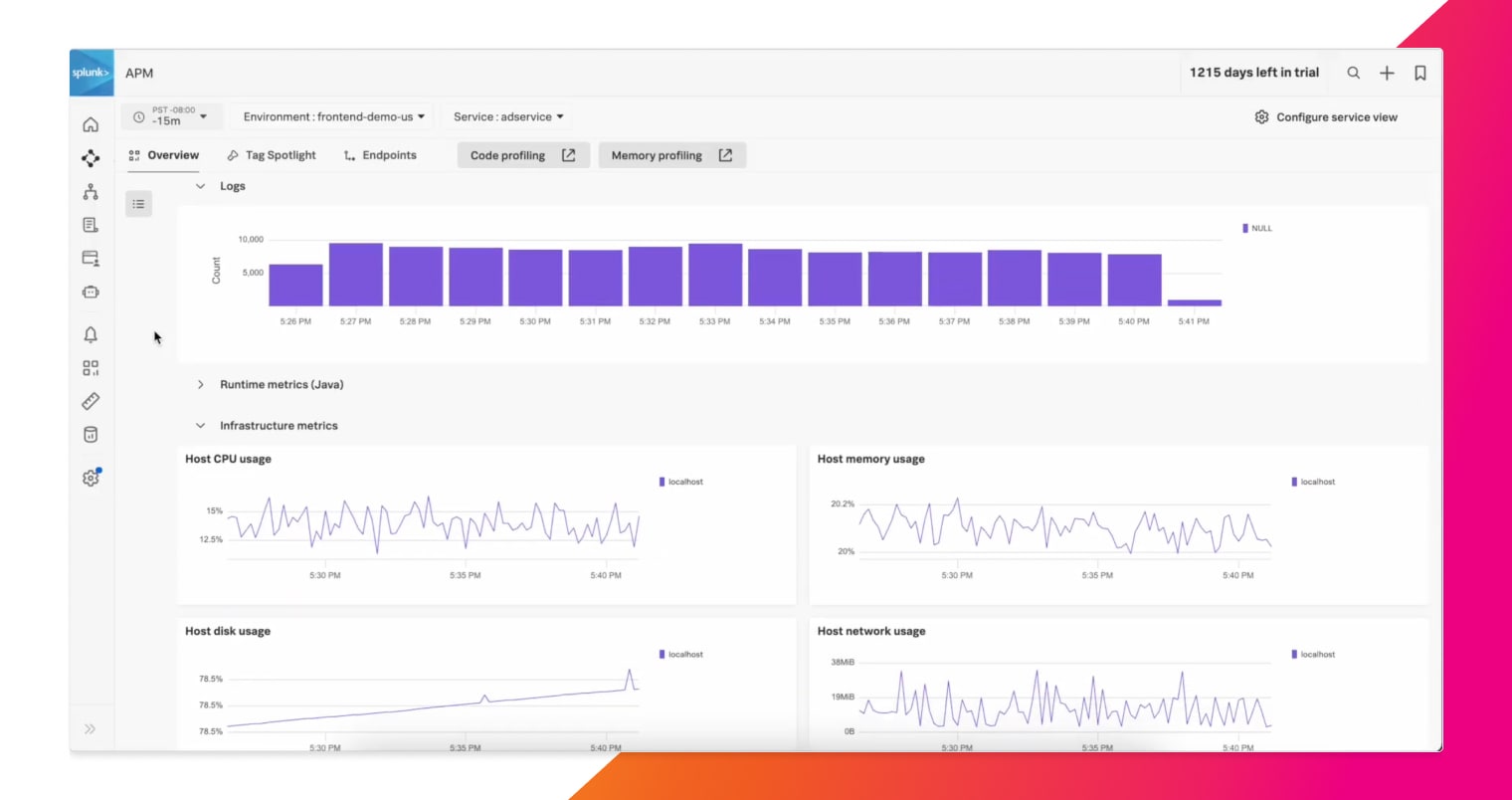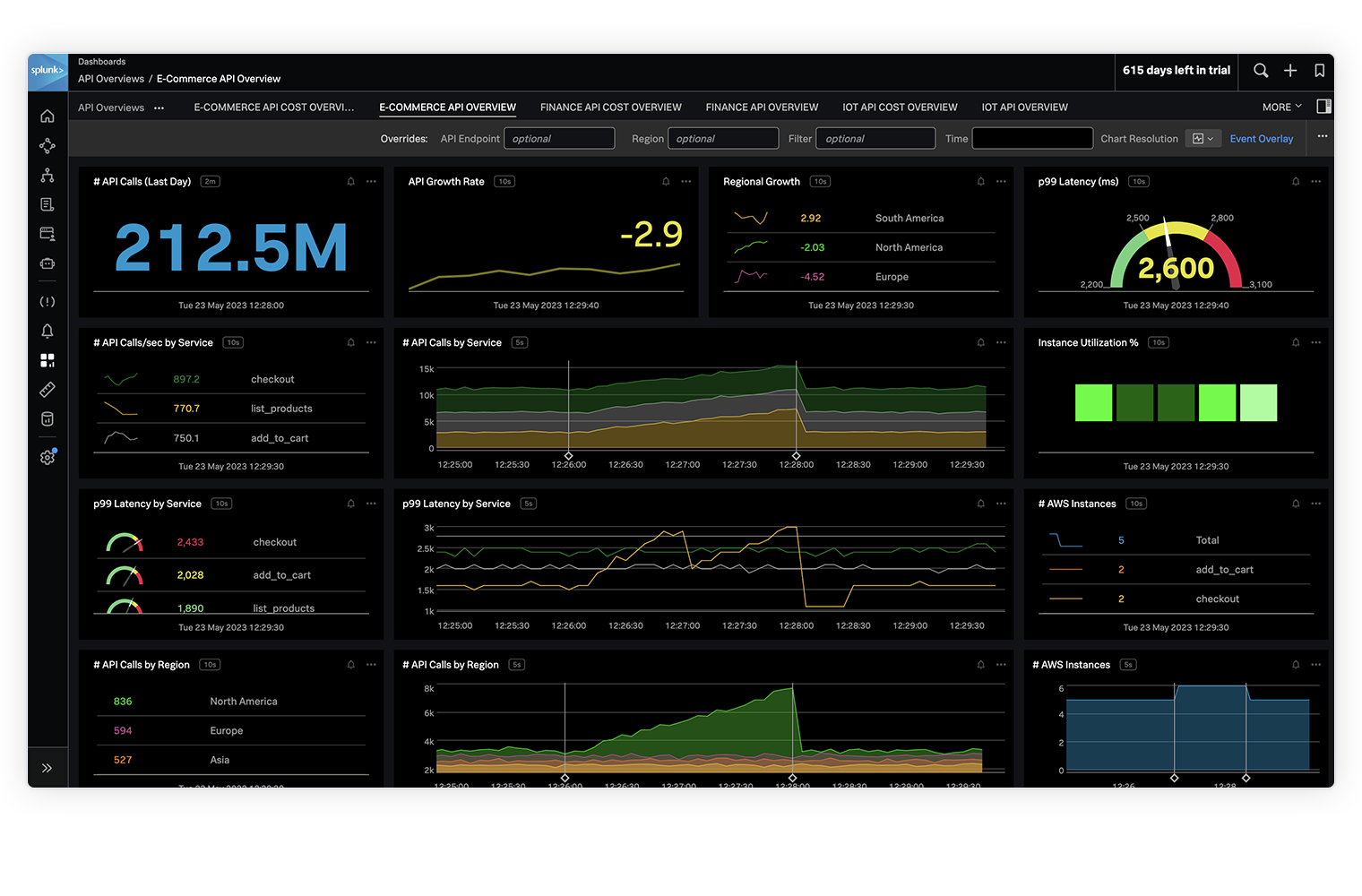
Wenn Sie Probleme, die durch Änderungen entstehen, sofort erkennen, die Fehler-Ursachen gezielt angehen und die Serviceleistung optimieren, können Sie Probleme schneller lösen – sowohl bei Monolithen als auch bei Microservices.
Lösung
Auf Traffic fokussieren, der für Sie wichtig ist
Alerts nach Business-Priorität
Flexible, benutzerdefinierte Metriken, die über Infrastrukturdaten und elementare KPIs weit hinausgehen, zeigen Ihnen genau, was vorgeht.
Probleme auf Anhieb einordnen
Der rote Punkt auf der Service Map macht sofort deutlich, welches Team für das Problem das richtige ist und den Fall weitergeleitet bekommen soll.
Fehlerbehebung mit gemeinsamem Kontext
Wenn Sie alle relevanten Daten sofort zur Hand haben, schaffen Sie Troubleshooting mit Rekordzeiten.
