
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Ending up with or having too many tools for monitoring is an age-old problem in the monitoring space. It has been around for decades. In fact I would go a step further and argue that it is much worse within the platforms of today then it was in days gone by. There is a direct correlation between the explosion of new, exciting and innovative technologies and services in modern platform development of today and the sheer volume of tooling you can easily end up with to monitor it.
In this blog I explore what has driven the expansion of tools, how having too many is creating fundamental challenges in how these platforms are being managed, the negative impact that this has on innovation and, most importantly, what the solution is.
First, let’s borrow that DeLorean from 'Back to the Future' - one of my all time favourite films - and transport ourselves back to the early 70s. Here systems were in a large monolith and static as they rarely changed, at least from a hardware point of view. The touch points to these systems were limited and controlled and available to a few rather than the many. It was much easier to monitor them too; one or two tools that specifically provided visibility into the key parts of the system. As we travel to the 90’s/00’s where distributed computing really took off and where systems changed significantly and grew to incorporate the SOA - service oriented architecture - so too did the monitoring needed and therefore the growth of multiple tooling. Each part of these distributed systems needed some form of visibility and thus needed monitoring of some capability.
Getting into that DeLorean again and going back to today (and perhaps a sneak peak at tomorrow), the systems - or platforms - of today are large, distributed, complex and ephemeral. Their size, compared to their counterparts only a few years ago, are extremely large. The tech stack used is wide and varied and could be across multiple cloud providers, with integrations with the classic stack that sits back in the ‘old’ DC. We now live in an app-driven world where everyone relies on them and the touch points to our platforms today are wide, varied and many. User expectations are simple but extremely high - apps should be accessible, work and are performant whenever they need them and poor or error prone experiences cause significant frustration, with users leaving, possibly permanently and some of these users are very vocal on social media about their bad experiences. Check out my blog on why knowing about the front-end and user experience is key to understanding how that platform is performing for more info on this important area of observability.
The use of all this innovative tech has resulted in more tooling. The requirement to have visibility in each tech area has grown and to provide that visibility lots of tools can easily be used. These can range from using those that are free, through to purchasing new tooling specifically for that technology area or directly from the vendor of that technology itself. I have also seen the use of DIY approaches grow too - more on this later on. For those organisations that are moving to become digital native - but also have the classic stack of apps that are still used and connected to these platforms - there might be existing tooling on these classic apps which is then mandated to be used on these new platforms.
Typically, in these organisations there is a tooling team which provides the monitoring tools as a service to other teams in the business. The monitoring is standardised within this central team and then rolled out to the appropriate teams as a standard, which also forms part of their monitoring governance. Any changes or anything else that is needed - perhaps some additional visibility - requires a request to be made to the tooling team who will then analyse this, determine if the changes can be made and then, if in agreement, at some point, make those changes. This approach frequently doesn’t work with the new digital native teams as the process is often too slow, the existing tooling is routed in traditional monitoring approaches and is not fit for purpose for the modern digital cloud native platforms of today. They may also be stretched to fit the requirements of today but with mixed results, similar to fitting a round peg into a square hole. The new platform teams will push back on this approach and will go out and find the tooling that they need to provide visibility into their environments. This easily adds to the collection of monitoring tools within the organisation.
Another factor that has grown considerably in recent years is the use of do-it-yourself approaches to monitoring. These DIY tools are being used to help resolve some of the challenges above and provide the visibility needed for that developer or team for the part of the app or service they build and manage. The idea behind this is to provide better control on what they want to see and have visibility on rather than rely on monitoring tooling that decides what should be collected. Furthermore, the developers are also in control of how the metrics are collected. This approach can allow more control to be put in place as well as the capability to define monitoring standards that could be rolled out across the teams. Whilst this has some perceived monetary savings - no licensing or PS needed for deployment - it is a false economy as there are many hidden costs to this approach.
A key downside to any DIY monitoring approaches is increasing developer toil. What you want the developers to be doing is focusing on building out the next innovative release and writing code as opposed to building and maintaining their own monitoring tooling. Anything like this is time away from building code and will introduce delays into the release cycle process and ultimately innovation to your customers. In extreme cases, it can also lead to recruiting more and more developers into the business to compensate for the loss time due to developer toil.
