Was ist Distributed Tracing?

In einem Umfeld, in dem IT-Systeme ebenso verteilt sind wie Anwendungen, Software und Mitarbeitende, braucht es Klarheit darüber, was in diesem Geflecht separater Interaktionen vor sich geht. Genau das macht dezentrales Tracing möglich.
Dezentrales Tracing ist ein Verfahren zur Erfassung der Anforderung in Anwendungen und dazu, welchen Weg diese Anforderung von Benutzern und Frontend-Geräten bis zu Backend-Services und -Datenbanken nehmen.
Anforderungen und Transaktionen lassen sich damit aus jeder beliebigen Anwendung erfassen, die durch Monitoring abgedeckt ist. Dies liefert wichtige Informationen, die zur Verbesserung der Verfügbarkeit, zur Problem- und Incident-Behebung, zur fortlaufenden Optimierung und damit letztlich auch zu einem herausragenden Benutzer- und Kundenerlebnis beitragen.
In diesem Artikel schauen wir uns das dezentrale Tracing sowie die Technologien, die seine Umsetzung in eurem Unternehmen möglich machen, genauer an.
Metriken, Logdaten und Traces: die Säulen der Observability
Das Management moderner Softwareumgebungen steht und fällt mit den drei „Säulen der Observability“. Mitunter werden Metriken, Logdaten und Traces mit Events sogar noch um eine weitere Säule ergänzt (MELT-Framework). Jede Säule stellt eine Datenquelle dar, die enorm wichtige Einblicke in Anwendungen und die Infrastruktur liefert, auf der sie gehostet wird. Diese Methode wird häufig als Application Performance Monitoring (APM) bezeichnet, einem Gebiet des IT-Monitorings.
Vielen ITOps- und SRE-Teams (Site Reliability Engineering) dürften die beiden Säulen Logdaten und Metriken wohlbekannt sein, ist ihre Analyse doch schon seit Jahrzehnten gängige Praxis, um Folgendes zu erreichen:
- Bestimmung von Baselines für normales Anwendungsverhalten
- Erkennung von Anomalien als Anzeichen für potenzielle Probleme
- tiefergreifende Untersuchung im Bedarfsfall
Dagegen sind Traces und mit ihnen die dritte Säule womöglich manchen weniger ein Begriff.
Was ist eine Trace und worin liegt ihre Bedeutung?
Tracing ist per se kein neues Konzept. Eine Trace bezeichnet eine Sammlung von Transaktionen, auch Spans genannt, die eine eindeutige User- oder API-Transaktion repräsentieren und von einer Anwendung und den ihr zugehörigen Services verarbeitet werden.
Tracing beginnt ab dem Moment, an dem ein Benutzer mit einer Anwendung interagiert. Sendet ein Benutzer eine Anforderung ab, etwa das Hinzufügen eines Artikels zum Warenkorb, wird dieser eine eindeutige Trace-ID zugewiesen. Diese Trace repräsentiert also eine einzelne User-Interaktion. Auf dem Weg der Anforderung durch das Host-System wird jede darauf ausgeführte Operation (oder Span) mit einigen Kennzeichnungen versehen.
Die Trace setzt sich aus einer Sammlung von Spans zusammen. Diese stellen wiederum jeweils eine einzelne Operation dar, die Folgendes umfasst:
- den Zeitpunkt, an dem sie beginnt und endet
- eine Trace-ID zur Korrelation mit der jeweiligen Benutzertransaktion
- eine ID oder ein Tag zur Ergänzung zusätzlicher Informationen zur Anforderung, wie etwa die jeweilige Version des Microservices, von dem der Span generiert wurde
Jeder Span stellt ein Segment des Pfads der Anforderung dar. Dementsprechend umfasst jeder Span wichtige Informationen im Zusammenhang mit dem Service, der die Operation ausgeführt hat. Dazu gehören:
- Name und Adresse des Prozesses, der die Anforderung verarbeitet
- Logs und Events, die Kontext über die Prozessaktivität bereitstellen
- Tags für die Abfrage und Filterung von Anforderungen nach Session-ID, Datenbank-Host, HTTP-Methode und anderen Bezeichnern
- Detaillierte Stack Traces und Fehlermeldungen bei Ausfällen
Entwicklungs- und Management-Teams mit Fokus auf monolithischen Anwendungen nutzen Traces schon seit Langem, um Aufschluss über verschiedene Faktoren der App-Performance zu erhalten:
- wie Anwendungen Anforderungen verarbeiten
- wie sich Performance-Probleme auf bestimmte Zeilen im Quellcode der Anwendung zurückverfolgen lassen
Beim Tracing geht es letztlich immer darum, Klarheit über Transaktionen zu erhalten. Was sich jedoch verändert, ist die Art seiner Umsetzung. Denn Tracing funktioniert nicht bei Anwendungen, die auf dezentralen Softwarearchitekturen aufbauen, wie beispielsweise Microservices.
