
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

“The Ethereum 2.0 Medalla testnet is live. Validators are validating. Attesters are attesting. Blocks are propagating. Which means, data, lots and lots of data.”
Say no more! We love data and couldn’t resist spending a few days to make sense of Ethereum 2.0 data using the Data-to-Everything Platform. The Ethereum community is a very open community which is one of our core values. Thus, everything you’re about to see/read can be hosted by any community member using open source software and the free version of splunk. For a couple weeks we’ll also host a publicly accessible version of the dashboard here.

[The Medalla Testnet Operations Center]
We began our journey trying to figure out what components and contributing factors would help determine the overall health of the Medalla Tesnet. Combining these findings together and monitoring them in real-time became the Medalla Testnet Operations Center as shown above. In this post we will break down the insights we found and how the dashboard came together.
In order to come up with these insights we collected data by standing up our own nodes using different clients, scraped data from eth2stats.io, brought in chaind data, Discord and more! Of course, this is an inconclusive set of data and insights.
“We must be able to measure blockchain decentralization before we can improve it” - Balaji
Balaji Srinivasan and Leland Lee wrote a great article on quantifying decentralization. Plotting a Lorenz Curve and calculating the Gini coefficient you can identify vulnerable areas where health or security are most likely to be compromised. We created a couple search macros to  automatically calculate the lorenz curve or gini coefficient for any field in the data. So for example, to calculate the gini coefficient for the locations of the nodes a simple search of index=eth2stats `lorenz(location.city)` would produce lorenz curve in the top left of the image below and index=eth2stats `gini(location.city)` would produce the gini coefficient of 0.34. Worth noting is that splunk does this as data streams in, so these are real-time charts that automatically update! Because of this, simple alerts can be configured in splunk. If for example any gini moves more than 2 standard deviations from the mean it could be an indicator of a health issue or attack.
automatically calculate the lorenz curve or gini coefficient for any field in the data. So for example, to calculate the gini coefficient for the locations of the nodes a simple search of index=eth2stats `lorenz(location.city)` would produce lorenz curve in the top left of the image below and index=eth2stats `gini(location.city)` would produce the gini coefficient of 0.34. Worth noting is that splunk does this as data streams in, so these are real-time charts that automatically update! Because of this, simple alerts can be configured in splunk. If for example any gini moves more than 2 standard deviations from the mean it could be an indicator of a health issue or attack.

We found the Gini coefficient may not be the best measurement. For example, the Gini coefficient for the client nodes of 0.49 is better than 0.64 for the attestors; however, one bug in the prysm client could have more drastic implications than one bad attestor. For this reason a better metric would be to create a macro to calculate the Nakamoto coefficient. The Nakamoto coefficient is the minimum number entities in a given subsystem are required to get to 51% of the total capacity. The higher the number the better. Since prysm nodes account for >51% the Nakamoto coefficient is 1 (not good). If there were an issue with Prysm clients it could have a significant impact on the network. Then it happened.
New Prysm clients are released on Mondays and are adopted pretty quickly as you can see below. By Wednesday there were more alpha.29 clients than any other.
When I upgraded my prysm client I started getting warnings and attestations ceased.

I wasn’t the only one, a quick search and saw others having issues. The Medalla Testnet Operations dashboard started changing quickly. The health score dropped as metrics started to get worse such as connected peers, nodes syncing, and uptime of nodes.
The awesome team at Prysmatic Labs had already implemented a hotfix but since it requires compiling from sources it’s unlikely most of the network would upgrade before the next weekly release. I upgraded my node, it started working just fine but when it caught back up it crashed once the validators connected. Using the Splunk App for Infrastructure it was easy to identify the issue, the system was running out of memory. The reason was non-finality increases memory utilization, once I increased the system memory and it’s been smooth sailing since. If you’re running nodes I highly recommend the app, it will generate a single curl command that will collect all the system and application logs, metrics, and docker data automatically. There is no need to install different software for the logs, metrics, docker data etc, Splunk can handle all types of machine data.


As expected the network was still not happy with so many nodes down. In addition, Nimbus clients had a sync bug as well and some testers were shutting down their Medalla nodes to join Zinken without properly exiting. Since the Beacon Chain requires 66% network participation for it to reach finality the network is going to be unhealthy until these nodes fall below 16ETH (from slashing) and are kicked off the network. This is unlikely to happen on mainnet because validators will be losing real ETH and will properly exit. The more concerning attribute is that the Prysm Alpha.29 release represented over 33% of the Medalla network and most clients haven’t applied the hotfix. Breaking down by client version across all nodes the Nakamoto coefficient is 5, meaning that the top 5 client versions makeup >51%. The Alpha.29 clients represented less than 51% of the network but still caused issues, perhaps the term “Buterin Coefficient” should represent the minimum number of entities in a given subsystem to get >33% of the total capacity. :)
What we learned: Real-time Lorenz curves and Gini coefficients look cool but having alerts for the Nakamoto/Buterin coefficients could enable proactive resolutions of network issues before they become a problem. Using basic machine learning would enable even greater proactiveness by detecting outliers or forecasting if/when the network will have issues. Basically moving from level 1 to level 2 of data maturity in the Operational Intelligence Curve.

