Was ist Predictive Modeling? Eine Einführung

Bei der prädiktiven Modellierung wird mithilfe bekannter Ergebnisse ein statistisches Modell erstellt, mit dem prädiktive Analysen durchgeführt oder zukünftige Verhaltensweisen vorhergesagt werden können. Es handelt sich um ein Tool im Rahmen der Predictive Analytics, eines Bereichs des Data Mining, bei dem versucht wird, die Frage „Was wird wohl als Nächstes passieren?“ zu beantworten.
Die Digitalisierung hat in nahezu allen Branchen enorme Mengen an Echtzeitdaten geschaffen. Mithilfe dieser Daten lassen sich historische Events analysieren, um zukünftige Events, wie z. B. finanzielle Risiken, Maschinenschäden, Verhaltensweisen von Kunden und weitere Ergebnisse vorherzusagen. Die von digitalen Produkten erzeugten Daten liegen jedoch oft unstrukturiert vor, also nicht in vordefinierter Weise organisiert. Das machtsie für menschliche Analysen zu komplex. Stattdessen nutzen Unternehmen Predictive-Modeling-Tools, die mithilfe von Algorithmen des maschinellen Lernens Muster in den Daten erkennen, die Rückschlüsse auf zukünftige Ereignisse zulassen.
Diese „Kristallkugel-Fähigkeit“ findet unternehmensweit Anwendung; Unternehmen nutzen Predictive Modeling, um ihre Abläufe effizienter zu gestalten, Produkte schneller auf den Markt zu bringen und Kundenbeziehungen zu verbessern, um nur einige Beispiele zu nennen. Sie gilt als besonders leistungsfähiges Werkzeug im ITOps-Bereich und bei der Software-Entwicklung, wo sie bei der Vorhersage von Systemausfällen, Anwendungsunterbrechungen und anderen Problemen helfen kann.
Splunk ITSI ist ein Branchenführer im Bereich AIOps
Splunk IT Service Intelligence (ITSI) ist eine AIOps-, Analyse- und IT-Management-Lösung, die Teams dabei unterstützt, Vorfälle vorherzusagen, bevor sie sich auf Kunden auswirken.

Unter Einsatz von KI und maschinellem Lernen korreliert ITSI Daten aus Überwachungsquellen und liefert eine einheitliche Echtzeitansicht relevanter IT- und Geschäftsdienste, reduziert die Alarmmenge und verhindert proaktiv Ausfälle.
Im Folgenden werden wir uns mit der Funktionsweise prädiktiver Modelle, den verschiedenen Verfahren zur prädiktiven Modellierung, den Vorteilen von Predictive Analytics und der Auswahl des richtigen prädiktiven Modells für Eure Organisation beschäftigen.
Grundlagen der prädiktiven Modellierung
Was ist Predictive Analytics? Predictive Analytics bezeichnet die Anwendung mathematischer Modelle auf große Datenmengen – mit dem Ziel, vergangene Verhaltensmuster zu identifizieren und zukünftige Ergebnisse vorherzusagen. Diese Praxis kombiniert Datensammlung, Data Mining, maschinelles Lernen und statistische Algorithmen, um das „vorhersagende“ Element zu liefern.
Predictive Analytics ist lediglich eine Praktik innerhalb eines Spektrums von Analyseansätzen wie z. B. der folgenden :
- Deskriptiv: Als grundlegendste Form der Analytik identifiziert deskriptive Analytik ein Problem oder beantwortet die Frage, was passiert ist. Sie kann jedoch nicht erklären, warum etwas passiert ist. Deshalb kommt sie normalerweise in Verbindung mit einer oder mehreren anderen Arten zum Einsatz.
- Diagnostisch: Die diagnostische Analyse kommt dort ins Spiel, wo die deskriptive Analyse aufhört und stellt Zusammenhänge her, die erklären, warum etwas passiert ist.
- Prädiktiv: Predictive Analytics erfasst historische Daten und erkennt Muster, die auf wahrscheinliche Ereignisse in der Zukunft hinweisen.
- Präskriptiv: Als raffiniertester Typ legt die präskriptive Analyse nahe, wie weiter vorzugehen ist, um ein Problem zu lösen oder zu vermeiden.
