Corrélation des événements informatiques : logiciels, techniques et avantages

La corrélation des événements informatiques consiste à analyser les événements de l’infrastructure informatique et à identifier les relations qu’ils entretiennent pour détecter les problèmes et découvrir leur cause profonde. Un outil de corrélation d’événements peut aider les organisations à superviser plus efficacement leurs systèmes et leurs applications tout en améliorant leur disponibilité et leurs performances.
Splunk ITSI est un leader dans le domaine de l’AIOps
Splunk IT Service Intelligence (ITSI) est une solution d’AIOps, d’analytique et de gestion IT qui aide les équipes à anticiper les incidents avant qu’ils n’affectent les clients.

ITSI utilise l’IA et le machine learning pour corréler les données collectées auprès de nombreuses sources de supervision et offrir une vue unifiée des services IT et métiers pertinents. La solution a un double avantage : elle réduit les déluges d’alertes et permet la prévention des interruptions de service.
Définition des événements informatiques
Un événement est un élément de données qui fournit des informations sur un changement d’état survenu au sein de cette infrastructure (la connexion d’un utilisateur, par exemple). Bon nombre de ces événements sont normaux et bénins, mais certains traduisent un problème au sein de l’infrastructure.
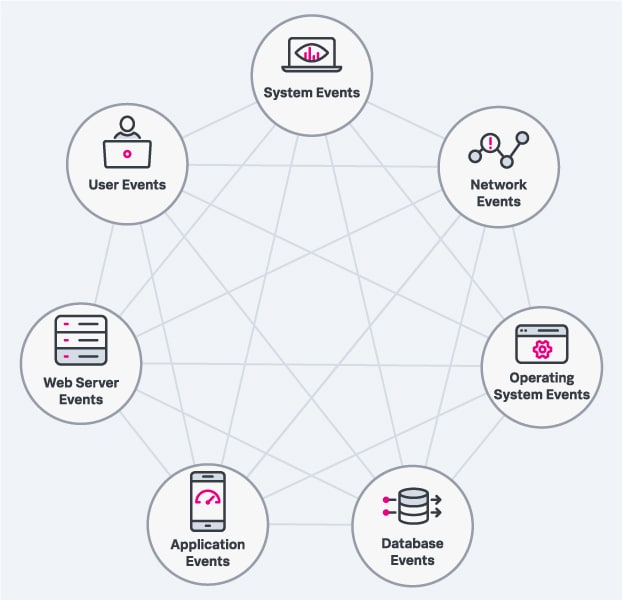
Voici quelques exemples courants d’événements suivis par une entreprise :
- Événements système : ces événements décrivent des changements anormaux dans les ressources ou l’intégrité du système. Par exemple, un disque plein ou une charge CPU élevée.
- Événements réseau : les événements réseau décrivent la santé et les performances des switches, routeurs, ports et autres composants du réseau, et signalent si le trafic réseau dépasse les seuils définis.
- Événements du système d’exploitation : ces événements sont générés par les systèmes d’exploitation (Windows, Linux, Android, iOS, etc.) et décrivent les modifications de l’interface entre le matériel et le logiciel.
- Événements de base de données : ces événements aident les analystes et les administrateurs à comprendre les opérations de lecture, de stockage et de mise à jour des données dans une base de données.
- Événements d’application : générés par les applications logicielles, ces événements peuvent apporter un aperçu des performances des applications.
- Événements de serveur web : ces événements décrivent l’activité du matériel et des logiciels qui fournissent le contenu d’une page web, ce qui peut recouper l’analytique web traditionnelle.
- Événements utilisateur : ils rendent compte des performances de l’infrastructure du point de vue de l’utilisateur et sont générés par des systèmes de supervision synthétique ou de supervision des utilisateurs réels.
Les outils de corrélation d’événements informatiques permettent d’interpréter différents types d’événements afin de déclencher une réponse ou une action.
Les infrastructures IT d’entreprise génèrent d’énormes volumes de données (et d’événements) dans divers formats. Ces données sont produites par des serveurs, des bases de données, des machines virtuelles, des appareils mobiles, des systèmes d’exploitation, des applications, des capteurs et bien d’autres composants réseau. Parce qu’une entreprise typique traite des milliers d’événements chaque jour, les corréler pour en extraire des informations pertinentes représente un défi important pour les équipes informatiques.
Dans les sections suivantes, nous allons nous pencher sur le fonctionnement de la corrélation d’événements, les avantages qu’elle offre à la plupart des organisations, les défis auxquels elle répond et la façon dont vous pouvez l’utiliser pour mieux comprendre les données de votre infrastructure.
Comment fonctionne la corrélation des événements informatiques ?
