
Digitale Resilienz zahlt sich aus
Ladet euch dieses E-Book herunter, um mehr über die Rolle der digitalen Resilienz in Unternehmen zu erfahren.

Fast alles, was digital ist, läuft heute auf verteilten Systemen. Wie diese Distributed Systems funktionieren, was sie leisten und warum Unternehmen zu Recht auf verteiltes Rechnen (Distributed Computing) setzen, erfahren Sie hier.
Verteilte Systeme können ziemlich kompliziert sein. Zum Glück ist die Idee dahinter leicht zu verstehen! Ein verteiltes System ist einfach eine Umgebung, in der mehrere Rechner oder Geräte, die über ein Netzwerk miteinander verbunden sind, an gemeinsamen Aufgaben arbeiten. Die Komponenten in verteilten Systemen teilen sich die Arbeit auf und gehen dabei koordiniert vor, sodass sie eine konkrete Aufgabe effizienter erledigen, als wenn nur ein einziges Gerät sie erledigt.
Es ist nur logisch, dass es immer mehr verteilte Systeme gibt. Das Internet hat es möglich gemacht, dass wir aus der Ferne arbeiten, und viele Rechenaufgaben sind heute ohnehin zu komplex, als dass ein einzelner Rechner sie allein bewältigen könnte. Das ist der große Vorteil verteilter Systeme: effizientes Arbeiten über Länder- und Teamgrenzen hinweg. Ohne Distributed Computing wäre das meiste davon gar nicht machbar.
In diesem Beitrag befassen wir uns mit der Funktionsweise von verteilten Systemen (Distributed Systems), mit den Herausforderungen und Risiken der entsprechenden Plattformen und mit den unzähligen Vorteilen von verteiltem Rechnen (Distributed Computing).
In der Vergangenheit war verteiltes Rechnen relativ teuer, komplex in der Konfiguration und schwierig im Management. Dank SaaS-Lösungen ist verteiltes Rechnen aber für Unternehmen jeder Art und Größe machbar und erschwinglich geworden.
Heutzutage findet bei praktisch allen Arten der Datenverarbeitung verteiltes Rechnen statt, vom Datenbank-Management bis hin zu Videospielen. Tatsächlich wären viele Formen von Software, etwa Kryptowährungen, wissenschaftliche Simulationen, Blockchain-Technologien und KI-Lösungen, ohne entsprechende Plattformen überhaupt nicht möglich.
Distributed Systems kommen dann zum Einsatz, wenn eine Workload zu groß für einen einzelnen Rechner oder ein einziges Gerät wäre. Verteilte Systeme sind ein entscheidender Erfolgsfaktor im Umgang mit veränderlichen Workloads, etwa wenn im E-Commerce der Traffic am Cyber Monday ansteigt oder wenn euer Unternehmen plötzlich mediale Aufmerksamkeit bekommt.
Weil sie auf die Fähigkeiten anderer Rechner und Prozesse zurückgreifen, können verteilte Systeme Funktionen bereitstellen, die für einzelne Systeme nur schwer oder gar nicht zu entwickeln wären.
Hierzu gehören auch Dinge wie externe Off-Site-Backups von Servern und Anwendungen. Wenn der Master-Katalog nicht über die Segmente verfügt, die er für eine Wiederherstellung benötigt, kann er einfach einen anderen Knoten von außerhalb bitten, die Segmente zu senden. Praktisch immer, wenn ihr heute einen Rechner etwas tun lasst, funktioniert das mithilfe verteilter Systeme: wenn ihr eine Mail verschickt, wenn ihr ein Game spielt und wenn ihr diesen Beitrag im Internet vor euch habt.
