Was ist Verfügbarkeit?

Verfügbarkeit bezeichnet die Zeitspanne, in der ein Gerät, ein Dienst oder ein anderer Teil der IT-Infrastruktur nutzbar ist – oder ob er überhaupt zur Verfügung steht. Da Verfügbarkeit bzw. Systemverfügbarkeit anzeigt, ob ein System normal funktioniert und wie effektiv es sich von einem Absturz, einem Angriff oder einer anderen Art von Störung erholen kann, gilt sie als eine der wichtigsten Kennzahlen im IT-Management. Sie ist eine bleibende Herausforderung. Schließlich kann es sein, dass ein ganzes Unternehmen nicht arbeiten kann, wenn ein wesentliches Hardware-Element oder ein wichtiger Dienst nicht verfügbar ist.
Zahlreiche Geschäftsprozesse sowie interne und externe Faktoren können die Verfügbarkeit beeinflussen. Das macht es besonders schwierig, Verfügbarkeit aufrechtzuerhalten. Denial-of-Service-Angriffe, Hardware- und IT-Ausfälle und sogar Naturkatastrophen können sich auf die Verfügbarkeit auswirken und die mittlere Reparaturzeit (MTTR) verlängern. Ein Problem auf einem einzigen gemeinsam genutzten Cloud-Server eines Drittanbieters kann sich kaskadenartig auf die Verfügbarkeit einer anderen Organisation auswirken. In jeder IT-Umgebung interagieren zahlreiche Geräte und Dienste – und ein Problem mit einem einzelnen Gerät oder Dienst kann zu einem weitreichenden Ausfall führen. Wenn beispielsweise eine wichtige Datenbank beschädigt wird, kann ein kritischer Webserver ausfallen, selbst wenn die zugrunde liegende Hardware, das Betriebssystem und das Netzwerk nicht betroffen sind.
Die Verfügbarkeit wird üblicherweise als prozentuale Kennzahl dargestellt und wie folgt berechnet:
Verfügbarkeit = (Gesamtbetriebszeit) - (Ausfallzeit) / (Gesamtbetriebszeit)
Diese Kennzahl kann auch als konkretes Zeitmaß dargestellt werden. Wenn Server X beispielsweise eine angegebene oder zugesicherte Verfügbarkeit von 99,999 % (in der Branche als "fünf Neunen" bekannt) über den vorangegangenen Monat aufweist, beträgt seine maximale Ausfallzeit 26 Sekunden pro Monat.
In diesem Artikel untersuchen wir, wie Unternehmen in verschiedenen Betriebsumgebungen ein hohes Maß an Verfügbarkeit erreichen können und welche Vorteile und Kosten damit verbunden sind.
Splunk ITSI ist ein Branchenführer im Bereich AIOps
Splunk IT Service Intelligence (ITSI) ist eine AIOps-, Analyse- und IT-Management-Lösung, die Teams dabei unterstützt, Vorfälle vorherzusagen, bevor sie sich auf Kunden auswirken.

Unter Einsatz von KI und maschinellem Lernen korreliert ITSI Daten aus Überwachungsquellen und liefert eine einheitliche Echtzeitansicht relevanter IT- und Geschäftsdienste, reduziert die Alarmmenge und verhindert proaktiv Ausfälle.
Hochverfügbarkeit verstehen
Hochverfügbarkeit ist dann erreicht, wenn ein System außergewöhnliche Verfügbarkeitswerte aufweist – hohe Betriebszeiten, Fehlertoleranz und Ausfallsicherheit.
Die Definition von Verfügbarkeit oder Hochverfügbarkeit beschreibt typischerweise einen Dienst, der praktisch nie ausfällt. Große Websites wie Google und Amazon – obwohl nicht völlig ausfallsicher – sind so zuverlässig, dass sie als Standards für Hochverfügbarkeit für andere Dienste dienen. Sie setzen auf umfangreiche, komplexe und sehr kostspielige Technologien, um dieses Maß an Verfügbarkeit zu gewährleisten. Versorgungseinrichtungen wie die für Strom, Gas und Wasser sind weitere gängige Beispiele für Hochverfügbarkeit in der Praxis, ebenso wie die Komponenten der Flugsysteme eines Flugzeugs und die Ausrüstung in einem Krankenhaus-Operationssaal.
Hochverfügbarkeit hängt auch mit Reaktionsfähigkeit zusammen. Wenn ein Dienst zwar betriebsbereit ist, aber so langsam arbeitet, dass er die Endnutzer frustriert, kann seine Verfügbarkeit infrage gestellt sein. Während die Verfügbarkeit formal anhand der obigen Formel gemessen werden kann, die die Betriebszeit als binären Datenpunkt betrachtet (entweder der Dienst ist online oder offline), ergibt sich eine differenziertere Bewertung der Verfügbarkeit, wenn sie zusammen mit verwandten Kennzahlen wie Antwortzeit und Fehlerrate betrachtet wird.
Der weithin angepriesene Goldstandard für echte Hochverfügbarkeit ist eine Verfügbarkeit von 99,999 %, die gemeinhin als "fünf Neunen" bezeichnet wird. Wie im obigen Beispiel bedeutet eine Verfügbarkeit von 99,999 % eine Ausfallzeit von 26 Sekunden pro Monat oder etwa 5,5 Minuten pro Jahr. Wenn man bedenkt, wie lange es dauert, einen PC nach einem Stromausfall neu zu starten, wird deutlich, wie anspruchsvoll und schwierig es sein kann, eine Verfügbarkeit von fünf Neunen zu erreichen.