Deskriptive und diagnostische Analyse-Tools sind von unschätzbarem Wert, wenn es darum geht, Data Scientists dabei zu unterstützen, faktenbasierte Entscheidungen zu aktuellen Ereignissen zu treffen, aber für sich genommen sind sie nicht ausreichend. Unternehmen müssen Trends, Probleme und andere Ereignisse vorhersehen können, um wettbewerbsfähig zu sein. Die prädiktive Analyse baut auf der deskriptiven und der diagnostischen Analyse auf, indem sie Muster in Datenausgaben erkennt und mögliche Ergebnisse sowie die Wahrscheinlichkeit, dass sie passieren werden, vorhersagt. Dadurch können Unternehmen genauer planen, Risiken vermeiden oder abschwächen, Optionen schnell evaluieren und ganz allgemein fundiertere geschäftliche Entscheidungen treffen.
Dank der prädiktiven Analyse können Einzelhandelsunternehmen den langfristigen Kundenwert vorhersagen; medizinisches Fachpersonal kann die kostengünstigste Methode zur Behandlung von Patienten bestimmen und Lehrende können ermitteln, welche Schülerinnen und Schüler ihre persönliche Betreuung benötigen, um nur einige Anwendungsfälle zu nennen.
Predictive Analytics hat sich besonders in der IT als transformativ erwiesen. Die zunehmende Komplexität der Architektur, die auf Virtualisierung, Cloud, Internet der Dinge (IoT) und andere technologische Fortschritte zurückzuführen ist, erhöht das Volumen verständlicher Daten exponentiell. Das führt zu längeren Verzögerungen bei der Problemdiagnose und -lösung. Auf Basis von Big Data und künstlicher Intelligenz (KI) überwindet Predictive Analytics diese Schwierigkeiten. Indem sie Muster erkennt, kann sie Vorhersagen für Leistungsprobleme, Netzwerkausfälle, Kapazitätsengpässe, Sicherheitsverletzungen und eine Vielzahl anderer Infrastrukturprobleme machen. Das steigert die Leistung, reduziert die Ausfallzeiten und führt zu einer insgesamt widerstandsfähigeren Infrastruktur.
Wie Predictive-Analytics-Modelle funktionieren
Prädiktive Analysemodelle funktionieren, indem Machine Learning-Algorithmen an Datensätzen ausgeführt werden, die für Unternehmen relevant sind. Das Erstellen eines prädiktiven Modells ist ein schrittweiser Prozess, der damit beginnt, dass ein klares geschäftliches Ziel definiert wird. Dieses Ziel wird oftmals als Frage definiert und trägt dazu bei, den Umfang des Projekts und das entsprechende zu verwendende prädiktive Modell zu ermitteln. Von diesem Punkt aus führen Sie die nachfolgend dargestellten Schritte aus.
- Bereitet eure historischen Daten für die statistische Analyse vor.In den meisten Organisationen verteilen sich die Daten über viele Quellen (zum Beispiel Datenlager, Online-Datenbanken und vernetzte Geräte). Sie müssen gesammelt und bereinigt werden, um doppelte, fehlende, beschädigte oder ungenaue Daten zu entfernen. Dann benötigen sie ein definiertes Format für die Analyse.
- Teilt die Daten in zwei Datensätze: Trainingsdaten und Testdaten.Bei Trainingsdaten handelt es sich um Daten, die bekannten Ergebnissen entsprechen; sie werden dem Algorithmus für maschinelles Lernen zugeführt, damit er bewertet werden kann und auf Grundlage neuer Daten Vorhersagen treffen kann. Die Testdaten kommen zum Einsatz, um zu validieren, dass es dem Modell gelingt, genaue Vorhersagen zu treffen.
- Führt einen oder mehrere Algorithmen auf den Datensatz aus.Sobald der geeignete Modelltyp und die Algorithmen festgelegt sind, wird das Vorhersagemodell erstellt und implementiert.
Prädiktive Modellierung (Predictive Modeling) ist ein iterativer Prozess. Sobald ein Lernmodell erstellt und bereitgestellt wurde, muss seine Performance überwacht und verbessert werden. Das bedeutet, dass es kontinuierlich mit neuen Daten aktualisiert, trainiert, evaluiert und anderweitig verwaltet werden muss, damit es auf dem aktuellen Stand bleibt.
