


Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Do you SPL? Well, if you do, you probably either already know about the job inspector, or you’re about to. Either way, you probably don’t know enough. Don’t worry though, that’s all about to change.
There are a few different aspects of the job inspector that everyone should be familiar with. These include the execution costs, the search job properties, and the search.log. I’m going to walk us through these areas, and some others, and their importance. Don’t worry though, the job inspector is always on duty!
The job inspector is a tool normally used in Splunk Web (though can also be utilized through REST) that allows users to examine various aspects of their search in order to troubleshoot, improve, or simply understand its behavior.
Accessing the Job Inspector is quite easy. In the search window, simply click on the job dropdown and press “Inspect Job”.
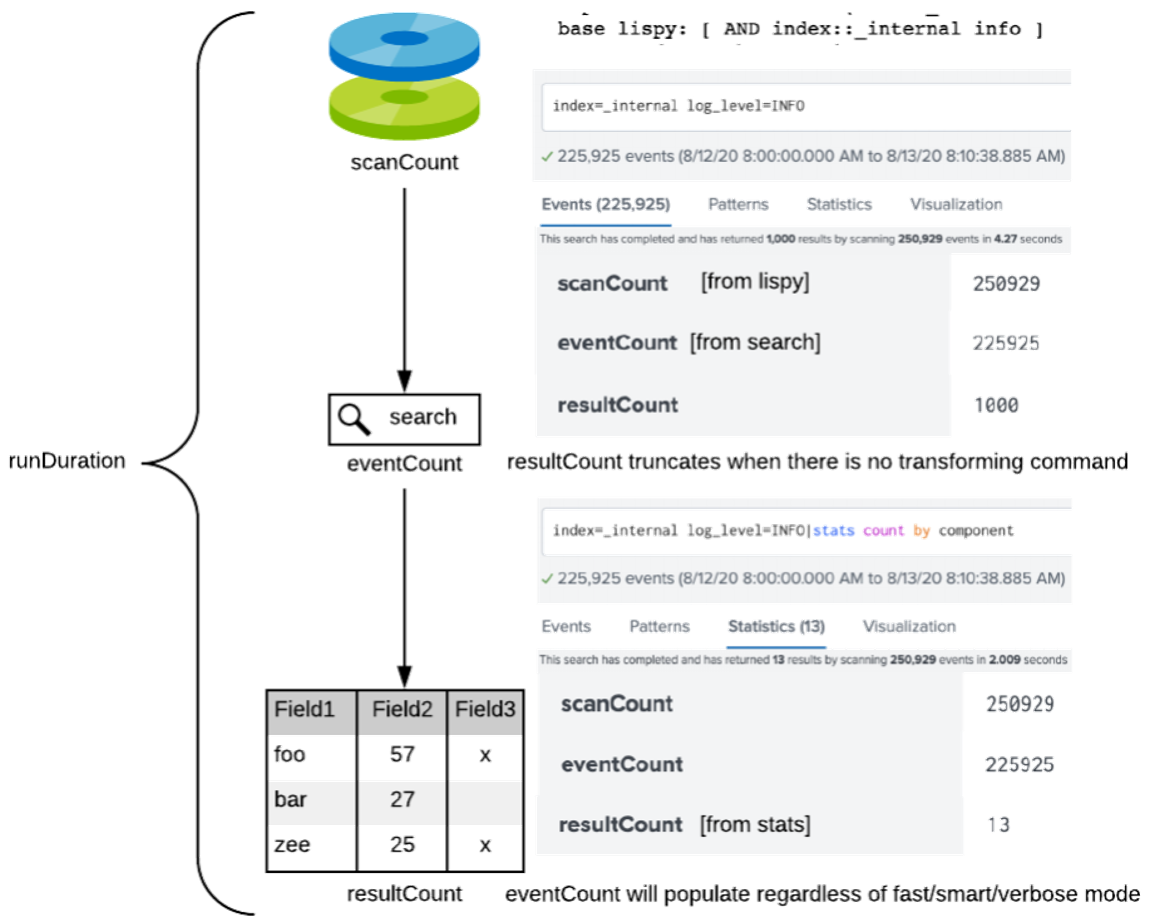
There are important details in the top level bar of the Job Inspector. Most notably, you’ll see the scanCount, runDuration, job status, and any important messages.
It is common practice to measure performance by calculating the events per second (eps) by taking the scanCount/runDuration. Splunk deployments differ, we all know that. In some environments, with the consideration of dense searches, you might find that 10k eps/indexer is a well oiled machine, however you might also find that it is completely insufficient.
Let’s start getting into the meat of the Job Inspector. The execution costs are hugely important, as they tell us where the search is spending all it’s time. No one wants Buttercup grazing in the pasture all day, she should be spending her time galloping through a field and doing all sorts of activities.