Klassisches Tracing vs. dezentrales Tracing
Nachfolgend zunächst ein Blick auf klassisches Tracing, seine Funktionsweise und warum es in der heutigen Zeit wenig zielführend ist.
Klassisches Tracing
In den Anwendungen früherer Zeiten, die als Monolithen ausgeführt wurden, war Tracing zwar möglich, es war aber weniger wichtig, die zugrunde liegenden Vorgänge nachzuvollziehen, da eine Anforderung während ihrer Verarbeitung durch die Anwendung weniger bewegliche Elemente durchlaufen musste. Es gab also schlicht weniger Traces, die man hätte erfassen können.
Die damaligen Tracing-Tools basierten auf probabilistischen Stichprobenverfahren. Dadurch wurde jedoch nur ein kleiner, willkürlich ausgewählter Teil der Gesamtmenge aller Transaktionen erfasst. Probabilistische Stichproben liefern einen gewissen Einblick in das Geschehen. Da es aber eben nur Momentaufnahmen vereinzelter Transaktionen sind, decken sie nicht die Gesamtheit ab und können somit auch kein Gesamtbild liefern. So könnten IT- und SRE-Teams durch Tracing mittels Stichprobenverfahren auch allerhöchstens folgende Erkenntnisse gewinnen:
- allgemeine Trends zu den gängigsten Benutzeranforderungen
- signifikante Performance-Schwankungen wie vollständige Serviceausfälle, durch die sämtliche Transaktionsstichproben in Fehlern resultieren
Aufschluss über detaillierte Performance-Trends könnte dieser Ansatz jedoch nicht liefern. Ebenso wenig ist er skalierbar genug, um die Tausenden dezentralen Services innerhalb von containerisierten Umgebungen zu quantifizieren, die hochdynamischen Veränderungen unterliegen:
- Ein geringfügiger Performance-Abfall könnte unbemerkt bleiben, z. B. eine Erhöhung der durchschnittlichen Latenz von 1 Sekunde auf 1,2 Sekunden für Benutzer, die in einem bestimmten Bereich der Backend-Datenbank gehostet werden. Der Grund hierfür ist, dass das traditionelle APM-Tool womöglich nicht genügend Transaktionen erfasst, um diese Veränderung registrieren zu können.
- Unbemerkt bleiben könnten auch Fehler, die bei einigen Transaktionen aufgrund bestimmter benutzerseitiger Eingaben auftreten. Zurückzuführen wäre dies darauf, dass sie zu wenig häufig auftreten, als dass sie in den Stichprobendaten einen signifikanten Trend darstellen würden.
Es lässt sich also schnell erkennen, dass dieser Ansatz der kurzlebigen Beschaffenheit dezentraler Systeme nicht gewachsen ist, kann dieser Umstand doch weitere Warnmeldungen ohne direkten Zusammenhang nach sich ziehen und so die Behebung eines Problems erschweren. Ein Beispiel wäre, dass ein EC2-Node ausfällt und durch einen anderen ersetzt wird: Wenn sich dies nur auf eine Benutzeranforderung auswirkt, muss dann überhaupt benachrichtigt werden? Entsprechend würden derartige Probleme dem Team so lange verborgen bleiben, bis sie sich zu ernsthaften Störungen auswachsen.
In einer statischen, monolithischen Umgebung wäre das nicht weiter problematisch. Wahrscheinlicher ist aber, dass eure Umgebung deutlich komplexer ist und sich laufend verändert.