Predictive-Modeling-Techniken
Es gibt mehrere gängige Predictive-Modeling- Techniken, die sich entweder als Regressions- oder Klassifikationsanalyse einstufen lassen. Die Regressionsanalyse betrachtet eine abhängige Variable (die Aktion) und mehrere unabhängige Variablen (Ergebnisse) und bewertet die Stärke der Beziehung zwischen ihnen. Sie kann zum Einsatz kommen, um Trends vorherzusagen, die Auswirkungen einer bestimmten Aktion zu prognostizieren oder zu bestimmen, ob eine Aktion und ihre Ergebnisse korrelieren. Sobald ihr euch für den Einsatz der Regressionsanalyse entschieden habt, stehen mehrere Arten zur Auswahl. Zu den gängigsten zählen:
- Einfache lineare Regression: Die grundlegendste Form der Regressionsanalyse, sie stellt die Beziehung zwischen zwei Variablen her. Ein einfaches Beispiel: Ein Geschäft könnte lineare Regression verwenden, um die Beziehung zwischen der Anzahl der angestellten Verkäufer und dem erzielten Umsatz zu bestimmen.
- Multiple lineare Regression: Multiple lineare Regression kann verwendet werden, um die Beziehung zwischen der abhängigen Variable und jeder der unabhängigen Variablen herzustellen. Ein Gesundheitsforscher kann diese Technik beispielsweise einsetzen, um den Einfluss von Faktoren wie Rauchen, Ernährung und Bewegung auf die Entwicklung von Herzkrankheiten zu bestimmen.
- Logistische Regression: Diese Art der Regressionsanalyse eignet sich, um die Wahrscheinlichkeit zu bestimmen, dass ein Satz von Faktoren dazu führt, dass ein Ereignis eintritt oder nicht eintritt. Eine Bank, die vorhersagen möchte, ob ein Antragsteller einen Kredit zurückzahlen wird oder nicht, ist ein häufiger Anwendungsfall für logistische Regression.
- Ridge-Regression: Diese Technik wird verwendet, um multiple lineare Regressionsdatensätze zu analysieren, die einen hohen Grad an Korrelation zwischen unabhängigen Variablen aufweisen.
Mit der Klassifizierungsanalyse werden Daten in Kategorien eingeteilt, um sie genauer analysieren zu können. Dabei kommen unterschiedliche mathematische Verfahren zu Einsatz, wie z. B.
- Entscheidungsdiagramme: Diese Technik repliziert den Entscheidungsprozess, indem sie mit einer einzelnen Frage oder Idee beginnt und verschiedene Handlungsoptionen und deren mögliche Auswirkungen durch einen „Verzweigungsprozess“ untersucht, um zu einer Entscheidung zu gelangen.
- Neuronale Netze: Diese am menschlichen Gehirn orientierte Technik hilft, Daten zu clustern und zu klassifizieren, um Muster und Trends zu identifizieren, die für andere Techniken zu komplex sind. Eine Einzelhandelswebsite, die Produkte auf Basis von früheren Käufen eines Benutzers empfiehlt, liefert ein gutes Beispiel für neuronale Netze in Aktion.
Präskriptive vs. prädiktive Modellierung: Was ist der Unterschied?
Bei der präskriptiven Modellierung werden Daten in Echtzeit analysiert, um eine Vorgehensweise vorzuschlagen. Im Wesentlichen basiert sie auf den Erkenntnissen anderer Analysemodelle zur Berücksichtigung der verfügbaren Ressourcen, der früheren und aktuellen Performance und der potenziellen Ergebnisse, anhand derer vorgeschlagen wird, welche Maßnahmen als Nächste ergriffen werden. In einem IT-Kontext können mithilfe der präskriptiven Modellierung beispielsweise Infrastrukturverbesserungen auf der Grundlage von Überwachungs- und Instandhaltungsdaten vorgeschlagen werden; ferner kann das System sogar in die Lage versetzt werden, dass es die erforderlichen Anpassungen gemäß einem zuvor erstellten Skript selber vornimmt.
Präskriptive Analytik ist eine Erweiterung der prädiktiven Analytik. Während euch die prädiktive Analytik sagen kann, wie, wann und warum ein Problem wahrscheinlich auftreten wird, geht präskriptive Analytik einen Schritt weiter. Sie bietet konkrete Maßnahmen an, die ihr ergreifen könnt, um dieses Problem zu lösen. Beide Arten der Analytik ermöglichen es euch, fundiertere Entscheidungen zu treffen. Präskriptive Analytik zieht jedoch den größten Wert aus euren Daten und ermöglicht es euch, Prozesse und Systeme kurz- und langfristig zu optimieren. Lest mehr über die Unterschiede zwischen prädiktiver und präskriptiver Analytik.