Wie sich Hochverfügbarkeit erreichen lässt
Hochverfügbarkeit wird durch den Einsatz von Technologien erreicht, die speziell für diese Aufgabe entwickelt wurden. In Computersystemen wird Hochverfügbarkeit durch folgende Taktiken und Werkzeuge erreicht:
- Redundanz : Mehrere Systeme laufen parallel, sodass bei Ausfall eines Systems ein anderes sofort einspringen kann. Redundanz kann lokal und verteilt wirksam werden; während lokale Redundanz (mehrere Server in einem Raum) bei einem isolierten Hardwareausfall hilft, ist geografisch verteilte Redundanz bei Naturkatastrophen oder anderen regionalen Problemen nützlich, die ein ganzes Rechenzentrum lahmlegen können. Große Dienstanbieter betreiben Server in Dutzenden von Regionen weltweit, um extreme Zuverlässigkeit zu gewährleisten.
- Skalierbarkeit: Systeme sind so konzipiert, dass sie eine plötzliche Zunahme der Arbeitslast (wie z. B. Webverkehr) bewältigen können, sei es legitim oder bösartig – wie im Fall eines verteilten Denial-of-Service-Angriffs.
- Lastverteilung: Diese Werkzeuge verteilen Arbeitslasten auf Server/Dienste, um die Belastung einzelner Systeme zu minimieren und eine Überlastung einzelner Dienste zu verhindern.
- Überwachung: IT-Mitarbeiter können intelligente Systeme nutzen, um die Leistung aller oben genannten Komponenten in Echtzeit zu überwachen und frühzeitig auf sich anbahnende Probleme aufmerksam zu werden – vorzugsweise lange bevor ein Problem zu Ausfallzeiten führen könnte.
- Backup: Da hochwertige Backups eine effiziente und zeitnahe Wiederherstellung nach einem Ausfall gewährleisten, sind sie ein wesentlicher Bestandteil jeder Hochverfügbarkeitsstrategie.
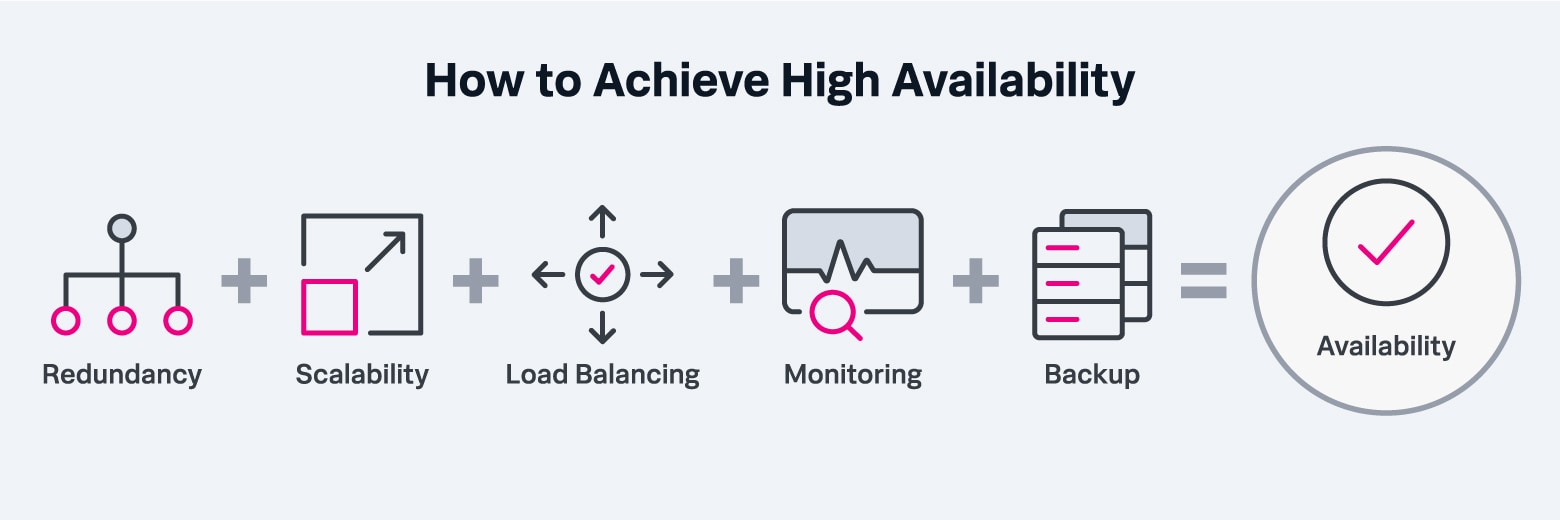
Um Hochverfügbarkeit zu erreichen, benötigt man eine Vielzahl von Werkzeugen, die sicherstellen, dass alle Systeme reibungslos und optimal laufen.