Pour interpréter tous ces événements, les équipes peuvent recourir à un logiciel de corrélation des événements informatiques.
Les logiciels de cette catégorie ingèrent les données d’infrastructure et utilisent le machine learning pour reconnaître des modèles pertinents et des relations. Grâce à ces techniques, les équipes vont :
- identifier et résoudre plus facilement les incidents et les défaillances,
- assurer la supervision des performances des systèmes ,
- améliorer la disponibilité et la stabilité de l’infrastructure.
Aujourd’hui, la corrélation des événements informatiques repose principalement sur l’automatisation et des outils logiciels appelés corrélateurs d’événements. Ceux-ci reçoivent un flux de données de supervision et de gestion des événements ; produit automatiquement à partir de l’environnement supervisé.
À l’aide d’algorithmes d’intelligence artificielle, le corrélateur analyse les alertes pour corréler les événements et former des groupes, puis les comparer aux données relatives aux modifications du système et à la topologie du réseau pour identifier la cause des problèmes et la meilleure piste de solutions. Il est donc impératif de maintenir une qualité de données élevée et de définir des règles de corrélation définitives, en particulier lors de la prise en charge de tâches connexes telles que la cartographie des dépendances, la cartographie des services et la suppression des événements.
Processus de corrélation des événements
L’ensemble du processus de corrélation d’événements se déroule généralement en plusieurs étapes, comme suit :
- Agrégation : les données de supervision de l’infrastructure sont collectées à partir de divers appareils, applications, outils de supervision et systèmes de ticket d’incident, puis transmises au corrélateur.
- Filtrage : les événements sont filtrés selon des critères définis par l’utilisateur : source, période ou niveau de l’événement. Cette étape peut aussi être réalisée avant l’agrégation.
- Déduplication : l’outil identifie les événements redondants déclenchés par le même problème. La duplication peut avoir de nombreuses raisons (par exemple, 100 personnes reçoivent le même message d’erreur, ce qui génère 100 alertes distinctes). Souvent, malgré la multiplicité des alertes, il n’y a qu’un seul problème à résoudre.
- Normalisation : la normalisation convertit les données dans un format uniforme pour que l’algorithme d’intelligence artificielle de l’outil de corrélation d’événements les interprète de la même manière, quelle que soit la source.
- Analyse de la cause profonde : c’est l’étape la plus complexe du processus. Les interdépendances des événements sont analysées pour déterminer la cause profonde de l’événement. Pour prendre un exemple, les événements d’un appareil sont examinés pour déterminer son impact sur chaque appareil du réseau.
Une fois le processus de corrélation terminé, le volume initial d’événements aura été réduit à une poignée d’événements à traiter. À ce stade, certains outils de corrélation d’événements déclenchent une réponse : recommandation d’investigation plus approfondie, escalade ou correction automatisée. Tout cela permet aux administrateurs informatiques d’aborder les tâches de dépannage mieux armés.
Comment identifier les modèles dans les événements informatiques
Après une interrogation initiale des données d’événement, un analyste peut utiliser l’outil pour regrouper les résultats en modèles. Parce qu’elle met au jour les types d’événements les plus courants, l’analyse des modèles d’événements est particulièrement utile lorsqu’une recherche renvoie une grande diversité d’événements.
Les outils de corrélation d’événements incluent généralement la détection des anomalies et d’autres fonctions d’identification de modèle dans leur interface utilisateur. Le lancement d’une fonction de modèles pour la détection d’anomalies, par exemple, va déclencher une recherche secondaire sur un sous-ensemble des résultats de recherche actuels, afin de les analyser pour y identifier des modèles communs.
Pour des questions d’exactitude, les modèles s’appuient sur de vastes groupes d’événements classés par ordre de prévalence décroissante. L’outil de corrélation d’événements vous permet d’enregistrer une recherche de modèle en tant que type d’événement et de créer une alerte qui se déclenchera en cas d’anomalie ou d’aberration dans le modèle.
Techniques courantes de corrélation des événements
La corrélation d’événements utilise diverses techniques pour identifier les relations entre les données des événements et découvrir la cause d’un problème. Plutôt que de recourir à de lourds processus manuels, un logiciel de corrélation des événements utilise des algorithmes de machine learning qui excellent à identifier des modèles et l’origine des problèmes dans des volumes considérables de données.
Voici quelques techniques courantes de corrélation d’événements :
Corrélation basée sur la chronologie
Cette technique examine ce qui s’est passé immédiatement avant ou pendant un événement pour identifier des relations dans la chronologie des événements. L’utilisateur définit une plage de temps ou une condition de latence pour la corrélation.