Auswahl des richtigen prädiktiven Modells
Es gibt mehrere verschiedene Arten von prädiktiven Analysemodellen. Die meisten von ihnen sind für bestimmte Anwendungen vorgesehen, aber einige können in vielen verschiedenen Situationen eingesetzt werden. Hierzu zählen:
- Prognosemodelle sind vermutlich die gängigsten Arten von prädiktiven Analysemodellen. Sie lernen aus historischen Daten, um die Werte neuer Daten zu schätzen. Prognosemodelle können beispielsweise bestimmen, wie viele Anrufe ein Kundendienstmitarbeiter pro Tag bewältigen kann oder wie viele Exemplare eines Bestsellers ein Händler für die kommende Verkaufsperiode ordern sollte.
- Klassifizierungsmodelle: Diese Modelle nutzen historische Daten, um Informationen für Abfragen und Antworten zu kategorisieren. Sie bieten umfassende Analysen, die zur Entscheidungsfindung beitragen. Sie sind weit verbreitet in vielen verschiedenen Branchen und eignen sich besonders für Ja/Nein-Fragen wie: „Wird dieser Kreditantragsteller wahrscheinlich nicht zahlen können?“
- Clustering-Modelle: Dieses Modell sortiert Daten anhand gemeinsamer Attribute. Zu den gängigen Anwendungen zählt die Kundensegmentierung, bei der das Modell die Kundendaten eines Unternehmens nach gemeinsamen Merkmalen und Verhaltensweisen gruppiert. Clustering-Modelle verwenden zwei Arten von Clustering: hart und weich. Beim harten Clustering gehören Datenpunkte entweder zu einer Kategorie oder nicht. Das weiche Clustering ordnet Datenpunkte nicht in separate Cluster ein, sondern weist jedem Punkt eine Wahrscheinlichkeit für die Zugehörigkeit zu jedem Cluster zu.
- Ausreißermodelle: Ausreißermodelle identifizieren und analysieren abnormale Einträge in einem Datensatz. Sie kommen in der Regel dort zum Einsatz, wo unerkannte Anomalien für Firmen kostspielig sein können, etwa im Finanzwesen und Einzelhandel. Ein Ausreißermodell könnte beispielsweise eine betrügerische Transaktion erkennen, indem es Betrag, Zeit, Ort, Kaufhistorie und Art des Kaufs bewertet.
