
NextGen Incident Response
Modern incident response requires faster, smarter solutions. See why in this free guide.

Effectively managing events and alerts is essential for preventing or quickly resolving incidents, whether it’s a sudden service outage or an ongoing cyberattack.
The three terms — events, alerts, incidents — are different but they are closely related. Read on to learn more.
Ensuring the reliability, performance, and efficiency of IT systems is both the heart of operational excellence and an important strategic objective for digital organizations.
This goal is to design and implement robust and resilient applications, platforms, and infrastructure. The reality, however, is the significant effort involved in monitoring and addressing instances where the technology (and dependent elements) fail to live up to the expectations.
This “IT support” role has become critical in the digital era where enterprises rely on technology availability. How dependent? Well, the cost of downtime has spiked considerably. In a 2024 outage analysis survey, over half of respondents reported that their most recent significant, serious, or severe outage hit their organizations’ bottom lines by more than $100,000.
Understanding the terminology behind IT system availability is crucial in the quest to align all stakeholders in detecting, responding to, and resolving instances of outages and performance degradation. Three key terms come to mind: event, alert, and incident. They are regularly mentioned in IT support processes, sometimes used interchangeably — but not necessarily in the correct manner.
What do they mean, how different are they, and how do they relate with IT support processes? We will tackle these questions in this article.
Let’s start with the textbook definitions for these terms, as outlined in the ITIL® 4 service management framework:
When IT systems are in production — up and running — their health and performance is monitored by the service provider so as to quickly and adequately respond to any issue.
In the following sections, I’ll walk through how an event is generated, alerts are sent, and an incident may be declared.
Information is polled from configuration items (CIs) and sent to monitoring tools. Here, the monitoring tools analyze the information — if/when certain conditions are met, the tool generates events. These conditions are either:
Monitoring tools that interrogate these components is known as active monitoring, while collection the notifications sent by the components to the monitoring tools represents passive monitoring.
(Not all monitoring results in the detection of an event, as thresholds and other criteria determine which change of state will be treated as events).
Once an event is detected, it is usually categorized in one of three buckets based on increasing significance (think of it like a traffic light sequence). These are:
Informational events signify that normal operation is taking place, so they are of the lowest significance.
Usually no response is required, since these events indicate the status of components or task (such as user login or task completion).
Warning events signify that:
Examples of warning events may be a surge in errors or the capacity approaching maximum limit. Depending on the context of the event or the criticality of the service component, a service provider may react to a warning event by taking action to forestall an exception from occurring.
Exception events signify that a threshold has been breached or the service is facing a significant deviation from normal. Here, the service is not responding, transactions are completely failing, or intrusion is detected.
Exception events require an immediate response from a service provider to remedy the situation. (This likely triggers your organization’s incident response practice — more on this later.)
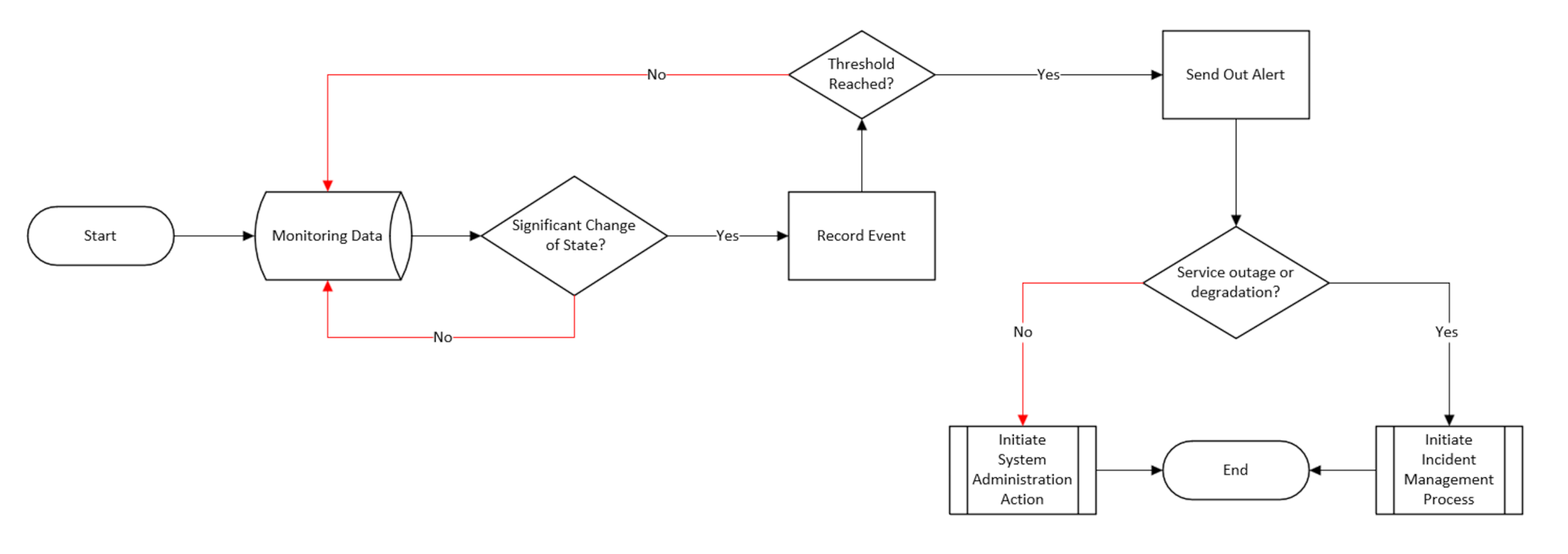