Hochverfügbarkeit im Vergleich zu Fehlertoleranz
Hochverfügbarkeit und Fehlertoleranz sind eng verwandte Themen mit einem wesentlichen Unterschied: Während Systeme mit Hochverfügbarkeit sehr geringe Ausfallzeiten haben, sind fehlertolerante Systeme so konzipiert, dass sie keine Ausfallzeiten haben. Null Ausfallzeit ist möglich, allerdings zu extrem hohen Kosten und mit größerer Komplexität. Fehlertolerante Systeme sind speziell darauf ausgelegt, Fehler zu verkraften — sei es in Hardwarekomponenten, Softwarecode oder anderen Teilen der Infrastruktur.
Fehlertoleranz wird am häufigsten in großen Cloud-Umgebungen implementiert. Amazon AWS, Azure und Google Cloud betreiben beispielsweise mehrere Verfügbarkeitszonen — geografische Regionen, in denen sich Rechenzentren befinden. Durch den gleichzeitigen Betrieb in mehreren Verfügbarkeitszonen kann eine Anwendung fehlertolerant gestaltet werden. Wenn in einer Zone ein Problem auftritt, können mehrere andere Zonen die Arbeit übernehmen. Dieses Design ähnelt dem vieler hochverfügbarer Dienste, ist aber komplexer. Während ein hochverfügbares Design möglicherweise sekundäre Kopien der Anwendung reduziert — beispielsweise die Schreibfähigkeit der Anwendung einschränkt, wenn die primäre Serverinstanz offline ist — tut ein fehlertolerantes System dies nicht. In manchen Fällen müssen exakte Kopien der Anwendung gleichzeitig in jeder Verfügbarkeitszone ausgeführt werden, einschließlich genauer Echtzeit-Kopien aller verwendeten Datenbanken.
- Ein Benutzer in einem hochverfügbaren System, das einen Ausfall erlebt, bemerkt möglicherweise, dass es langsamer ist oder dass bestimmte Funktionen fehlen.
- Ein Benutzer eines fehlertoleranten Systems dagegen wird (theoretisch) keine Veränderung bemerken, unabhängig davon, was im Hintergrund passiert ist.
Allerdings kann selbst das am besten konzipierte System nicht ohne sehr hohe Investitionen – die oft nicht einmal die größten Dienstleister getätigt haben – vollständig fehlertolerant sein.
Die Entscheidung für die Implementierung von Hochverfügbarkeit versus Fehlertoleranz hängt oft von Kosten und der System Kritikalität ab. Ist es überhaupt möglich, auf 26 Sekunden pro Monat zu kommen? Ein realistischeres Ziel könnten drei Neunen sein, also etwa 45 Minuten pro Monat. Sind 26 Sekunden Ausfallzeit pro Monat unter Umständen akzeptabel? Lohnt es sich, diese Ausfallzeit durch eine erhebliche Steigerung der Ausgaben für Cloud-Dienste zu vermeiden? Es stellt sich auch die Frage, wann die Ausfallzeit auftritt. Wenn Benutzer in einem bestimmten geografischen Gebiet konzentriert sind, gilt dann die Anwendung als ausgefallen, wenn es unbemerkt bleibt? Die Antworten auf diese Fragen hängen von der jeweiligen Anwendung und dem spezifischen Risikoniveau des Unternehmens ab.
Hochverfügbarkeit im Cloud Computing
Hochverfügbarkeit ist ein häufig beworbenes Merkmal des Cloud Computings. Da Ressourcen in der Cloud flexibler sind, ist es einfacher und kostengünstiger, ein System mit Redundanz und Lastausgleichsfunktionen zu entwickeln. Im Cloud-Betrieb wird dies durch ein Designfeature namens Cluster ermöglicht. Ein Cluster ist im Wesentlichen eine Gruppe virtueller Server, von denen jeder eine Kopie der Produktionsumgebung enthält. Cluster sind speziell für Lastausgleich und Failover-Funktionen konzipiert. Wenn etwas eintritt, das zum Ausfall einer Anwendung auf einem Server führt, übernehmen die anderen Server im Cluster sofort die Arbeit. In Umgebungen mit hoher Arbeitslast kann ein Cluster Dutzende oder sogar Hunderte von Servern umfassen.
Cloud-Systeme umfassen auch viele andere Punkte der Checkliste für Hochverfügbarkeit, einschließlich integrierter Lastausgleichsfunktionen, nahtloser Skalierbarkeit bei Belastung eines Dienstes, Datensicherungssysteme und mehr – oft als sofort anwendbare Konfigurationsoptionen vom Cloud-Anbieter bereitgestellt. Festgelegte Verfügbarkeitsniveaus sind üblicherweise in den Service Level Agreements (SLAs) von Cloud-Dienstanbietern verankert; fällt die Verfügbarkeit unter das im SLA festgelegte Niveau, könnte der Kunde Anspruch auf eine Rückerstattung oder Gutschrift haben. Es ist jedoch ratsam, die Vereinbarungen sorgfältig zu lesen und zu verstehen, wie der Dienstanbieter die Definition von "Ausfall" interpretiert.