Understanding the Health of the NetworkCompiling all of the searches, dashboards and alerts into one place was the inspiration for the OPs dashboard. We needed to bring the KPIs together but also provide a way to drill down into each sub area (by clicking on the mini dashboard images or KPIs themselves) in order to understand why a chart or KPI might be abnormal.
The top row is meant to display generic statistics across the board whereas each quadrant surrounding the overall health score focused on a specific area such as staking activity, node and client statistics, validator analytics and finally data feed health (see more about data health at the end of the post!)
Starting at the top left is transaction activity. Using the open source Splunk Connect for Ethereum we were able to ingest and continually analyze transaction activity - in this case we specifically looked at the deposit contract address. By focusing on the deposit contract address we could determine the who, what, and how often when it came to deposit activity (great for finding whales and patterns of transactions). This eventually became one of the many gini coefficients we calculated for the main dashboard.

[Deposit Activity for the Medalla Testnet]
The lower left quadrant focused on eth2stats. Ethereum 2.0 beacon chain clients can optionally export their health metrics to eth2stats.io. We started by scraping the data exposed by this portal to understand the make up of the network among actively reporting nodes. While similar to the eth2stats.io website, we could now add and correlate this data with everything else we were collecting and further drill down to the nodes we stood up to see system level logs and metrics. This proved to be very useful when problems arose like the one earlier in the post.

[eth2stats vSplunk]
Having these stats available both historically and in real-time allowed us to calculate some high level KPIs for the main operations dashboard such as average uptime of all nodes, connected peers over time and a live ratio of syncing nodes. For example, below you can see that as the Prysm Alpha.29 client was adopted the % of fully synced clients diminished.

[status of syncing nodes]
Another area we found interesting was the average memory usage of each client and their versions. Did memory usage improve over time with new version releases? Which client type uses the most?

