
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Skipped searches are a bane of existence for many Splunk Administrators. Often searches are skipped because the load on the system is higher than available resources and there is a need to either increase system resources or reduce the workload. However, plenty of times the skipped searches may be reduced by configuring Splunk correctly. In this blog, I will review the search concurrency model in Splunk and go through a systematic way to identify various reasons for skipping and how to remedy them.
First, let's understand the search concurrency model for Splunk. I will primarily focus on the historical searches but some of this discussion is also valid for real-time searches.
Splunk restricts the number of concurrent searches running on the system. We can think about this as search slots.This is done to protect the system from thrashing and grinding to a halt if search workload is much higher than resources available. By default, the system total max concurrency (max search slots) is calculated based on the number of CPU cores on a search head (SH) or across search head cluster (SHC). There are scheduled searches and ad-hoc searches that use these search slots. There is a default limit of the search slots that scheduled searches can use but there is no default limit on ad-hoc searches. It means that ad-hoc searches can use up to the max search slots, essentially leaving none for scheduled searches. Some of these calculations are shown below for a single search head but this can be easily extended to a search head cluster:
Total max concurrency = <max_searches_per_cpu> x number of CPU cores in SH/SHC + <base_max_searches>
Max concurrent scheduled searches = <max_searches_perc> x total max concurrency
Max auto-summarization searches = <auto_summary_perc> x max concurrent scheduled searches
Default Values are
max_searches_per_cpu=1
base_max_searches=6
auto_summary_perc=50%
max_searches_perc=50%
Having said this, there is a new feature in Splunk Cloud Platform using which you can limit ad-hoc searches such that they do not take away all search slots.
There are many reasons why searches are skipped. It is very important to understand why searches are skipping. You may run the search below to find the reasons.
index=_internal sourcetype=scheduler savedsearch_name=* status=skipped | stats count by reason
If you have programmed user or role quotas, certain searches may skip if these quota limits are breached. This is the intended function of quotas - to limit the number of concurrent searches a user or users within a role can run concurrently. If you need to remedy this, you may change the user or role quotas. Sometimes you will also see that searches from certain users are skipped because they don’t have permissions to run scheduled jobs. Here is a good resource on this.