Modernes Tracing: Funktionsweise von Traces in Microservices
Mit einer einzelnen Benutzertransaktion gehen Interaktionen mit Dutzenden oder auch Hunderten von Microservices einher, von denen jeder Daten aus Backend-Datenspeichern anfordert, die wiederum miteinander über APIs oder mit anderen Teilen der Infrastruktur interagieren. Oder einfach ausgedrückt: Eine Software steuert eine andere an.
Microservices sind so angelegt, dass sie voneinander unabhängig skalieren. So ist es auch nichts Ungewöhnliches, dass mehrere Instanzen eines einzelnen Services auf mehreren Servern, an unterschiedlichen Standorten und in verschiedenen Umgebungen gleichzeitig ausgeführt werden. Dabei kann sich jeder Microservice zudem auf Stacks mit mehreren Ebenen verteilen, die sich aus folgenden Komponenten zusammensetzen:
- Server
- Anwendungscode
- Container
- Orchestratoren
- Und mehr
Klassisches Monitoring, bei dem nur Stichproben oder ein einzelnes Codeelement betrachtet wird, reicht hier schlicht nicht aus. Um die Anforderungen innerhalb eines Verbunds aus Microservices nachvollziehen zu können, gilt es, zusätzliche Daten zu erfassen. Darunter etwa:
- die spezifische Services-Instanz oder -Version, die die Anforderung verarbeitet
- wo diese innerhalb der verteilten Umgebung gehostet wird
Da sich die Traces auf verschiedene Services verteilen, spricht man bei der Kennzeichnung von Spans und deren Korrelation von dezentralem Tracing.
Funktionsweise von dezentralem Tracing
Am besten stellt man sich hierzu ein Online-Videospiel mit Millionen von Spielern vor: Das Spiel muss den Standort jedes Endbenutzers erfassen, dazu jede Interaktion zwischen den Spielern, jeden Gegenstand, den sie im Spiel aufnehmen, sowie eine Vielzahl anderer Daten, die im Spielverlauf generiert werden. Mit herkömmlichen Tracing-Methoden wäre eine flüssige Ausführung des Spiels undenkbar – gewährleisten lässt sich dies erst durch dezentrales Tracing.
Dezentrales Tracing erfasst, wie eine Anforderung (bzw. Transaktion) verschiedene Services innerhalb einer Microservice-Architektur durchläuft. So wird der Ursprung (also die benutzerzentrierte Frontend-Anwendung) einer Anforderung auf ihrem Weg zu anderen Services nachvollziehbar.
Veranschaulichen lässt sich dezentrales Tracing am Beispiel eines Verbunds von Microservices in einer modernen Anwendung:
- Eine kleine Gruppe aus Microservices rendert die Benutzeroberfläche.
- Benutzerdaten werden in einer Datenbank erfasst, die auf einem anderen Service läuft.
- Eine kleine Anzahl von Backend-Services übernimmt die Datenverarbeitung.
In dieser Umgebung würde eine dezentrale Trace der Benutzeranforderung zuerst Informationen zum Anforderungsstatus am ersten Frontend-Service erfassen – also die Daten, die benutzerseitig eingegeben wurden, und wie lange der Service benötigt, um diese Daten an andere Services weiterzuleiten.
Der nächste Berührungspunkt in der Trace würde die Backend-Services betreffen, die die Eingaben akzeptieren und die erforderliche Datenverarbeitung durchführen, z. B. ETL oder inzwischen immer häufiger auch ELT. Im Anschluss daran übertragen die Backend-Services die verarbeiteten Daten an den Datenbank-Service, wo sie gespeichert werden.
Beispiel für dezentrales Tracing
Nehmen wir eine einfache Client-Server-Anwendung:
- Der Client sendet eine Anforderung an den Server für einen bestimmten Kunden.
- Der Server verarbeitet die Anforderung und sendet die Antwort an den Client zurück.
Aus Sicht des Clients ist eine einzige Aktion aufgetreten. Der Client hat eine Anforderung gesendet und eine Antwort erhalten. Wir erfassen jedoch sämtliche Server-Anforderungen, die als Ergebnis dieser Client-Anforderung generiert werden, in einem Span. Der Client führt im Kontext der Anwendung verschiedene Transaktionen mit dem Server aus, daher werden mehr Spans generiert. Diese können wir innerhalb eines Trace-Kontextes miteinander korrelieren.
