

Gartner Magic Quadrant für SIEM

Die Nachricht der "Sunburst Backdoor" Malware, die über die Orion-Software von SolarWinds verbreitet wurde, hat Unternehmen vor die Entscheidung gestellt, Orion abzuschalten, um sich selbst zu schützen. Das schließt eine Reihe von US-Regierungsorganisationen ein, die der kürzlich veröffentlichten CISA-Empfehlung folgen. Wenn ihr eine ähnliche Maßnahme in eurer eigenen Umgebung in Erwägung zieht, besteht ein wichtiger nächster Schritt darin, die verlorene Transparenz hinsichtlich der Integrität und des Betriebs eurer Infrastruktur wiederherzustellen.
Zu diesem Zweck machen wir euch mit Splunks Funktionen zum Infrastruktur-Monitoring und Troubleshooting bekannt, mit denen ihr einen großen Teil der durch die Abschaltung von Orion verlorenen Transparenz wiederherstellen könnt.
Dieser Blog soll euch einen Leitfaden an die Hand geben, den ihr schnell umsetzen könnt, um mit minimalen Kosten und wenig Aufwand maximale Ergebnisse zu erzielen. Wenn ihr diesen Blog lest, nutzt ihr Splunk wahrscheinlich bereits in eurer Umgebung und setzt den Universal Forwarder in den besonders kritischen Teilen eurer Infrastruktur ein. Vor diesem Hintergrund möchten wir euch die folgenden, sofort umsetzbaren Schritte vorstellen, die euch helfen, mit dem von der Sunburst-Backdoor verursachten Risiko umzugehen:
Wie bei jeder Bedrohung bzw. jedem Angriff im Bereich der Cybersicherheit kommen der Gefahrenerkennung, -eindämmung und -entschärfung die höchste Priorität zu. Die Sicherheitsexperten von Splunk arbeiten unermüdlich daran, Anleitungen bereitzustellen, die euch helfen, Aktivitäten der Sunburst-Backdoor-Malware zu erkennen und euer Netzwerk davor zu schützen. Weitere Informationen dazu findet ihr im Blogbeitrag „Sunburst-Backdoor mit Splunk aufspüren“.
Im weiteren Verlauf dieses Blogs werden wir von einigen Annahmen über eure Umgebung ausgehen, was dazu führt, dass einige mögliche Maßnahmen und Besonderheiten nicht in diesem Blog behandelt werden. Wir gehen davon aus, dass ihr bereits Zugang zu einer Splunk-Umgebung habt, an die ihr Daten senden könnt. Wir gehen davon aus, dass in einem Großteil oder in der gesamten Infrastruktur, die ihr überwachen möchtet, bereits der Universal Forwarder installiert ist. Außerdem gehen wir davon aus, dass ihr Kontakt zu einem Splunk-Admin oder einem Splunk-Team habt, der bzw. das ein gutes Verständnis für die Verwaltung und Bereitstellung neuer Konfigurationen über den Deployment-Server oder andere Methoden hat und euch bei der Umsetzung der in diesem Blog beschriebenen Änderungen unterstützen kann.
In diesem Abschnitt behandeln wir die einzelnen Schritte, welche euch folgende Funktionen ermöglichen:
Wie immer besteht der erste Schritt darin, die erforderlichen Daten in Splunk zu erfassen, um unsere Hosts visualisieren und überwachen zu können. Wir verwenden die Windows- und Unix/Linux-Add-Ons, um Informationen für die einzelnen Hosts zu sammeln. Die Konfiguration dieser Add-Ons wird ausführlich im Abschnitt „Apps und Add-Ons“ unserer Dokumentation behandelt. Wir haben außerdem ein kurzes Videotutorial verlinkt, das die Grundlagen der Erfassung von Windows- und Linux-Daten in Splunk darlegt. Schließlich haben wir Links zu inputs.conf-Beispielkonfigurationen für Windows-Betriebssystemmetriken und -ereignisse sowie für Linux-Betriebssystemmetriken und -ereignisse aufgenommen, die ihr auf den Universal Forwards bereitstellen könnt, um eure Infrastruktur effektiv zu überwachen.
Anzeigen der CPU-, Datenträger-, Arbeitsspeicher- und Netzwerkauslastung für jeden Linux- und Windows-Host in eurer Umgebung.
