Qu’est-ce que la disponibilité ?

La disponibilité désigne la durée pendant laquelle un dispositif, un service ou un autre composant de l’infrastructure informatique est utilisable, s’il est disponible. Comme la disponibilité, ou la disponibilité des systèmes, indique si un système fonctionne normalement et dans quelle mesure il peut se rétablir après une interruption, une attaque ou tout autre type de défaillance, la disponibilité est considérée comme la métrique la plus importante dans la gestion des technologies de l’information. C’est une préoccupation constante. En effet, les activités de toute une entreprise peuvent être mises à l’arrêt en cas d’indisponibilité d’un composant matériel ou d’un service.
De nombreux processus métiers et facteurs internes et externes peuvent affecter la disponibilité, ce qui explique qu’elle soit difficile à atteindre. Les attaques par déni de service, les défaillances matérielles, les interruptions de service IT et même les catastrophes naturelles sont autant de facteurs qui affectent la disponibilité et prolongent le temps moyen de réparation (MTTR). Un problème touchant le serveur cloud partagé d’un fournisseur de service tiers peut se répercuter en aval sur la disponibilité d’une autre entreprise. Et dans n’importe quel environnement informatique, de nombreux dispositifs et services sont en interaction constante, et il suffit qu’un appareil ou un service ait un problème pour provoquer une interruption à grande échelle. Par exemple, un serveur web critique peut devenir indisponible suite à la corruption d’une base de données stratégique, même si le matériel lui-même et le réseau sont intacts.
La disponibilité est généralement représentée sous la forme d’un pourcentage, calculé comme suit :
Disponibilité = (Temps de service total) - (Temps d’indisponibilité)/(Temps de service total)
Cette métrique peut également être représentée par une durée. Par exemple, si le serveur X promet une disponibilité de 99,999 % (qu’on appelle couramment les « cinq neuf » dans l’industrie) sur un mois, cela correspond à un maximum de 26 secondes d’indisponibilité par mois.
Dans cet article, nous allons voir comment les entreprises peuvent atteindre de hauts niveaux de disponibilité dans un large éventail d’environnements d’exploitation, ainsi que les avantages et les coûts de ces pratiques.
Splunk ITSI est un leader dans le domaine de l’AIOps
Splunk IT Service Intelligence (ITSI) est une solution d’AIOps, d’analytique et de gestion IT qui aide les équipes à anticiper les incidents avant qu’ils n’affectent les clients.

ITSI utilise l’IA et le machine learning pour corréler les données collectées auprès de nombreuses sources de supervision et offrir une vue unifiée des services IT et métiers pertinents. La solution a un double avantage : elle réduit les déluges d’alertes et permet la prévention des interruptions de service.
Qu’est-ce que la haute disponibilité ?
On parle de haute disponibilité lorsqu’un système présente des niveaux exceptionnels de disponibilité, de tolérance aux défaillances et de résilience.
La disponibilité, ou la haute disponibilité, décrit typiquement un service qui ne présente pratiquement jamais de défaillance. Des sites majeurs comme Google et Amazon, s’ils ne peuvent éviter entièrement les indisponibilités, sont tellement fiables qu’ils servent de norme de haute disponibilité pour d’autres services. Ils s’appuient sur de nombreuses technologies complexes et coûteuses pour garantir un tel niveau de disponibilité. Les services de distribution d’énergie, de gaz et d’eau offrent d’excellents exemples de la haute disponibilité à l’œuvre, tout comme les composants des systèmes avioniques et l’équipement utilisé en hôpital dans les salles d’opération.
La haute disponibilité est également associée à la réactivité. Si un service est opérationnel mais que sa lenteur frustre les utilisateurs finaux, sa disponibilité peut être remise en question. La disponibilité peut être mesurée formellement à l’aide de la formule ci-dessus, qui envisage la disponibilité comme une donnée binaire – le service est en ligne ou hors ligne. Mais en la rapprochant de métriques connexes comme le temps de réponse et le taux d’erreur, on obtient une évaluation plus nuancée de la disponibilité.
Le standard universel de la haute disponibilité véritable est un taux de 99,999 %, qu’on surnomme couramment les « cinq neuf ». Dans l’exemple ci-dessus, une disponibilité de 99,999 % implique 26 secondes d’interruption par mois, soit 5,5 minutes par an. Si vous comptabilisez le temps d’arrêt qu’implique le redémarrage d’un ordinateur personnel après une coupure de courant, vous comprenez à quel point il peut être difficile d’atteindre ces cinq neuf.
