옵저버빌러티
Splunk 인프라 모니터링
온프레미스, 하이브리드 또는 멀티클라우드에 상관없이 Splunk는 실시간 모니터링 및 장애 해결을 제공하며, 완전한 가시성과 함께 인프라 성능을 극대화할 수 있도록 지원합니다.
즉각적 시각화
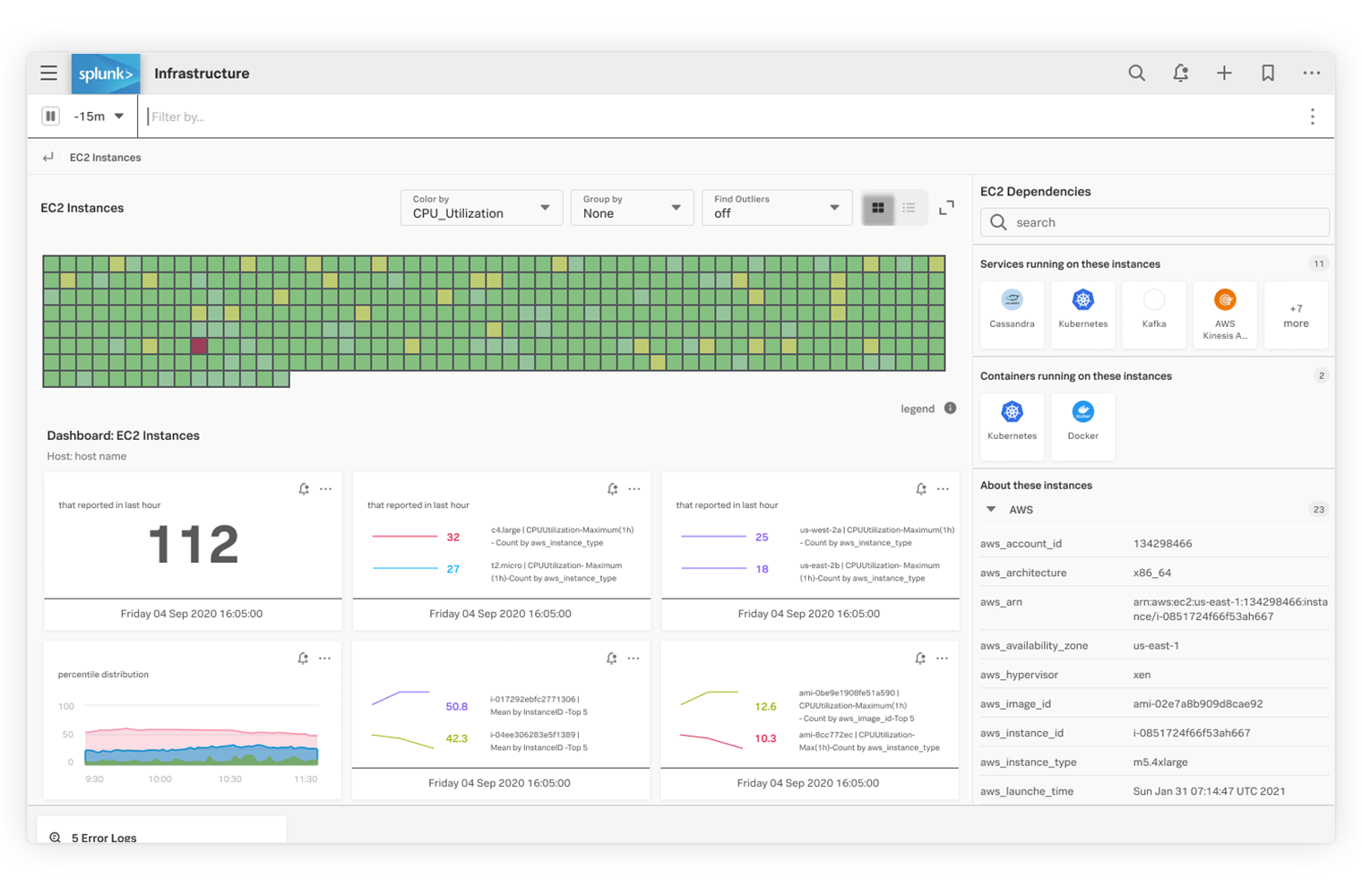
250개 이상의 클라우드 서비스 통합과 사전 구축된 대시보드를 통해 전체 스택에 대한 가시화를 완료하고 빠르게 가치를 실현할 수 있습니다. 또한 몇 분 만에 클라우드, 서비스 및 시스템에 대한 자동 검색, 분류, 그룹화 및 탐색이 가능합니다.