Hochverfügbarkeit in der Architektur des Unternehmens
In der physischen Infrastruktur und Unternehmensarchitektur wird hohe Verfügbarkeit durch den Einsatz redundanter Hardware und spezieller Software erreicht, die für Lastausgleich und Failover-Funktionen konzipiert ist. Speichersysteme können durch den Einsatz gespiegelter Laufwerke und RAID-Arrays hochverfügbar gestaltet werden, wodurch der Speicher auch bei Ausfall einer Festplatte normal weiterfunktioniert. RAID steht für „redundant array of independent disks“, also „redundante Anordnung unabhängiger Festplatten“. Stromversorgungen und Kühlsysteme können redundant ausgelegt werden, sodass eine Einheit bereitsteht, um bei Ausfall der Haupteinheit zu übernehmen. Unterbrechungsfreie Stromversorgungen (USV) und Generatoren können bei einem Stromausfall Notstrom liefern.
Ähnlich wie im Cloud-Beispiel können Clustering und Lastausgleich auch in einer lokalen Umgebung realisiert werden – allerdings zu deutlich höheren Kosten. In diesem Fall laufen mehrere Server (auch als Cluster bezeichnet) parallel, wobei jeder eine Kopie der Datenbank, Anwendungen und anderer erforderlicher Software enthält. Lastausgleichshardware (oder -software) leitet eingehende Anfragen an den Server im Cluster mit der höchsten Verfügbarkeit und verteilt diese Anfragen möglichst gleichmäßig. Dies stellt sicher, dass kein einzelner Server überlastet wird und Anfragen mit maximaler Geschwindigkeit bearbeitet werden. Wird ein Server aus irgendeinem Grund nicht verfügbar, nimmt der Lastverteiler diesen Server automatisch aus der Rotation und verteilt Anfragen auf die verbleibenden Geräte, bis eine Reparatur durchgeführt wird.
Hochverfügbarkeit in der Netzwerktechnik
In der Netzwerktechnik bezieht sich Hochverfügbarkeit darauf sicherzustellen, dass die Netzwerkinfrastruktur betriebsbereit und online bleibt. Die Netzwerkverfügbarkeit ist entscheidend, da sie die physische Lebensader zwischen dem Benutzer und allen Ressourcen darstellt, unabhängig davon, ob diese lokal oder in der Cloud bereitgestellt werden. Wie bei anderen Arten der Verfügbarkeit wird die Netzwerkverfügbarkeit durch den Einsatz von Systemen erreicht, die Redundanz, Lastausgleich und Skalierbarkeit ermöglichen.
Ein hochverfügbares Netzwerkdesign dreht sich um den Einsatz redundanter Netzwerkhardware innerhalb des Unternehmens und oft mehrerer Internetdienstanbieter (ISPs). In einem vereinfachten Beispiel würden zwei Router verwendet, um eine Verbindung zu zwei separaten ISPs herzustellen, was vier mögliche Verbindungskombinationen erlaubt (Router A zu ISP A, Router A zu ISP B, Router B zu ISP A und Router B zu ISP B). Wenn ein Router ausfällt – und wenn ein ISP ausfällt – bliebe die Netzwerkverbindung ununterbrochen. Dies ist ein sehr schlichtes Beispiel; die Topologie für Hochverfügbarkeit kann sehr komplex werden, wenn ein Unternehmen in der Größe wächst – und die Zuverlässigkeitsanforderungen steigen. (Beispielsweise kann man sich dieses Beispieldesign mit zwei ISPs und vier Routern, vier ISPs und acht Routern usw. vorstellen.) Eine Backup-Verbindungsmethode zu haben, ist ebenfalls etwas, das ihr in Betracht ziehen solltet. Ob ihr einen oder zehn ISPs habt, wenn alle Verbindungen durch eine einzelne, anfällige oder beschädigungsgefährdete Leitung gehen, seid ihr gleichermaßen gefährdet.
Allgemeine Vorteile der Hochverfügbarkeit
Hochverfügbarkeit bietet eine Reihe von Vorteilen, darunter:
- Verringertes Risiko: Hochverfügbarkeit reduziert das Risiko, dass Ressourcen aus irgendeinem Grund überhaupt offline gehen, was für die Geschäftskontinuität entscheidend ist.
- Mehr Einnahmen: Verringertes Risiko bedeutet mehr Einnahmen, da umsatzgenerierende Dienste den Benutzern häufiger zur Verfügung stehen.
- Schnellere Wiederherstellung: Falls ein Ausfall eintritt, minimieren Hochverfügbarkeitstechnologien die Zeit, die benötigt wird, um Systeme wieder zum Laufen zu bringen.
- Bessere Kundenerfahrung: Hochverfügbarkeitstechnologien gleichen Lasten aus, sodass keine einzelne Ressource übermäßig beansprucht wird. Dies stellt sicher, dass alle Benutzer in etwa die gleiche Erfahrung machen und kein Benutzer übermäßig lange auf die Erfüllung von Aufgaben warten muss.
- Zufriedeneres IT-Personal: Hochverfügbarkeitssysteme ermöglichen einen entspannteren Wiederherstellungsprozess bei Problemen, was weniger Notfallübungen und zufriedeneres Personal bedeutet.
- Verbesserte Skalierbarkeit: Hochverfügbarkeitslösungen ermöglichen Unternehmen eine einfachere Skalierung bei Bedarf an zusätzlichen Ressourcen durch Hinzufügen weiterer Server zu einem Cluster, sei es physisch oder virtuell.