Scheduled searches run at a certain frequency (e.g. every 5 minutes) and by default only 1 instance of a scheduled search can run at any given time. This is defined by <max_concurrent> in savedsearches.conf file and generally, you don’t need to change this attribute to more than 1 (default). If for any reason, a scheduled search job cannot be completed before the next period starts, it will be skipped. For instance if a job takes 10 mins to complete and runs at a 5 min frequency then it will skip. To remedy this, first you need to identify which scheduled search(es) are skipped due to this reason and then:
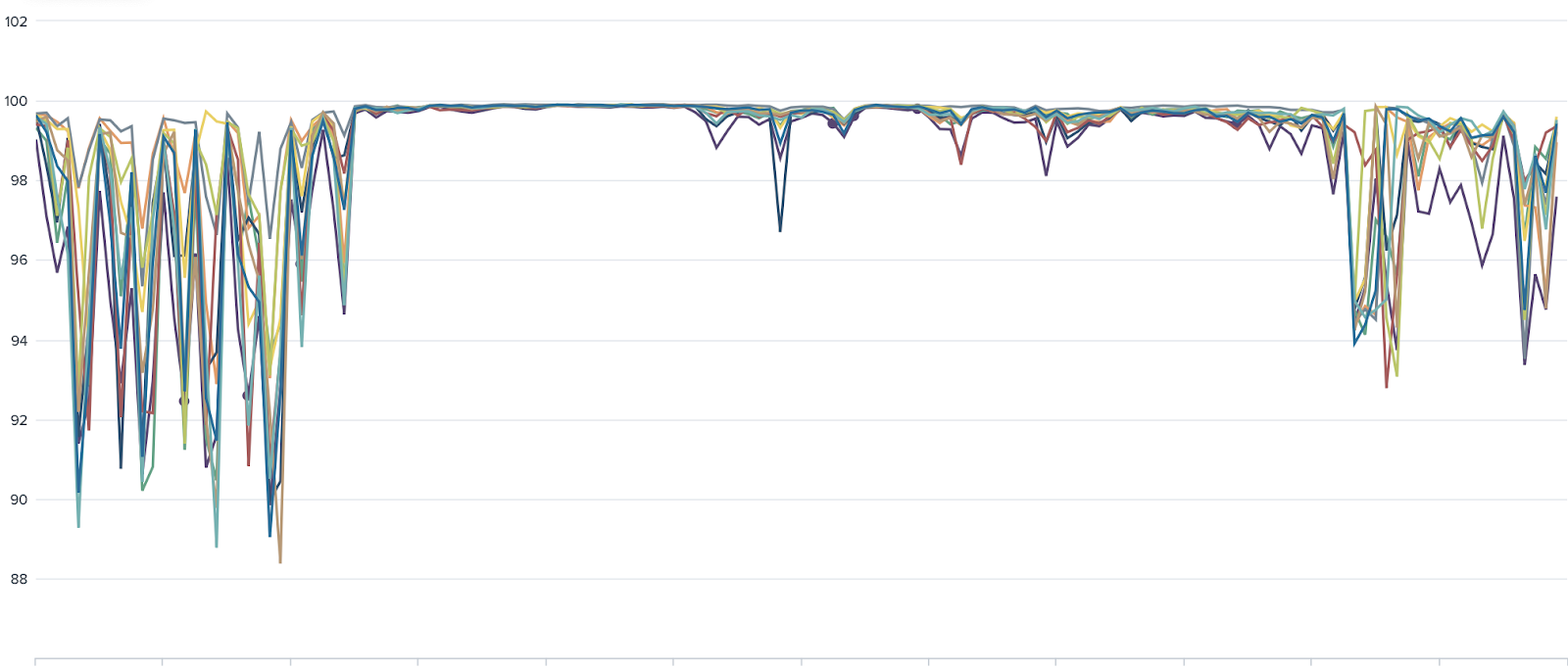
For example, you may run the search given below or look at the monitoring console to figure out CPU utilization on indexers. If the output looks like below, you know why searches have a long execution time and that you need to add more indexer resources.
index=_introspection host=idx* component=Hostwide | eval total_cpu_usage = 'data.cpu_system_pct' + 'data.cpu_user_pct' | timechart span=10m perc95(total_cpu_usage) by host
Example of high CPU utilization on the indexers
As explained above, the number of summarization searches that can run concurrently is capped and that limit is defined by <auto_summary_perc> in limits.conf file. This attribute may be raised to 75% to allow auto-summarization searches to be a higher percentage of overall scheduled search limit and hence reduce the skipped searches.
Also, check if you are seeing skipped searches at well defined time such as top of the hour or 30 minutes past the hour. It means you have scheduled too many searches at the same time. A way to resolve this issue is to allow the scheduler to optimize search dispatch time by setting <allow_skew> or <schedule_window>. Paul Lucas has written a great blog, Schedule Windows vs. Skewing, on these two settings.
This is the most common reason for skipped searches. This happens because the searches have taken all available search slots and hence new searches cannot be scheduled.
As mentioned above, check if your search schedule aligns at specific times (e.g. 1PM, 1:15PM, 1:30PM etc.). If this is the issue you may try to use the <allow_skew> or <schedule_window> settings as explained in this blog
As mentioned earlier, by default ad-hoc searches can use all available search slots leaving none for scheduled searches. To ensure this is the real cause, find out if there is a pattern to skipping by using the search below. And then correlate the periods of high skipped searches with the number of ad-hoc searches running. If this is an issue, you may limit ad-hoc searches to a percentage of total max concurrency using the new feature in admission rules.