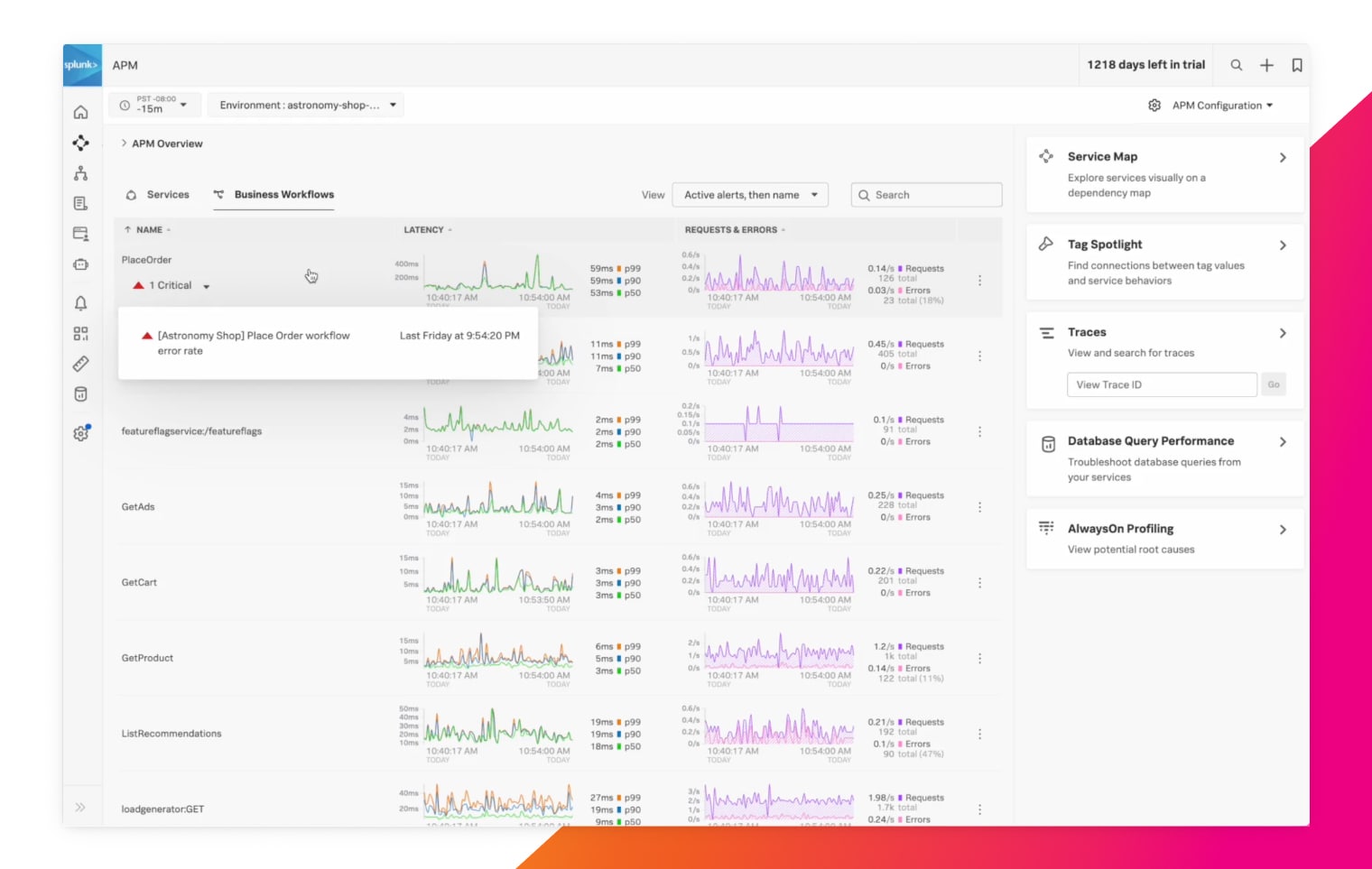
Nach Traffic filtern, der für Sie wichtig ist
Mit Business Workflows fassen Sie beliebige Microservice-Kombinationen zusammen, die zu wichtigen Geschäftsworkflows gehören (z. B. Kasse oder Login). Dann genügt ein Mausklick, und Sie sehen, ob und wie diese Funktionen je nach User-Segment arbeiten.