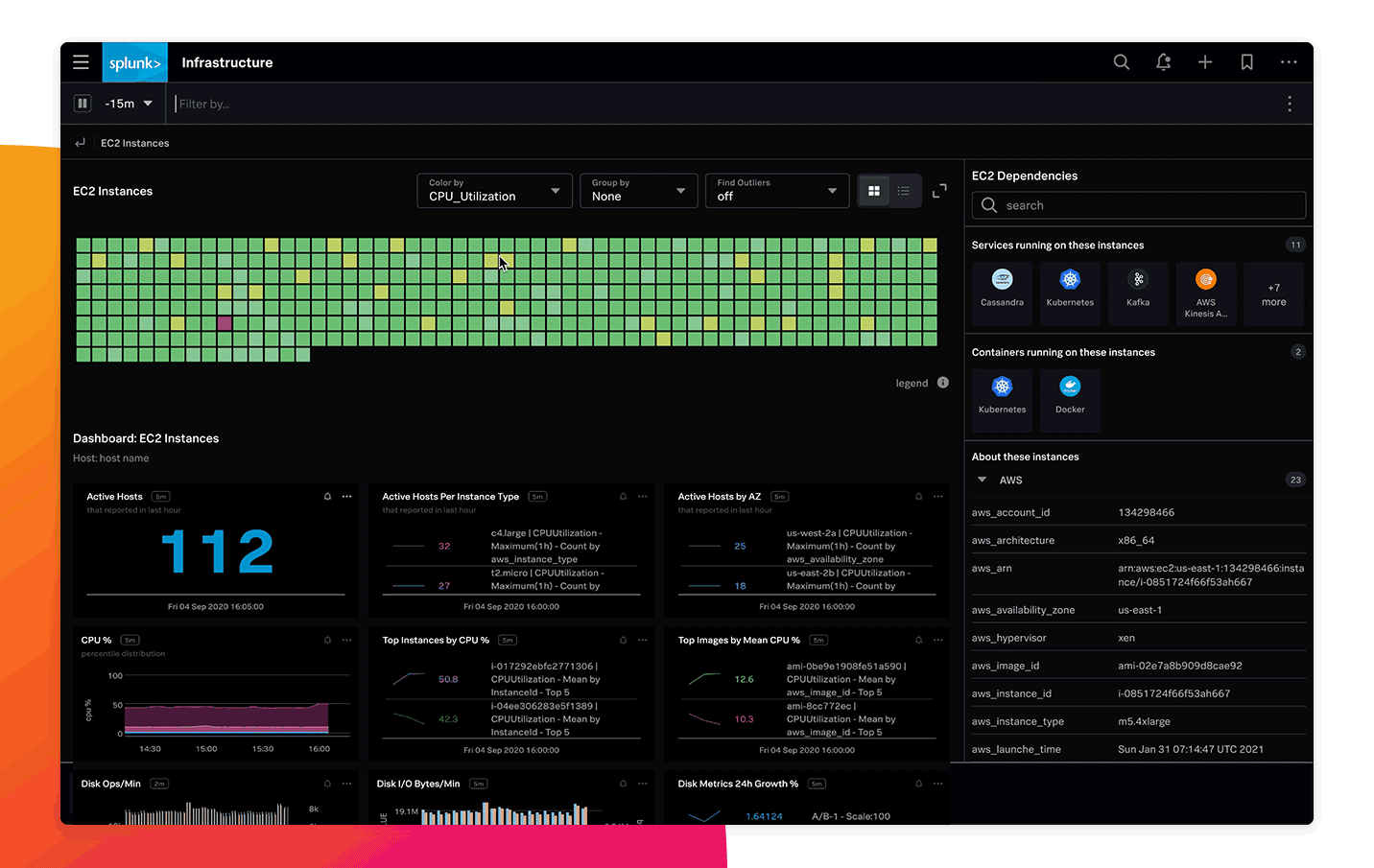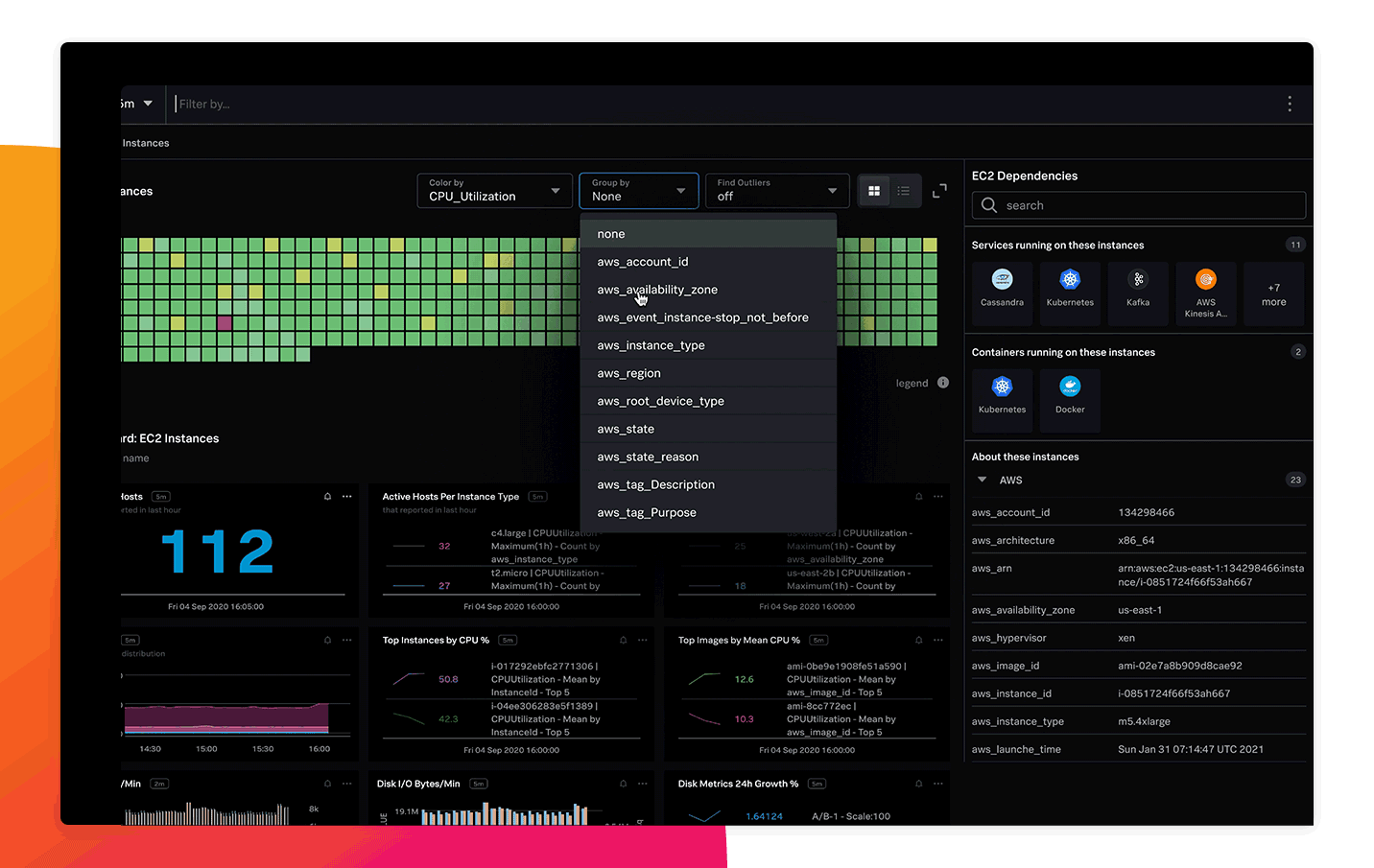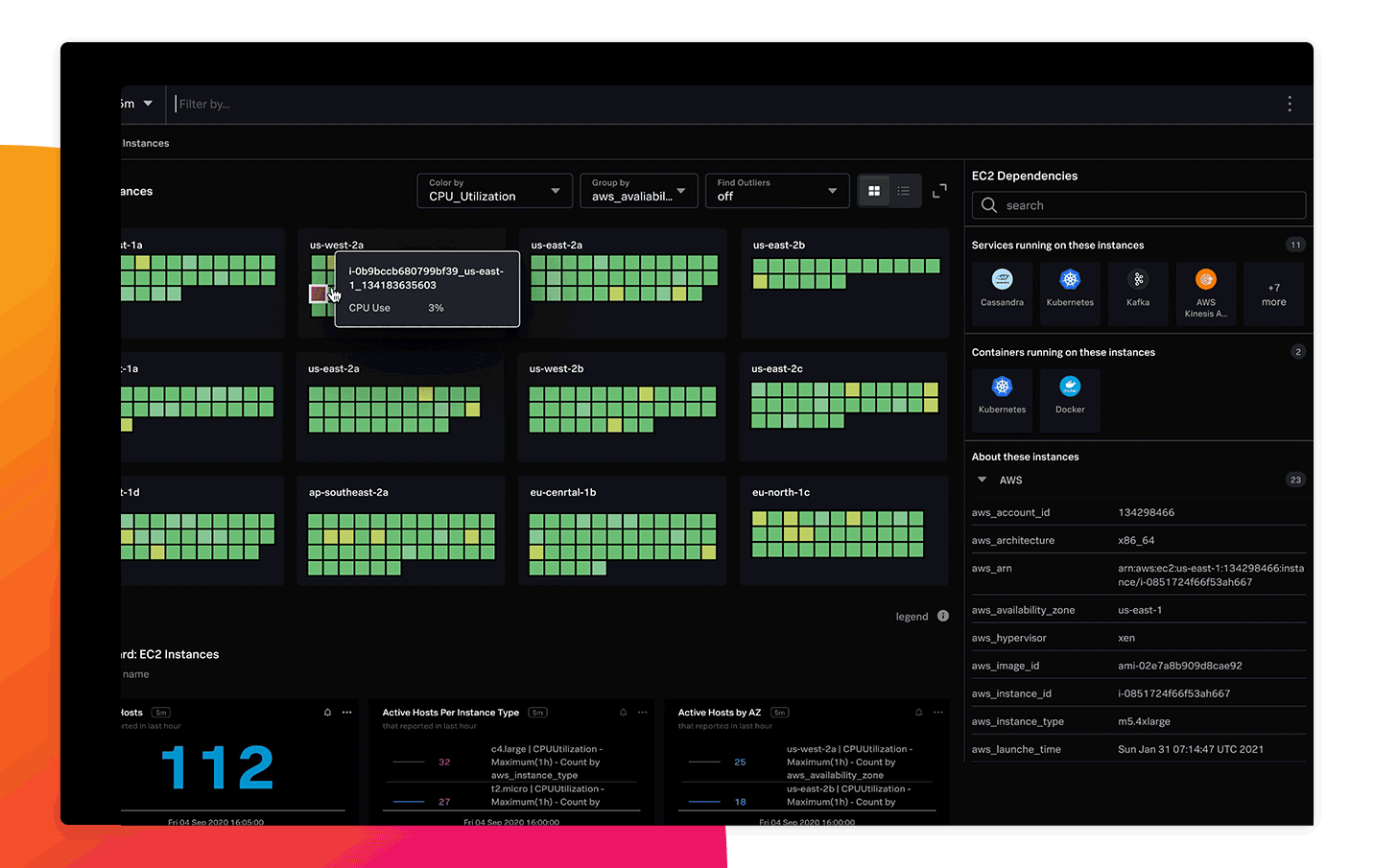