- Erfüllung von SLA-Verpflichtungen: In manchen Fällen ist Hochverfügbarkeit zwingend erforderlich, da sie durch ein SLA vorgeschrieben ist – entweder mit einem Kunden oder intern vereinbart. Wo solche Dienstleistungsgarantien gelten, muss das Unternehmen Hochverfügbarkeit umsetzen.
Häufige Herausforderungen bei der Umsetzung von Hochverfügbarkeit
Verschiedene Hindernisse können die Umsetzung von Hochverfügbarkeit erschweren und deren Aufrechterhaltung nach der Implementierung zu einer Herausforderung machen. Dazu gehören:
- Hohe Kosten: Hochverfügbarkeit erfordert mehr Hardware und Software sowie zusätzliche Technologie (und höhere Preise) für deren Verwaltung. Die Kostenauswirkungen von Hochverfügbarkeit werden im folgenden Abschnitt erörtert.
- Mangel an erfahrenem Personal: Das Servicemanagement einer Hochverfügbarkeitsumgebung erfordert spezielle Fähigkeiten und Zertifizierungen, die möglicherweise nicht leicht zu finden sind. Der schlimmste Zeitpunkt, um festzustellen, dass die Umgebung nicht richtig konfiguriert wurde, ist nach einem Ausfall.
- Sicherheitsbedenken: Eine Hochverfügbarkeitsumgebung ist nicht besser vor Angriffen geschützt als eine Standardverfügbarkeitsumgebung. Tatsächlich kann sich Malware, die auf einem Server in einem Cluster installiert ist, leicht auf andere Server im Cluster ausbreiten. IT-Mitarbeiter könnten durch die Zuverlässigkeit und Lastverteilungsfunktionen von Hochverfügbarkeitssystemen in falscher Sicherheit gewiegt werden; das richtige Maß an Aufmerksamkeit für Cybersicherheit muss stets aufrechterhalten werden.
- Wahrung der Datenintegrität: Eine der Herausforderungen bei Hochverfügbarkeit besteht darin, sicherzustellen, dass Daten in Echtzeit genau zwischen verschiedenen Datenspeichern repliziert werden; die Verwendung veralteter Informationen in einem Prozess kann zu zahlreichen Fehlern, Datenbeschädigungen und Schlimmerem führen. Die Verwaltung einer einzigen Quelle der Wahrheit für kritische Daten ist in jeder Hochverfügbarkeitsumgebung eine große Herausforderung.
- Selbstgefälligkeit des Personals: Um Reaktionszeiten zu optimieren, müssen IT-Service-Teams regelmäßige DR-Übungen durchführen, um potenzielle Fallstricke vorherzusehen und zu beheben, bevor sie auftreten. Wenn die Infrastruktur relativ widerstandsfähig ist, sodass potenzielle Probleme und deren Lösungen nie diskutiert oder untersucht werden, können Teams Probleme nicht so schnell beheben, wenn sie tatsächlich auftreten.
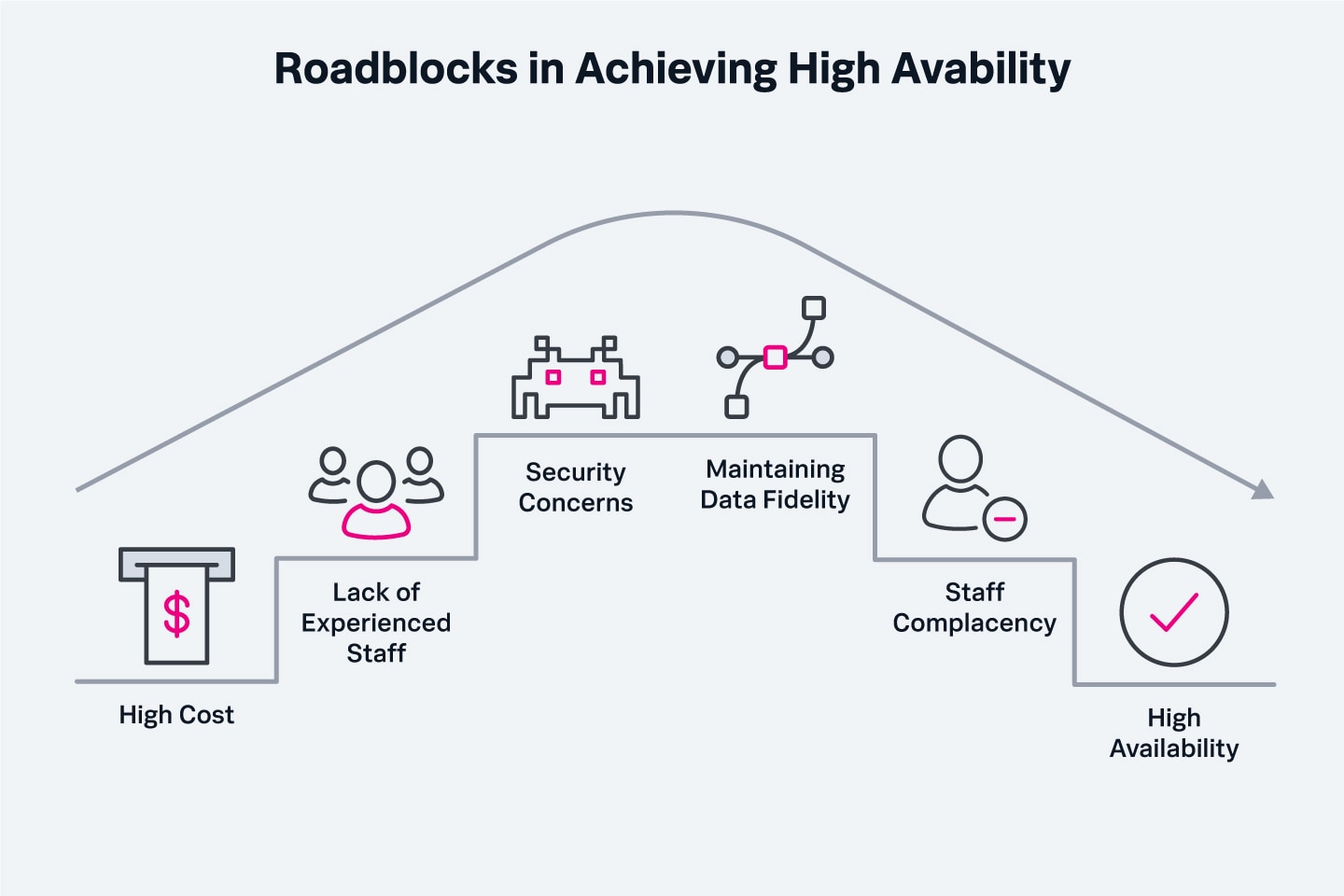
Hindernisse für Hochverfügbarkeit umfassen oft den Faktor Mensch, z. B. Mangel an erfahrenem Personal und Selbstgefälligkeit.
Kostenüberlegungen zur Aufrechterhaltung von Hochverfügbarkeit
