
Wege zum Aufbau erfolgreicher Observability-Praktiken

Im digitalen Ökosystem von heute, das sich mit einer unablässigen Innovationsdynamik weiterentwickelt, stehen Unternehmen vor einer doppelten Herausforderung: Neben explosionsartig zunehmenden Datenmengen, die es zu bewältigen gilt, müssen sie auch resilienter werden und dabei kosteneffizienter agieren. Eine überzeugende Lösung hierfür bieten moderne Datenansätze, durch die sich die Nutzung der Splunk-Plattform ausgewogener und im Sinne von mehr digitaler Resilienz gestalten lässt. Tatsächlich ist eine solche Modernisierung in der Tech-Landschaft von heute nicht mehr nur eine Option, sondern strategisches Mandat. Die Gründe hierfür untersuchen wir im Folgenden, um anschließend drei Strategien zu beleuchten, die zu besserer Observability ebenso beitragen können wie zu einer ausgewogeneren Nutzung der Splunk-Plattform.
Moderne Tech-Stacks haben bekanntlich einen gewaltigen Ressourcenbedarf – angefangen bei der zunehmenden Zahl an Services, die es zu überwachen und zu schützen gilt, über immer vielfältigere Cloud-Umgebungen bis hin zu mehr Daten, die in hybriden Architekturen analysiert und korreliert werden müssen. Entsprechend zahlreicher sind somit auch die unvorhersehbaren Fehlerquellen, und nicht zuletzt ist da noch die Vielzahl an Tools, die das Ganze „observable“ bzw. ausleuchtbar machen sollen. Im Dickicht dieser Komplexitäten kann Observability als wichtiger Effizienz-Kompass dienen. Denn sie führt euch nicht nur zu einer ausgewogenen Nutzung der Splunk-Plattform und mehr digitaler Resilienz, sondern verhilft euch auch zu größerer Transparenz, einer kürzeren MTTD/MTTR und besseren Zusammenarbeit zwischen Dev-, Ops- und Security-Teams.
Im klassischen Sinne ist Observability als Konzept in Cloud-nativen Umgebungen verortet. Inzwischen hält das Konzept jedoch auch zunehmend Einzug in Legacy-Komponenten der IT-Infrastruktur, da Unternehmen dessen Mehrwert beim Gewinnen von Einblicken über verschiedene Systeme hinweg erkennen. Dabei gilt jedoch zu bedenken, dass die schnelle, detaillierte Überprüfung im Rahmen von Observability definitiv nicht für alle Daten notwendig ist. Denn je älter Daten werden, desto geringer ist in der Regel ihre Aussagekraft und Relevanz. Deshalb ist ein differenzierter Datenmanagement-Ansatz gefragt. Konkret geht es dabei um die Klassifizierung der Daten nach ihrem Wert: Durch die Unterscheidung zwischen Logs, Metriken und Traces lässt sich sicherstellen, dass wichtige Einblicke priorisiert und keine Ressourcen für weniger wichtige Daten aufgewendet werden. Indem Unternehmen ihre Daten auf diese Weise strategisch organisieren, können sie unabhängig von ihrer Umgebung das maximale Potenzial von Observability-Tools erschließen und dabei tiefgehende Einblicke, Kosten und Ressourcenaufwand optimal in Einklang bringen.
In Echtzeit erhobene Daten – in erster Linie Metriken – stellen spezielle Anforderungen an ihre Handhabung. Dafür bedarf es Use Cases für Observability, bei denen Streaming-Technologien zur zeitnahen Datenerfassung und -analyse zum Einsatz kommen. Was Daten anbelangt, die für Compliance-Zwecke oder die langfristige Aufbewahrung bestimmt sind, so bietet sich dagegen die Ablage in einem kostengünstigen Data Lake an. Durch die Ausrichtung ihrer Datenmanagement-Strategien an Daten-Wert und -Nutzungsmuster können Unternehmen die Ressourcenzuteilung optimieren und ihre Workflows effizienter gestalten.