Atteindre une haute disponibilité
La haute disponibilité repose sur l’utilisation de technologies spécialement conçues pour cette mission. Dans les systèmes informatiques, la haute disponibilité est le fruit des tactiques et outils suivants :
- Redondance : plusieurs systèmes fonctionnent en parallèle de manière à ce qu’ils puissent se relayer en cas de défaillance. La redondance peut être mise en place de façon locale ou distribuée. La redondance locale (plusieurs serveurs dans une même salle) est efficace en cas de défaillance matérielle isolée, tandis que la redondance distribuée géographiquement est utile en cas de catastrophe naturelle ou autre problème régional pouvant mettre à l’arrêt un data center complet. Les fournisseurs de service à grande échelle exploitent des serveurs dans des dizaines de régions du monde pour garantir des niveaux de disponibilité extrêmes.
- Évolutivité : les systèmes sont conçus pour traiter une augmentation soudaine de la charge (un pic de trafic web, par exemple), qu’elle soit légitime ou malveillante, comme c’est le cas dans une attaque par déni de service distribué.
- Équilibrage de charge : ces outils répartissent les workloads entre les serveurs et les services pour minimiser la charge pesant sur chaque système et éviter qu’un service soit surchargé.
- Supervision : le personnel informatique peut utiliser des systèmes intelligents pour superviser les performances de tout ce qui précède en temps réel et être averti si un problème émerge, de préférence bien avant qu’il n’entraîne une interruption de service.
- Sauvegarde : des sauvegardes de haute qualité garantissent un rétablissement rapide et efficace en cas d’interruption, et sont à ce titre un composant incontournable dans toute stratégie de haute disponibilité.
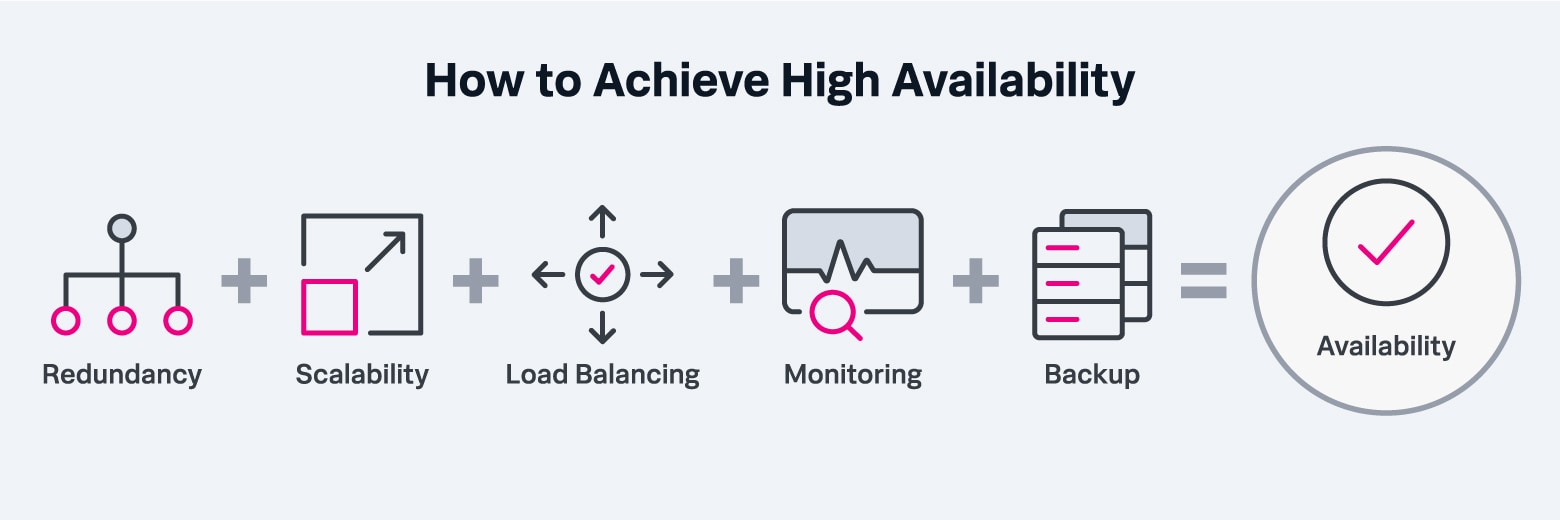
Pour atteindre votre objectif de haute disponibilité, il vous faut une myriade d’outils qui veillent à ce que tous les systèmes fonctionnent de façon optimale.