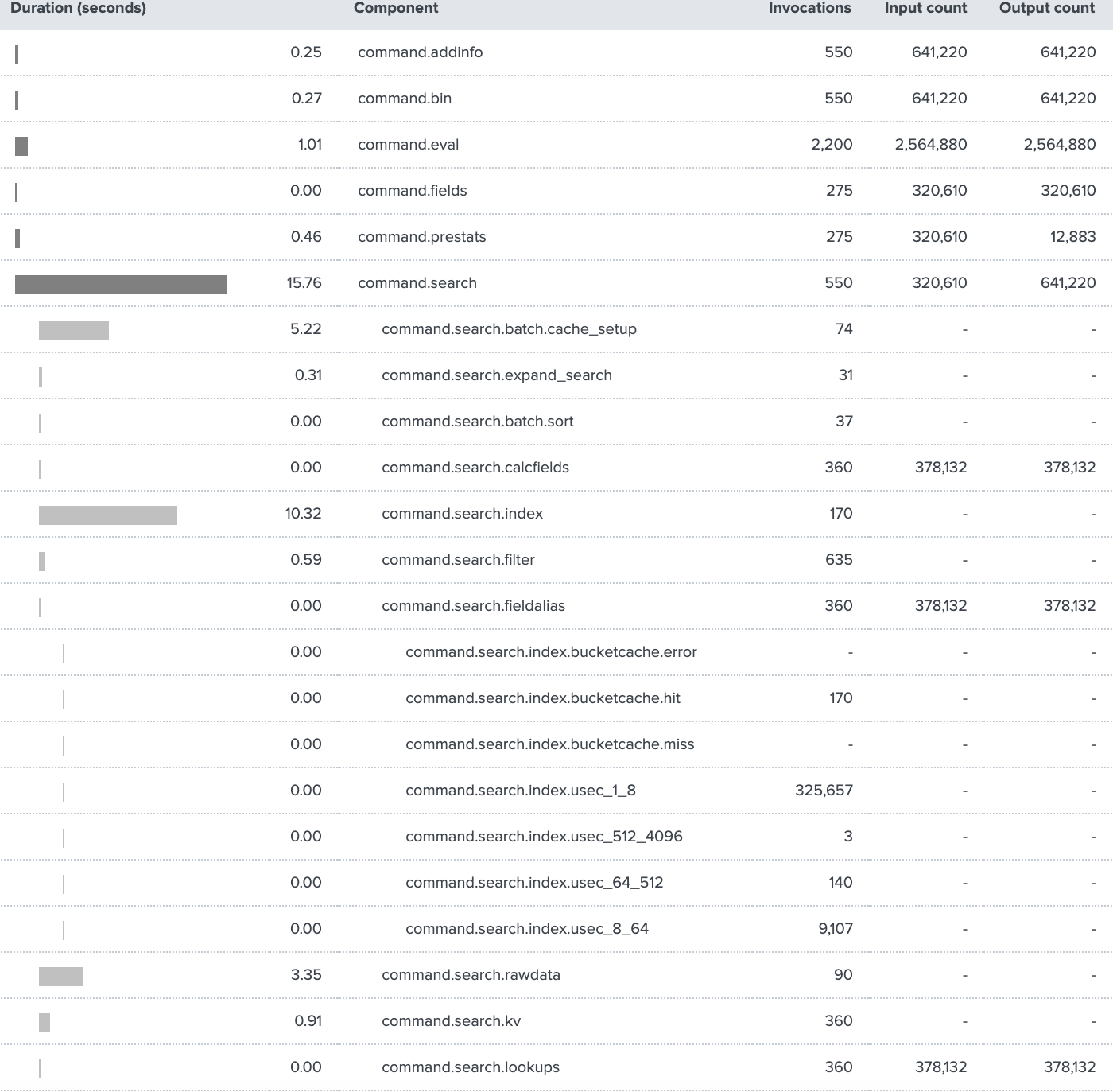
There are five columns in the execution cost table that you should understand: duration (seconds), component, invocations, input count, output count.
Duration (seconds) is essentially what it sounds like. It is the cumulative run duration over all phases of the search, including the search head and indexers. There are a lot of components and Splunk is not exhaustive in including everything into a subcomponent. You may notice that not all subcomponent durations add up properly to their parent component.
Components are the hierarchical structure of commands, along with a majority of their subcommands utilized within the search. As a note, the duration of each subcomponent is included in the overall duration of its parent component.
Invocations are how many times the components were carried out.
Input/Output counts account for the number of events going in and out of each component. The only component that this is different for is dispatch.stream.remote, which are the bytes sent from the IDXs to the SH.
