
Downtime costs you
Learn about the costs of downtime — and how to avoid it. Get the free report.

Predictive modeling is the process of using known results to create a statistical model that can be used for predictive analysis and forecasting future behaviors.
Think of predictive modeling as under the umbrella of predictive analytics. Predictive analytics is a field of data mining that tries to answer the question: “What is likely to happen next?”
Digitization has created enormous volumes of real-time data in virtually every industry. We can use this data to analyze historical events to help forecast future ones, such as financial risks, mechanical breakdowns, customer behavior, and other outcomes. However, the data produced by digital products is often unstructured data — that is, it's not organized in a predefined manner. This lack of structure makes it too complex for human analysis.
Instead, companies use predictive modeling tools that employ machine learning algorithms to parse and identify patterns in the data that can suggest what events are likely to happen in the future.
This “crystal ball” capability has applications across the enterprise. Businesses use predictive modeling to, among many areas:
It is an especially powerful tool in ITOps and software development, where it can help predict system failures, application outages, and other issues. Let's take a look in this in-depth article. We'll look at:
Splunk IT Service Intelligence (ITSI) is an AIOps, analytics and IT management solution that helps teams predict incidents before they impact customers.

Using AI and machine learning, ITSI correlates data collected from monitoring sources and delivers a single live view of relevant IT and business services, reducing alert noise and proactively preventing outages.
What is predictive analytics? Predictive analytics refers to the application of mathematical models to large amounts of data with the aim of identifying past behavior patterns and predicting future outcomes. The practice combines data collection, data mining, machine learning and statistical algorithms to provide the “predictive” element.
Predictive analytics is just one practice within a spectrum of analytics approaches that include the following:
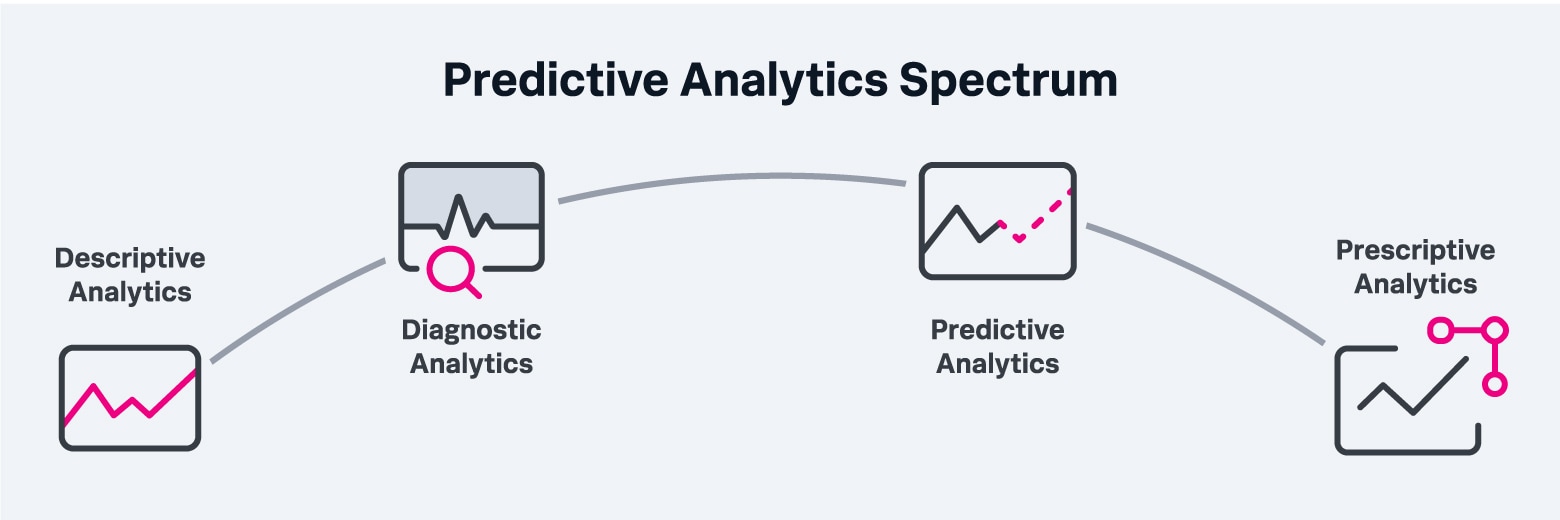
Our focus in this article is on predictive analytics, which differes from prescriptive analytics.