We have no doubt all heard that ‘single pane of glass’ pitch - either as a pitcher or as an audience member in a pitch! It has been around the monitoring space for decades. Its goal, as the name suggests, is to have a single place where you can quickly see the performance of your platform and take action quickly if there is a problem. However, the reality is somewhat different and whilst there may be a ‘single pane of glass’ in some areas it is frequently not achieved overall. Furthermore, the platforms of today have become so complex that a unified representation or visualisation is often unintelligible, difficult to produce and frequently not adequate enough to allow actionable insights to resolve issues. The frequency of change, given the nature of these platforms, also means that it can be cumbersome and time consuming to keep up to date and relevant to the platform it represents.
Traditional monitoring approaches typically use vendor provided heavy-weight agents that collect monitoring data that the vendor believes to be important. Their agents are subsequently programmed to collect that data and as these approaches are founded in polling metrics (say, every minute or five minutes) and sampling (around 5% of the data is typically captured), there is application logic inside the agent which is processing the expected data so, for example, it can provide a sample to send back. These methods focus the monitoring on the metrics that the vendor selects as important and can easily lead to gaps - parts of the platform with no insight - as the agents are not designed to collect these metrics. And given that it is using polling and sampling techniques, there are gaps within the data it is collecting, too. To add to this, these agents are supported on certain tech types which make it challenging to support other tech, particularly the new, emerging and innovative tech stacks and thus further visibility gaps can easily occur.
The problem that has faced the monitoring space historically is the lack of standardisation used in monitoring. That is not to say that it hasn’t been attempted but the focus here has been on the need to standardise monitoring models and model descriptions rather than focusing on creating standards for the data itself. The challenge with monitoring models is that the platforms of today change too fast for any model based standard to stick. However, on the data side, an industry standard has been established and has grown hugely over the last few years - and that standard is OpenTelemetry or OTel for short.
Having too many tools equals higher costs and these can be divided in two categories; the green and blue dollars. The green dollar is the money spent by the organisation to use the tools. This includes the licensing to use them which can easily be expensive just for one product let alone multiple point tooling. Furthermore, it can be complicated to work out this cost as a total because the licensing may come from different budget lines and therefore make it difficult to come to total cost. The second expensive cost here is the deployment and setup of the tooling, particularly if that has involved either third-party PS and/or internal services (if the tool is provided by another internal team, for example, that may cross charge for their services). The other area to consider is the training, knowledge transfer and learning that is required for each tool. There may be a cost attached to formal training sessions but what must also be taken into account is the time it takes for someone to learn that tooling and, of course, to learn it significantly well to ensure that maximum value is derived. The time here is then taken away from other tasks and from a developer perspective, can contribute to the developer toil - more on this later.
All of these areas can create more challenges too - from not being deployed properly through to a lack of knowledge on how to use it. In both cases, the tool doesn’t provide the value and so other tools are then sought and the cycle is likely to start all over again.
The blue dollar, on the other hand, is the expected benefit - the return on investment - of having the tool. If you get the right O11y tool in place, you can then increase the blue dollar - development teams are more efficient, more innovation can get to your customers faster thus driving up revenue and the ability to see when issues are happening and solving them faster will save significant amounts of time, money and resources to the business. Throw in less tooling and therefore the knowledge required to learn them all, will reduce developer toil, and increase productivity too. Releases can get out faster and with less risk, thus getting that innovation to your customers and users quickly and seamlessly.
