
Wege zum Aufbau erfolgreicher Observability-Praktiken
Wenn wir ehrlich sind, läuft heutzutage vieles unter der Bezeichnung „Observability“. Ihr benötigt ein höheres Budget, um euer Toolset zu modernisieren? Meistens genügt das Zauberwort „Observability“. Wenn das Budget dann genehmigt ist, habt ihr ein Observability-Projekt. Ihr macht euch also auf die Suche nach einer Lösung und stellt schnell fest, dass alle Anbieter die gleichen Formulierungen verwenden und die gleichen Lösungen anbieten. Etwa so: „Wir erfassen Metriken, Traces und Logs, nutzen OpenTelemetry und am Backend bieten wir APM, Infrastruktur-Monitoring, Real User Monitoring, Synthetic Monitoring und so weiter und so fort.“ Kommt euch das bekannt vor? Hat da gerade jemand „Observability-Washing“ gesagt?
Allerdings sind nicht alle Lösungen gleich aufgebaut. Tatsächlich sind sie ganz unterschiedlich, wenn man einen Blick hinter die (architektonischen) Kulissen wirft. Wer genauer hinschaut, entdeckt viele verschiedene Architekturen, und auch bei der Datenerfassung gibt es Unterschiede. In diesem Blogbeitrag möchte ich euch erklären, warum nicht alle Lösungen gleich sind, insbesondere mit Blick auf Unternehmen, die moderne Methoden wie Microservices und Container verwenden. Dies gilt allerdings ebenso für klassische dreischichtige On-Premises-Anwendungen.
Beginnen wir mit dem Architekturdesign. In der Cloud-nativen Welt geht alles ganz schnell. Container oder Funktionen werden erstellt, sie stürzen ab und werden neu gestartet oder gelöscht – alles superschnell. Deshalb braucht ihr eine Lösung, die mit diesem neuen Tempo Schritt halten kann. Wen das interessiert? Auf jeden Fall eure Benutzer. Laut einer 2016 von Google durchgeführten Studie konnte man damals bis zu 53 % seiner Kunden verlieren, wenn Transaktionen länger als 3 Sekunden dauerten. Jetzt stellt euch das 2024 vor! Schnelligkeit ist nicht nur wichtig, um Umsatzeinbußen zu vermeiden, sie kann sogar Einnahmen generieren. Aus einer anderen Studie von Deloitte geht hervor, dass eine Performance-Optimierung der mobilen App von 0,1 Sekunden in einigen Branchen wie dem Einzelhandel einen fast 9-prozentigen Anstieg der durchschnittlichen Auftragsgröße zur Folge haben kann. Und noch ein letzter Aspekt: Wenn eure Website zu langsam und nicht reaktiv genug ist (d. h. nicht konform mit den Google Core Web Vitals), könnt ihr Unsummen für SEO ausgeben und landet trotzdem in den Google-Ergebnissen nicht ganz oben.
Es kommt also auf jede Sekunde an, sogar auf Millisekunden. Das bedeutet, dass ihr fast schon Echtzeitlösungen braucht. Euch muss bewusst sein, dass ihr nach 3 Sekunden bereits Kundschaft verloren habt. Und ihr müsst wissen, ob es ein Speicherleck in Container X gibt, bevor Kubernetes ihn neu startet, um ihn wieder zum Laufen zu bringen.