So now you’re an expert in each of the columns! That’s fantastic. It’s probably a good idea to know a little bit about the various components in the Execution Costs themselves. Let’s cover some of the more helpful components when it comes to troubleshooting issues or looking into search performance.
First, the command components explain the costs of various commands used to complete the search. It’s important to note that the command.search components can run concurrently, not necessarily consecutively.
command.<command> are components that indicate what commands have been executed in your search. When trying to optimize your SPL, look at these components and focus on any commands that are taking the longest to run and try to make them more efficient.
You’re able to see how much time it takes to apply search-time field extractions with command.search.kv as well as the information around the fields added through automatic lookups with command.search.lookups.
If you rename fields a lot, knowing the execution costs of the FIELDALIAS property in props.conf with command.search.fieldalias can be extremely helpful.
The costs associated with assigning tags and eventtypes are visible through command.search.tags and command.search.typer, respectively.
The components where invocations really come in handy are the command.search.index components. So the command.search.index component let’s us know how much time was spent crawling the tsidx files, but we’ll use the invocations to see the number of SmartStore buckets in the cache with command.search.index.bucketcache.hit and how many buckets were downloaded from S3 with command.search.index.bucketcache.miss. Hopefully command.search.index.bucketcache.error is always 0, as that tells us that there was an error in the cachemanager.
One more useful component to know with invocations is command.search.index.usec_N_M, because that shows the number of IO operations that lasted between N and M microseconds. For example, if the component was command.search.index.usec_64_512 and had 315 invocations, the search would have yielded 315 IO operations that took between 64 and 512 microseconds.
Are you still awake? I’m just checking...
Outside of the command components, there are also costs associated from dispatching the search.
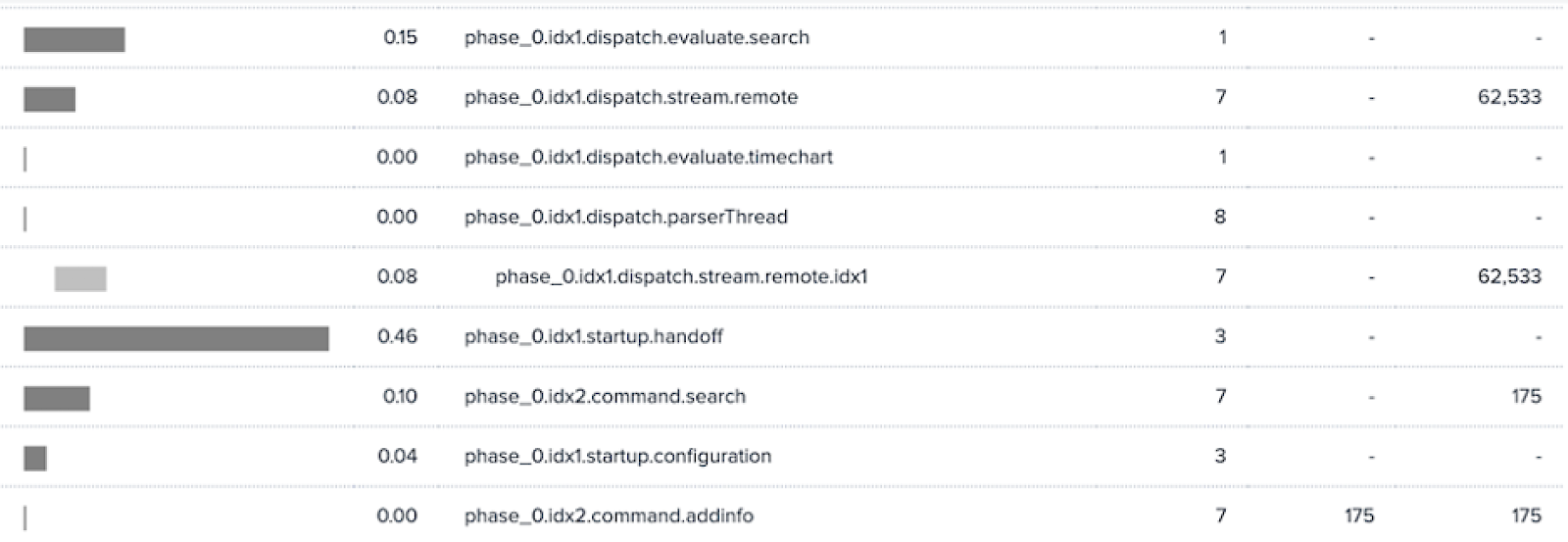
One of the first things that happens when the search kicks off is it gets sent off to the indexers. Take a look at the startup.handoff component to see the cumulative time spent communicating to all of the indexers and setting up the search processes. If you notice large durations relative to the indexer count, this might indicate overloaded indexers or network issues.