Das Erreichen von Hochverfügbarkeit kann kostspielig sein. Zusätzlich zu den direkten Kosten für das Produkt oder den Dienst erfordern Hochverfügbarkeitssysteme mehr kontinuierliche Wartung und Überwachung als herkömmliche Computersysteme – all dies kann erhebliche Auswirkungen auf das Geschäft eurer Organisation haben.
Lohnt sich der erforderliche finanzielle Aufwand für die Verbesserung der betrieblichen Verfügbarkeit? Dies ist letztlich eine Risiko-Nutzen-Rechnung. Das Unternehmen muss die Gesamtkosten von Ausfallzeiten ermitteln und diese mit den Kosten für deren Beseitigung vergleichen. Wenn die Kosten für die Bereitstellung von Hochverfügbarkeitsdiensten zur Begrenzung von Ausfallzeiten die Kosten für Offline-Zeiten (durch entgangene Verkäufe usw.) übersteigen, lohnt sich die Investition in Hochverfügbarkeit möglicherweise nicht. In solchen Fällen kann ein Unternehmen die Kosten für ein gewisses Maß an Hochverfügbarkeit möglicherweise noch rechtfertigen, entscheidet sich aber stattdessen für eine Investition in ein niedrigeres Niveau – beispielsweise vier Neunen statt fünf Neunen.
Verfügbarkeitsüberwachung – Übersicht
Bei der Verfügbarkeitsüberwachung (Availability Monitoring) wird der Status wichtiger IT-Systeme beobachtet, ganz gleich, ob es sich um lokale Services oder um Services in der Cloud handelt.In ihrer einfachsten Form können Verfügbarkeitsüberwachungstools in Echtzeit über den Betriebszeitstatus eines Systems berichten, indem sie einen Dienst in festgelegten Intervallen abfragen, um sicherzustellen, dass er reagiert. Verfügbarkeitsüberwachungstools können jedoch auch verwendet werden, um komplexere Tests zu erstellen, die mehr Informationen liefern und prüfen, ob Dienste von verschiedenen Standorten weltweit aus zugänglich sind, die Reaktionsgeschwindigkeit messen, Fehler melden und die Gründe für Ausfälle ermitteln. Verfügbarkeitsüberwachung funktioniert am besten, wenn sowohl Echtzeit- als auch prädiktive Tools eingesetzt werden, sodass IT-Teams schnell auf Probleme reagieren können, bevor sie katastrophal werden.
Verfügbarkeitsüberwachung ist Teil des Verfügbarkeitsmanagements, eines IT-Prozesses zur Überwachung und Verwaltung von IT-Diensten – von der Planung und Implementierung bis hin zum Betrieb und zur Berichterstattung. Schlechte Verfügbarkeit kann massive Auswirkungen auf das Unternehmen haben, und in den meisten Organisationen bedeutet dies direkte Einbußen bei Umsatz und Rentabilität, unzufriedene Kunden und Reputationsverlust. Zu den bewährten Methoden zur Sicherstellung hoher Verfügbarkeit gehören das Verständnis der Hauptrisikoquellen aufgrund potenzieller Ausfälle im Unternehmen, die Implementierung eines regelmäßigen Stresstestplans und der Einsatz von Automatisierung, wo immer möglich.