In der kostenlosen Splunk App for Infrastructure (im weiteren Verlauf als SAI bezeichnet) könnt ihr den Status eurer Entitäten schnell im Untersuchungsbereich in der Kachelansicht einsehen. Ihr könnt zu bestimmten Hosts herunterfiltern oder alle Entitäten in der Anzeige belassen. In diesem Beispiel haben wir „color by cpu.system“ festgelegt, einen Indikator der CPU-Auslastung für Windows- oder Linux-Hosts. Ihr könnt auch einen bestimmten Schwellenwert für cpu.system innerhalb dieser Ansicht festlegen und seht dann, wie die Kacheln rot aufleuchten, wenn ein Host diesen Wert überschreitet.

Zum Visualisieren aller Kernmetriken für einen bestimmten Host klickt ihr einfach auf die Host-Kachel. Beispielsweise auth-01.
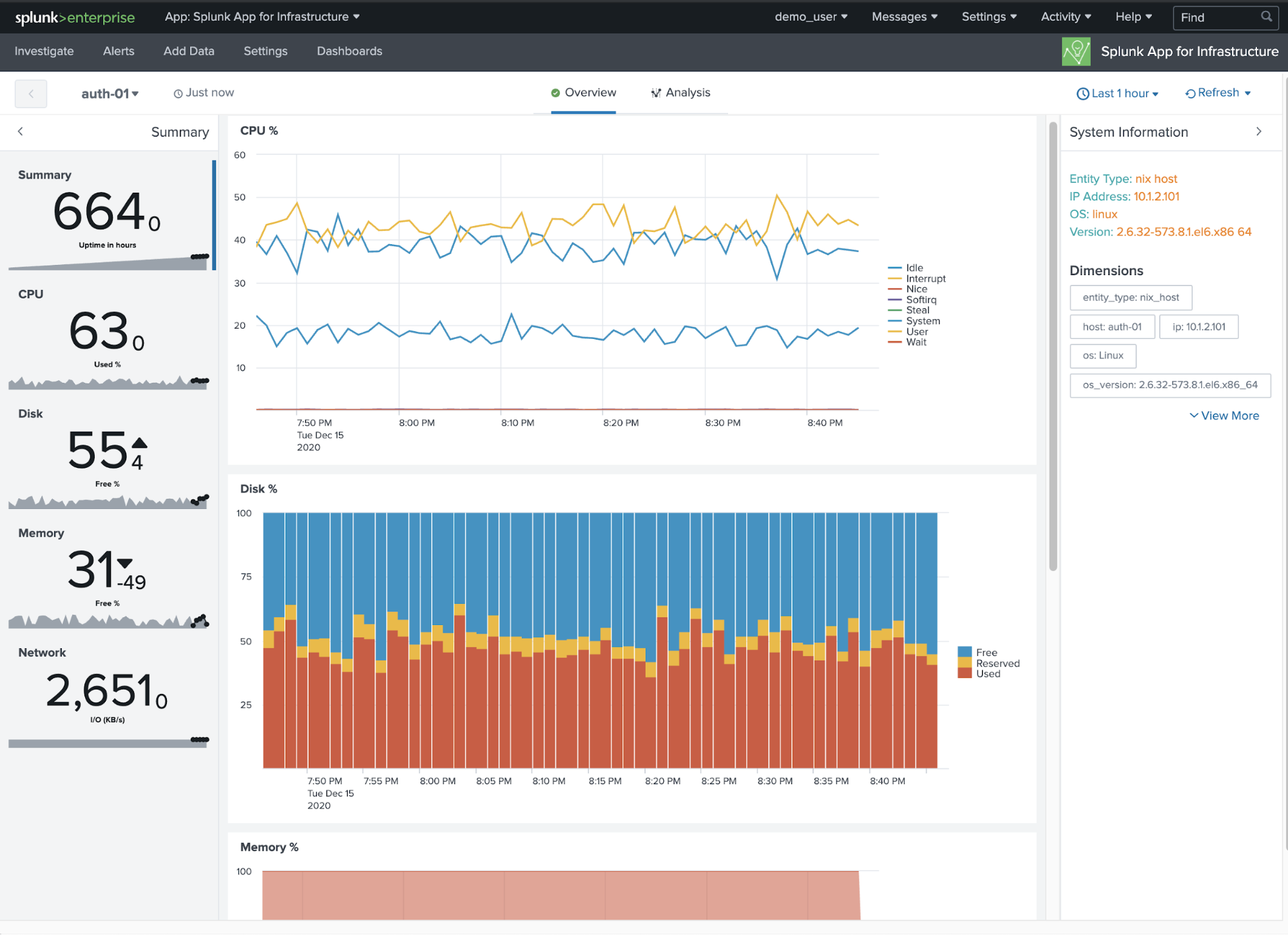
Zwar helfen euch Metriken beim Isolieren der Hosts, die Probleme haben, und auch bei der Frage, wann diese Probleme begonnen haben, es sind jedoch oftmals die Logs und Ereignisse, welche die Informationen enthalten, die wir benötigen, um der wahren Ursache des Problems auf den Grund zu gehen. Verwendet Splunk, um die vom Host kommenden Logs und Ereignisse zu isolieren und nach häufigen Anzeichen für Probleme wie „error“ oder „failed“ usw. zu suchen.