Descriptive and diagnostic analytics tools are invaluable for helping data scientists make fact-based decisions about current events, but they’re not enough on their own. In order to compete today, businesses must be able to anticipate trends, problems, and other events.
Predictive analytics builds on descriptive and diagnostic analytics by:
This ability allows businesses to plan more accurately, avoid or mitigate risk, quickly evaluate options, and generally make more confident business decisions. Here are some real-world examples of what predictive analytics can do:
Predictive analytics has been particularly transformative in IT. The increased complexity of architecture sourced to virtualization, the cloud, the Internet of Things (IoT), and other technological advances exponentially increases the volume of comprehensible data, resulting in long delays in issue diagnosis and resolution.
Powered by big data and artificial intelligence (AI), predictive analytics overcomes these difficulties. As it identifies patterns, it can create predictors around IT issues such as:
What's the value of knowing all this? It's clear: improved performance, reduced downtime, and overall more resilient infrastructure.
Predictive models can analyze vast amounts of transactional data to find anomalies or suspicious activities. As a result, it helps in fraud detection and prevention, helping businesses to enhance their security protocols and prevent financial losses.
Predictive analytics models work by running machine learning algorithms on business-relevant data sets.
Building a predictive model is a step-by-step process that starts with defining a clear business objective. This objective is often a question that helps define the scope of the project and determine the appropriate type of prediction model to use. From there, you’ll follow a series of steps as outlined below.
Predictive modeling is an iterative process. Once a learning model is built and deployed, its performance must be monitored and improved. That means it must be continuously refreshed with new data, trained, evaluated, and otherwise managed to stay up-to-date.
(Related reading: continuous data & continuous monitoring.)
There are several common predictive modeling techniques that can be classified as either regression analysis or classification analysis.
Once you decide to use regression analysis, there are several types to choose from. Some of the most common include:
The most basic form of regression analysis, linear regression establishes the relationship between two variables.
To use a simple example, a store could use linear regression to determine the relationship between the number of salespeople it employs and how much revenue it generates.
Multiple linear regression can be used to establish the relationship between the dependent variable and each of the independent variables. A health researcher can use this technique to determine the impact of factors like smoking, diet, and exercise on the development of heart disease, for example.
This type of regression analysis is used to determine the likelihood that a set of factors will result in an event happening or not happening. A bank trying to predict if an applicant will default or won’t default on a loan is a common use of logistic regression.
This technique is used to analyze multiple linear regression datasets that have a high degree of correlation between independent variables.
A "classification" approach, this technique replicates the decision-making process by starting with a single question or idea and exploring different courses of action and their possible effects through a “branching” process to arrive at a decision.
Modeled on the human brain, this technique helps cluster and classify data to recognize patterns and identify trends that are too complex for other techniques. That's why it's considered a classification analysis.
A retail site that recommends products based on a user’s past purchases is one example of neural networks in action.
(See how Splunk can detect suspicious security activities using ML and recurrent neural networks.)
Prescriptive modeling is the practice of analyzing data to suggest a course of action in real-time. Essentially, it relies on the insights produced by other analytics models to consider various factors — available resources, past and current performance, and potential outcomes — to propose what action to take next.
In an IT context, for example, prescriptive modeling can:
Prescriptive analytics is an extension of predictive analytics. Where predictive analytics can tell you what, when, and why a problem will likely happen, prescriptive analytics goes a step further and offers specific actions you can take to solve that problem. Both types of analytics enable you to make better-informed decisions, but prescriptive analytics pulls the most value from your data, allowing you to optimize processes and systems for the short and long term.
There are several different types of predictive analytics models. Most are designed for specific applications, but some can be used in a variety of situations.