Auf dem Weg zur Datenmodernisierung gilt es, architekturbezogene Entscheidungen sorgfältig abzuwägen, um maximale Effizienz bei geringstmöglichen Kosten zu gewährleisten. Logs bieten zwar detaillierte Einblicke in das Systemverhalten, doch in Container- oder etwa auch Microservice-Umgebungen, die per se äußerst kurzlebig sind, erweisen sie sich mitunter als ineffizient. So können sie die Erkennung verzögern, wenn Log-basierte Metrikerstellung (Log Metricization) verwendet wird oder Metriken einfach in Splunk Cloud oder Splunk Enterprise übertragen werden. Falls ihr gar nicht vorhabt, diese Cloud-nativen Technologien in großem Umfang einzusetzen, dann könnt ihr euch den Rest dieses Artikel womöglich auch sparen. Unbedingt weiterlesen solltet Ihr allerdings, wenn euch eine der folgenden Herausforderungen bekannt vorkommt.
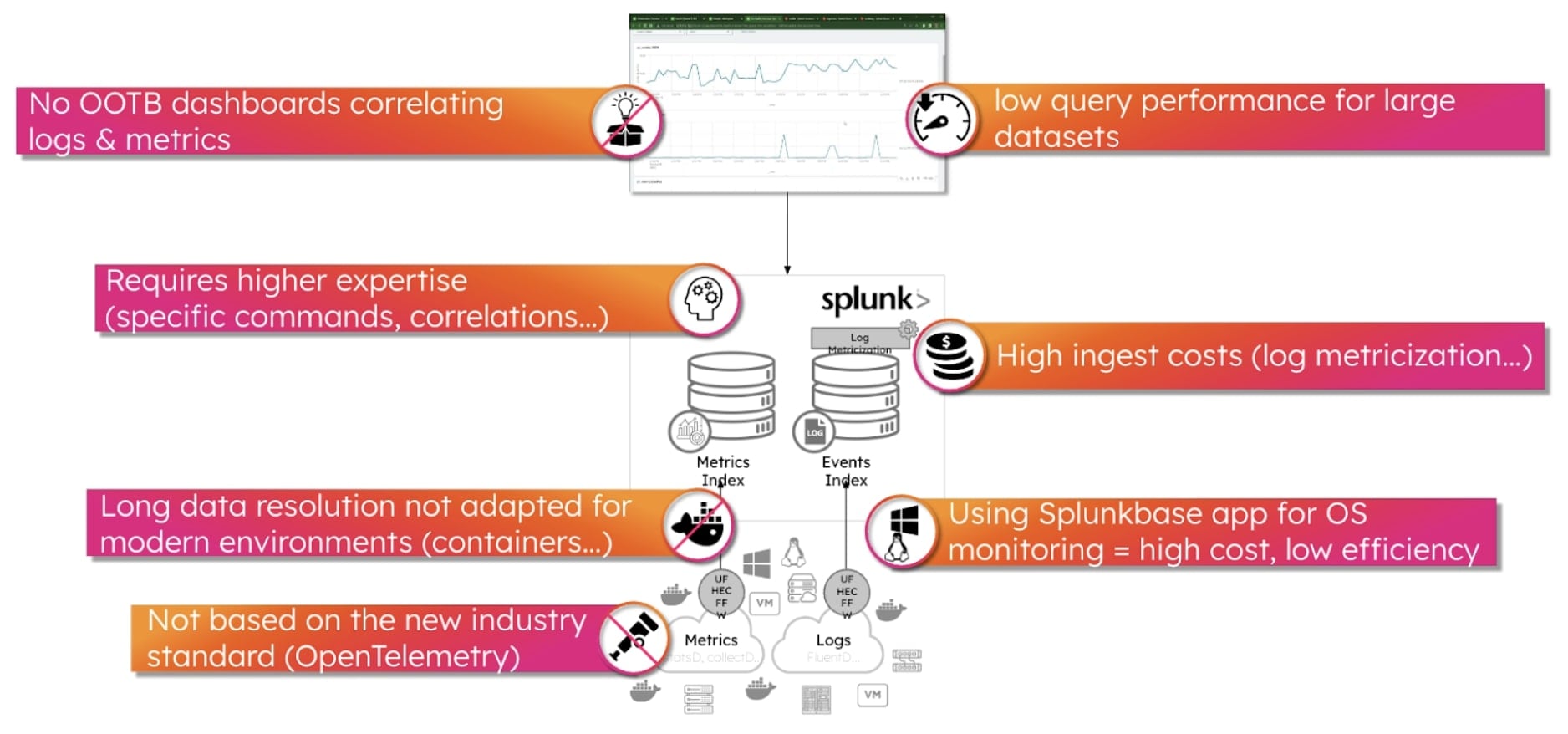
Werfen wir einen Blick auf die drei Optionen, die als Alternative zur Übertragung