[Average Memory Usage by Client and Version]
The upper right quadrant focused on Validators, attestations and slashings.
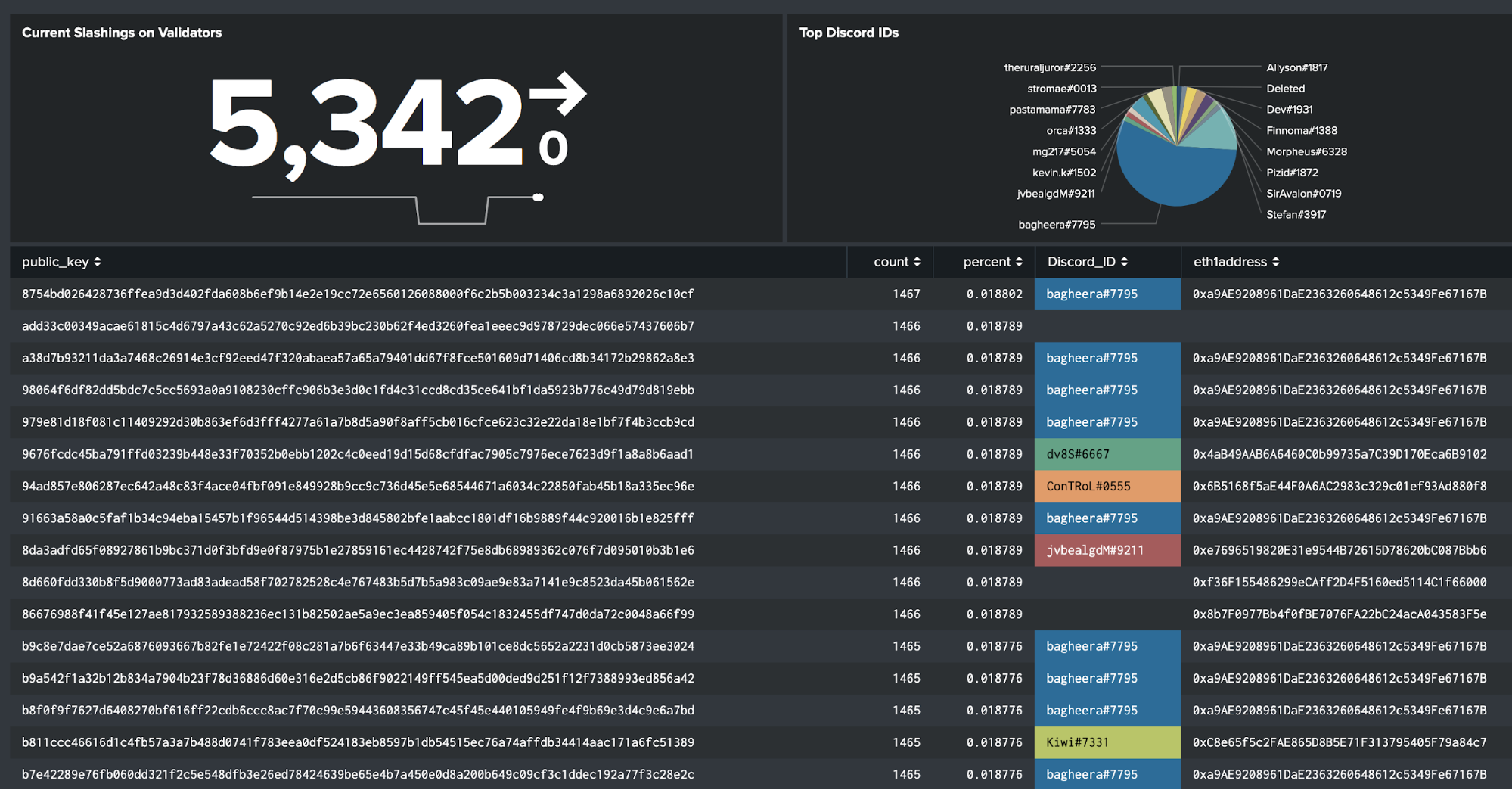
[Slashings correlated with Discord usernames]
Notice that many of the public keys have a Discord_ID. We found that validators deposit ETH into a deposit contract associated with their BLS public key. This allows each validator to use a different BLS key. However, would a single ETH1 address hold multiple validator keys? What was the repartition like? To analyze this, we used the Splunk Connect for Ethereum suite to run a Hyperledger Besu connected to the Goerli network, decoding the calls to the deposit contract using our ABI decoding feature. The team there set up a channel for folks to request funds for eth1 addresses. Using this approach, we correlated Discord handles requesting funds to the eth1 addresses. Joining all this data together, we associated validator keys to Discord handles. We identified an issue with a couple validators and were able to reach out to them on Discord to let them know. This could easily be automated with a splunk alert to send a Discord message to users if they opted for it.
When looking at slashings, we saw that a subset of users were being slashed, and had been for quite some time. We could see that those users had made a correct deposit, had run validators for some time, but eventually went offline. They kept being slashed as they didn’t exit properly from the contract by calling the voluntary exit contract. The voluntary exit contract also does not guarantee that they can stop validating right away. This pushed us to look at the number of voluntary exits on the network. We noticed very few had exercised this option.

Another interesting aspect was monitoring graffiti obtained from the block proposers. Some simple decoding right in the Splunk search processing language (SPL) allowed for an easy word cloud along with the top 3 always being present on the main operations center dashboard.

None of this is possible without data so we decided it was important to monitor the health of each data source and feed as well. Determining the nominal behavior of each source allowed us to create a health score and be alerted if any issues arose. This ended up helping us several times throughout the hack when either nodes or their logging/metric components failed.

[Real-time Data Health Dashboard]
Secure blockchains provide incredible levels of data integrity. Often we see organizations write scripts to take data off-chain and put it in a relational database or similar for analysis. At this point the data can no longer be trusted because it can be altered. That’s why we hashed all the data as it was ingested and stored this hash and some metadata on-chain. This enables the verification of the integrity of all the data in Splunk, which means users can trust but also verify the data in splunk by computing and comparing the hash with what’s on chain. For example this transaction shows a “bucket” of data and the hash associated. Which of course could also be seen in Splunk using Splunk Connect for Ethereum.

Think about that for a second. Off-chain, on-chain, and cross-chain data can be indexed into Splunk and the ledger can verify the integrity of the data. As Splunk ingests the ledger data it uses the ledger itself to improve the trustworthiness of the data in Splunk.
We hope you enjoyed the blog posts and insights. In just a few days we feel we’ve barely scratched the surface - but it’s a start. Splunk allowed us to dive right into asking questions without worrying about data formats, velocities and input methods. If you would like to try this out for yourself you can try a docker-compose example with both the open source Splunk Connect for Ethereum and a free version of Splunk. Additionally feel free to ask us questions at blockchain at splunk dot com.
– @dataPhysicist and @ArbiterOfData
We are not (yet) Ethereum 2.0 experts and there might be inaccuracies in our analytics. Our goal was to have a little fun learning about Ethereum 2.0 and hopefully provide some useful examples on how to use data to gain observability of the Medalla testnet.
----------------------------------------------------
Thanks!
Nate McKervey

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