index=* host=* sourcetype=* (error OR fail*) |

Eine hohe CPU-Auslastung kann ein Anzeichen dafür sein, dass der Host Probleme hat. Wenn euer System übermäßig ausgelastet ist, hat es nicht genügend Kapazität, um den CPU-Bedarf zu befriedigen. Verwendet Metriken, um eine hohe CPU-Auslastung zu erkennen, bevor sie sich auf die Systemleistung auswirkt, und lasst euch benachrichtigen, sobald diese Metrik einen festgelegten Schwellenwert überschreitet.
Hinweis: Diese Vorgehensweise kann so verändert werden, dass es zu einer Warnmeldung bei Datenträger- und Speicherauslastung kommt. Verwendet die Suche unten, um alle Metriken anzuzeigen, die in euren Metrik-Inidizes verfügbar sind.
| mcatalog values(metric_name) WHERE index=* |
In diesem Beispiel verwenden wir „% Processor Time“ als unsere Metrik zum Erkennen hoher CPU-Auslastung mit einem Schwellenwert von 95%.
| mstats avg(_value) prestats=true WHERE metric_name="Processor.%_Processor_Time" AND index="em_metrics" AND instance="_Total" span=1m BY host
| stats avg(_value) as cpu_usage BY host
| eval Critical_Usage = if(cpu_usage > 95, "Yes", "No")
| table host Critical_Usage cpu_usage
| where Critical_Usage="Yes"
Speichert dies als Warnmeldung und passt die Auslöseaktionen an.

Beim Monitoring des Gesamtzustands eines Hosts muss überwacht werden, ob ein kritischer Prozess plötzlich nicht mehr ausgeführt wird. Anschließend muss eine Warnmeldung ausgegeben werden, um schnell wieder einen funktionstüchtigen Zustand herstellen zu können. In diesem Beispiel verwenden wir Windows und die Metriksammlung, um zu erkennen, ob ein Prozess in den letzten 60 Minuten ausgeführt wurde, nicht jedoch in den letzten 10 Minuten.