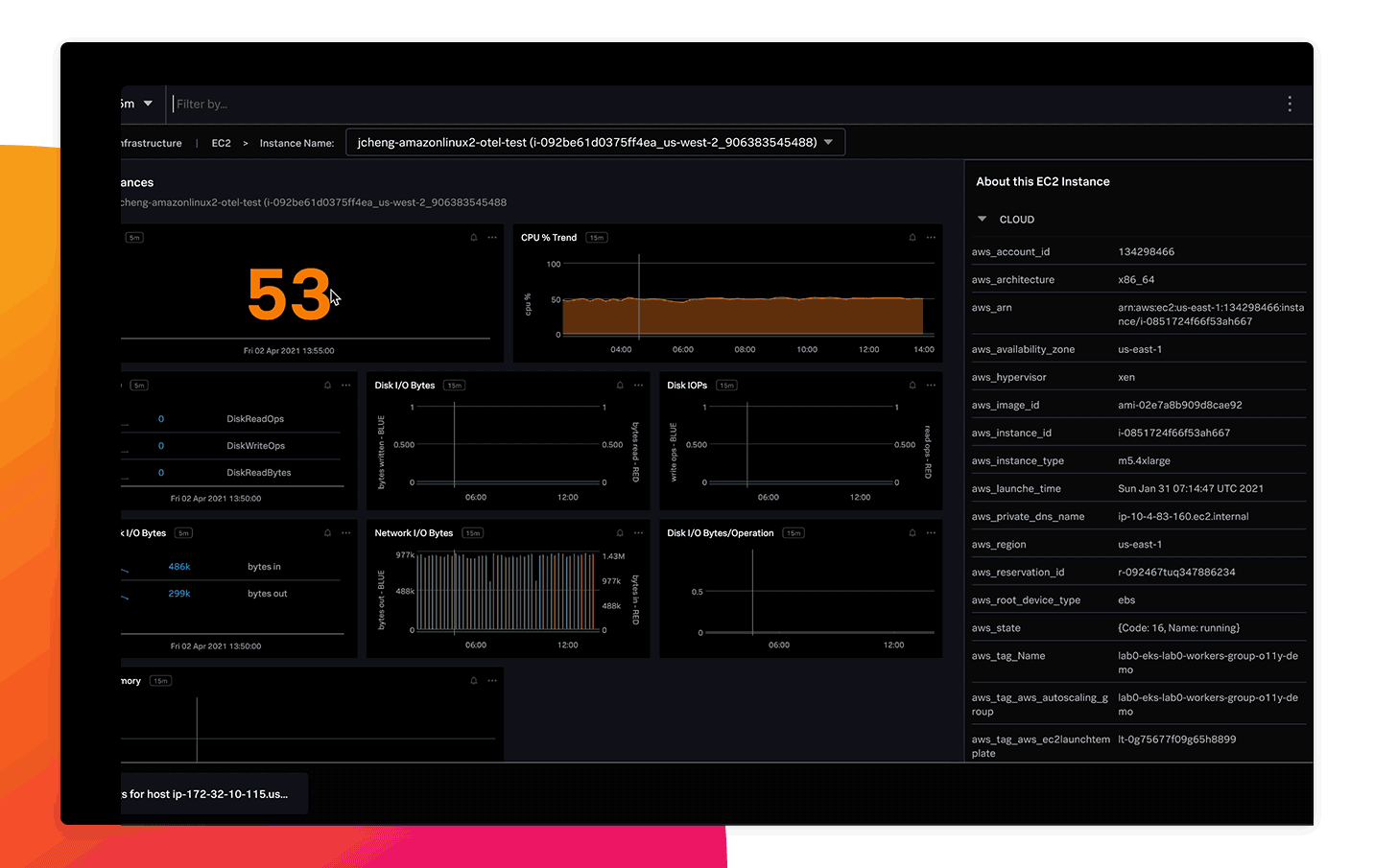
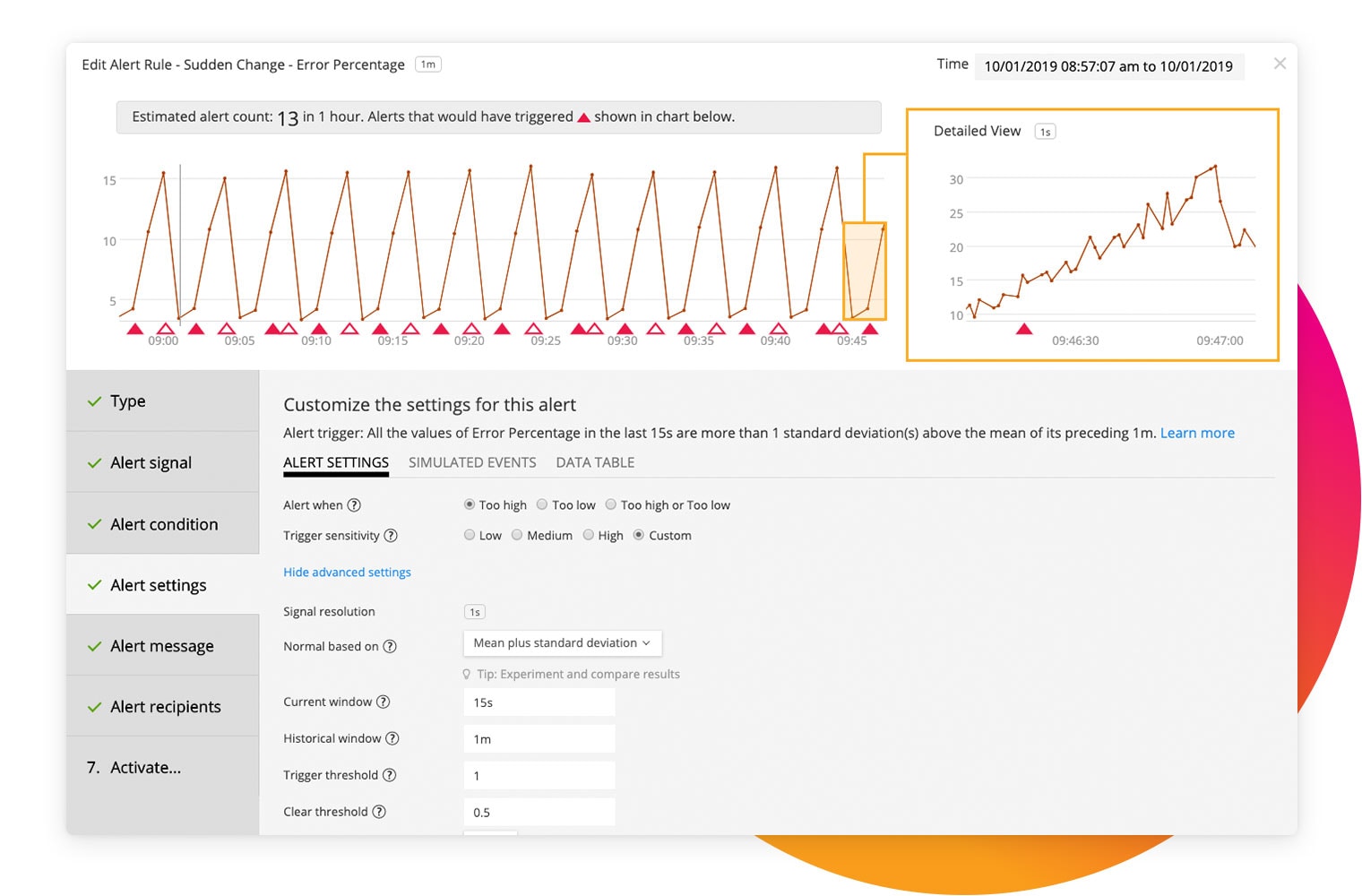
실시간으로 제공되는 실행 가능한 경보
인프라 성능 저하로 최종 사용자 경험에 영향이 악화되기 전에 조치를 취하십시오. 동적 임계값, 여러 조건 및 규칙에 기반해서 문제를 즉시 감지하고 정확하게 경보를 발생시켜, 경보의 수를 줄이고 동시에 평균 탐지 시간 및 수리 시간을 크게 줄일 수 있습니다.
중앙 집중식 전사적 통제
정확한 상황에 기반하여 비즈니스에 중요한 문제에 대응하고, 서비스 수준 목표와 지표를 즉각적으로 모니터링 할 수 있습니다. 비지니스 KPI에 맞춘 커스텀 메트릭스 및 토큰 기반 액세스 및 사용 제어가 가능합니다.
