Perspectives Home / Industry Insights
7 Challenges Tech Leaders Face in FSI — And Steps for How To Solve Them
The EU and UK are known as global leaders in the financial sector. Here’s what their technical leaders are struggling with the most when measuring resilience.
By Kirsty Paine, Strategic Advisor, and Mark Woods, Chief Technical Advisor, EMEA
January 24, 2024 • 4 minute read
We recently met with a focus group of technical leaders in financial services to understand how they were managing and measuring resilience in their organisations. If you couldn’t tell from my spelling of organisations with an S, we were in the UK — as the financial services institutions (FSI) in the EU and the UK are often called out as being global leaders.
This status has come into sharper focus with the latest legislative advancements to shape the FSI market, which contain concrete obligations for the sector on service, resilience and security.
In these sessions, we asked a series of questions for discussion under the Chatham House Rule, and synthesised the resulting commentary in a digestible format to give some FSI Perspectives — and then added our own take.
What’s going wrong?
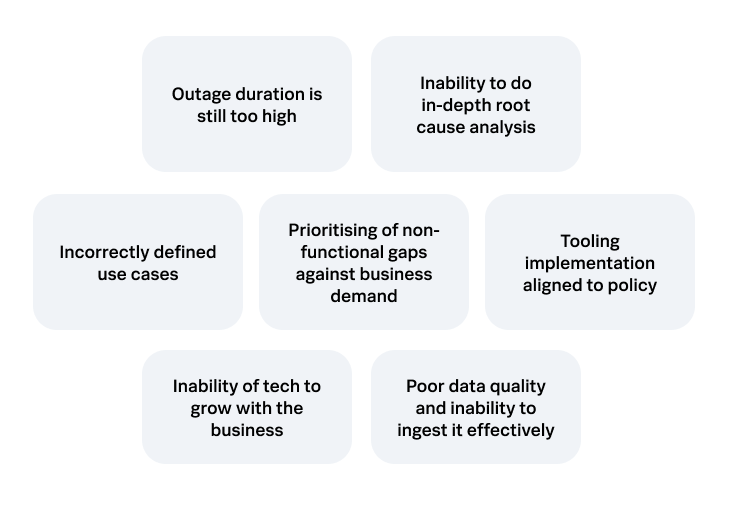
Always cheery, we first wanted to know what was a problem for technology leaders in FSI today. Seven key areas emerged, each worthy of their own roundtable. Try ordering these challenges shown in the diagram below for your organisation, from most to least relevant, or tell us what’s missing but important to you.
So what?
We distilled four main interventions that organisations can prioritise as remedies to these seven problem areas:
Measure based on well-considered assumptions. Use the data to identify weaknesses, use cases and provide justifications for improvements.
Avoid lags as a priority. They create delay, reducing an organisation’s ability to address issues and respond appropriately.
Invest in root cause analysis. It feeds back into better leading indicators, averting outages before they arise and moving responsiveness upstream.
Have data to show which tools are(n’t) delivering. Avoid overfit of tooling to policy, and therefore prevent tooling that doesn’t scale to business needs.
How do you know if you are resilient?
A common theme throughout this discussion was that lagging indicators are much easier to find than leading indicators. So, even though they are less useful in preventing issues, we have a bias towards these lagging indicators and metrics. Post-incident remediation and wash-ups should include attempts to find leading indicators to avert the issue earlier next time.
When we discussed resilience measurement, we had a mix of responses in the group:
Most organisations are checking performance, availability and security.
Most have some form of lagging indicators for (lack of) resilience.
Some are checking auditability.
Few have direct leading indicators for (lack of) resilience.
None are using other measures (elasticity, efficiency, usability, adaptability).
The current measures are imperfect, but still give information. An “amber” status can be unhelpfully ambiguous, and implies a need to revisit leading indicators to see if more could have been anticipated or predicted before an incident occurs.
Outages and span of control
Outages are often used as a measure of resilience, and span of control indicates the impact of such outages. We found some commonality in how outages are defined and how services are prioritised:
Most keep a focus on minimising: service disruption and “absolute harm.”
Most agree that tiering of services is necessary to prioritise cost and support, but there are evolving maturity levels in defining these tiers and the numbers in each tier.
What leaders told us
“Severity of the change relates to the downtime and the risk. We’re not good at zero downtime today.”
“Payments touches so many of our critical services; the mapping we have for services says there’s a dependency, but not how change might impact that — maturity of thought isn’t there.”
“We categorise into: incidents and outages, and under active review — what’s the appetite to have any impact to payments under any circumstances at certain times?”
“The regulator focuses on the customers, but regulation needs individual organisations to find their own level, which hopefully is similar across the industry. Different scenarios have different contingencies. So we look at ‘absolute harm’ as our measure.”
“We have changed from disaster recovery to recovery mode.”
Our perspective on progress
So why aren’t we moving more quickly towards better resilience measures? A major reason is the inability (or unwillingness) to show how imperfectly we understand factors that impact important services, especially from leadership. Most improvement initiatives are based on incremental upgrade cycles, blanket changes or best guess hypotheses rather than operational insight — a myopic focus on availability, data flows and incident handling.
This short-term approach is understandable, as there's lots of work remaining to provide consistent foundations. However, simply wrapping these initiatives in different 'treatment' boxes will do little to move beyond an expensive reactionary stance — which is essential to make true progress towards better understanding.
No one has the resources to provide 100% quality coverage and improvements, so consistent prioritisation is critical. This should be based on leading (not lagging) service-level measurements and assumptions, which are currently complete blind spots for the majority of organisations. This can be shaped, tested and improved to fit your service, organisation and customer needs.
We need to be relentless in showing how imperfectly perfect our services are, using more expansive and relevant measurements than just basic system performance. With new measures, we have a chance to focus on truly building resilient capacity rather than mitigating perpetual failure.
To read more industry insights like this one, sign up for our Perspectives newsletter.