von Metriken an Splunk Cloud/Enterprise und die Nutzung der Log-Metricization-Funktion bestehen:
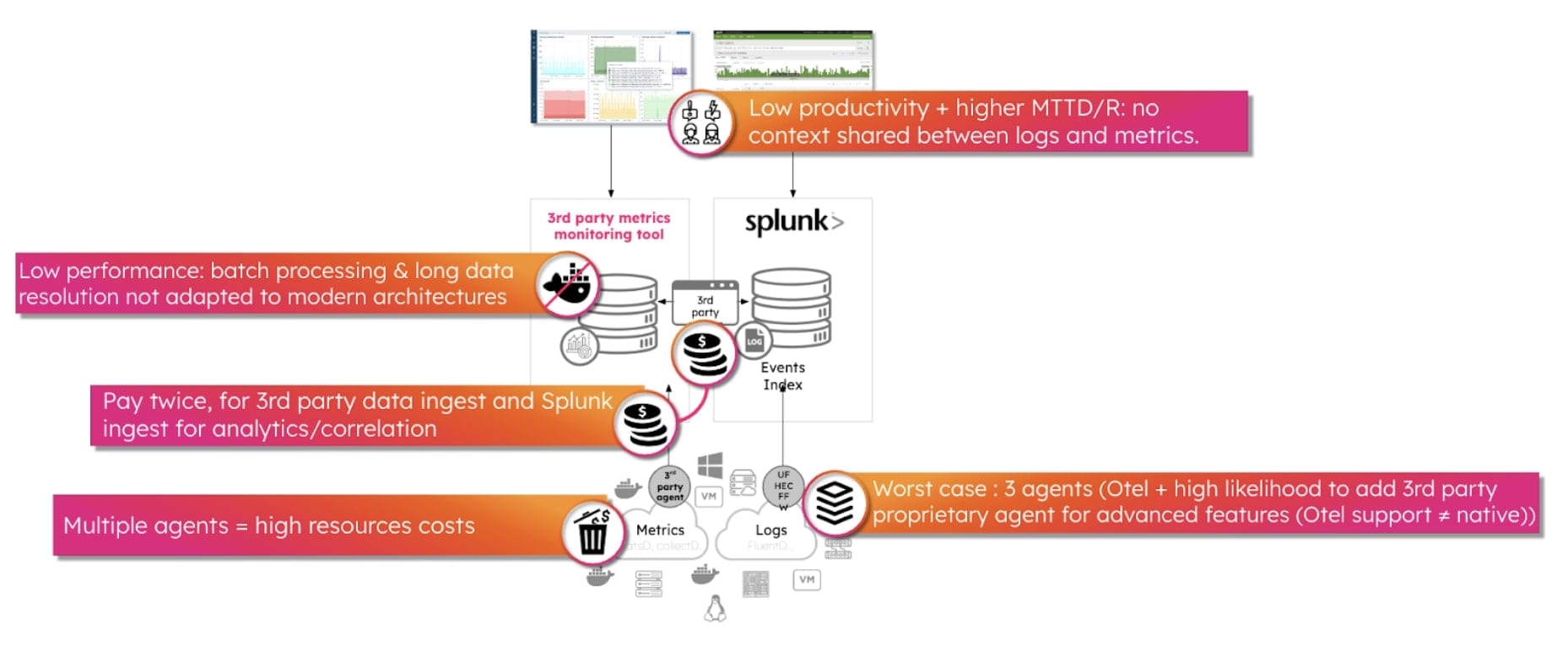
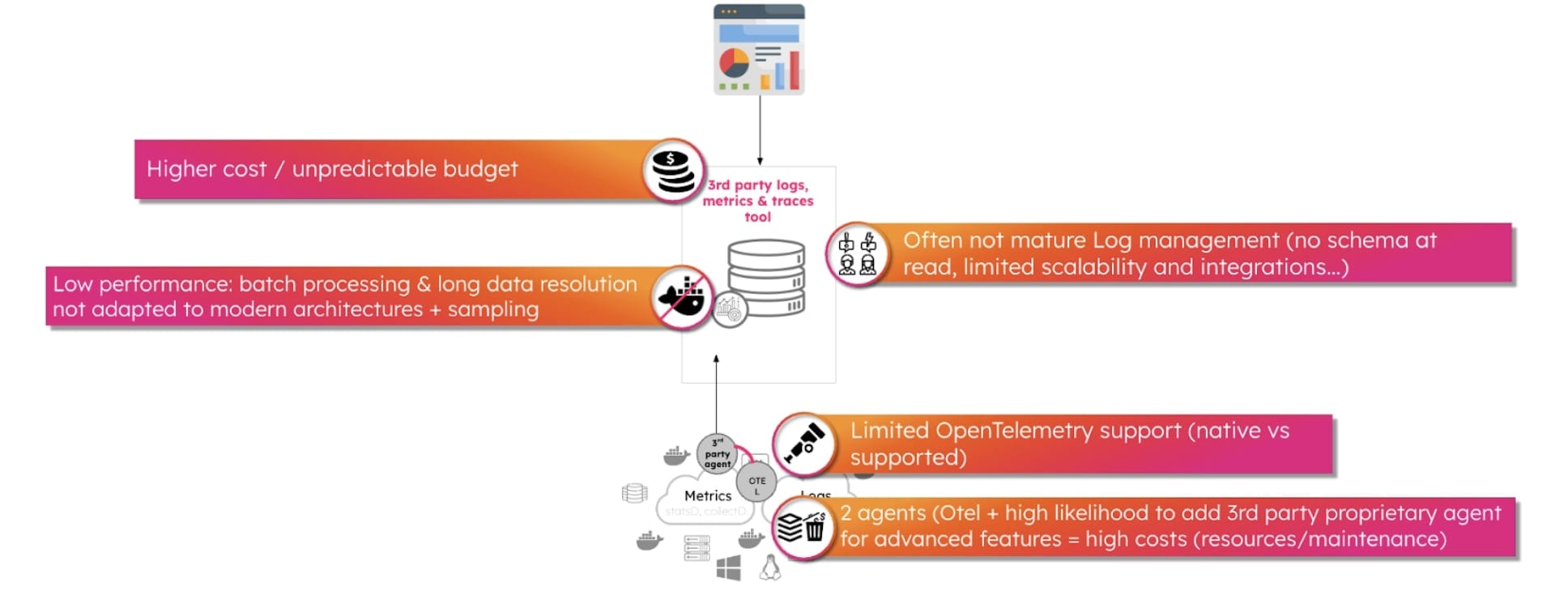
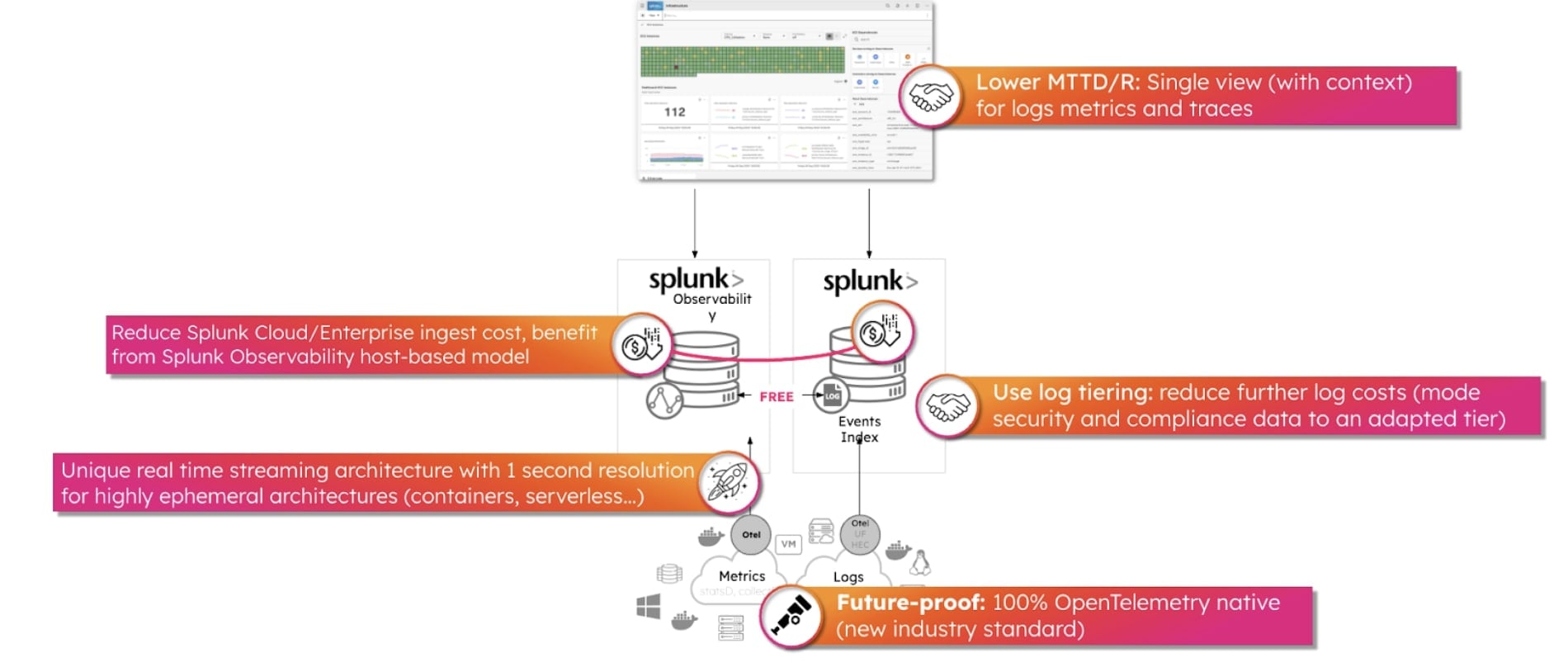
Wie sieht das Ganze aus? Hier ein einfaches Beispiel zur Behandlung von Kubernetes-Fehlern.