Der Trace-Kontext ist gewissermaßen der Kitt, der die Spans zusammenhält, wie sich an dieser Aufschlüsselung erkennen lässt:
- Client sendet Anforderung zum Namen eines Kunden an Server zum Zeitpunkt X (Trace-Kontext: customerrequest1, SpanID: 1, timestamp: X)
- Server erhält Anforderung zum Namen eines Kunden von Client zum Zeitpunkt Y (Trace-Kontext: customerrequest1, SpanID: 1, timestamp: X)
- Server parst Anforderung zum Namen eines Kunden von Client zum Zeitpunkt Z (Trace-Kontext: customerrequest1, SpanID: 1, timestamp: X)
Zu beachten gilt, dass der Trace-Kontext derselbe bleibt. Auf diese Weise werden alle Spans miteinander verknüpft, und die Infrastruktur wird darüber informiert, dass jeder Span der gleichen Transaktion zugehörig ist.
Tools für dezentrales Tracing korrelieren zunächst die Daten aus allen Spans, um sie anschließend als Visualisierungen zu formatieren, die auf zwei Arten bereitgestellt werden können:
- auf Anforderung über eine Web-Schnittstelle
- automatisch über Warnmeldungen oder AIOps-Tools
Instrumentierung: Generieren von Traces
Um Traces erfassen zu können, müssen die Anwendungen zunächst instrumentiert werden. Zur Instrumentierung von Anwendungen bedarf es Frameworks wie OpenTelemetry, mittels derer sich Traces generieren und die App-Performance messen lässt. Diese Informationen sind äußerst nützlich, da sie die Ursache von Engstellen leicht erkennbar machen, statt lange nach ihnen suchen zu müssen.
Dabei gilt: Solange ihr ein anbieterunabhängiges Framework wie OpenTelemetry nutzt, müsst ihr dies zudem nur einmal vornehmen.
Erfassen und Exportieren von Traces
Im Anschluss an die Instrumentierung der Anwendung gilt es, Telemetriedaten mithilfe eines Collectors zu erfassen.
Hierfür ideal geeignet ist der Splunk OpenTelemetry Collector, mit dem sich die Erfassung und Verarbeitung von App-Telemetrie ebenso wie deren Export in ein Analysetool wie Splunk APM einheitlich lösen lässt. Dies wiederum macht Folgendes möglich:
- Ihr könnt Dashboards und Business-Workflows einrichten, um kritische Metriken auszumachen.
- Ereignisse wie eine Zunahme von Latenzzeiten oder Fehler lassen sich schnell mit Tag-Werten korrelieren. So erhaltet ihr eine zentrale Stelle, von der aus ihr das Verhalten von Traces über eure gesamte Anwendung hinweg nachvollziehen könnt.
- Trace-Daten könnt ihr in Sekundenschnelle ausleuchten und so direkt feststellen, welcher Microservice für Fehler innerhalb der dynamischen Service-Map verantwortlich ist.
Wollt ihr wissen, welcher Microservice letztlich die Fehler in der Anwendung verursacht hat? Mit Splunk erkennt ihr nicht nur, dass es paymentService war, ihr könnt sogar noch tiefer ins Detail gehen und feststellen, welche Version die Ursache war.
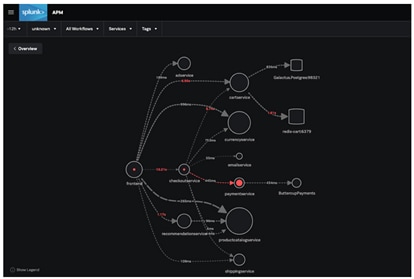
(Wie sich Anwendungen automatisch instrumentieren und die Trace-Daten mit Splunk APM analysieren lassen, zeigen wir hier am Beispiel einer einfachen Java-App.)