Hier ein paar ganz alltägliche Beispiele für Distributed Systems:
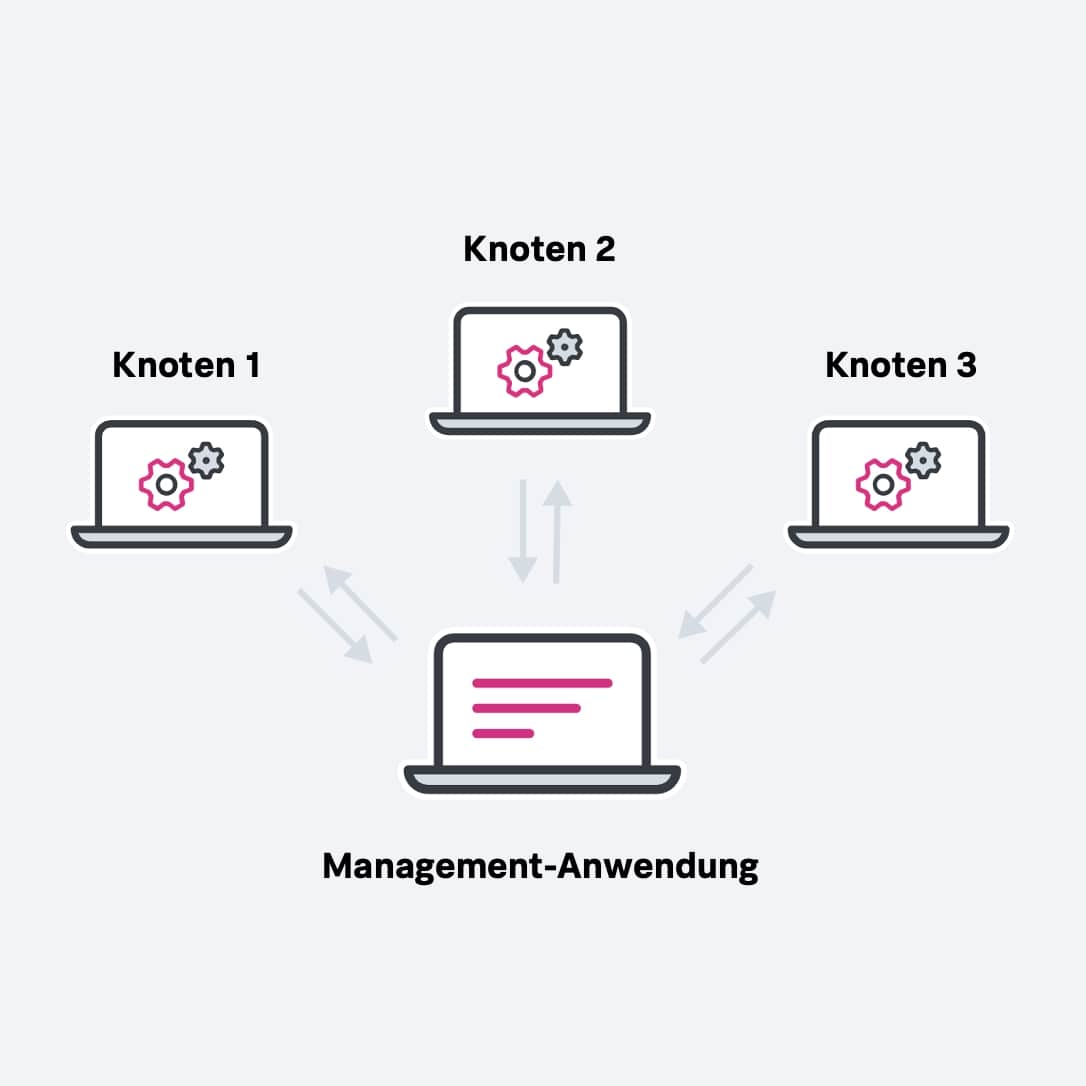
Am Anfang eines verteilten Systems steht eine Aufgabe. Nehmen wir an, ihr müsst ein Video rendern, das ihr für ein bestimmtes Produkt braucht.