First things first, we can consolidate tooling and realise the benefits described above. The key to achieving this is the approach to observability, ranging from what needs to be measured through to how that data is then collected. Working with our customers, I have outlined some key best practices to help you get there:
1. Decide what visibility is needed
2. Understand the User Experience
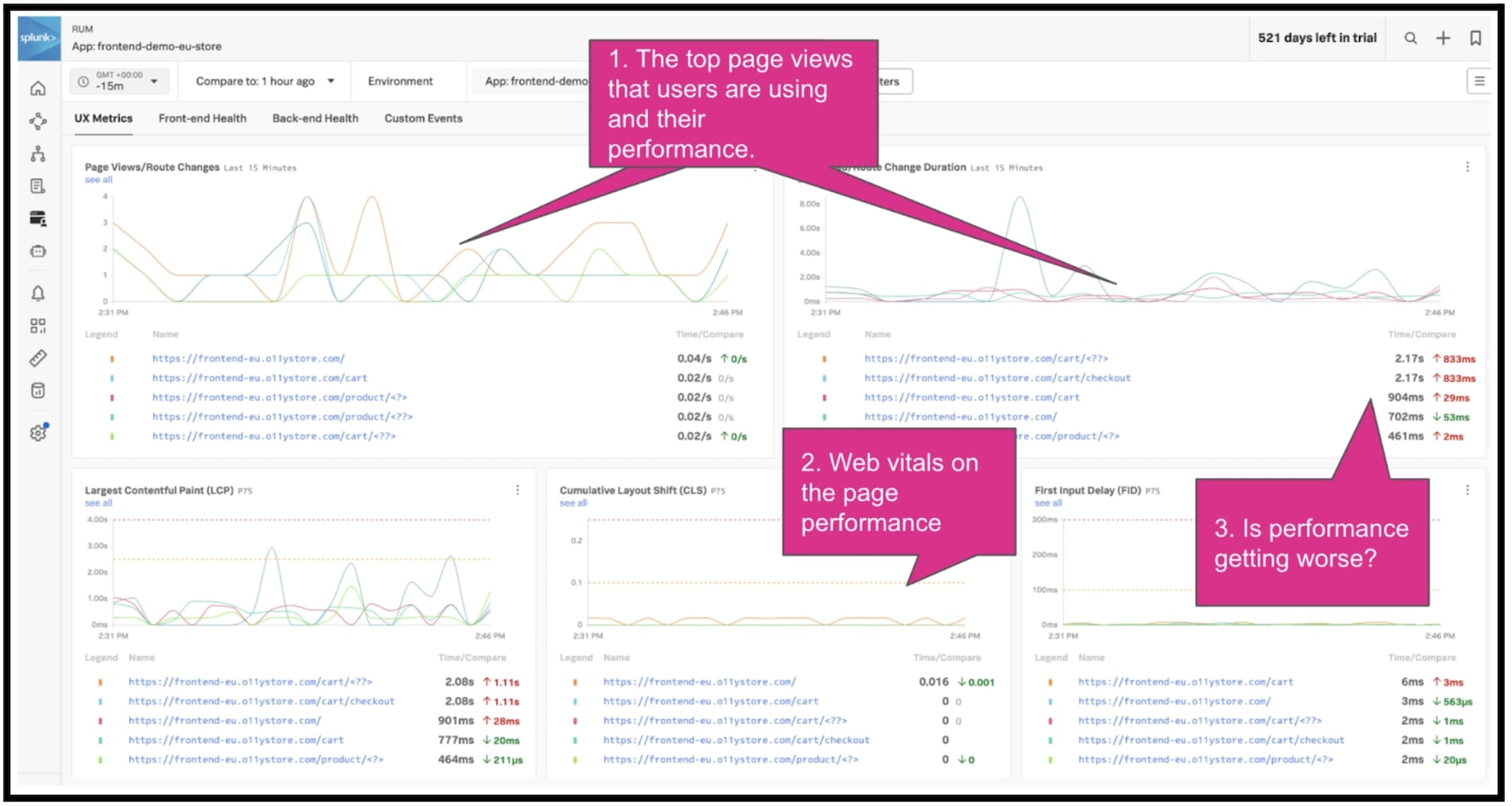 3. Using OpenTelemetry - OTel - as the data collection engine
3. Using OpenTelemetry - OTel - as the data collection engine
Now that the more challenging part has been done in terms of deciding what to observe and measure within the platform, the next step is to understand how to go and get that data from the platform and this is where OpenTelemetry - or OTel for short - comes in.
OTel is an industry standard data collection engine and is the second largest cloud native project, just behind the Kubernetes orchestration engine. It is vendor agnostic, thus separating the collection of data from the vendor that then processes it. As it is an agreed industry standard, it focuses on best practices to collect data and can adapt much faster to the evolution and innovation of tech that powers your platforms.
Freedom and control - OTel allows you to decide what to collect and also how it is collected. The control moves away from a tech or monitoring vendor, and into the hands of the teams that build and run the platforms. It is therefore much easier to collect the data that is needed in point one above, from any part of the platform, without the typical constraints of vendor and tech supplied heavyweight agents. OTel can then be used in place of these other approaches and helps enable tool consolidation.
4. Build out a monitoring standard
5. Decide which tools can be rationalised
6. Visibility is an iterative cycle and can always be changed
In summary, we can consolidate tooling in this modern platform world and control the costs attached with providing the right visibility needed. Check out the links below for some great further reading:

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.