„Ist das denn wirklich ein Problem? Die Anbieter, mit denen ich gesprochen habe, haben mir erklärt, dass sie nur 15 Sekunden brauchen, um Telemetriedaten, Metriken usw. zu erfassen. Das sollte doch reichen.“ Nein, es reicht eben nicht. Diese Anbieter verheimlichen euch nämlich, was als Nächstes passiert. Daten in 15 Sekunden zu erfassen und in einer Zeitreihendatenbank (Time Series Database, TSDB) zu speichern, ist einfach. Aber es ist auch nutzlos. In diesem Moment verfügt ihr nur über Daten, die euch Geld kosten, aber keinen Mehrwert bieten (keine Benachrichtigungen, kein Reporting, keine Analyse, nichts …). Tatsächlich verwenden die meisten Anbieter Batch-basierte Datenbankabfragen, um diese Metriken und Traces zu „nutzen“ – und diese Methode nimmt viel Zeit in Anspruch (oftmals eine Minute oder mehr). Das bedeutet, dass ihr nicht nach 15 Sekunden eine Benachrichtigung bekommt, sondern erst nach 75! Alles in allem bedeutet dieser „traditionelle“ Batch-Ansatz Folgendes:
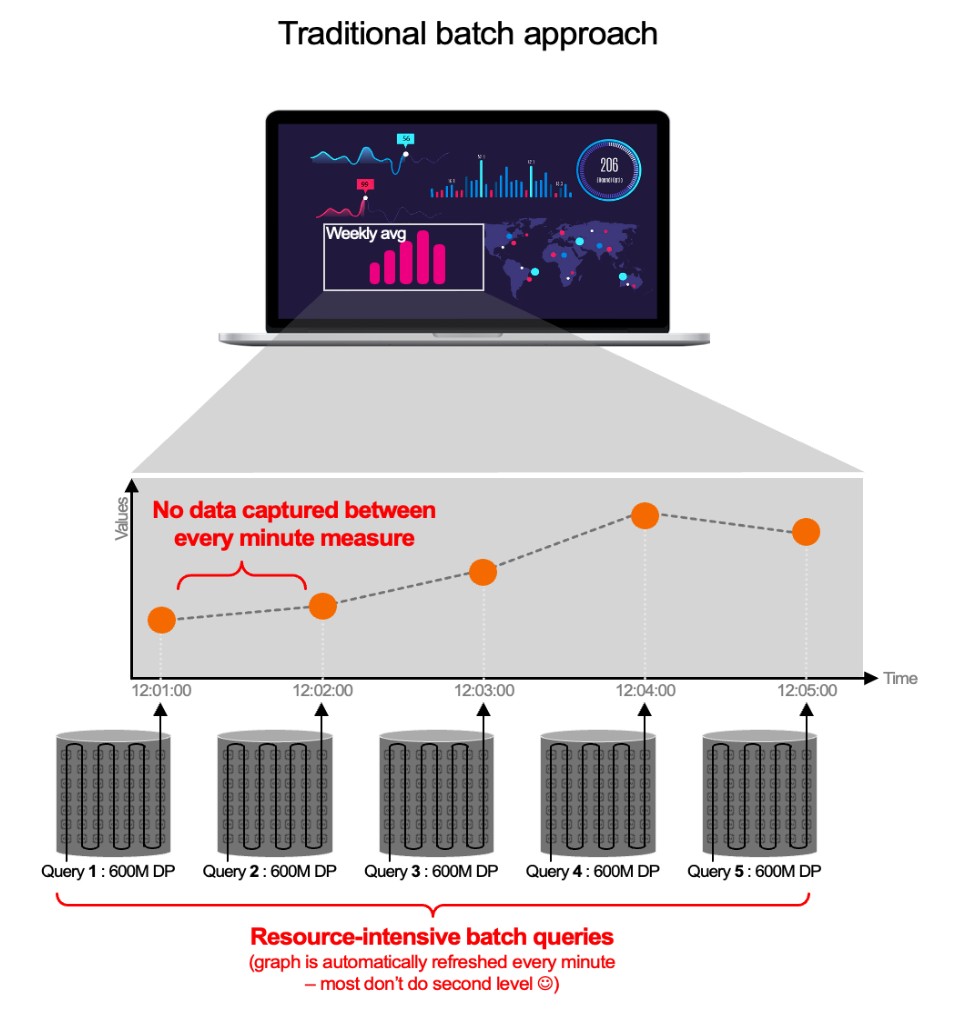 Schauen wir uns ein Beispiel an: „Ich hätte gern die CPU-Daten für meinen 1.000-Container-Cluster für eine Woche mit einer Auflösung von 1 Sekunde.“ Das bedeutet, dass 600 Millionen Datenpunkte (604.800 Sekunden/Woche x 1.000) analysiert werden müssen, um ein einziges Diagramm zu erstellen (CPU).
Schauen wir uns ein Beispiel an: „Ich hätte gern die CPU-Daten für meinen 1.000-Container-Cluster für eine Woche mit einer Auflösung von 1 Sekunde.“ Das bedeutet, dass 600 Millionen Datenpunkte (604.800 Sekunden/Woche x 1.000) analysiert werden müssen, um ein einziges Diagramm zu erstellen (CPU).
