
Créer une pratique d’observabilité de pointe
Regardons les choses en face : l’observabilité est LE sujet du moment. Il vous faut plus de budget pour moderniser vos outils ? Dites simplement le mot magique, « observabilité ». Le budget est approuvé, et vous avez un projet d’observabilité. Vous partez en quête d’une solution, et vous réalisez bien vite que tous les fournisseurs utilisent les mêmes formules et proposent les mêmes solutions : « nous collectons les métriques, les traces et les logs avec OpenTelemetry, et notre back-end réunit l’APM, la supervision de l’infrastructure, la supervision des utilisateurs réels, la supervision synthétique, etc. ». Vous avez déjà entendu ça quelque part ? Quelqu’un a dit « observability-washing » ?
Mais toutes les solutions ne se valent pas. Elles peuvent même être très différentes les unes des autres dès que vous soulevez le capot (de la conception architecturale). Elles présentent en effet des architectures très différentes et ne recueillent pas les données de la même façon. Je vais tenter d’expliquer ce qui différencie toutes ces solutions, en particulier pour les organisations qui utilisent des approches modernes comme les microservices et les conteneurs – en gardant en tête que cela vaut également pour les applications classiques à 3 niveaux en local.
Commençons par la conception architecturale. Dans un monde cloud-native, tout va très vite. Conteneurs et fonctions apparaissent, subissent une défaillance, redémarrent ou disparaissent à grande vitesse. Il vous faut donc une solution capable de tenir ce rythme inédit. Pourquoi ? Parce que c’est important pour vos utilisateurs. Selon une étude menée en 2016 par Google, vous pouviez perdre jusqu’à 53 % de vos clients si vos transactions prenaient plus de 3 secondes. Imaginez alors la situation en 2024 ! Non seulement la vitesse est indispensable pour éviter de perdre des revenus, mais elle peut également en créer. Une autre étude de Deloitte montre en effet que dans certains secteurs, et notamment celui de la vente au détail, une amélioration de 0,1 seconde des performances de votre application mobile peut se traduire par une augmentation de près de 9 % du montant moyen des commandes. Dernier point, et non des moindres, si votre site manque de réactivité (autrement dit, s’il n’est pas conforme aux critères Core Web Vitals de Google), vous pourriez dépenser des millions de dollars en SEO sans pour autant figurer en tête des résultats de Google.
Oui, chaque seconde – chaque milliseconde, même – compte. Il vous faut des solutions qui opèrent en quasi-temps réel. Vous devez garder en tête qu’au bout de 3 secondes, vous perdez des clients. Vous devez savoir s’il y a une fuite de mémoire au niveau du conteneur X avant que Kubernetes ne le relance et qu’il fonctionne à nouveau comme prévu.
« Est-ce vraiment aussi crucial ? Les fournisseurs avec lesquels j’ai discuté me disent qu’il ne leur faut que 15 secondes pour collecter les données de télémétrie, les métriques, etc. Ça devrait suffire, non ? » Non, ça ne suffit pas. Parce qu’ils ne vous parlent pas de ce qui se passe ensuite. Il n’est pas difficile de collecter des données en 15 secondes et de les