Die Anwendung oder die verteilten Anwendungen, die diese Aufgabe managen – in diesem Fall ein Video-Editor auf dem Client-Computer – teilt bzw. teilen die Aufgabe in einzelne Portionen auf. In diesem einfachen Beispiel gibt der Algorithmus einem Verbund von zwölf einzelnen Rechnern oder Knoten (Nodes) jeweils einzelne Frames zur Bearbeitung. Wenn ein Einzelbild bearbeitet und abgeliefert ist, teilt die Management-Anwendung dem Knoten einen neuen Frame zu. Das geht so weiter, bis das gesamte Video fertig ist und alle Teile zusammengefügt sind.
Ein solches System muss sich aber keineswegs auf zwölf Knoten beschränken. Aufgaben lassen sich auf Hunderte und Tausende von Knoten verteilen, sodass eine Arbeit, für die ein einzelner Rechner Tage gebraucht hätte, in wenigen Minuten erledigt ist.
Wer die Herausforderungen einer verteilten Rechenplattform verstehen will, wird feststellen, dass der Trick darin besteht, das Ganze als Abfolge miteinander verbundener Muster zu gestalten. Wenn das System so weit vereinfacht ist, dass es aus kleineren Komponenten besteht, die leichter zu handhaben und zu verstehen sind, dann lässt sich daraus eine komplexe Architektur abstrahieren. Diese Muster dienen oft auch dazu, Distributed Systems zu beschreiben. Bekannte Beispiele:
Verteilte Systeme werden mit unterschiedlichen Kombinationen von Mustern ausgestaltet, und jeder Ansatz hat spezifische Vor- und Nachteile.
Es gibt heute eine Vielzahl von Modellen und Architekturen verteilter Systeme.
An diesem Punkt dürfte euch vermutlich schon klar sein: Die gängigsten Formen verteilter Systeme arbeiten heute über das Internet. Sie geben ihre Workloads an Dutzende von virtuellen Cloud-Servern weiter, und diese Instanzen werden flexibel gestartet und wieder beendet, wenn die Aufgabe erledigt ist.
Nachdem wir nun eine Vorstellung davon haben, was verteilte Systeme sind, können wir damit beginnen, ihre Hauptmerkmale zu beschreiben. Gute verteilte Systeme haben folgende Eigenschaften gemeinsam:
