mettre la puissance de la modélisation prédictive au service de la résolution des problèmes métiers les plus épineux et ainsi découvrir de nouvelles opportunités.
Une erreur à signaler ? Une suggestion à faire ? Contactez-nous à l’adresse ssg-blogs@splunk.com.
Cette publication ne représente pas nécessairement la position, les stratégies ou l’opinion de Splunk.

Articles connexes
À propos de Splunk
La plateforme Splunk élimine les obstacles qui séparent les données de l'action, pour donner aux équipes d'observabilité, d'IT et de sécurité les moyens de préserver la sécurité, la résilience et le pouvoir d'innovation de leur organisation.
Fondée en 2003, Splunk est une entreprise internationale. Ses plus de 7 500 employés, les Splunkers, ont déjà obtenu plus de 1 020 brevets à ce jour, et ses solutions sont disponibles dans 21 régions du monde. Ouverte et extensible, la plateforme de données Splunk prend en charge les données de tous les environnements pour donner à toutes les équipes d'une entreprise une visibilité complète et contextualisée sur l'ensemble des interactions et des processus métier. Splunk, une base solide pour vos données.

Abonnez-vous à notre blog
Recevez les derniers articles de Splunk par e-mail.