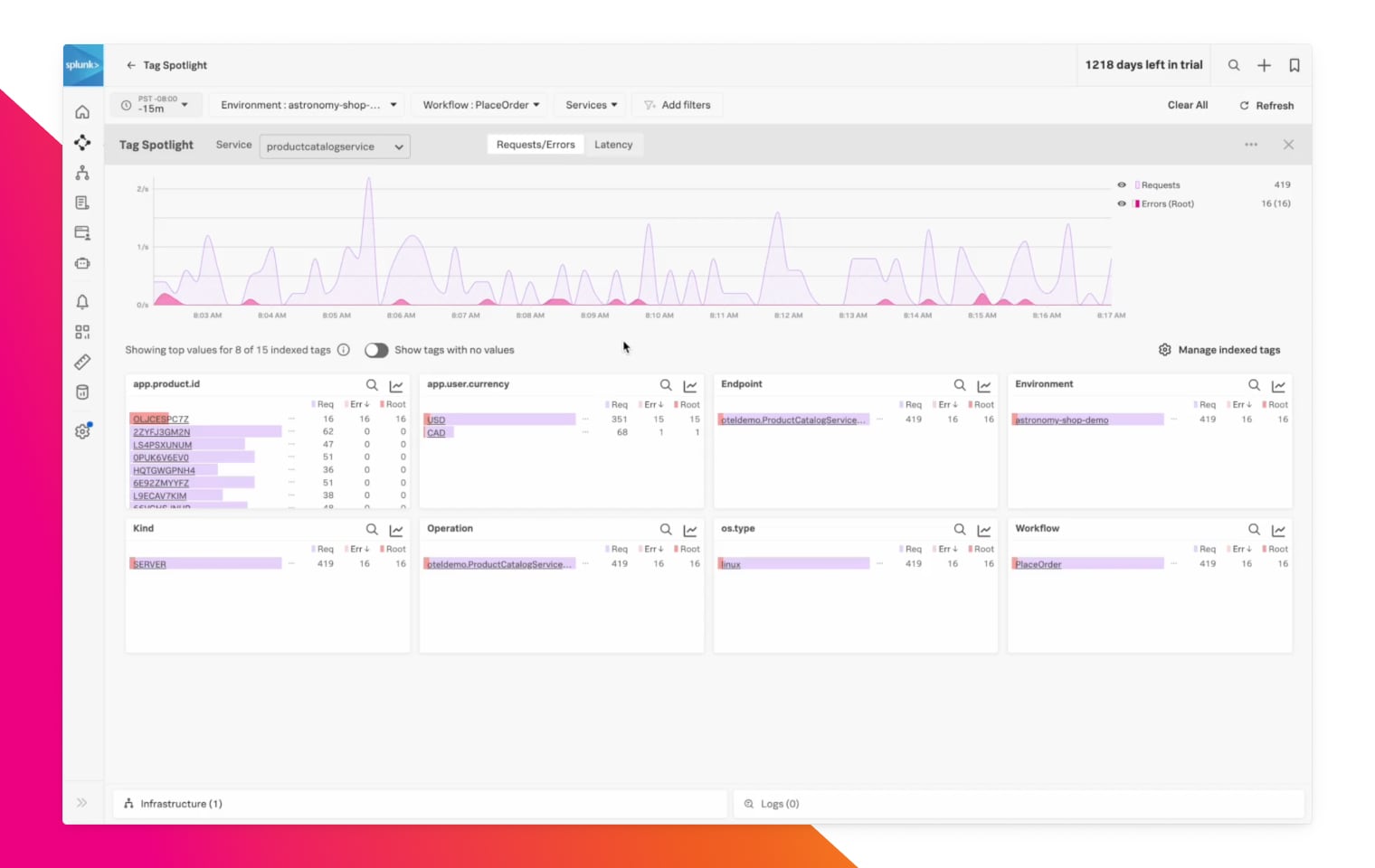
Die Services isolieren, in denen der Fehler steckt
Mithilfe von Service Map und Tag Spotlight zoomen Sie auf die Performance entscheidender Workflows, die den Traffic wichtiger User-Segmente betreffen. Wenn dann eine Änderung greift, zeigt Ihnen die Farbcodierung, welcher Service zu Problemen geführt hat.
Schnelles Troubleshooting mit gemeinsamem Kontext
Bei Infrastrukturmonitoring und der Logs-im-Kontext-Funktion führt Splunk alle Traces, Infrastrukturmetriken mit sämtlichen Logs zusammen, die für das zu untersuchende Problem relevant sind. Daten, die nicht relevant sind, werden ausgefiltert.
Splunk erfasst sämtliche Logs, Metriken und Traces auf eine Weise, durch die wir jegliches Event innerhalb unserer gesamten Plattform verstehen und damit wirklich auf jede Frage eine Antwort erhalten.