Corrélation basée sur des règles
La corrélation basée sur des règles compare les événements à des variables spécifiques telles que l’horodatage, le type de transaction ou l’emplacement du client. Il faut rédiger de nouvelles règles pour chaque variable, ce qui rend cette approche peu pratique pour de nombreuses organisations.
Corrélation basée sur des modèles
Cette approche combine chronologie et règles pour identifier, au sein des événements, des relations qui correspondent à un modèle défini. La corrélation basée sur des modèles est plus efficace que l’approche basée sur des règles, mais elle nécessite un outil de corrélation d’événements intégrant le machine learning.
Corrélation basée sur la topologie
Cette technique associe les événements à la topologie des périphériques réseau ou des applications concernés, pour permettre aux utilisateurs de visualiser plus facilement les incidents dans le contexte de leur environnement informatique.
Corrélation basée sur le domaine
Cette approche importe les données de supervision de différents domaines des opérations IT (performances du réseau, applications web, etc.) et corrèle les événements. Un outil de corrélation d’événements peut également collecter des données de tous les domaines et effectuer une corrélation inter-domaines.
Corrélation basée sur l’historique
Cette technique vous permet de tirer des informations des événements historiques en comparant les nouveaux événements aux événements passés. L’approche basée sur l’historique est similaire à la corrélation basée sur les modèles, mais elle ne peut rapprocher que des événements identiques, tandis que la corrélation basée sur des modèles ne souffre pas de ces limitations.
Avantages de la corrélation des événements informatiques
La corrélation des événements informatiques présente de nombreux avantages dans de multiples scénarios d’utilisation :
Cybersécurité, visibilité et détection en temps réel des logiciels malveillants
Les équipes informatiques peuvent corréler les journaux de supervision des logiciels antivirus, des pare-feux et d’autres outils de gestion de la sécurité pour obtenir de la threat intelligence exploitables. Cela leur permet d’identifier les failles de sécurité et de détecter les menaces en temps réel.
Un logiciel de corrélation des événements informatiques peut également s’intégrer à la gestion des événements et des informations de sécurité (SIEM) en important les logs, puis en les corrélant et en les normalisant pour faciliter l’identification des problèmes de sécurité dans votre environnement. Le processus repose sur un logiciel SIEM et un moteur de corrélation d’événements distinct.
À son niveau le plus élémentaire, un SIEM collecte et agrège les données de logs générées dans l’ensemble de l’infrastructure informatique d’une organisation. Ces données proviennent des périphériques réseau, des serveurs, des applications, des contrôleurs de domaine et autres sources, et elles se présentent dans divers formats. Du fait de cette diversité, il existe peu de moyens de corréler les données pour y détecter des tendances ou des modèles. Il est donc d’autant plus difficile de déterminer si un événement inhabituel est le signe d’une menace pour la sécurité ou une simple anomalie passagère.
Les logiciels de corrélation des événements peuvent systématiser et simplifier ce processus pour maximiser l’efficacité de votre SIEM.
Réduction des coûts d’exploitation de l’IT
La corrélation des événements automatise des processus de gestion réseau qui sont indispensables, mais prennent un temps considérable. Résultat : les équipes passent moins de temps à interpréter les alertes récurrentes et davantage à résoudre les menaces et les problèmes.
Efficacité accrue
La corrélation manuelle des événements demande énormément de temps, d’efforts et d’expertise – et cela ne fait qu’empirer à mesure que l’infrastructure se développe. À l’inverse, les outils automatisés augmentent l’efficacité de votre équipe et savent évoluer pour s’aligner sur vos SLA et votre infrastructure.
Mise en conformité simplifiée
La corrélation des événements facilite la supervision continue de toutes les infrastructures informatiques et vous permet de générer des rapports détaillant les menaces de sécurité et les mesures de conformité réglementaire.
Réduction du bruit
Parmi les milliers d’événements réseau qui se produisent chaque jour, certains sont plus graves que d’autres. Un logiciel de corrélation d’événements passe rapidement au crible les torrents d’incidents et d’événements pour identifier les plus critiques et en faire une priorité absolue.
La corrélation des événements informatiques aide essentiellement les entreprises à garantir la fiabilité de leur infrastructure informatique. La capacité d’une entreprise à servir ses clients et à générer des revenus peut être compromise par des problèmes de toute nature. Selon un rapport produit en 2022, plus de 60 % des interruptions provoquaient au moins 100 000 $ de pertes. La corrélation des événements permet d’atténuer ces coûts d’indisponibilité en contribuant à fiabiliser l’infrastructure.
Sécurité des réseaux
La corrélation d’événements peut contribuer à la sécurité du réseau en analysant un grand nombre de données d’événements et en identifiant les relations ou les modèles pouvant indiquer une menace de sécurité.