| mstats count WHERE metric_name="Process.Elapsed_Time" AND index IN (*) host IN (*) instance IN ("listCriticalProcessesHere") BY host instance span=1m
| stats sparkline(count, 1m) as trend count min(_time) as earliest_time max(_time) as latest_time by host instance
| eval minutes_since_last_reported_event = round((now()-latest_time) / 60, 0)
| eval alive = if(minutes_since_last_reported_event < 11, "Yes", "No")
| convert ctime(earliest_time) as earliest_event_last60m ctime(latest_time) as latest_event_last60m
| table host instance alive minutes_since_last_reported_event trend count
| where alive="No"

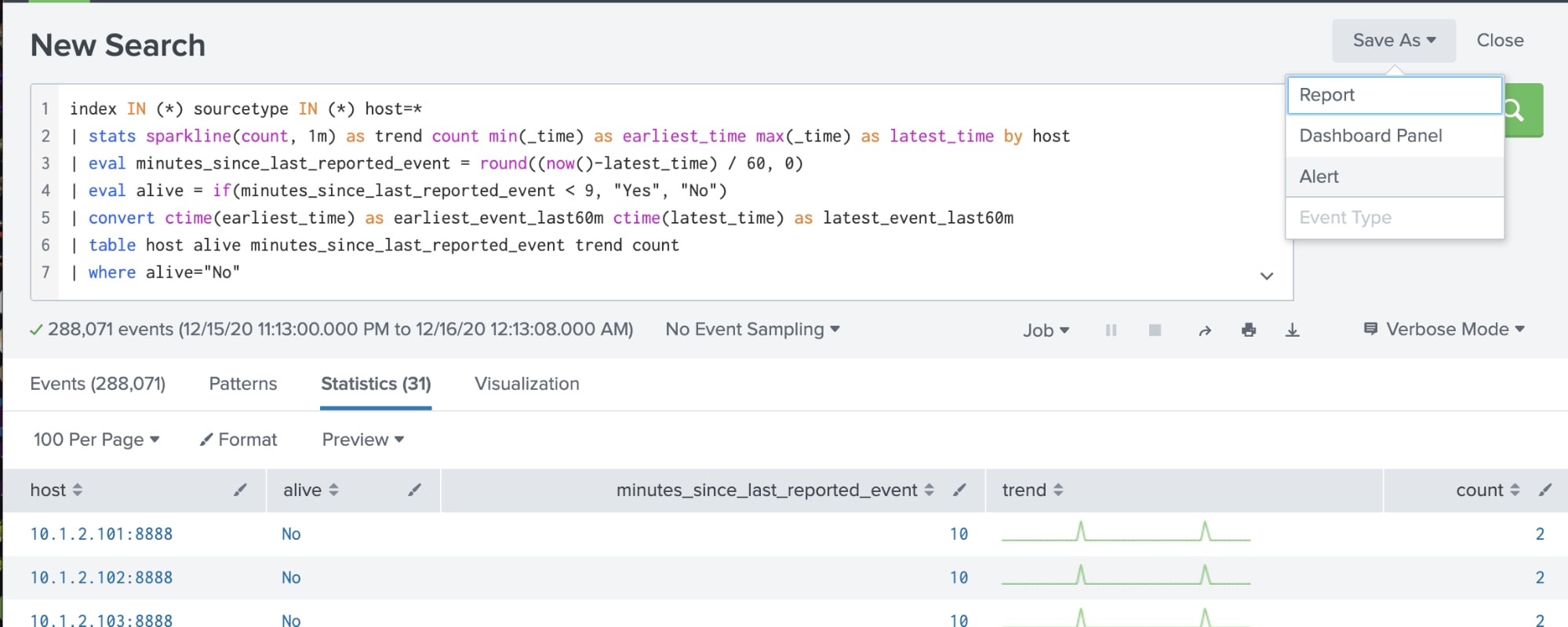
Die einfachste Form des Infrastruktur-Monitorings besteht in der Prüfung, ob ein Host aktiv ist, und in der Generierung einer Benachrichtigung, wenn dies nicht der Fall ist. Es gibt verschiedene Ansätze zum Überprüfen der Hostverfügbarkeit – der Ansatz von Splunk besteht in einem „Heartbeat Check“ für eine kritische Metrik und im Senden einer Warnmeldung, wenn die Metrik aufhört, zu berichten. Tritt dies ein, sendet entweder der Agent keine Daten oder der Host ist offline – beide Probleme erfordern ein Eingreifen.
| tstats count where index IN (*) sourcetype IN (*) host=* by host _time span=1m
| stats sparkline(sum(count), 1m) as trend sum(count) as count min(_time) as earliest_time max(_time) as latest_time by host
| eval minutes_since_last_reported_event = round((now()-latest_time) / 60, 0)
| eval alive = if(minutes_since_last_reported_event < 9, "Yes", "No")
| convert ctime(earliest_time) as earliest_event_last60m ctime(latest_time) as latest_event_last60m
| table host alive minutes_since_last_reported_event trend count
SolarWinds wird oftmals als Syslog-Empfänger, Log-Analyseprogramm und Monitoringlösung für den Netzwerk-Traffic eingesetzt. Splunk kann dabei helfen, diese Funktionen zu übernehmen und stellt eine der schnellsten Möglichkeiten dar, den Datenfluss von den verschiedenen Netzwerkkomponenten im gesamten Netzwerk wiederherzustellen. Das Ziel besteht darin, einen grundlegenden Einblick in diese Geräte wiederzuerlangen, indem der Syslog-Datenverkehr und die SNMP-Traps zur weiteren Analyse an Splunk weitergeleitet werden.