Verfügbarkeitsüberwachung versus Verfügbarkeitsmanagement
Verfügbarkeitsüberwachung ist eine Praktik innerhalb des Verfügbarkeitsmanagements, die den Prozess der Planung, Analyse, des Betriebs und der Überwachung eines IT-Dienstes umfasst. Das Ziel des Verfügbarkeitsmanagements ist die Gewährleistung hoher Verfügbarkeit und stellt eine umfassendere Disziplin als die Verfügbarkeitsüberwachung dar. Die Praxis geht über die bloße Überwachung der Verfügbarkeit eines Dienstes hinaus und zielt darauf ab, die Verfügbarkeit des besagten Dienstes aktiv zu verbessern.
Verfügbarkeitsmanagement steht in engem Zusammenhang mit einer Reihe anderer IT-Bereiche, darunter IT-Servicemanagement (ITSM), Observability und Anwendungsleistungsüberwachung (APM). Es gibt viele Überwachungslösungen innerhalb der APM, wie synthetische Überwachung, Server-Überwachung, Cloud-Überwachung, Netzwerk-Überwachung und Echtzeit-Benutzerüberwachung (RUM). RUM geht bei der Verfügbarkeitsüberwachung einen Schritt weiter: Es bietet Einblicke in die Benutzererfahrung einer Website oder App, indem es passiv Timing-, Fehler- und dimensionale Informationen über Endbenutzer in Echtzeit sammelt und analysiert.
Darüber hinaus ist das Verfügbarkeitsmanagement Teil des weithin genutzten ITIL-Frameworks, in dem die Standardprozesse und die bewährten Vorgehensweisen zur Optimierung von IT-Services und zur Minimierung der Auswirkungen von Service-Ausfällen festgelegt sind. Wie bei der Verfügbarkeitsüberwachung besteht eines der Ziele des Verfügbarkeitsmanagements darin sicherzustellen, dass das Unternehmen seine Kapazitäten optimal ausnutzt. Das ultimative Ziel des Verfügbarkeitsmanagements ist also die Förderung einer kontinuierlichen Verbesserung.
Die Wichtigkeit der Verfügbarkeitsüberwachung
Verfügbarkeitsüberwachung bietet eine Methode, um sicherzustellen, dass Technologieprodukte und -dienste in Betrieb sind und wie erwartet funktionieren. Für fast jede Art von Organisation ist Technologie die Lebensader des Betriebs. Nehmen wir als Beispiel die Überwachung der Website-Leistung. Wenn die Startseite eines Unternehmens wie Amazon oder Facebook offline geht, wird sich schnell eine Reihe katastrophaler Ereignisse abspielen. Ob es nun eine informative Statusseite gibt oder einfach keine Verbindung möglich ist, Kunden werden sofort verärgert sein, der Umsatz wird faktisch auf Null sinken, und – letztendlich – werden Benutzer zu Alternativen abwandern, was sowohl dem Ruf des Unternehmens als auch seiner finanziellen Gesundheit schadet.
Als Facebook im Herbst 2021 einen Ausfall erlebte (zusammen mit den Schwesterseiten WhatsApp und Instagram), waren die Websites rund sechs Stunden lang nicht erreichbar. In diesem Zeitraum meldeten über 14 Millionen Nutzer, dass sie keine der Apps oder Dienste von Facebook verwenden konnten. Experten schätzten, dass jede Minute Ausfallzeit das Unternehmen umgerechnet ca. 147.210 Euro kostete, was sich an diesem Tag auf etwa 54 Millionen Euro an entgangenen Einnahmen summierte.
Darüber hinaus ziehen Ausfallzeiten Produktivitätseinbußen nach sich, da Unternehmen verpflichtet sind, einen „All Hands on Deck“-Alarm für die IT-Mitarbeiter auszugeben, die alles stehen und liegen lassen müssen, um schnell die nötigen Reparaturen durchzuführen, damit die Services wieder online gehen können.
Zweck der Verfügbarkeitsüberwachung ist es, diese Art von katastrophalen Kosten zu vermeiden und dafür zu sorgen, dass wichtige IT-Services – und nicht nur Website-Endpunkte sondern jede Art von Hardware und Software – in Betrieb bleiben und den an sie gestellten Erwartungen standhalten.
Eine weitere wichtige Funktion der Verfügbarkeitsüberwachung besteht darin, die Einhaltung von Service Level Agreements (SLAs) mit externen Technologieanbietern zu überwachen. Bei Geschäftsbeziehungen mit einem Dienstleister (wie einem Internetanbieter oder Cloud-Technologieanbieter) legt der Vertrag fast immer fest, dass der Anbieter ein Mindestniveau an Verfügbarkeit erreichen muss. Dies wird in der Regel als prozentualer Anteil der Betriebszeit über einen Monat oder einen anderen festgelegten Zeitraum ausgedrückt. Daher ist es für den Kunden ratsam, die tatsächlich erreichte Verfügbarkeit beispielsweise durch Überwachung der Betriebszeit zu verfolgen. Wenn das SLA nicht eingehalten wird – gemessen an der Verfügbarkeitsüberwachungslösung des Kunden – sind Rückerstattungen oder Gutschriften angebracht.