Beim herkömmlichen Ansatz muss die Observability-Lösung jede Minute eine Abfrage generieren, die 600 Millionen Datenpunkte erfasst. Hinzu kommt, dass eure Umgebung 59 Sekunden lang „unbeobachtbar“ ist, wenn jede Minute ein Batch verarbeitet wird!
Dies geschieht bei jedem Diagramm (Arbeitsspeicher, IOPs usw.) in einem Dashboard, bei jedem Benutzer usw. Daher müssen viele Abfragen mit 600 Millionen Datenpunkten ausgeführt werden – für moderne Umgebungen wie Container eine ungeeignete Methode.
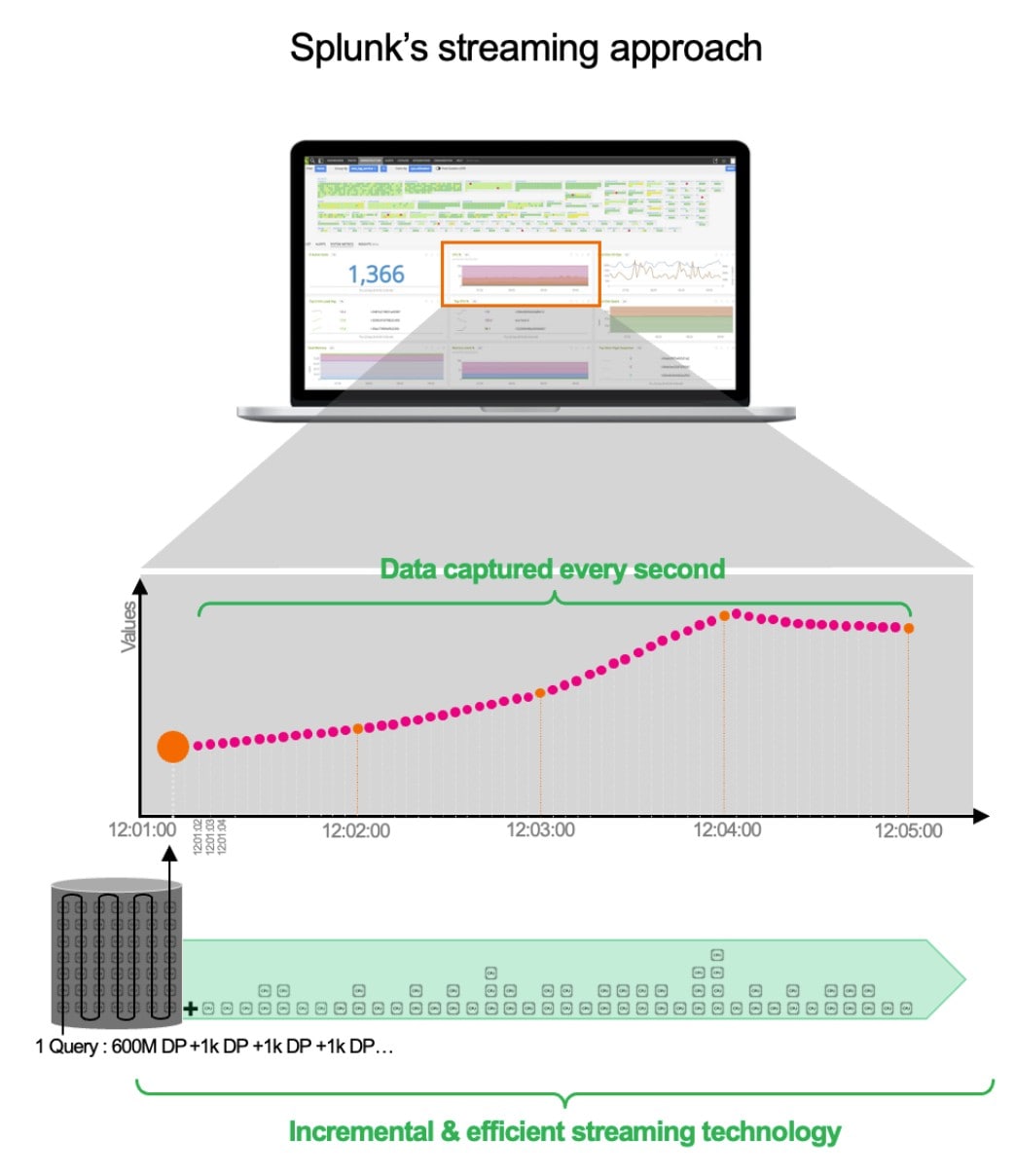
Bei Splunk haben wir uns für eine Streaming-Architektur entschieden. Wenn der Service gestartet wird, müssen natürlich auch wir die ersten 600 Millionen Datenpunkte abrufen, aber wir generieren nicht eine Minute später eine neue große Abfrage. Unsere Abfrage bleibt bestehen. Wir aktualisieren sie einfach jede Sekunde mit neuen Daten (in Schritten von 1.000 Datenpunkten). Diese Methode ist nicht nur effizienter, schneller und besser skalierbar, sondern erfasst auch alles – von ungeduldigen Kunden bis hin zu Funktionen mit Speicherlecks. Aber das ist noch längst nicht alles. Es wird sogar noch besser. Ihr müsst die Ansicht wechseln? Ihr möchtet den Durchschnittswert ermitteln? Keine Sorge. Um noch effizienter zu sein, berechnen wir einige Daten im Backend bereits im Voraus.