Verteilte Systeme bieten eine Reihe von Vorteilen gegenüber monolithischen Einzelsystemen:
(Ein eigener Beitrag erklärt den Unterschied zwischen Content Delivery Networks und Load Balancers.)
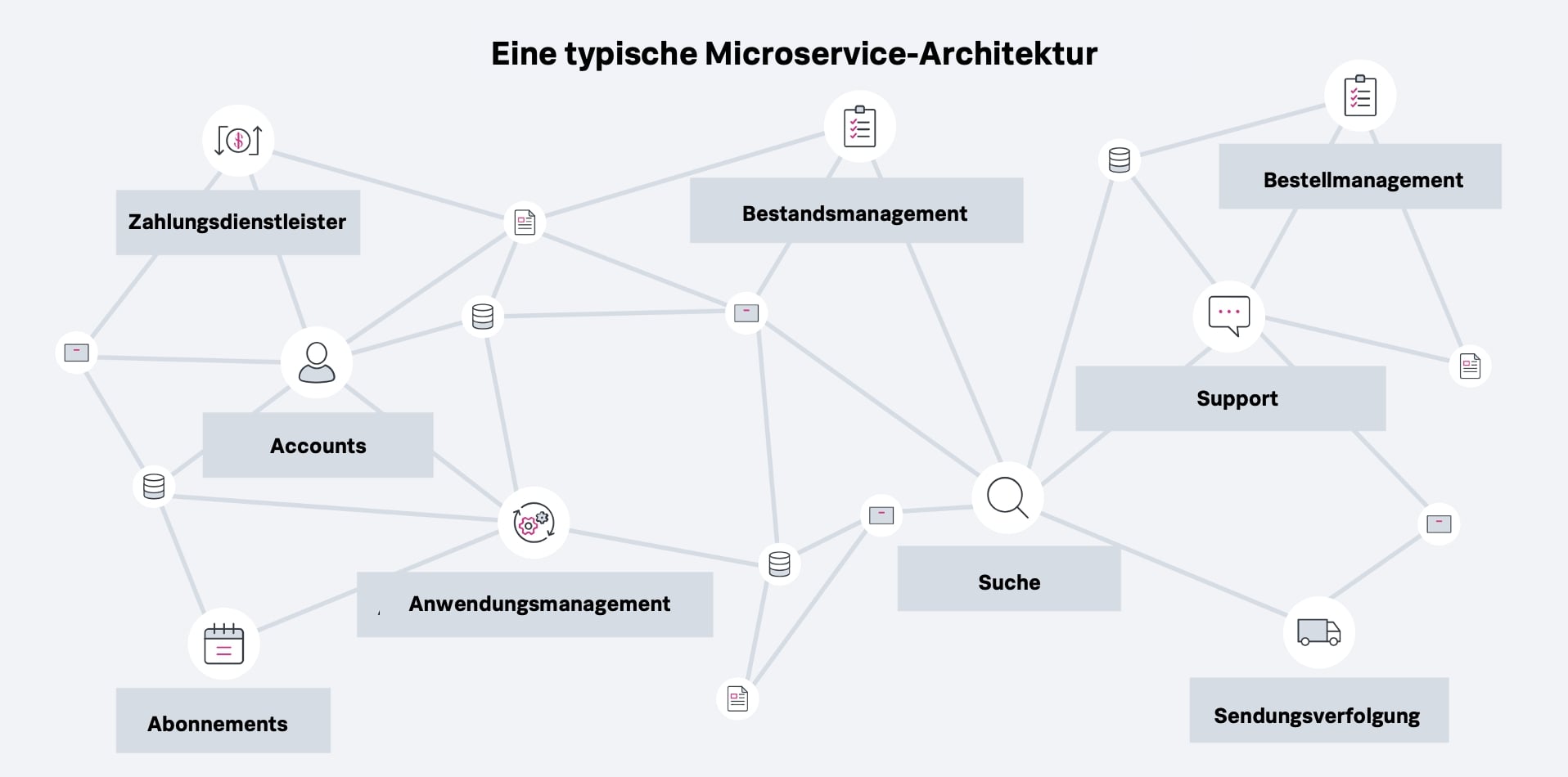
Distributed systems are considerably more complex than monolithic computing environments, and raise a number of challenges around design, operations and maintenance. These include:
Verteilte Systeme sind jedoch wesentlich komplexer als monolithische Rechenumgebungen und bringen eine ganze Reihe von Herausforderungen in Bezug auf Design, Betrieb und Wartung mit sich. Dazu gehören vor allem die folgenden:
Die Herausforderungen, die verteilte Systeme mit sich bringen, führen zu einer Reihe spezifischer Risiken:
Distributed Systems können ganz bescheidene Bereitstellungen einzelner Abteilungen im LAN sein – oder groß angelegte Implementierungen mit globaler Reichweite. Neben der Größe und der Gesamtkomplexität sind folgende Kriterien zu berücksichtigen:
Verteilte Bereitstellungen lassen sich in die Kategorien „Abteilung“, „kleines Unternehmen“, „mittleres Unternehmen“ und „Großunternehmen“ einteilen. Diese Sortierung ist keineswegs verbindlich, aber ein guter Ausgangspunkt für die Planung der erforderlichen Ressourcen bei der Implementierung eines verteilten Rechensystems.
Verteilte Systeme können sich außerdem im Laufe der Zeit weiterentwickeln, wenn das Unternehmen wächst und expandiert, sodass etwa aus einer Bereitstellung für die Abteilung eine Bereitstellung der Kategorie „kleines Unternehmen“ wird.
Nun ist klar, dass verteilte Systeme trotz all ihrer Vorteile eine komplizierte Angelegenheit sind. Es ist definitiv von Vorteil, wenn ihr wisst, was im System vorgeht – wir sprechen hier von der Beobachtbarkeit oder Observability des Systems. Glücklicherweise ist dies mit dezentralem Tracing (Distributed Tracing) zu schaffen.