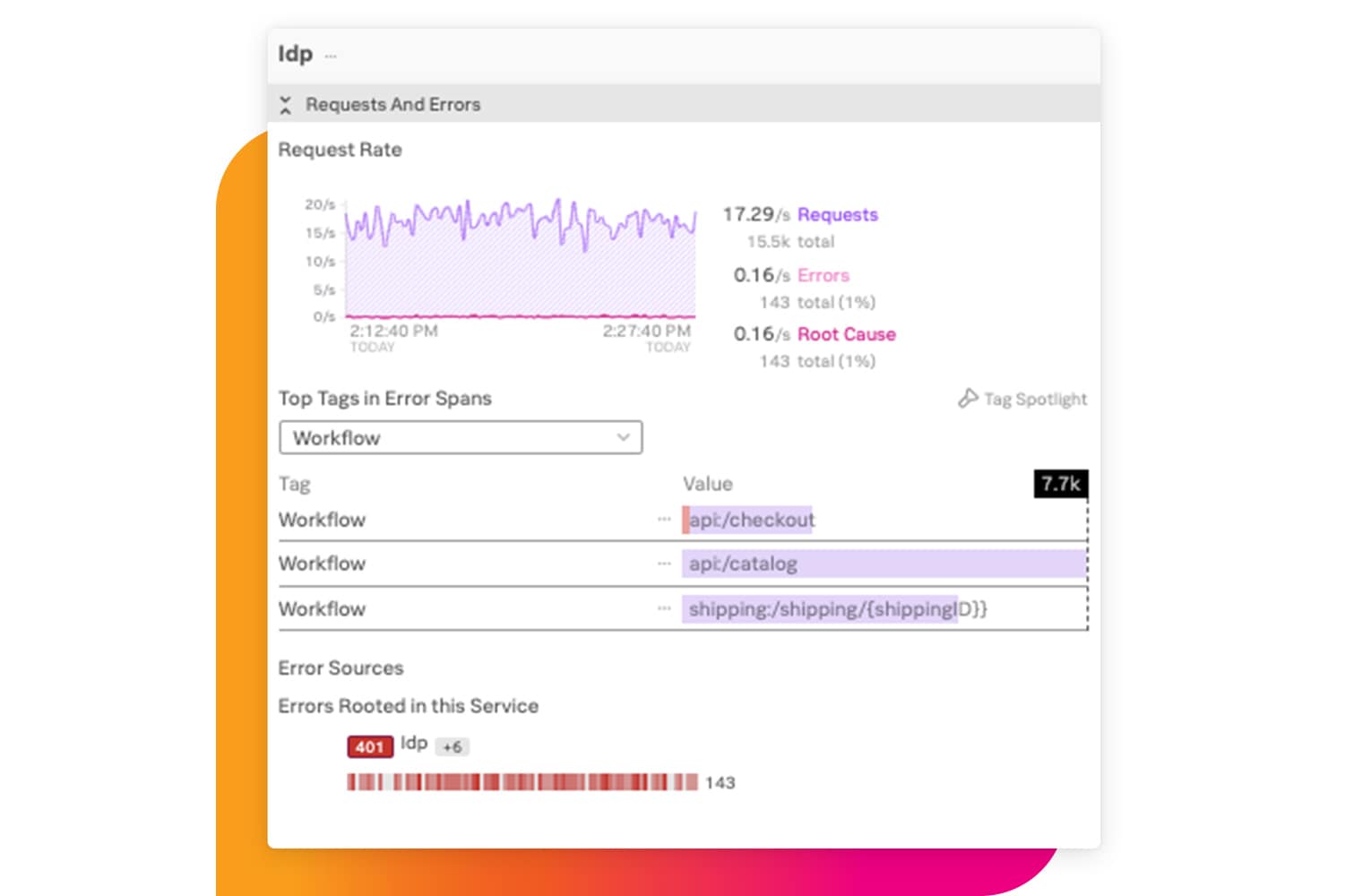
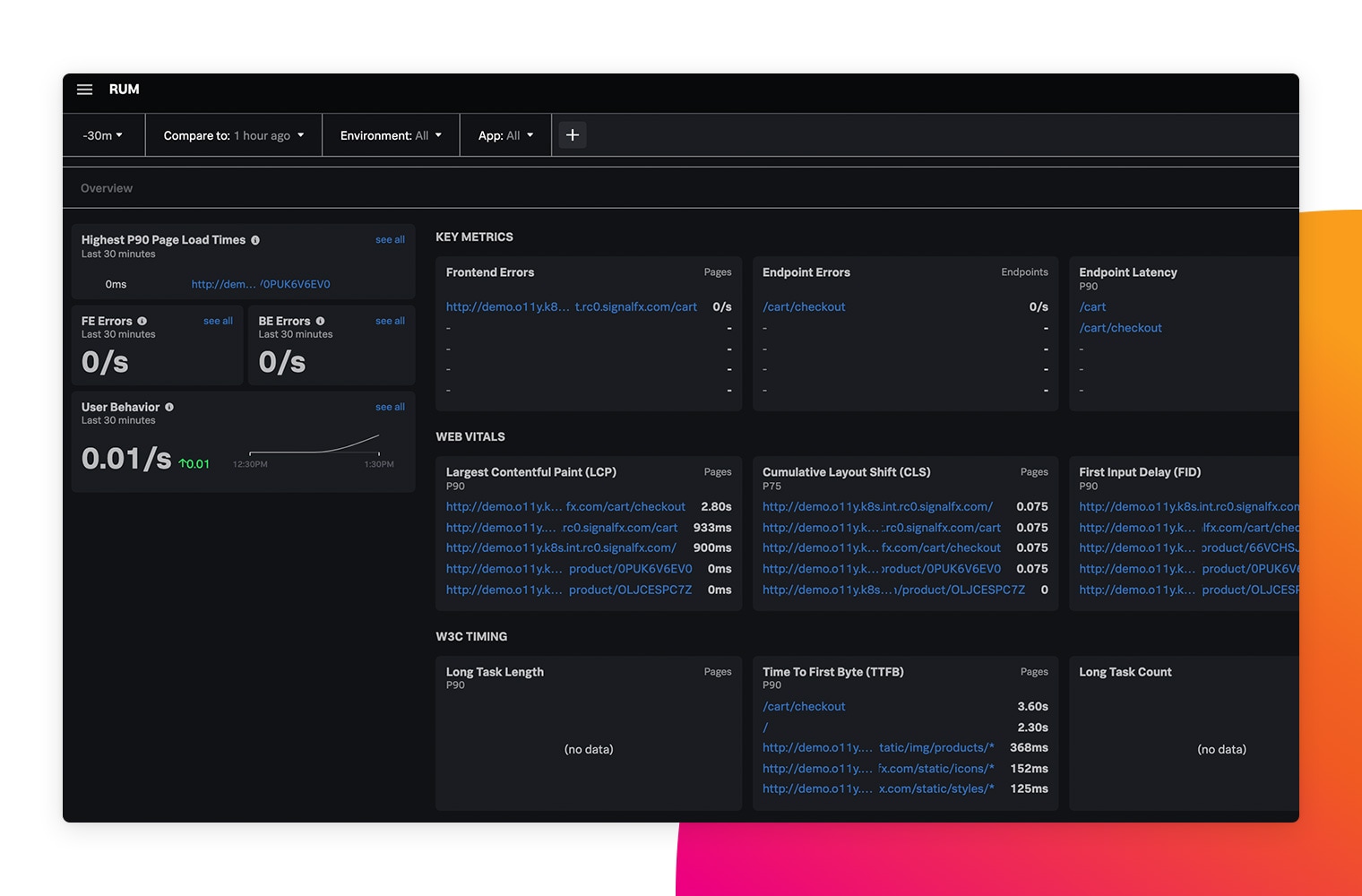
믿을 수 있는 확장성
수천 개의 마이크로서비스와 수십억 개의 이벤트 속에서 발생하는 모든 문제를 빠짐없이 해결하십시오. 메트릭스가 수집되기 전에 내용을 집계할 수 있고, 과거에 사용되지 않은 메트릭 타임 시리즈 정보를 추가하여 단순 모니터링이 아닌 어플리케이선 확장에 집중할 수 있습니다.
기능
하이브리드 인프라 모니터링을 위한 속도, 확장성 및 분석
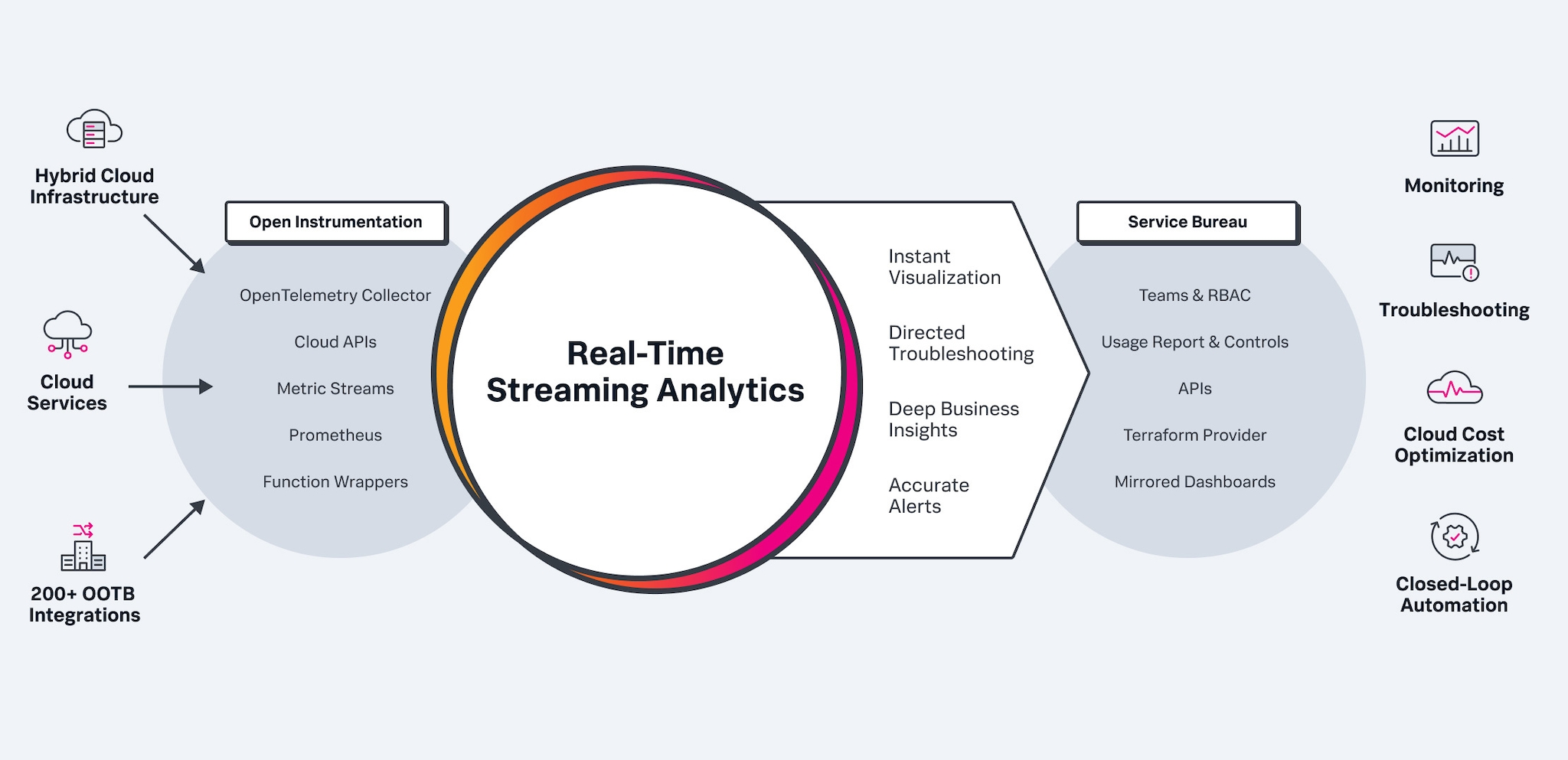
Splunk 인프라 모니터링은 대규모의 실시간 클라우드 모니터링 요건 충족을 위해 특별히 제작된 메트릭 플랫폼입니다.
전체 스택 가시성