Before deep diving into the specific models, we need to understand the differences between unsupervised and supervised models.
Since each industry has different data objectives, nature, and challenges, the different types of predictive models have varying applications across different domains. Each type of model has specific tasks like detecting unusual activities, forecasting demands, and so on. Let's discuss the common types of predictive models.
Perhaps the most common types of predictive analytics models, forecast models learn from historical data to estimate the values of new data. Forecast models can be used to determine, for example, things like:
A real-world example is using predictive algorithms to predict the readmission of patients, as done in the Mount Sinai health system.
Classification models use historical data to categorize information for query and response and provide broad analysis to help people take decisive action. Popular across a wide range of industries, they’re best used to answer yes/no questions such as, “Is this loan applicant likely to default?”
This model sorts data together around common attributes. One popular application is customer segmentation, where the model can cluster a business’s customer data around shared attributes and behaviors. Clustering models use two types of clustering — hard and soft.
Outlier models identify and analyze abnormal entries within a dataset and are usually used where unrecognized anomalies can be costly to companies, such as in finance and retail. For example, an outlier model could identify a potential fraudulent transaction by assessing the amount, time, location, purchase history and the nature of the purchase.
(Related reading: anomaly detection.)
This model uses time as the input parameter to predict trends over a specific period. For example, a call center could use this model to determine how many support calls it can expect in the coming month based on how many it received over the previous three months.
(Related reading: time series forecasting & call center metrics to track.)
There are a few things to consider when choosing a predictive model:
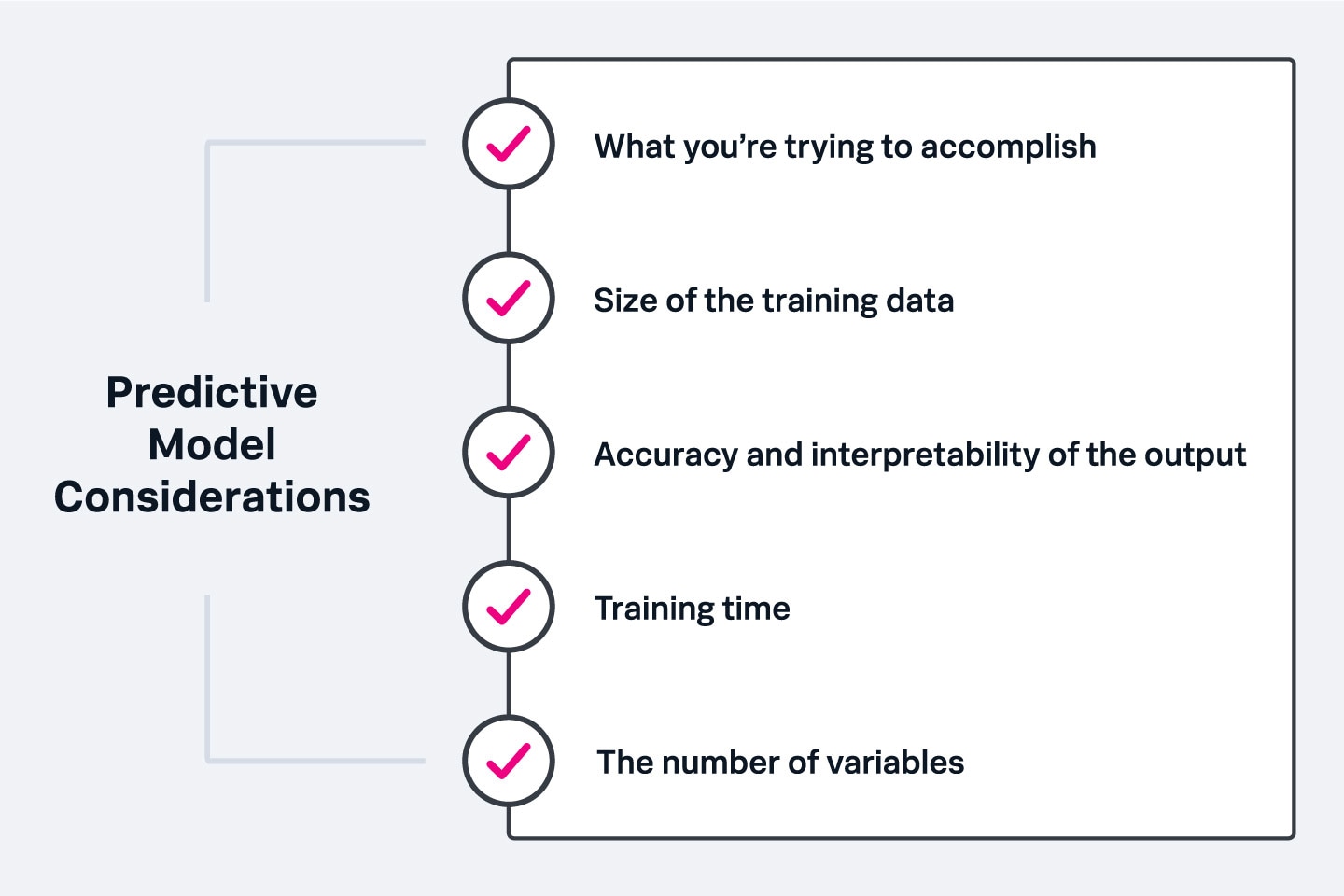
Ultimately, you will need to run various algorithms and predictive models on your data. Also, you need to evaluate results to make the best choice for your needs.
Predictive modeling is important because every business, regardless of industry, relies on data to make better business decisions. Predictive modeling boosts decision confidence by revealing the most likely outcomes of actions under consideration.
Some of the common business benefits can include:
Mathematically performed predictions based on datasets are not infallible. Typically, problems with predictive modeling come down to a few factors.