stocker dans une base de données de séries chronologiques (TSDB). Mais ce n’est pas non plus très utile. À ce moment-là, vous n’avez que des données qui vous coûtent de l’argent et n’apportent aucune valeur ajoutée : pas d’alertes, de rapports, d’analyse... rien. En réalité, pour « exploiter » ces métriques et ces traces, la plupart des fournisseurs fonctionnent par lot : ils interrogent la base de données, ce qui prend beaucoup plus de temps (une minute ou plus dans la plupart des cas). Autrement dit, votre alerte n’apparaîtra pas sous 15 secondes, mais bien au bout de 75 secondes ! Pour résumer, cette approche « traditionnelle » par lot a plusieurs conséquences :
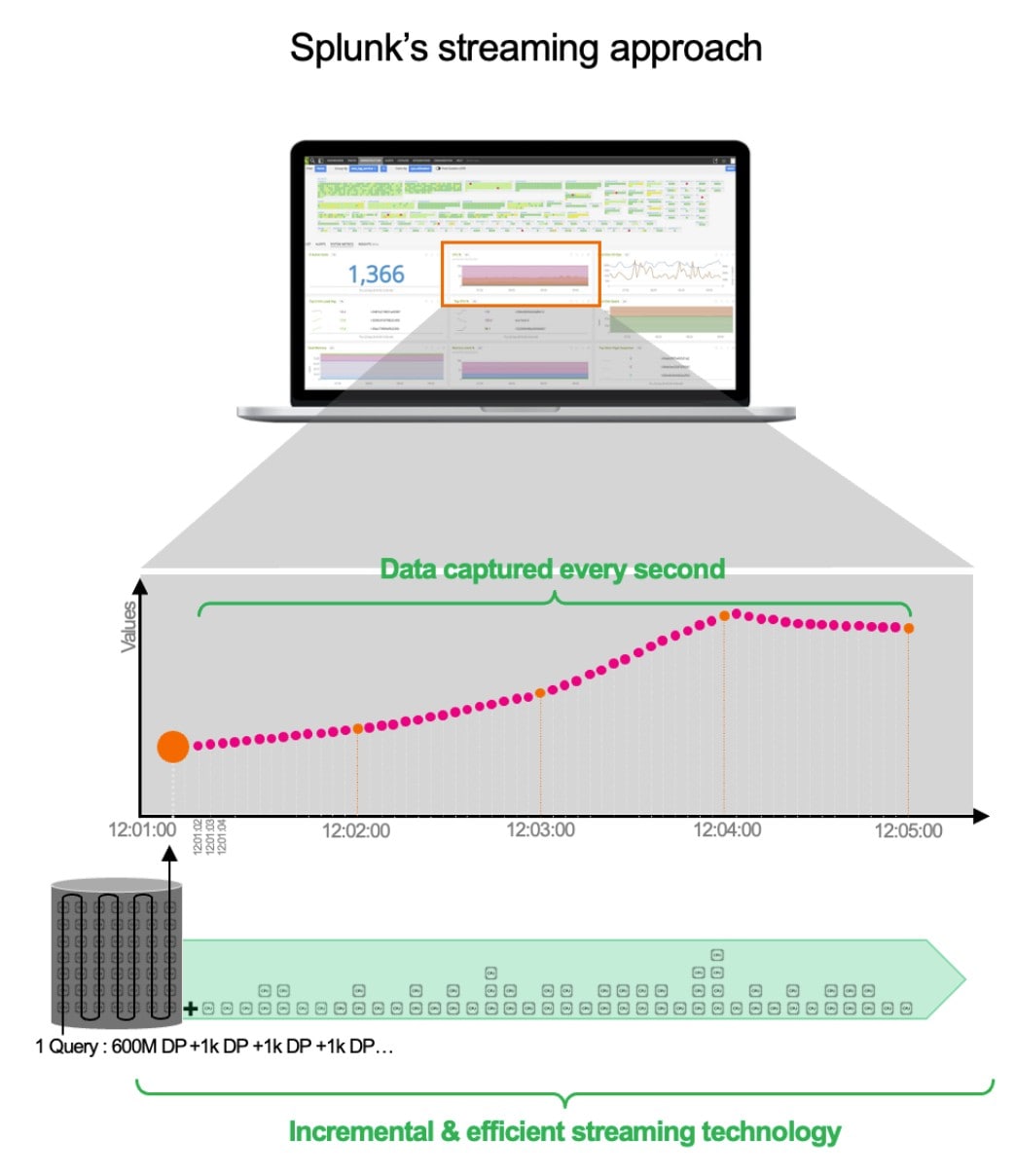
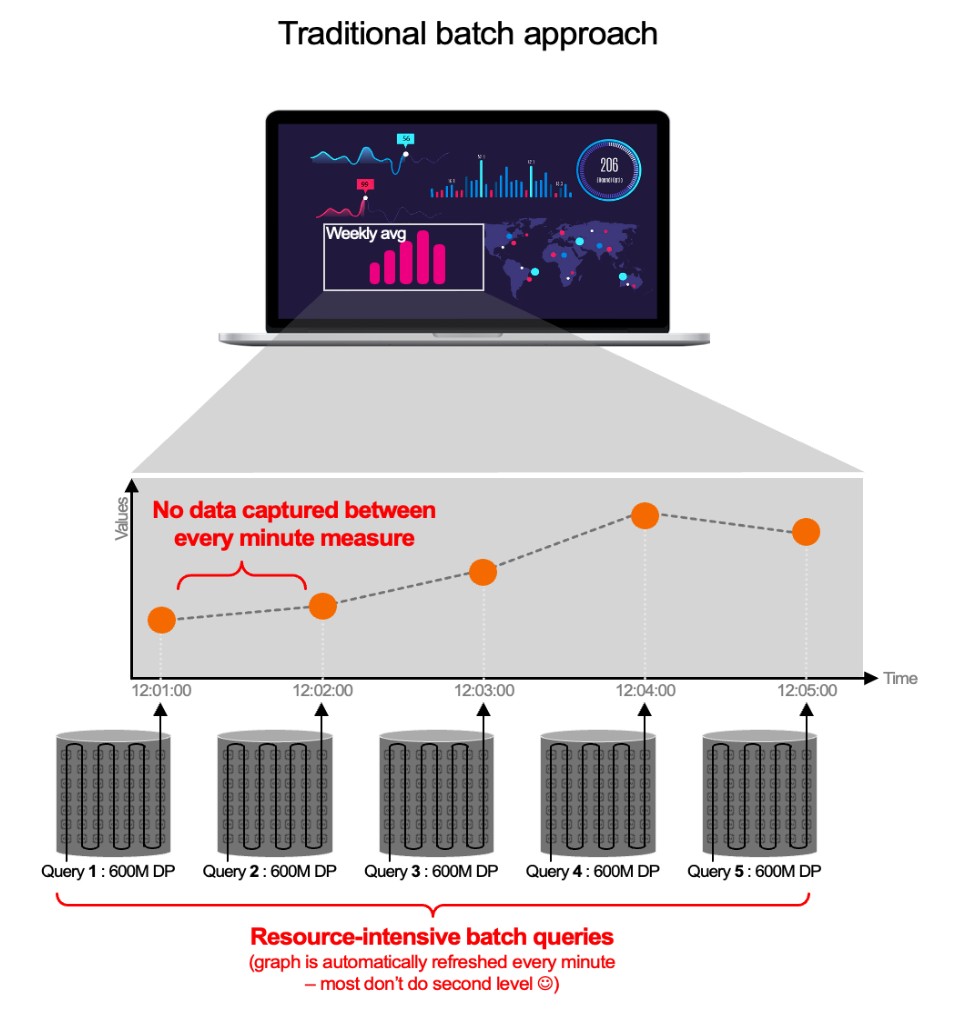 Prenons un exemple : « je veux une résolution de 1 seconde pour le CPU de mon cluster de 1 000 conteneurs, sur une semaine ». Il faut donc analyser 600 millions de points de données (604 800 secondes x 1 000) pour gérer un seul graphique (celui de la consommation de CPU).
Prenons un exemple : « je veux une résolution de 1 seconde pour le CPU de mon cluster de 1 000 conteneurs, sur une semaine ». Il faut donc analyser 600 millions de points de données (604 800 secondes x 1 000) pour gérer un seul graphique (celui de la consommation de CPU).
Avec une approche traditionnelle, la solution d’observabilité doit générer chaque minute une requête qui va collecter 600 millions de points de données. Et comme une tâche par lot est lancée chaque minute, cela veut dire que votre environnement échappe à toute observation pendant 59 secondes !