Distributed Tracing ermöglicht es, den Weg einer Anfrage oder Transaktion durch die Anwendung zu verfolgen. Dadurch lassen sich Engpässe, Fehler und andere Probleme identifizieren, die sich auf die Anwendungsleistung auswirken können.
Ohne Distributed Tracing wäre ein effektives Monitoring einer global verteilten Systemlandschaft kaum möglich.
Distributed Tracing, auch Distributed Request Tracing genannt, ist eine Methode zum Monitoring von Anwendungen. Meist handelt es sich dabei um Anwendungen in Microservice-Architekturen, die typischerweise in verteilten Systemen bereitgestellt werden. Distributed Tracing ist insofern eine Form von verteiltem Rechnen, als es normalerweise zum Monitoring von Anwendungen auf verteilten Systemen eingesetzt wird.
Tracing ermöglicht es in der Softwareentwicklung und den IT Operations, den Weg einer Transaktion durch eine Anwendung zu verfolgen. So hangelt sich zum Beispiel eine Online-Kreditkartentransaktion vom Kauf durch den Verifizierungs- und Bestätigungsprozess bis zum Transaktionsabschluss. Das Tracing-System überwacht diesen Prozess Schritt für Schritt und ermöglicht es den Entwicklungsteams, Fehler, Engpässe, Latenzen und andere Anwendungsprobleme zu erkennen.
Distributed Tracing ist aufgrund der enormen Komplexität moderner Software-Architekturen notwendig. Distributed-Tracing-Systeme sind darauf ausgelegt, in Infrastrukturen mit verteilten Diensten zu arbeiten und eine Vielzahl von Anwendungen und Prozessen gleichzeitig über zahlreiche Knoten und Rechenumgebungen hinweg zu verfolgen. (Als separaten Beitrag haben wir dazu einen Praxisleitfaden Distributed Tracing.)
In der Praxis nutzen Administratoren in verteilten Rechenumgebungen eine Vielzahl von Ansätzen der Zugangskontrolle, die von klassischen Zugriffssteuerungslisten (Access Control List, ACL) bis hin zu rollenbasierten Zugangskontrollen (Role-based Access Control, RBAC) reichen.
Einer der vielversprechendsten Zugangskontrollmechanismen für verteilte Systeme ist die attributbasierte Zugangskontrolle (Attribute-based Access Control, ABAC). Sie kontrolliert den Zugriff auf Objekte und Prozesse mit Hilfe von Regeln, die User-Informationen ebenso enthalten wie Informationen zur angeforderten Aktion und zur Umgebung, aus der die Anfrage kommt. Administratoren können diese Rollen noch weiter verfeinern und beispielsweise den Zugang auf bestimmte Tageszeiten oder bestimmte Standorte beschränken.
Verteilte Systeme haben das Potential, die Datenverarbeitung in absehbarer Zukunft entscheidend zu prägen. Praktisch jede Art von Anwendung oder Dienstleistung wird in irgendeiner Form von verteiltem Rechnen zu tun haben. Und der Bedarf an Datenverarbeitung, die always on und überall verfügbar ist, dürfte noch kräftig steigen.
Dieser Beitrag stellt nicht unbedingt den Standpunkt, die Strategie oder die Meinung von Splunk dar.

Weltweit führende Unternehmen verlassen sich auf Splunk, ein Cisco-Unternehmen, um mit unserer Plattform für einheitliche Sicherheit und Observability, die auf branchenführender KI basiert, kontinuierlich ihre digitale Resilienz zu stärken.
Unsere Kunden vertrauen auf die preisgekrönten Security- und Observability-Lösungen von Splunk, um ihre komplexen digitalen Umgebungen ungeachtet ihrer Größenordnung zuverlässig zu sichern und verbessern.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2025 Splunk LLC All rights reserved.
© 2005 - 2025 Splunk LLC All rights reserved.