하이브리드 인프라와 마이크로서비스 간의 원활한 연계를 통해, 작업자는 문제 상황을 명확히 파악할 수 있으며 다른 맥락이나 상황을 가정하지 않고, 장애 해결을 위해 제안된 방법을 따라 손쉽게 작업이 가능합니다.
실시간 스트리밍 분석
스트리밍 pub/sub 버스를 사용하여 더욱 빠른 분석이 가능합니다. 매초가 중요한 상황에서 스트리밍 아키텍처만이 몇 초 만에 정보를 수집 및 분석하고 경보를 생성할 수 있습니다.
관리의 중앙화
프로그램 가능한 API를 활용한 근본 원인 지향형 모니터링 및 셀프 서비스 배포에 대한 투명성과 전사적 제어를 위해 CI/CD 내에서 모니터 에즈 코드(monitor-as-code) 제공.
로그와 컨텍스트 정보를 활용한 장애 해결
로그 옵저버 커넥트를 통해, Splunk 플랫폼에 수집이 완료된 로그와 실시간 메트릭스를 결합할 수 있습니다. 이제 중앙화된 단일 도구에서 클라우드에 대해 더욱 깊은 인사이트를 확보하고 더욱 빠른 근본 원인 분석이 가능합니다.
즉각적인 Kubernetes 기반 네트워크 가시성
클라우드 네트워크 이슈 발생 시에 추측성 작업을 제거하고 네트워크 중단의 원인과 영향을 쉽게 식별하여 MTTD 및 프로덕션 다운타임 시간을 줄입니다.
고급 쿠버네티스 모니터링
커스텀 대시보드 및 차트를 사용하여 쿠버네티스 오브젝트 및 그 상태와 성능을 자동으로 파악하고 즉시 시각화합니다.

고객 사례
레노버, Splunk 옵저버빌러티로 원활한 전자 상거래 경험 제공
Splunk는 운영 효율을 현저하게 개선하고 더 나은 팀 협업을 실현하기 때문에 Lenovo에게 아주 좋은 투자였습니다. 이 훌륭한 도구 덕분에 운영 팀은 그 어느 때보다도 훨씬 빠르게 문제를 해결합니다.
현재: MTTR 5분 미만
과거: 30분 소요
100% 가동 시간 보장
300%의 온라인 트래픽 증가,