Haute disponibilité et tolérance aux défaillances
La haute disponibilité et la tolérance aux défaillances sont deux sujets étroitement liés, mais avec une différence majeure : si les systèmes haute disponibilité ont un taux de temps d’arrêt très faible, les systèmes tolérants aux interruptions sont conçus dans une optique de zéro temps d’arrêt. Cet objectif peut être atteint mais son coût est extrêmement élevé et il implique un niveau de complexité supérieur. Les systèmes tolérants aux défaillances sont conçus spécialement pour supporter les interruptions, qu’il s’agisse d’un composant matériel défectueux, d’un bug dans le code d’un logiciel ou d’un problème dans un autre aspect de l’infrastructure.
La tolérance aux défaillances est essentiellement mise en œuvre dans les environnements cloud de grande envergure. Amazon AWS, Azure et Google Cloud, par exemple, exploitent tous plusieurs zones de disponibilité, qui correspondent aux différentes régions du monde où résident les données. En s’exécutant simultanément sur plusieurs zones de disponibilité, une application peut être conçue de façon à être tolérante aux défaillances. Si un problème émerge dans une zone, d’autres zones pourront prendre le relais. Cette conception est similaire à celle de nombreux services hautement disponibles, mais elle est plus complexe. Si une conception à haute disponibilité peut réduire le nombre de copies supplémentaires d’une application, par exemple en limitant les possibilités d’écriture sur l’application lorsque l’instance principale du serveur est hors ligne, ce n’est pas le cas d’un système tolérant aux défaillances. Dans certains cas, il peut être nécessaire d’exécuter simultanément plusieurs copies exactes de l’application dans toutes les zones de disponibilité, ce qui inclut la réplication à l’identique et en temps réel de toutes les bases de données éventuellement utilisées.
- L’utilisateur d’un système hautement disponible qui subit une interruption remarquera peut-être que le service est plus lent ou que certaines fonctionnalités manquent.
- Avec un système tolérant aux interruptions, l’utilisateur ne devrait, en théorie, jamais remarquer le moindre changement, quelles que soient les opérations réalisées en coulisses.
Cela dit, même le système le mieux conçu ne peut être entièrement immunisé contre les défaillances sans des investissements très élevés auxquels certains fournisseurs de service majeurs eux-mêmes n’ont pas consenti.
Le choix entre haute disponibilité et tolérance aux défaillances dépend le plus souvent du coût et du rôle stratégique du système. Peut-on parvenir réellement à 26 secondes d’interruption par mois ? Les « trois neuf », qui correspondent à 45 minutes d’indisponibilité par mois, pourraient constituer un objectif plus réaliste. Est-ce qu’un taux d’indisponibilité de 26 secondes par mois est acceptable en toutes circonstances ? Est-ce que l’élimination de ces temps d’arrêt mérite une augmentation significative de vos dépenses en services cloud ? Il faut aussi se demander à quel moment l’interruption se produit. Si les utilisateurs sont concentrés dans une région en particulier, est-ce que l’application est considérée comme indisponible si personne ne s’en aperçoit ? La réponse à ces questions dépend de l’application concernée et du niveau de risque propre à l’entreprise.
Haute disponibilité dans le cloud computing
La haute disponibilité est l’un des atouts les plus vantés du cloud. Comme les ressources sont plus fluides dans le cloud, on peut concevoir un système redondant et équipé de fonctions d’équilibrage des charges plus simplement et à un coût inférieur. Dans le domaine des opérations cloud, ce sont les clusters qui permettent cela. Un cluster est, pour résumer, un groupe de serveurs virtuels contenant chacun une copie de l’environnement de production. Les clusters sont conçus spécialement pour fournir les fonctions d’équilibrage des charges et de basculement en cas d’interruption. Si un incident provoque une défaillance dans une application sur un serveur, les autres serveurs du cluster vont immédiatement prendre le relais. Dans certains environnements à forte densité de workloads, un cluster peut abriter l’exécution de dizaines, voire de centaines de serveurs.
Les systèmes cloud offrent également bien d’autres caractéristiques propres à la haute disponibilité : fonctions intégrées d’équilibrage des charges, évolutivité immédiate en cas de surcharge, systèmes de sauvegarde des données et bien d’autres. Ces outils sont généralement prêts à l’emploi et fournis à titre d’options de configuration par le fournisseur de services cloud. Les niveaux de disponibilité spécifiés sont habituellement intégrés dans les accords de niveau de service (SLA) des fournisseurs. Si la disponibilité passe en dessous du seuil précisé dans le SLA, le client est en droit de demander un remboursement ou un crédit. On recommande toutefois de lire attentivement les accords pour comprendre ce qu’entend le fournisseur de service par « indisponibilité ».