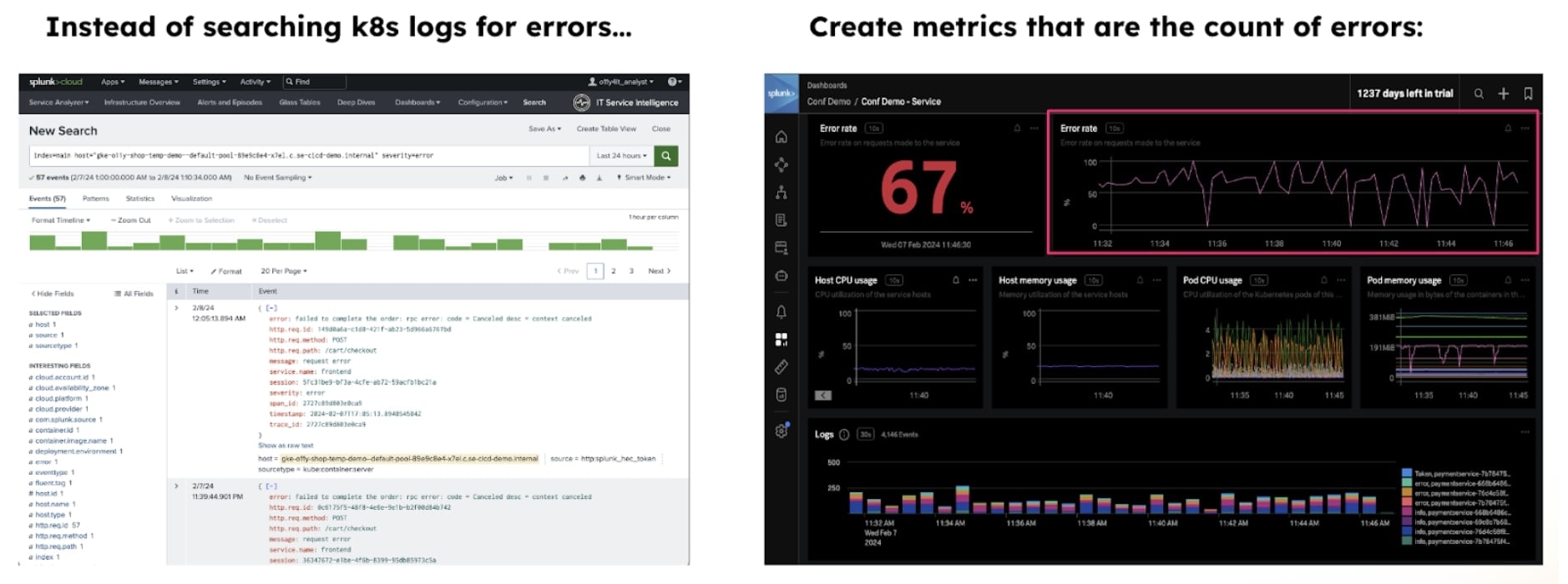
Unter dem Strich ergeben sich auf dem Weg zur Datenmodernisierung reichlich Potenziale zur Optimierung der Effizienz, Resilienz und Kosteneffizienz – die Nutzung des passenden Tool und des richtigen Geschäftsmodells (hostbasiert vs. volumenbasiert) vorausgesetzt. Unternehmen, die auf Observability und strategische Datenklassifizierung in Verbindung mit fundierten Architekturentscheidungen setzen, können die Komplexität moderner Tech-Stacks sicher meistern und das volle Potenzial ihrer Datenbestände ausschöpfen.
Bleibt am Ball – und freut euch auch künftig auf weitere spannende Einblicke dazu, wie Ihr eure Datenstrategie optimieren könnt.

Weltweit führende Unternehmen verlassen sich auf Splunk, ein Cisco-Unternehmen, um mit unserer Plattform für einheitliche Sicherheit und Observability, die auf branchenführender KI basiert, kontinuierlich ihre digitale Resilienz zu stärken.
Unsere Kunden vertrauen auf die preisgekrönten Security- und Observability-Lösungen von Splunk, um ihre komplexen digitalen Umgebungen ungeachtet ihrer Größenordnung zuverlässig zu sichern und verbessern.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2025 Splunk LLC All rights reserved.
© 2005 - 2025 Splunk LLC All rights reserved.