Ergebnisse und Vorteile von dezentralem Tracing
Der wichtigste Vorteil von dezentralem Tracing besteht darin, Benutzertransaktionen mit konkretem Kontext von einer zentralen Stelle aus durchleuchten zu können. Die Komplexität dahinter spielt so keine Rolle mehr. Ein ganzheitlicher Ansatz entsteht, der sich in vielerlei Hinsicht bemerkbar macht:
Punktgenaue Erkennung von Performance-Problemen
Da SRE- und IT-Teams den Anforderungsstatus einschließlich zugehöriger Performance-Faktoren für die einzelnen Services im Blick haben, können sie die Ursache von Leistungsproblemen präzise identifizieren. Hierzu können sie jedes nur erdenkliche Detail erfassen und so die Reaktionsfähigkeit jedes einzelnen Services ermitteln. Dadurch erhalten sie Klarheit über Probleme wie die Folgenden:
- hohe Latenz des Datenbank-Services
- Service, der Teile der Homepage rendert, fällt in 10 % der Fälle aus
Mehr Produktivität
Aufgrund der Fragmentierung von Microservice-Architekturen gestaltet sich das Monitoring der Anwendungsperformance rund um die Ermittlung und Behebung von Problemen zeitaufwändiger und kostenintensiver als bei monolithischen Anwendungen.
Zudem sind Daten zu Fehlern in Microservices nicht immer klar nachvollziehbar. So sind Entwicklungsteams häufig mit Fehlermeldungen und obskuren Statuscodes konfrontiert, aus denen es Probleme zu entschlüsseln gilt. Dezentrales Tracing liefert ihnen dagegen ein Gesamtbild verteilter Systeme mit folgenden Vorteilen:
- weniger Zeitaufwand für Diagnose und Debugging von fehlgeschlagenen Anforderungen und Latenzen
- effizientere Behebung von Problemen
All dies schlägt sich letztlich in einer verkürzten Mean Time to Recovery/Repair (MTTR) nieder.
Bessere teamübergreifende Zusammenarbeit
In Microservice-Umgebungen liegt jeder Prozess in der Regel in der Verantwortung eines bestimmten Teams. Dies kann es jedoch erschweren, Fehler auszumachen und zu bestimmen, wer für deren Behebung verantwortlich ist. Dezentrales Tracing hilft hier in vielerlei Hinsicht:
- Es wird ersichtlich, welches Team im Problemfall einschreiten muss.
- Reaktionszeiten werden verkürzt.
- Teams arbeiten effizienter zusammen.
Flexible Implementierung
Tools für dezentrales Tracing können mit vielen verschiedenen Anwendungen und Programmiersprachen verwendet werden, sodass Entwickler sie in praktisch jedes System einbinden und Daten in einer Tracing-Anwendung anzeigen können.
Arten von Tracing
Code-Tracing
Beim Code-Tracing interpretiert ein Programmierer die Ergebnisse jeder Codezeile einer Anwendung und zeichnet ihre Auswirkung per Hand auf (nicht mit einem Debugger, der den Prozess automatisiert), um die Programmausführung nachzuverfolgen.
Das manuelle Tracing kleiner Code-Blöcke kann effizienter sein, da der Programmierer nicht das gesamte Programm ausführen muss, um die Auswirkungen kleiner Änderungen zu prüfen.
Daten-Tracing
Daten-Tracing trägt dazu bei, die Genauigkeit und Datenqualität kritischer Datenelemente zu überprüfen, sie zu ihren Quellsystemen zurückzuverfolgen und sie mit statistischen Methoden zu überwachen und zu verwalten. Normalerweise besteht die beste Methode zur Überprüfung der Genauigkeit darin, Operationen bis zu ihrem Ursprung zurückzuverfolgen und mithilfe von Quelldaten zu validieren – dies hat sich in der Vergangenheit jedoch bei umfangreichen operativen Prozessen als nicht kosteneffizient erwiesen. Stattdessen kann die statistische Prozesskontrolle (Statistical Process Control, SPC) für Priorisierung, Tracing, Monitoring und Kontrolle von kritischen Datenelementen genutzt werden.
Programm-Trace (ptrace)
Unter einer Programm-Trace versteht man einen Index der während der Ausführung einer Anwendung ausgeführten Anweisungen und referenzierten Daten. Zu den Informationen in einer Programm-Trace gehören u. a. der Programmname, die Sprache und die ausgeführte Quellanweisung. Programm-Traces werden beim Debugging einer Anwendung verwendet.