Haute disponibilité dans l’architecture
Dans les infrastructures physiques et les architectures d’entreprise, la haute disponibilité est le fruit de matériel redondant et de logiciels spécialement conçus pour assurer l’équilibrage des charges et des fonctions de basculement en cas d’interruption. Les systèmes de stockage peuvent être conçus dans une optique de haute disponibilité en utilisant des disques miroirs et des ensembles RAID, qui permettent au stockage de remplir normalement ses fonctions même en cas de défaillance d’un disque dur. Les alimentations électriques et les systèmes de refroidissement peuvent, eux aussi, être redondants pour se relayer en cas de défaillance de l’unité principale. Les systèmes d’alimentation sans interruption (ASO) et les générateurs peuvent fournir une alimentation de secours en cas de coupure électrique.
En dehors du cloud, la création de clusters et l’équilibrage des charges sont également utilisables dans les environnements locaux, mais leur coût est considérablement plus élevé. Dans ce cas, plusieurs serveurs (formant un cluster) sont exploités en parallèle. Chacun d’eux abrite un exemplaire de la base de données, des applications et des logiciels nécessaires. Le système (matériel ou logiciel) d’équilibrage des charges achemine les requêtes entrantes vers le serveur du cluster qui affiche le plus de disponibilité et répartit les requêtes de façon aussi homogène que possible. De cette manière, aucun serveur en particulier ne se retrouve surchargé et les requêtes sont traitées à une vitesse maximale. Si un serveur devient indisponible pour une raison ou une autre, le système d’équilibrage de charge l’exclut de la rotation et distribue les requêtes aux serveurs restants jusqu’à ce qu’il soit réparé.
Haute disponibilité du réseau
En matière de réseau, la haute disponibilité consiste à assurer le bon fonctionnement de l’infrastructure. La disponibilité du réseau revêt une importance stratégique : c’est elle qui relie l’utilisateur à toutes les ressources, qu’elles soient hébergées sur place ou dans le cloud. Comme dans le cas des autres types de disponibilité, la disponibilité du réseau repose sur des systèmes de redondance, d’équilibrage des charges et d’évolutivité des capacités.
La conception d’un réseau hautement disponible consiste à dupliquer le matériel réseau de l’entreprise et, souvent, à combiner plusieurs fournisseurs d’accès à Internet. Pour prendre un exemple simple, on utilisera deux routeurs pour se connecter à deux FAI différents, ce qui représente quatre combinaisons de connectivité possibles (le routeur A vers le FAI A, le routeur A vers le FAI B, le routeur B vers le FAI A et le routeur B vers le FAI B). Si un routeur subit une interruption, ou si le service d’un fournisseur d’accès à Internet est coupé, la connectivité du réseau sera maintenue. C’est un exemple très simple et la topologie haute disponibilité peut devenir très complexe quand l’entreprise se développe et que ses exigences de fiabilité augmentent. (On peut ainsi décliner notre exemple avec deux FAI et quatre routeurs, quatre FAI et huit routeurs, et ainsi de suite.) Il peut également être utile de prévoir une méthode de connectivité de secours. Que vous ayez un seul ou dix fournisseur d’accès à Internet, si les connexions passent toutes par un même conduit qui présente des vulnérabilités ou pourrait être endommagé, le risque est là.
Principaux avantages de la haute disponibilité
Les avantages de haute disponibilité sont pluriels :
- Réduction des risques : la haute disponibilité réduit le risque d’inaccessibilité des ressources, quelle qu’en soit la cause, ce qui est indispensable à la continuité des activités.
- Augmentation des revenus : la réduction des risques a un impact direct sur les revenus en assurant un meilleur accès des utilisateurs aux services qui les génèrent.
- Rétablissement plus rapide : en cas d’interruption, les technologies de haute disponibilité réduisent le temps nécessaire au rétablissement des systèmes.
- Amélioration de l’expérience client : les technologies de haute disponibilité équilibrent les charges pour éviter qu’une ressource particulière soit sursollicitée. De cette manière, tous les utilisateurs bénéficient d’une expérience équivalente et aucun d’entre eux ne doit subir de retard excessif dans l’exécution de certaines tâches.
- Satisfaction du personnel informatique : les systèmes haute disponibilité facilitent le processus de rétablissement en cas de problème, ce qui réduit les interventions d’urgence et influe positivement sur le moral des équipes.
- Évolutivité plus simple : les solutions de haute disponibilité permettent à l’entreprise de faire évoluer plus facilement ses capacités en cas de besoin, notamment par l’ajout de serveurs supplémentaires à un cluster physique ou virtuel.
- Respect des accords de niveau de service : dans certains cas, la haute disponibilité n’est pas une option : elle est exigée par un accord de niveau de service (SLA), qu’il soit interne ou concerne des clients. Toute entreprise qui offre une garantie de service doit adopter la haute disponibilité.