Die Streaming-Architektur von Splunk bietet folgende Vorteile:
OpenTelemetry (OTel) entwickelt sich zum De-facto-Standard für die Erfassung von Telemetriedaten. Es handelt sich um eine schlanke Open-Source-Lösung, keine Blackbox wie proprietäre Tools bestimmter Anbieter. Das heißt: Ihr könnt Observability-Daten (Metriken, Traces und Logs) mit einem einzigen Agent erfassen und verarbeiten (transformieren, filtern, anonymisieren, …), bevor ihr sie an das Backend eines beliebigen Observability-Anbieters sendet, der OTel unterstützt. Klingt super, oder? Nutzt ihr einen OTel-Agent und wollt den Backend-Anbieter wechseln? Wollt ihr euer APM wechseln? Kein Problem! Sendet die Daten einfach an den neuen Anbieter und die Sache ist erledigt. OpenTelemetry ist kostenlos und spart in eurer gesamten Umgebung Ressourcen.
Weitere Infos dazu findet ihr auf https://opentelemetry.io/.
OpenTelemetry ist der neue Stern am Observability-Himmel, also will und muss jeder OTel unterstützen. Aber unterstützen bedeutet wie gesagt nicht automatisch, OTel-nativ zu sein. Ihr solltet euch darüber im Klaren sein, dass ihr bei einigen Observability-Lösungen, die OTel unterstützen, deren proprietären Agent hinzufügen müsst. Ansonsten könnt ihr die Vorteile einiger ausgefeilter Backend-Funktionen nicht nutzen.
Bei Splunk haben wir uns für einen gänzlich OpenTelemetry-nativen Ansatz entschieden, bei dem ihr unseren bestehenden Universal Forwarder Agent nicht verwenden müsst. (Falls ihr ihn bereits habt, könnt ihr ihn nutzen, aber erforderlich ist er nicht.) Tatsächlich ist Splunk (gemeinsam mit anderen wie Microsoft, Lightstep, AWS und Cisco oder Unternehmen wie Shopify und Uber) sehr stark in dieses Projekt involviert. Gerade haben wir unsere Zero Configuration für den Otel Collector veröffentlicht. Damit könnt ihr automatisch Services suchen, die in eurer Umgebung ausgeführt werden, und entscheiden, ob sie vom OTel-Agent instrumentiert werden müssen – ganz ohne manuelles Eingreifen.
Fazit: Stimmt schon, jeder bietet Observability an … aber unser Ansatz ist einfach etwas anders. ;)

Weltweit führende Unternehmen verlassen sich auf Splunk, ein Cisco-Unternehmen, um mit unserer Plattform für einheitliche Sicherheit und Observability, die auf branchenführender KI basiert, kontinuierlich ihre digitale Resilienz zu stärken.
Unsere Kunden vertrauen auf die preisgekrönten Security- und Observability-Lösungen von Splunk, um ihre komplexen digitalen Umgebungen ungeachtet ihrer Größenordnung zuverlässig zu sichern und verbessern.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2025 Splunk LLC All rights reserved.
© 2005 - 2025 Splunk LLC All rights reserved.