- Zeitreihenmodelle: Dieses Modell verwendet Zeit als Eingabeparameter, um Trends in einem bestimmten Zeitraum vorherzusagen. Ein Callcenter könnte dieses Modell beispielsweise nutzen, um die erwartete Anzahl von Support-Anrufen im kommenden Monat basierend auf den Anrufen der letzten drei Monate zu ermitteln.
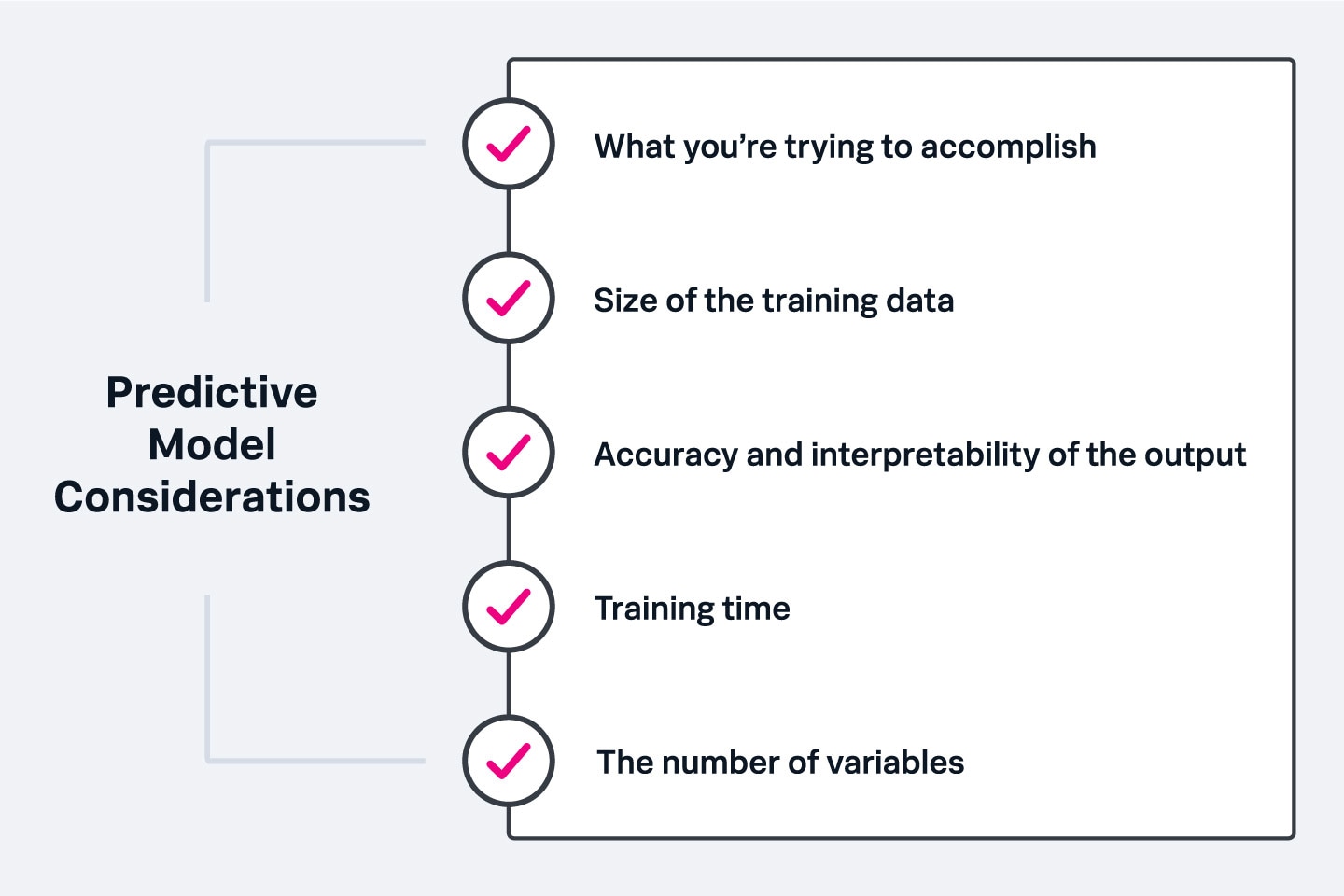
Bei der Wahl eines prädiktiven Modells gibt es einige Dinge zu berücksichtigen:
- Zielsetzung: Prognosemodelle eignen sich hervorragend zur Vorhersage zukünftiger Ereignisse basierend auf vergangenen, während Klassifizierungsmodelle eine gute Wahl darstellen, wenn ihr mögliche Ergebnisse untersuchen möchtet, um eine wichtige Entscheidung zu treffen. Das richtige Modell hängt stark davon ab, was ihr aus euren Daten lernen möchtet.
- Generell gilt bei der Menge der Trainingsdaten: Je mehr Trainingsdaten vorliegen, desto zuverlässiger fallen die Vorhersagen aus. Eine begrenzte Datenmenge oder wenige Vorkommen des zu messenden Ereignisses im Datensatz könnten – im Vergleich zu einem großen Datensatz mit vielen Variablen – den Einsatz anderer Algorithmen erfordern.
- Genauigkeit und Interpretierbarkeit der Ergebnisse: Genauigkeit bezieht sich auf die Zuverlässigkeit der Modellvorhersagen, Interpretierbarkeit hingegen darauf, wie leicht sie zu verstehen sind. Idealerweise weist euer Modell ein ausgewogenes Verhältnis beider Aspekte auf.
- Trainingszeit: Je mehr Trainingsdaten vorliegen, desto mehr Zeit erfordert das Training des Algorithmus. Höhere Genauigkeit erfordert ebenfalls eine längere Trainingszeit. Diese beiden Faktoren könnten für viele Organisationen bei der Modellauswahl am wichtigsten sein.
- Linearität der Daten: Nicht alle Beziehungen verlaufen ganz linear, und komplexere Datenstrukturen können die Optionen bei den Techniken (etwa neuronale Netze) einschränken.
- Anzahl der Variablen: Daten mit vielen Variablen verlangsamen manche Algorithmen und verlängern die Trainingszeit. Das sollte bei der Modellauswahl Berücksichtigung finden.