Les grands défis de la haute disponibilité
Plusieurs obstacles peuvent freiner la mise en place de la haute disponibilité et nuire à son maintien une fois qu’elle est implémentée. Voici les plus importants :
- Coût élevé : la haute disponibilité implique l’acquisition de matériel et de logiciels supplémentaires et sa gestion repose sur une technologie coûteuse. Nous abordons les implications financières de la haute disponibilité dans la section suivante.
- Manque de personnel expérimenté : dans un environnement à haute disponibilité, la gestion des services exige des compétences et des certifications spécifiques qui ne sont pas toujours faciles à obtenir. Et il n’y a rien de pire que de découvrir à l’occasion d’une interruption que votre environnement n’a pas été correctement configuré.
- Enjeux de sécurité : un environnement haute disponibilité n’est pas mieux protégé contre les attaques qu’un environnement à disponibilité standard. Un malware installé sur un serveur d’un cluster peut même facilement se propager aux autres serveurs du même cluster. La fiabilité et les fonctions d’équilibrage de charge des systèmes à haute disponibilité peuvent donner un sentiment de confiance infondé aux équipes informatiques, et c’est pourquoi il faut accorder une attention constante à la cybersécurité.
- Maintien de la fidélité des données : l’un des défis de la haute disponibilité consiste à s’assurer que les données sont répliquées à l’identique et en temps réel entre les différents dépôts. La présence d’informations obsolètes dans un processus peut provoquer de nombreuses erreurs, une corruption des données ou pire encore. Le maintien d’une source unique de vérité pour les données critiques représente un défi majeur dans tout environnement haute disponibilité.
- Négligence du personnel : pour optimiser les temps de réponse, les équipes de livraison des services informatiques doivent procéder régulièrement à des exercices de rétablissement pour anticiper et résoudre les problèmes potentiels. Si la résilience de l’infrastructure fait que les problèmes potentiels et leurs solutions ne sont jamais abordés ni analysés, les équipes ne sauront pas traiter les problèmes avec la rapidité qu’ils exigent lorsqu’ils surviendront.
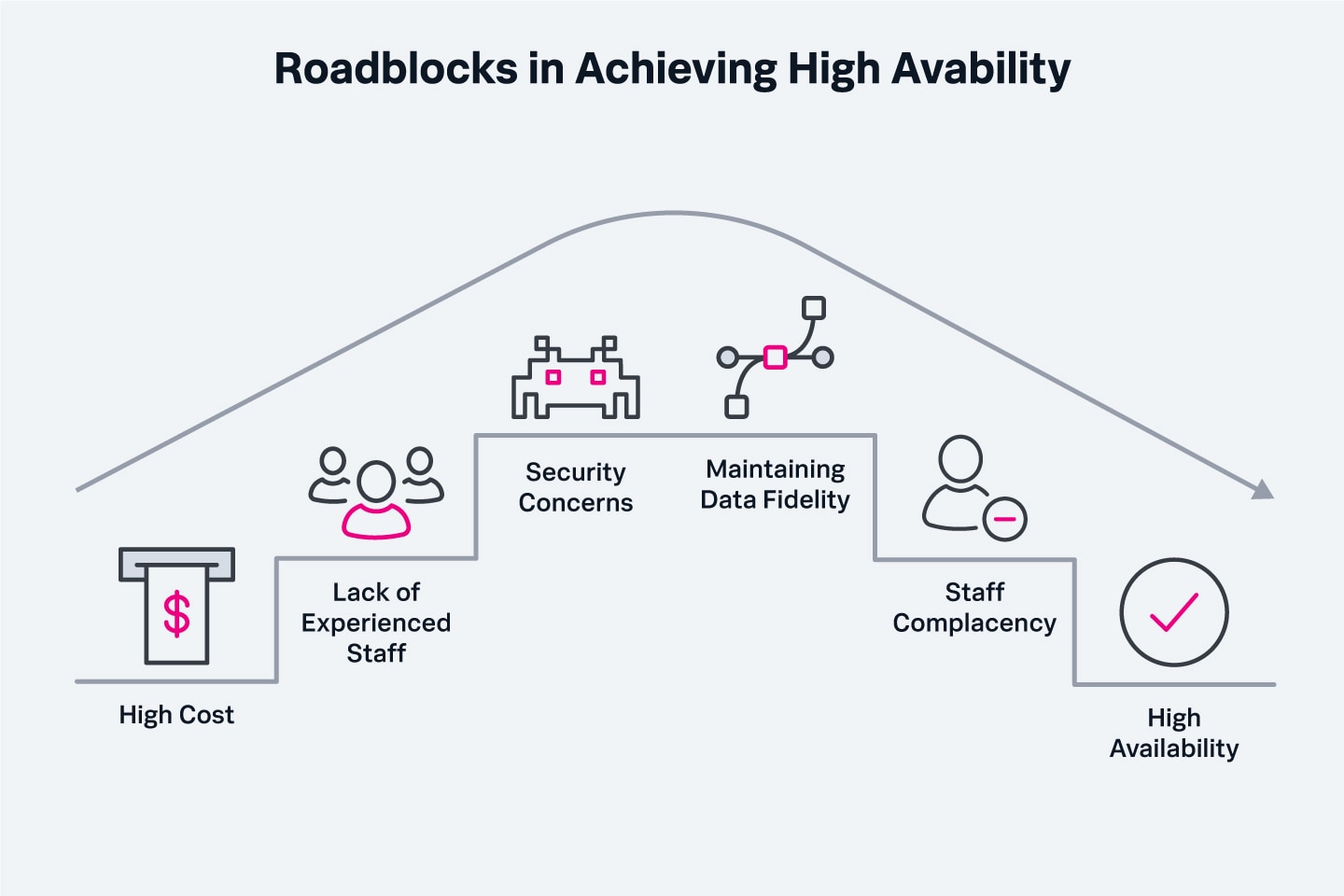
Les freins à la haute disponibilité sont souvent à chercher du côté du facteur humain, et plus précisément du manque de personnel expérimenté et de la négligence.
Considérations relatives au coût de la haute disponibilité
La mise en place de la haute disponibilité peut coûter très cher. Outre le coût direct des produits et des services, les systèmes à haute disponibilité exigent des efforts de maintenance et de supervision plus importants que les systèmes informatiques traditionnels, ce qui peut avoir un impact significatif sur le fonctionnement de votre organisation.