Another interesting component is dispatch.emit_prereport_files, which tells you how long it took for transforming commands to write to local files after the data has come back from the search peers.
dispatch.fetch is the time it took for the search head to wait for all of the peers to send the data. It has big overlap with command.search, but some differences: command.search includes any non-generating search commands run on the SH, dispatch.fetch includes other distributed streaming commands run on the IDX. As an example, let’s look at the following search:
index=_internal | eval user = coalesce(user, "unknown") | stats count by user | search count > 10
The eval runs on the IDXs and thus has its runtime included in dispatch.fetch as well as called out individually in command.eval. The generating search loading events from the internal index and the later search filtering on the count of events are both included in command.search, but only the first is included in dispatch.fetch because the second runs on the SH.
The last bit of dispatch components I’m going to talk about are the dispatch.stream.remote and dispatch.stream.remote.<IDX> components. These indicate whether it is the indexers or the search head that is doing all of the work by showing the time spent by the indexers and the total bytes returned by the search head. The lower number of bytes indicates that the search is more efficient. If there are large differences between the 'bytes returned' for the different indexers, it could indicate that there is poor data balance. If instead, the indexers report similar bytes but some have slower speeds, then it's probably performance differences in the underlying hardware of the indexers.
Wowzers! That was a lot! Moving onto something you’re probably all a little bit more familiar with, the job properties of searches. Some of these are used more frequently in dashboards or in alert actions.
The first properties we’ll talk about are, in my opinion, the most important job properties. They help benchmark and optimize searches. So when the events are loaded off disk and props.conf are applied and those fields are extracted, the returned events are defined by the scanCount. Essentially, this is the lispy. Once the generating search command runs against the events that have come back and possibly more defined filters are applied, that provides the eventCount. The number of results returned after the last command in the SPL renders the resultCount. From start to finish, the cumulative duration of the search is defined by the runDuration. runDuration can be really important because some searches are automatically terminated if they run over a certain length of time, which is set using srchMaxTime per role in authorize.conf.
There are a handful of other really interesting job properties defined in the Splunk Documentation (linked above) that I suggest you check out. They can come in handy when trying to understand more about your search.
We are all little inspectors here, and what a better way to inspect with this gadget than to add debugging! That’s right, explorers, we can add all sorts of debugging to our job inspector!
There are two different types of debugging that you’re able to add and both can be added to limits.conf.
The first one I’ll tell you about not only brings in debug messaging, but also brings in the lispy as well as subsearch outputs to the top message bar of the job inspector, both of which can be really helpful when trying to troubleshoot and optimize searches. The downside of bringing in the outputs of subsearches to the top of the job inspector is that the inspector might render more slowly if those are large outputs. The upside is that you’re able to see the search results of your subsearch without running it again in another search window, if you’re needing to troubleshoot it.
To add this to your limits.conf file, simply add this stanza:
[search_info]
infocsv_log_level = DEBUG
The other debug option brings in a wealth of information. It allows you to see detailed execution costs spent on each peer. This can be extremely useful to see if there is a problem and pinpoint exactly which peer that problem might be on.
This can be added to your limits.conf file with the following stanza:
[search_metrics]
debug_metrics = true
This deserves a blog post all its own, I think, and it very well might get one. I know you’re all at the edge of your seats because this is the most exciting topic you’ve ever gotten the chance to read about and you want me to write and write and write. Oh stop it. I couldn’t possibly.
All I’m really going to say about search.log is that they are not indexed in Splunk, so the only way to see them is through the job inspector. Also, there are times when error messages are not displayed at the top of the job inspector and only in search.log, such as regex errors for field extractions. It is helpful just to search for ERROR or WARN, though there can be things you’ll find simply by noticing bigger deltas in timestamps. The search.log provides a lot of helpful information when it comes to debugging, though it can take some time to understand what to look for. This is why I believe it might deserve it’s very own post.
There is an incredible amount that we didn’t get through. What I hope you can learn from this is that the job inspector is so rich with information and that we can utilize all of this to better understand our searches and make them better, and also find problems within your environment. You might wonder why it’s important to optimize your searches, and the answer is pretty simple. There may be rules and limits put in place on your Splunk environment that could halt searches if system resources are needed elsewhere or if the limit for that search was hit. Poorly written searches that are also scheduled could lead to constantly skipped jobs, as well as a decrease in the overall performance of the search head or search head cluster.
This post is more of a dictionary of sorts to get the basic understanding of core components. What you might see from me later on is a post about the search.log and a job inspector troubleshooting example. What I’d love is for you all to go explore your searches with the job inspector and see what happens when you move commands around, add commands, change filters, etc. I don’t want you to purposefully make your searches terribly inefficient, or to become worse SPLers, but I want you to understand how each command and where it lands in the search affects the overall efficiency of the search.
October 2020, Splunk Enterprise v8.0.0

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