Letztlich werden Sie wahrscheinlich mehrere verschiedene Algorithmen und prädiktive Modelle an Ihren Daten ausführen und die Ergebnisse evaluieren müssen, um die für Ihre Bedürfnisse am besten geeignet Wahl zu treffen.
Beispiele für geschäftliche Vorteile prädiktiver Modellierung
Prädiktive Modellierung (Predictive Modeling) ist wichtig, da jedes Unternehmen, ganz unabhängig von der Branche, auf Daten setzt, um bessere unternehmerische Entscheidungen zu treffen. Dank prädiktiver Modellierung können Sie Ihren Entscheidungen mehr Vertrauen schenken, da sie Ihnen zeigt, mit welchen Ergebnissen bei den Aktionen, die Sie in Erwägung ziehen, aller Wahrscheinlichkeit nach zu rechnen ist.
Zu den häufigsten geschäftlichen Vorteilen können gehören:
- Verbesserte Entscheidungsfindung: Durch das Verständnis wahrscheinlicher zukünftiger Ergebnisse können Unternehmen fundierte Entscheidungen treffen. Ob es um die Ressourcenzuweisung, Marketingkampagnen oder die Auswahl von Leads geht: Prädiktive Erkenntnisse bieten Orientierung.
- Kosteneinsparungen: Prädiktive Modelle helfen Unternehmen dabei, Risiken vorherzusehen und zu managen, Verschwendung zu reduzieren und Prozesse zu optimieren. Die Vorhersage von Maschinenausfällen kann beispielsweise zu rechtzeitiger Wartung führen und kostspielige Ausfallzeiten vermeiden.
- Umsatzsteigerung: Durch den Einsatz prädiktiver Analytik können Firmen das Kundenverhalten besser verstehen, ihre Marktsegmente gezielter ansprechen und sich auf die vielversprechendsten Chancen konzentrieren. Die Vorhersage, welche Kunden am ehesten abwandern könnten, ermöglicht Firmen beispielsweise ein proaktives Eingreifen.
- Betriebliche Effizienz: Durch Nachfrageprognosen können Unternehmen Bestände besser verwalten, Lieferkettenprozesse optimieren und Kundenbedürfnisse erfüllen, ohne überschüssige Lagerbestände zu halten.
- Verbesserte Kundenerfahrung: Prädiktive Modelle können Unternehmen helfen, Kundenbedürfnisse und -präferenzen zu verstehen. Das ermöglicht maßgeschneiderte Produktempfehlungen, personalisierte Marketingbotschaften und effektivere Kundenservice-Maßnahmen.
- Risikomanagement: Finanzinstitute nutzen prädiktive Modellierung zur Bewertung von Kreditrisiken, Versicherungsansprüchen und potenziellen betrügerischen Aktivitäten. Durch die Vorhersage wahrscheinlich betrügerischer Transaktionen gelingt es Unternehmen, das Risiko finanzieller Verluste zu reduzieren.
- Strategische Vorteile: Einblicke in zukünftige Marktbedingungen, Wettbewerbslandschaften und Kundenpräferenzen ermöglichen Firmen eine effektivere Positionierung und Wettbewerbsvorteile.
Herausforderungen, Risiken und Annahmen
Mathematisch ausgeführte, auf Datasets basierende Vorhersagen sind nicht unfehlbar. In der Regel lassen sich Probleme mit prädiktiver Modellierung auf wenige Faktoren eingrenzen. Um genaue Vorhersagen zu treffen, benötigen Sie ein großes Dataset mit vielen Variablen, die als Grundlage für Ihre Vorhersagen geeignet sind. Für viele Organisationen ist es nicht leicht, an diese Daten heranzukommen, da sie keine robuste Datenplattform haben, mit der es möglich ist, alle Daten eines Unternehmens zu korrelieren, Informationen detailliert zu analysieren und verwertbare Erkenntnisse aus großen Datasets abzuleiten. Folglich kann es leicht passieren, dass kleine oder unvollständige Datenproben zu unverlässlichen Vorhersagen führen.