In diesem Abschnitt behandeln wir die einzelnen Schritte, die euch folgende Funktionen ermöglichen:
Der erste Schritt beim Wiedererlangen der Transparenz besteht darin, die notwendigen Daten in Splunk zu erfassen, damit die Netzwerkgeräte visualisiert und überwacht werden können. In diesem Abschnitt behandeln wir die Konfigurationsänderungen, die zum Erfassen von Syslog-Daten und SNMP-Traps in Splunk erforderlich sind.
Da es die Best Practice für Splunk darstellt, empfehlen wir den Einsatz von Splunk Connect for Syslog (SC4S) für das Sammeln der Syslog-Daten. Wenn ihr jedoch mit anderen Methoden der Erfassung von Syslog-Daten vertraut seid, funktionieren diese ebenso. Die Konfiguration von SC4S ist umfassend in dieser Dokumentation dargestellt. Wir empfehlen außerdem die hier verlinkte zweiteilige Blog-Reihe (Teil 1, Teil 2) und diesen nützlichen .conf-Talk, in dem die Grundlagen für den Einstieg in SC4S behandelt werden.
Wir empfehlen, SC4S nach Möglichkeit mit der gleichen IP-Adresse zu versehen, die von SolarWinds für das Sammeln des Syslog-Datenverkehrs verwendet wurde. Dies hilft dabei, eine Neukonfiguration aller Netzwerkgeräte und Firewallregeln zu vermeiden, die erforderlich wäre, um den Fluss des Syslog-Datenverkehrs an einen neuen Syslog-Empfänger zu erlauben.
Zum Sammeln von SNMP-Traps in Splunk müsst ihr einen snmptrapd-Server auf einem Linux- oder Windows-Computer betreiben, um Traps zu erfassen und sie in eine Datei zu schreiben. Sobald sie auf einen Datenträger geschrieben wurden, könnt ihr den Universal Forwarder dafür konfigurieren, diese Dateien zu lesen und sie an Splunk weiterzuleiten. Diese Konfiguration ist hier in unserer Dokumentation skizziert. Dieser Ansatz wurde außerdem ausführlicher in der ersten Hälfte dieses Schritt-für-Schritt-Blogbeitrags behandelt. (Hinweis: Der zweite Teil des Blogs befasst sich mit der Erfassung von Traps in Splunk IT Service Intelligence, was für die in diesem Blog behandelte Netzwerksichtbarkeit nicht erforderlich ist.)
Die Inventarisierung aller Geräte im Netzwerk ist von grundlegender Bedeutung für die Transparenz und Verwaltung des Netzwerks. Sie schafft die Voraussetzungen für Verfügbarkeitsmonitoring und Benachrichtigungen, sollten Geräte das Senden von Daten einstellen.
Hinweis: Schränkt eure Suche außerdem auf die Indizes und Sourcetypen ein, die mit euren Netzwerkgeräten zusammenhängen.
index IN (*) sourcetype IN (*) sc4s_vendor_product=* | stats count by host, sourcetype, sc4s_vendor_product
Wenn ihr den Verdacht habt, dass bei einem bestimmten Gerät Probleme vorliegen, finden sich oftmals Anzeichen dafür in den Syslog-Meldungen. Verwendet Splunk, um die eingehenden Syslog-Meldungen vom betreffenden Gerät zu isolieren und sucht nach Meldungen mit erhöhtem Schweregrad.
Hinweis: Schränkt eure Suche außerdem auf die Indizes und Sourcetypen ein, die mit euren Netzwerkgeräten zusammenhängen. Fügt den Host oder die IP-Adresse des Geräts hinzu, das ihr untersuchen möchtet.
index IN (*) sourcetype IN (*) host= (severity_name IN (emergency, alert, critical, error, warning) OR sc4s_syslog_severity IN (emergency, alert, critical, error, warning)) |

Der Verlust eines Netzwerkhosts in der Umgebung ist offensichtlich ein Problem, das erkannt und vor dem gewarnt werden muss. Indem wir das Vorhandensein von Syslog-Daten als „Heartbeat“ für die Funktionstüchtigkeit des Hosts werten, können wir Splunk so konfigurieren, dass eine Warnmeldung ausgegeben wird, wenn ein Host, der zuvor Daten gesendet hat, dies nicht mehr tut.