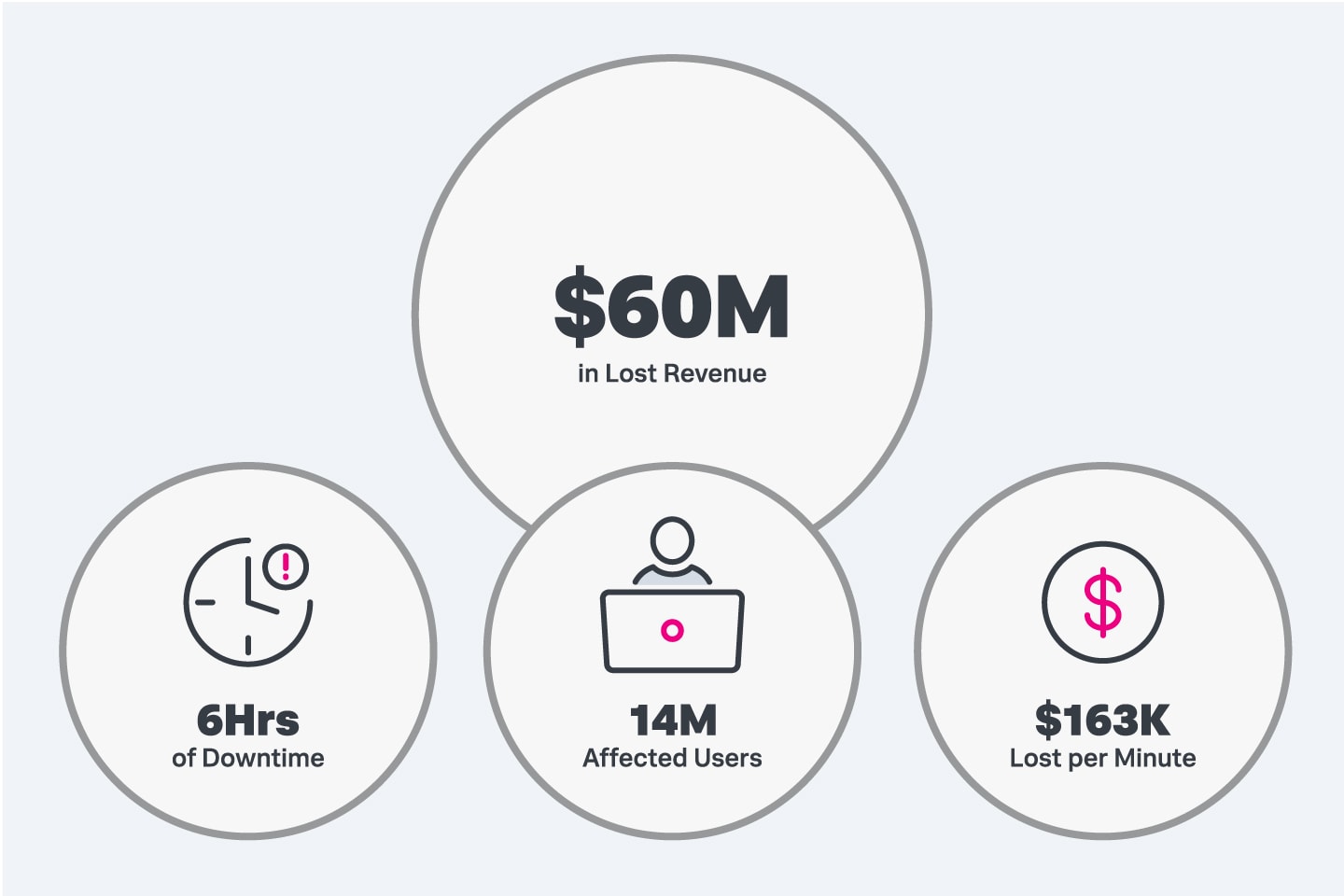
Downtime in Unternehmen führt oftmals zum Verlust von Kunden und beträchtlichen finanziellen Einbußen.
Fazit: Die Sicherstellung der Verfügbarkeit bleibt für Unternehmen von entscheidender Bedeutung
Verfügbarkeit ist eines der wichtigsten Elemente guten IT-Managements, auch wenn Unternehmen von lokalen Rechenzentren in die Cloud migriert sind. Die Bedeutung der Verfügbarkeit wird voraussichtlich weiter zunehmen, da Verbraucher in ihrem Alltag zunehmend auf das Internet und andere Netzwerktechnologien angewiesen sind. Für alle unternehmenskritischen Dienste muss jedes Unternehmen den Einsatz von Hochverfügbarkeitswerkzeugen und -taktiken in Betracht ziehen, um Kundenunzufriedenheit und Umsatzverluste zu vermeiden.
Ihr habt einen Fehler entdeckt oder eine Anregung? Bitte lasst es uns wissen und schreibt eine E-Mail an ssg-blogs@splunk.com.
Dieser Beitrag spiegelt nicht zwingend die Position, Strategie oder Meinung von Splunk wider.
Video: Erfahre mehr über Verfügbarkeit

Ähnliche Artikel
Über Splunk
Weltweit führende Unternehmen verlassen sich auf Splunk, ein Cisco-Unternehmen, um mit unserer Plattform für einheitliche Sicherheit und Observability, die auf branchenführender KI basiert, kontinuierlich ihre digitale Resilienz zu stärken.
Unsere Kunden vertrauen auf die preisgekrönten Security- und Observability-Lösungen von Splunk, um ihre komplexen digitalen Umgebungen ungeachtet ihrer Größenordnung zuverlässig zu sichern und verbessern.

Den Splunk-Blog abonnieren
Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.