Et c’est le cas pour toutes les courbes (mémoire, IOPS, etc.) d’un tableau de bord, pour chaque utilisateur, etc. Cela fait un grand nombre de requêtes sur 600 millions de points de données, et c’est totalement incompatible avec les environnements modernes basés sur des conteneurs.
Chez Splunk, nous avons opté pour une architecture en streaming. Bien évidemment, lorsque le service démarre, il doit récupérer les 600 millions de points de données initiaux. Mais il ne va pas recréer une requête volumineuse une minute plus tard. Notre requête persiste. Mais nous la mettons à jour chaque seconde sur la base des nouvelles données (par incréments de 1 000 points de données). Cette approche n’est pas seulement plus efficace, rapide et évolutive. Elle garantit également la capture de toutes les anomalies, d’un client impatient à une fuite de mémoire dans une fonction. Mais ce n’est pas tout. La liste des avantages est encore longue. Vous voulez changer de vue ? Vous voulez connaître la moyenne du total ? Pas de problème. Certaines données ont déjà été précalculées en back-end pour encore plus d’efficacité.
Avec l’architecture en streaming de Splunk :
OpenTelemetry (OTel) devient la norme de facto pour la collecte des données de télémétrie. Cette méthode est à la fois légère et open source ; ce n’est pas une boîte opaque comme certains agents propriétaires. Vous pouvez donc utiliser un même agent pour recueillir des données d’observabilité (métriques, traces, logs) et les traiter (transformation, filtrage, anonymisation, etc.) avant de les envoyer à un back-end d’observabilité compatible avec OTel. Génial, non ? Vous utilisez un agent OTel et vous voulez changer de fournisseur en back-end ? Vous voulez changer d’outil APM ? Aucun problème. Envoyez les données à votre nouvelle solution, et c’est tout. C’est gratuit et cela vous permet d’économiser des ressources dans tout votre environnement.
Si vous voulez en savoir plus, rendez-vous sur https://opentelemetry.io/.
OTel est une étoile montante : tout le monde veut – et doit – prendre en charge OTel. Mais encore une fois, il y a prise en charge et prise en charge native. Sachez simplement que certaines solutions compatibles avec OTel vous imposent d’installer leur agent propriétaire pour profiter des fonctionnalités sophistiquées de leur back-end.
Chez Splunk, nous avons misé sur une prise en charge complètement native d’OpenTelemetry, qui ne repose pas sur notre agent Universal Forwarder (vous pouvez l’utiliser si vous l’avez déjà, mais ce n’est pas du tout une nécessité). Le fait est que Splunk est activement impliqué dans le projet (avec d’autres, dont Microsoft, Lightstep, AWS et Cisco, et même des organisations comme Shopify et Uber). Nous venons de publier notre outil zéro configuration pour Otel Collector, ce qui vous permet de rechercher automatiquement les services en cours d’exécution dans votre environnement et de décider s’ils doivent être instrumentés par l’agent OTel, sans aucune opération manuelle.
Conclusion : c’est vrai, tout le monde fait usage de l’observabilité. C’est juste que notre approche est différente ;)

La plateforme Splunk élimine les obstacles qui séparent les données de l'action, pour donner aux équipes d'observabilité, d'IT et de sécurité les moyens de préserver la sécurité, la résilience et le pouvoir d'innovation de leur organisation.
Fondée en 2003, Splunk est une entreprise internationale. Ses plus de 7 500 employés, les Splunkers, ont déjà obtenu plus de 1 020 brevets à ce jour, et ses solutions sont disponibles dans 21 régions du monde. Ouverte et extensible, la plateforme de données Splunk prend en charge les données de tous les environnements pour donner à toutes les équipes d'une entreprise une visibilité complète et contextualisée sur l'ensemble des interactions et des processus métier. Splunk, une base solide pour vos données.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2025 Splunk LLC Tous droits réservés.
© 2005 - 2025 Splunk LLC Tous droits réservés.