Tracing-Projekte und -Tools
Offene Standards für Distributed Tracing: OpenTelemetry
Bei Anwendungen, die sich aus verschiedenen Programmiersprachen und verteilten Microservices zusammensetzen und von ebenso global verteilten Entwicklern geschrieben wurden, ist es ungemein hilfreich, ein offenes, herstellerunabhängiges Framework an der Hand zu haben, mit dem sich die Anwendungen instrumentieren lassen.
OpenTelemetry ermöglicht dies bei einer Vielzahl von Programmiersprachen automatisch; nur bei einigen muss die Instrumentierung manuell erfolgen.
Jaeger und Zipkin
Jaeger und Zipkin sind zwei beliebte Open Source-Tools für das Anforderungs-Tracing mit ähnlichen Komponenten: Collector, Datenspeicher, Abfrage-API und Web-UI.
Die Funktionsweise gestaltet sich bei beiden wie folgt: Ausgehende Anforderungen werden zusammen mit der Anwendung nachverfolgt. Der Collector zeichnet die Daten auf, korreliert sie zwischen verschiedenen Traces und überträgt sie an eine Datenbank, aus der sie über die UI abgefragt und analysiert werden können.
Jaeger und Zipkin unterscheiden sich in ihrer Architektur und den unterstützten Programmiersprachen: Jaeger ist in Go implementiert, Zipkin in Java. Zipkin unterstützt praktisch jede Programmiersprache mit dedizierten Bibliotheken für Java, Javascript, C, C++, C#, Python, Go, Scala und anderen. Bei Jaeger ist die Liste der unterstützten Sprachen kürzer: C#, Java, Node.js, Python und Go.
Apache Kafka
Kafka ist eine verteilte Streaming-Plattform mit hohem Durchsatz und geringer Latenz für Echtzeit-Datenfeeds, die häufig in Microservice-Architekturen eingesetzt wird. Verwendet wird sie wie folgt:
- Verarbeitung von Datensatzströmen in Echtzeit
- Veröffentlichung und Bezug dieser Datensatzströme nach dem Prinzip einer Nachrichtenwarteschlange
- Fehlertolerante und dauerhafte Speicherung der Daten
Kafka nutzt „Topics“ – ein Kategorie- oder Feed-Name, unter dem Datensätze veröffentlicht werden – zum Abstrahieren von Datensatzströmen. Für jedes Topic legt Kafka ein partitioniertes Log an, bei dem es sich um eine geordnete, laufend erweiterte Abfolge von Datensätzen handelt, das als externes Commit-Log für ein verteiltes System dienen kann.
Kein Weg führt heute an Distributed Tracing vorbei
Microservices sind für Cloud-basierte Apps heute Standard. Mit der zunehmenden Komplexität dieser Systeme bietet Distributed Tracing von Anforderungen einen enormen Vorteil gegenüber dem älteren Suchansatz (der sprichwörtlichen Suche nach der Nadel im Heuhaufen) beim Aufspüren von Problemen, die Services stören könnten.
Wenn ihr für ein Microservice-basiertes System verantwortlich seid, wird euch die Einführung dieses leistungsfähigen Tools in eurem Unternehmen die Arbeit enorm erleichtern. Umso mehr gilt dies bei Umsetzung mit Splunk Observability. Hier könnt ihr die Lösung testen und in Aktion erleben, wie ihr damit eine Echtzeit-Ansicht eurer Tracing-Telemetrie erhaltet und auf diese Weise Probleme deutlich schneller behebt.
Ihr habt einen Fehler entdeckt oder eine Anregung? Bitte lasst es uns wissen und schreibt eine E-Mail an ssg-blogs@splunk.com.
Dieser Beitrag spiegelt nicht zwingend die Position, Strategie oder Meinung von Splunk wider.

Ähnliche Artikel
Über Splunk
Weltweit führende Unternehmen verlassen sich auf Splunk, ein Cisco-Unternehmen, um mit unserer Plattform für einheitliche Sicherheit und Observability, die auf branchenführender KI basiert, kontinuierlich ihre digitale Resilienz zu stärken.
Unsere Kunden vertrauen auf die preisgekrönten Security- und Observability-Lösungen von Splunk, um ihre komplexen digitalen Umgebungen ungeachtet ihrer Größenordnung zuverlässig zu sichern und verbessern.

Den Splunk-Blog abonnieren
Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.