Non-quality data. The first is a lack of good data. To make accurate predictions, you need a large dataset that is rich with the appropriate variables on which to base your predictions. That is not easy to come by for many organizations, as many organizations lack a robust data platform that can correlate all of an enterprise’s data, analyze information at a granular level, and derive actionable insights from large datasets. Consequently, small or incomplete data samples can easily result in unreliable predictions.
Past performance does not guarantee future performance. Another obstacle to effective predictive modeling is the assumption that the future will continue to be like the past. Predictive models are built using historical data. However, behaviors often change over time, which may render long-used models suddenly invalid. New and unique variables in different situations in turn elicit new corresponding behaviors and approaches that we can't always anticipate with prior models. Thus, we must constantly refresh predictive models with new data to keep pace with current behaviors in order to make accurate predictions based on them
Model drift. Another common challenge with predictive modeling is model drift. Model drift refers to a model’s tendency to lose its predictive ability over time. Statistical shifts in the data usually cause this. If left undetected, it can negatively impact businesses by producing inaccurate predictions.
Before starting with predictive modeling, first decide what problems your organization would like to solve. Clarity about what you want to accomplish will yield an accurate, usable outcome while taking an ad hoc approach will be far less effective.
Next, assess any skills and technology gaps in your company. While software solutions do much of the heavy lifting, predictive modeling requires expertise to be effective. Be sure you have the staff, tools, and infrastructure you’ll need to identify and prepare the data you’ll use in your analysis.
Finally, conduct a pilot project. Ideally, this will be small in scope and not business-critical but will be important to the company. Identify your objective, decide what metrics you will use to achieve it, and how you will quantify the value. Once you have your first success, you’ll have a foundation on which to build larger predictive modeling projects.
Predictive modeling is sound data science, but it’s not omniscient. Predictive model neither could have forecasted the COVID-19 pandemic. Nor how it would change consumer behavior on such a huge scale, for instance. Those once-in-a-lifetime circumstances aside, predictive modeling is a highly effective way to inform business decisions. You only need to have the right solution and staff in place. Also, you need to continually refresh your model with new data.
With a systematic approach and the right software solution, you can start leveraging the power of predictive modeling. By doing so, you can solve your most vexing business problems and uncover new opportunities.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