Hinweis: Die folgende Suche identifiziert Hosts, die innerhalb der letzten 60 Minuten Daten gesendet haben, nicht jedoch innerhalb der letzten 10 Minuten. Ihr könnt die Werte an eure Bedürfnisse anpassen. Schränkt eure Suche außerdem auf die Indizes und Sourcetypen ein, die mit euren Netzwerkgeräten zusammenhängen.
index IN (*) sourcetype IN (*) sc4s_vendor_product=* | stats sparkline(count, 1m) as trend count min(_time) as earliest_time max(_time) as latest_time by host | eval minutes_since_last_reported_event = round((now()-latest_time) / 60, 0) | eval alive = if(minutes_since_last_reported_event < 11, "Yes", "No") | convert ctime(earliest_time) as earliest_event_last60m ctime(latest_time) as latest_event_last60m | table host alive minutes_since_last_reported_event trend count | where alive="No" |
Wir wollten zwar den Schwerpunkt unserer Anleitung auf das Monitoring von Hosts und Netzwerkinfrastrukturen legen, es ist uns aber bewusst, dass das Monitoring der Anwendungen, die auf dieser Infrastruktur ausgeführt werden, ebenso wichtig ist. Ein großer Teil des Anwendungs-Monitorings, das in SolarWinds verfügbar ist, kann mithilfe der oben beschriebenen Techniken erreicht werden, indem zuerst die Daten erfasst und anschließend visualisiert und als Grundlage für Warnmeldungen verwendet werden. Im Splunkbase App Store von Splunk sind Hunderte von vorgefertigten Anwendungen verfügbar, die ihr installieren könnt, um das Sammeln und Visualisieren von Anwendungsdaten und das entsprechende Benachrichtigen für einige der gängigsten Anwendungen und Infrastrukturen zu unterstützen. Zwar ist es unmöglich, jede einzelne Splunk-App zu nennen, die ihr euch unserer Meinung nach ansehen solltet, jedoch möchten wir euch einige der beliebtesten Splunk-Apps für das Anwendungs- und Infrastruktur-Monitoring vorstellen:
Während einer Krise ist Zeit das A und O. Unser Ziel war es, euch einige Anleitungen an die Hand zu geben, die ihr sofort befolgen könnt, um die verlorene Transparenz der IT-Infrastruktur wiederherzustellen. Unter normalen Umständen würden wir einen ausgereifteren Ansatz für das Infrastruktur-Monitoring vorschlagen. In Anbetracht der tatsächlich vorliegenden Umstände haben wir uns jedoch für einen Ansatz entschieden, der schnell und einfach zu implementieren ist und der eure vorhandene Splunk-Implementierung optimal nutzt.
Euer Erfolg hat für uns bei Splunk oberste Priorität. Wir sind hier, um zu helfen. Wenn ihr nach dem Lesen des Blogs das Gefühl habt, dass ihr weiteren Support benötigt, seid ihr bei uns genau richtig. Wir empfehlen, dass ihr euch an euren Customer Success Manager, Sales Engineer oder Splunk-Kundenberater wendet, wenn ihr unmittelbar Unterstützung bei den oben genannten Empfehlungen benötigt.
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Recover Lost Visibility of IT Infrastructure With Splunk.
----------------------------------------------------
Thanks!
Splunk

Weltweit führende Unternehmen verlassen sich auf Splunk, ein Cisco-Unternehmen, um mit unserer Plattform für einheitliche Sicherheit und Observability, die auf branchenführender KI basiert, kontinuierlich ihre digitale Resilienz zu stärken.
Unsere Kunden vertrauen auf die preisgekrönten Security- und Observability-Lösungen von Splunk, um ihre komplexen digitalen Umgebungen ungeachtet ihrer Größenordnung zuverlässig zu sichern und verbessern.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2025 Splunk LLC All rights reserved.
© 2005 - 2025 Splunk LLC All rights reserved.