Un outil de corrélation d’événements peut cartographier et contextualiser les données qu’il importe depuis des sources d’infrastructure pour identifier les modèles suspects en temps réel. Certains outils de corrélation d’événements produiront également des rapports de corrélation pour des types d’attaques courants : compromissions de comptes d’utilisateurs, menaces visant les bases de données ou Windows et Linux, ransomwares, etc.
Choisir le bon outil de corrélation des événements
Pour commencer, il vous faut une solution de corrélation d’événements qui réponde spécifiquement aux besoins de votre organisation. Nous vous recommandons d’évaluer vos options à l’aune des critères suivants :
Expérience utilisateur
Comme pour tout nouveau logiciel, il est important de considérer à quel point il sera facile (ou difficile) à prendre en main et à utiliser. Un bon corrélateur d’événements aura une interface moderne avec une navigation intuitive et une console de gestion qui s’intègre à votre infrastructure IT. Ses analyses natives doivent être faciles à configurer et à interpréter, et elles doivent s’intégrer facilement aux meilleurs systèmes d’analyse tiers.
Caractéristiques et fonctionnalités
Il est essentiel de savoir quelles sources et quels formats de données un corrélateur de données peut traiter. Vous devez également savoir :
- quels types d’événements l’outil peut corréler (supervision, observabilité, changements, etc.),
- quelles étapes de traitement il applique (normalisation, suppression des doublons, analyse des causes profondes, etc.),
- s’il peut déclencher des actions appropriées en cas d’alerte, pour automatiser une procédure de remédiation, par exemple.
Machine learning et capacités de détection des anomalies
Vous n’avez pas besoin d’être un spécialiste des données pour utiliser un corrélateur d’événements, mais des notions de base en matière de machine learning éclaireront votre décision d’achat. Pour résumer, il existe deux types principaux de machine learning : supervisé et non supervisé.
Le machine learning supervisé exploite un ensemble de données structurées composé d’exemples dont les résultats sont connus et spécifiques, afin de guider l’algorithme. L’algorithme est informé des variables à analyser et reçoit des retours sur la précision de ses prédictions. Il est ainsi « entraîné », à l’aide de données existantes, à prédire le résultat de nouvelles données.
Le machine learning non supervisé, quant à lui, analyse les données sans aucune référence à des résultats connus. Cela lui permet d’identifier des modèles jusque-là inconnus dans des données non structurées et de les regrouper en fonction de leurs similitudes. Les formats de données générés par la machine varient considérablement, des données syslog structurées aux données d’application multilignes non structurées : il est donc indispensable qu’un corrélateur prenne en charge à la fois le machine learning supervisé et non supervisé.
Intégration au sein de la pile technologique
Au-delà de ces critères, vous devrez encore vous assurer que le corrélateur d’événements de votre choix peut s’intégrer à vos outils et partenaires actuels. Il doit aussi vous aider à répondre aux exigences de conformité de votre entreprise ou de votre secteur, et s’accompagner d’une bonne assistance client.
Une fois que vous avez commencé, optimisez vos processus en vous appuyant sur les bonnes pratiques de corrélation d’événements.
La corrélation des événements permet de comprendre votre infrastructure
Les indices des problèmes de performances et des menaces de sécurité se cachent au cœur de vos données d’événements. Mais quand les systèmes informatiques génèrent des téraoctets de données chaque jour, il devient pratiquement impossible de distinguer les événements à traiter de ceux qu’on peut ignorer. La corrélation des événements est la clé pour interpréter vos alertes et vous permettre de prendre des mesures correctives plus rapides et plus efficaces. Elle peut vous aider à mieux comprendre votre environnement IT, pour qu’il reste toujours au service de vos clients et de votre entreprise.
Une erreur à signaler ? Une suggestion à faire ? Contactez-nous à l’adresse ssg-blogs@splunk.com.
Cette publication ne représente pas nécessairement la position, les stratégies ou l’opinion de Splunk.

Articles connexes
À propos de Splunk
La plateforme Splunk élimine les obstacles qui séparent les données de l'action, pour donner aux équipes d'observabilité, d'IT et de sécurité les moyens de préserver la sécurité, la résilience et le pouvoir d'innovation de leur organisation.
Fondée en 2003, Splunk est une entreprise internationale. Ses plus de 7 500 employés, les Splunkers, ont déjà obtenu plus de 1 020 brevets à ce jour, et ses solutions sont disponibles dans 21 régions du monde. Ouverte et extensible, la plateforme de données Splunk prend en charge les données de tous les environnements pour donner à toutes les équipes d'une entreprise une visibilité complète et contextualisée sur l'ensemble des interactions et des processus métier. Splunk, une base solide pour vos données.

Abonnez-vous à notre blog
Recevez les derniers articles de Splunk par e-mail.