L’amélioration de la disponibilité opérationnelle vaut-elle réellement l’investissement financier qu’elle exige ? Il faut calculer le rapport bénéfice-risque. L’entreprise doit déterminer le coût total des temps d’arrêt et le comparer à celui de leur élimination. Si les services de haute disponibilité nécessaires pour limiter les temps d’arrêt ont un coût supérieur à celui d’une interruption (chiffrable en termes de ventes perdues, par exemple), il peut être préférable de renoncer à l’investissement. Une entreprise peut tout de même s’efforcer de rationaliser la dépense en haute disponibilité en choisissant un niveau de disponibilité moins élevé, à quatre neuf plutôt que cinq, par exemple.
Présentation de la supervision de la disponibilité
La supervision de la disponibilité consiste à observer l’état des systèmes technologiques essentiels, qu’il s’agisse de services basés sur site ou dans le cloud. Dans leur forme la plus simple, les outils de supervision de la disponibilité peuvent rendre compte de l’état d’un système en temps réel, en interrogeant périodiquement un service selon un calendrier défini, pour vérifier sa réactivité. Mais les outils de supervision de la disponibilité peuvent également effectuer des tests plus complexes pour produire davantage d’informations ; ils peuvent, par exemple, vérifier si les services sont accessibles à partir de différentes régions du monde, mesurer la vitesse de leur réponse, signaler les erreurs et déterminer les raisons des échecs. La supervision de la disponibilité fonctionne mieux lorsqu’on combine des outils en temps réel et prédictifs : les équipes informatiques sont alors en mesure de réagir rapidement aux problèmes avant qu’ils ne deviennent catastrophiques.
La supervision de la disponibilité est un sous-ensemble de la gestion de la disponibilité, qui consiste à superviser et gérer les services informatiques, de la planification aux rapports, en passant par la mise en œuvre et les opérations. Une disponibilité médiocre peut exercer un impact considérable sur l’entreprise : dégradation des revenus et de la rentabilité, clients mécontents et perte de réputation, entre autres. Plusieurs bonnes pratiques visent à garantir une haute disponibilité. Elles consistent notamment à comprendre les principales sources de risque liées à une interruption potentielle, à mettre en œuvre un programme de tests de résistance réguliers et à implémenter l’automatisation dans la mesure du possible.
Supervision et gestion de la disponibilité
La supervision de la disponibilité est un domaine spécifique de la gestion de la disponibilité, qui est le processus de planification, d’analyse, d’exploitation et de supervision d’un service informatique. L’objectif de la gestion de la disponibilité est d’assurer une haute disponibilité : c’est donc une discipline plus complète que la supervision. Elle vise en effet à améliorer activement la disponibilité d’un service.