Ein weiteres Hindernis für effektive prädiktive Modellierung stellt die Annahme dar, dass die Zukunft der Vergangenheit gleichen wird. Prädiktive Modelle basieren auf historischen Daten. Verhaltensweisen ändern sich jedoch oft im Laufe der Zeit, was lange genutzte Modelle plötzlich ungültig machen kann. Neue und einzigartige Variablen in verschiedenen Situationen rufen wiederum neu angepasste Verhaltensweisen und Ansätze hervor, die mit früheren Modellen nicht immer vorhersehbar sind. Deshalb müssen prädiktive Modelle ständig mit neuen Daten aktualisiert werden, um mit aktuellen Verhaltensweisen Schritt zu halten und darauf basierend genaue Vorhersagen zu treffen
Eine weitere häufige Herausforderung bei der prädiktiven Modellierung ist die Modellabweichung. Modellabweichung bezeichnet die Tendenz eines Modells, seine Vorhersagefähigkeit im Laufe der Zeit zu verlieren. Sie entsteht meistens durch statistische Verschiebungen in den Daten und kann Unternehmen durch ungenaue Vorhersagen negativ beeinflussen, wenn sie unentdeckt bleibt.
Sollte Ihr Unternehmen sich auf prädiktive Modellierung verlassen?
Prädiktive Modellierung ist eine solide Data Science-Methode, aber sie ist nicht unfehlbar. Kein prädiktives Modell konnte z. B. die COVID-19-Pandemie vorhersagen oder wie sie das Verbraucherverhalten in diesem immensen Ausmaß verändern sollte. Abgesehen von diesen einzigartigen Umständen ist prädiktive Modellierung eine äußerst effektive Methode für fundierte unternehmerische Entscheidungen, solange Sie über die richtige Lösung und die richtigen Mitarbeiter verfügen und Ihr Modell kontinuierlich mit neuen Daten aktualisieren.
Erste Schritte
Als Einstieg in die prädiktive Modellierung müssen Sie zunächst entscheiden, welche Probleme Ihre Organisation lösen möchte. Wenn Sie sich im Klaren darüber sind, was Sie erreichen möchten, erhalten Sie ein genaues verwertbares Ergebnis, während Sie mit einem Ad-hoc-Ansatz weitaus weniger effektiv sein werden.
Als Nächstes bewerten Sie sämtliche Fähigkeiten und technologischen Schwächen in Ihrem Unternehmen. Während Softwarelösungen das Gröbste für Sie erledigen, erfordert die prädiktive Modellierung Fachwissen, damit sie effektiv ist. Vergewissern Sie sich, dass Sie über die Mitarbeiter, die Tools und die Infrastruktur verfügen, die Sie benötigen, um die Daten für Ihre Analyse zu identifizieren und vorzubereiten.
Führen Sie schließlich ein Pilotprojekt durch. Idealerweise sollte dieses Projekt einen kleinen Umfang haben und nicht geschäftsentscheidend, aber dennoch wichtig für das Unternehmen sein. Identifizieren Sie Ihr Ziel, entscheiden Sie, welche Messdaten Sie verwenden möchten, um dieses Ziel zu erreichen, und wie Sie den Wert quantifizieren. Sobald Sie erste Erfolge erzielen, verfügen Sie über eine Grundlage, auf der Sie größere prädiktive Modellierungsprojekte aufbauen können.
Zusammenfassung
Prädiktive Modellierung ist das ultimative Werkzeug im Analytik-Arsenal und ermöglicht Organisationen jeder Größe, selbstbewusstere und wirkungsvollere Entscheidungen zu treffen. Mit einem systematischen Ansatz und der richtigen Software-Lösung könnt ihr die Macht der prädiktiven Modellierung nutzen, um komplexe Geschäftsprobleme zu lösen und neue Chancen zu entdecken.
Ihr habt einen Fehler entdeckt oder eine Anregung? Bitte lasst es uns wissen und schreibt eine E-Mail an ssg-blogs@splunk.com.
Dieser Beitrag spiegelt nicht zwingend die Position, Strategie oder Meinung von Splunk wider.

Ähnliche Artikel
Über Splunk
Weltweit führende Unternehmen verlassen sich auf Splunk, ein Cisco-Unternehmen, um mit unserer Plattform für einheitliche Sicherheit und Observability, die auf branchenführender KI basiert, kontinuierlich ihre digitale Resilienz zu stärken.
Unsere Kunden vertrauen auf die preisgekrönten Security- und Observability-Lösungen von Splunk, um ihre komplexen digitalen Umgebungen ungeachtet ihrer Größenordnung zuverlässig zu sichern und verbessern.

Den Splunk-Blog abonnieren
Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.