Process flow: Event to Alert to Incident
The need to notify IT system administrators of a significant event is driven by significance with mostly exception and warning events triggering the generation of an alert.
Alerts are created and controlled by monitoring tools. These underlying tools should be reliable, flexible, and able to generate detailed and actionable notification messages. Alerts can be sent out through a variety of channels including:
The way monitoring tools are configured to send out alerts should be cognizant of both:
Whenever IT support teams are swamped by a barrage of alerts — that are mostly informational or false positives — chances are high that they will inadvertently miss out on an exceptional event. When teams become frustrated by meaningless alerts over time, they become desensitized, leading to a condition termed “alert fatigue”. Advice on managing such scenarios is to:
The communication channel and the delivery time both matter. Configuring monitoring tools to send only emails might result in gaps during non-work hours if a 24/7 NOC is not established in the organization.
Having a diversity of alert channels —SMS, social media posts, and collaboration tool notifications, for example — can ensure that alerts are sent in a manner most likely to be seen and responded to. Monitoring tools should be integrated with the most common communication channels in the service provider’s environment.
Whenever an alert is sent for one or more exceptional events, the service provider’s support team will declare it an incident if it is an unplanned occurrence that has disrupted services in a manner that goes against agreed or expected performance levels.
Incidents can also be triggered in the absence of an alert, especially where users raise complaints on abnormal service degradation that has not been detected by standard monitoring tool alert thresholds.
So, how to handle incidents? According to the ISO 20000 standard for service management, an incident manage process should be repeatable. Put simply, incidents should be…
The classification and prioritization of incidents depends heavily on the information and significance of associated alerts and events. The impact of incidents is usually graded as high, medium, or low. Typically this depends on two factors: the scope and the level of service disruption. A central printer hitch on a building floor would not be rated as high as a mobile network outage affecting a city.
Most organizations have defined a major or critical incident priority level that is the highest level of impact. These critical incidents require:
And as the support teams diagnoses the incident to identify the root cause, the event messages are the first port of call.
When event logs are analyzed, the output can provide insights on:
All this information is vital in troubleshooting and resolving incidents. Bonus: you can also use event log information to be proactive. Analyze event information and take action to prevent incidents from recurring — or occurring in the first place.
Major incidents usually require a post-resolution incident report as part of the incident resolution process. The information from events and alerts is usually included for purposes of synopsis, lessons learnt, and continual improvement.
It’s easy to see why the lines separating events, alerts, and incidents may be blurred. The three terms are intertwined from the source, hence the significant dependencies among them.
By proactively analyzing events to detect trends early and optimizing monitoring tool thresholds, service providers can ensure only the right alerts go out to support teams for a more effective incident response. Delighting customers and managing costs through quality services can only be realized when events, alerts, and incidents are all managed in a cohesive manner.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