La gestion de la disponibilité est étroitement liée à plusieurs autres domaines de l’informatique, notamment la gestion des services informatiques (ITSM), l’observabilité et la supervision des performances des applications (APM). L’APM englobe elle-même de nombreuses solutions de supervision : la supervision synthétique, la supervision des serveurs, la supervision du cloud, la supervision du réseau et la supervision des utilisateurs réels (RUM). La RUM va encore plus loin dans la supervision de la disponibilité en offrant une visibilité sur l’expérience utilisateur d’un site web ou d’une application : pour ce faire, elle collecte passivement et analyse les erreurs et les informations temporelles et dimensionnelles sur les utilisateurs finaux en temps réel.
La gestion de la disponibilité est également un composant du framework ITIL. Largement utilisé, ce cadre définit les processus standards et les bonnes pratiques visant à optimiser les services informatiques et à minimiser l’impact des interruptions. Tout comme la supervision de la disponibilité, la gestion de la disponibilité vise à ce que l’entreprise fonctionne au maximum de ses capacités. Mais son objectif ultime reste l’amélioration continue.
Le rôle essentiel de la supervision de la disponibilité
La supervision de la disponibilité fournit une méthode pour s’assurer que les produits et services technologiques fonctionnent comme prévu. Dans tous les types d’organisations ou presque, la technologie est la pierre angulaire des opérations. Prenez la supervision des performances du site web, par exemple. Si la page d’accueil d’une entreprise comme Amazon ou Facebook est inaccessible, une série d’événements catastrophiques risque de s’enchaîner rapidement. Confrontés à une page d’erreur, ou tout simplement incapables de se connecter, les clients se mettront immédiatement en colère et chercheront assez vite des alternatives. Les revenus chuteront mécaniquement, et la réputation de l’entreprise sera dégradée – tout comme sa santé financière.
Lorsqu’une interruption a frappé Facebook à l’automne 2021 (de même que ses frères WhatsApp et Instagram), les sites sont restés inaccessibles pendant environ six heures. Sur cette période, plus de 14 millions d’utilisateurs ont signalé qu’ils ne pouvaient utiliser aucune des applications ou aucun des services de Facebook. Les experts ont estimé que chaque minute d’indisponibilité avait coûté 163 565 $ à l’entreprise, soit environ 60 millions de dollars de perte de revenus ce jour-là.
Ces temps d’arrêt ont aussi un coût en termes de productivité. Quand ils se produisent, l’entreprise sonne le branle-bas de combat, et tous les employés doivent se mobiliser pour corriger les problèmes dans la précipitation et remettre les services en ligne.
Le but de la supervision de la disponibilité est précisément d’éviter ce type de dépenses catastrophiques, en veillant à ce que les services technologiques stratégiques – non seulement les endpoints du site web, mais aussi tout type de matériel ou de logiciel critique – restent opérationnels et conformes aux attentes.
Une autre fonction majeure de la supervision de la disponibilité consiste à surveiller les performances des accords de niveau de service (SLA) passés avec des fournisseurs de technologie tiers. Lorsque vous faites affaire avec un fournisseur de services (connexion à Internet ou technologie cloud, par exemple), le contrat spécifie presque toujours que le fournisseur atteindra un niveau minimum de disponibilité, généralement exprimé en pourcentage de disponibilité sur un mois ou autre période définie. Dans ce cadre, il incombe au client de suivre la disponibilité réelle, grâce à la supervision du temps de fonctionnement, par exemple. Si les relevés de la solution de supervision du client indiquent que le SLA n’est pas respecté, des remboursements ou des crédits sont normalement prévus.
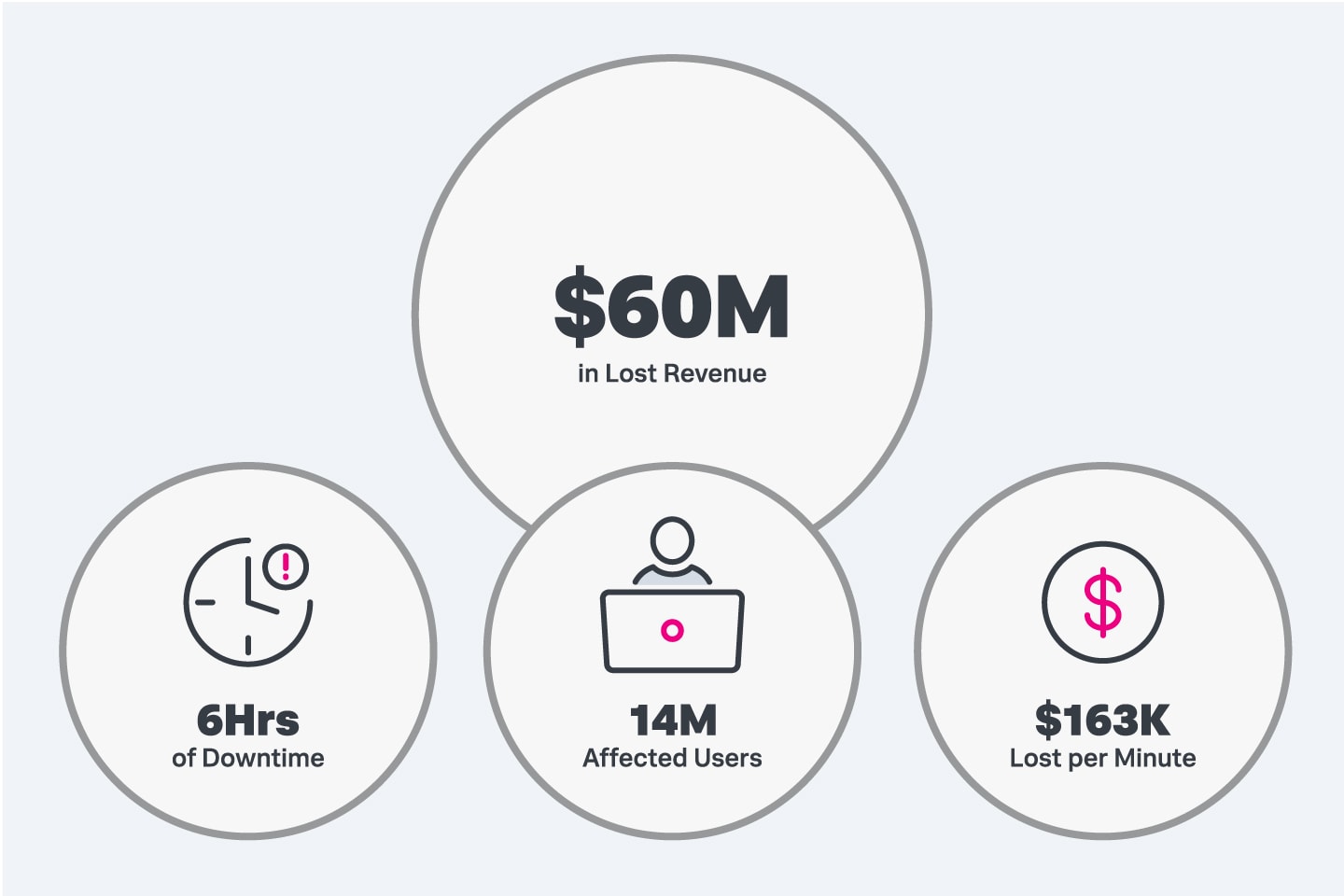
Dans une entreprise, les temps d’arrêt entraînent souvent une perte de clientèle et des pertes financières importantes.
Pour résumer : le maintien de la disponibilité reste crucial pour les entreprises
La disponibilité est l’un des piliers essentiels d’une bonne gestion de l’IT, même quand les entreprises ont abandonné l’informatique locale pour le cloud. La disponibilité va devenir d’autant plus cruciale que les consommateurs comptent de plus en plus sur Internet et les autres technologies de réseau dans leur quotidien. Pour tous les services stratégiques, toute entreprise doit envisager de miser sur les outils et les tactiques de haute disponibilité pour éviter de décevoir leurs clients et de perdre des revenus.
Une erreur à signaler ? Une suggestion à faire ? Contactez-nous à l’adresse ssg-blogs@splunk.com.
Cette publication ne représente pas nécessairement la position, les stratégies ou l’opinion de Splunk.
Vidéo : En savoir plus sur la disponibilité

Articles connexes
À propos de Splunk
La plateforme Splunk élimine les obstacles qui séparent les données de l'action, pour donner aux équipes d'observabilité, d'IT et de sécurité les moyens de préserver la sécurité, la résilience et le pouvoir d'innovation de leur organisation.
Fondée en 2003, Splunk est une entreprise internationale. Ses plus de 7 500 employés, les Splunkers, ont déjà obtenu plus de 1 020 brevets à ce jour, et ses solutions sont disponibles dans 21 régions du monde. Ouverte et extensible, la plateforme de données Splunk prend en charge les données de tous les environnements pour donner à toutes les équipes d'une entreprise une visibilité complète et contextualisée sur l'ensemble des interactions et des processus métier. Splunk, une base solide pour vos données.

Abonnez-vous à notre blog
Recevez les derniers articles de Splunk par e-mail.