index=_internal sourcetype=scheduler savedsearch_name=* status=skipped | bin _time=1h | stats count by _time
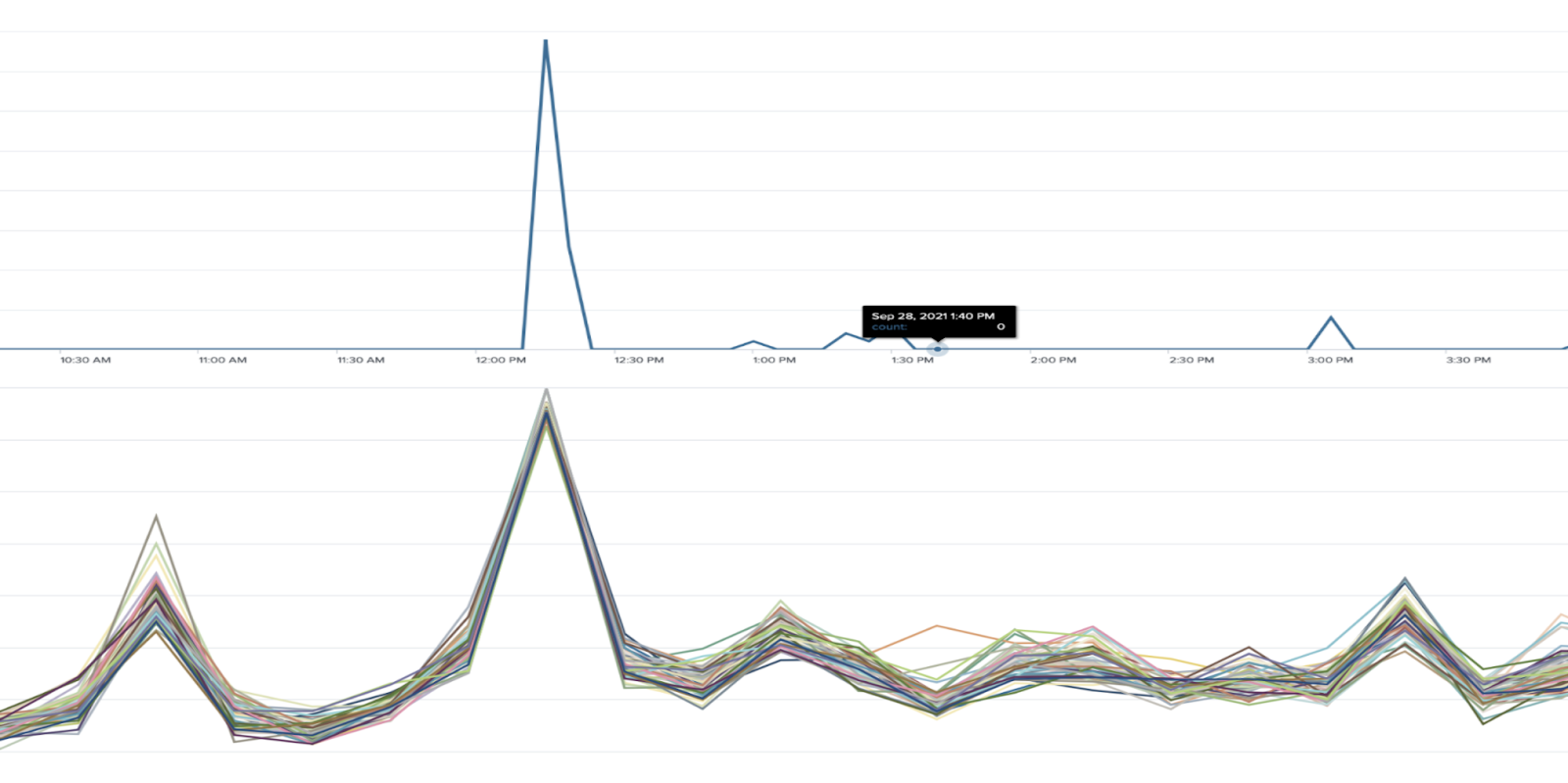
Most part of a search runs on indexers. If indexers are bottlenecked due to too many searches or poorly written searches (causing cache churn) or high ingest load, the searches may take longer time to complete. Hence, they will hold the search slots for longer and new searches cannot be dispatched causing skip. To ensure this is the real cause, find out if there is a pattern to skipping by using the search above. And then correlate the periods of high skipped searches with the CPU utilization of indexers. The best option is to add more capacity to the indexer tier.
Example of skipped searches correlating with indexer load
Many times the default max concurrency limit is too low for a workload environment. Especially, if you have short searches (e.g. ITSI app), you may want to raise this default limit by increasing <max_searches_per_cpu> in a range of 2-5 in steps. Before increasing this, check if the indexer and search head CPU utilization is low enough (P95 < 50-60%).
The concurrent scheduled searches are limited to 50% of the total maximum concurrency by default. If you are not running too many concurrent ad-hoc searches, you may just want to raise <max_searches_perc> from 50 to 75% or higher. This will not help if ad-hoc searches increase as they will overrun the scheduled searches unless you use the new feature to limit ad-hoc searches as described above.
To finish, reducing skipped searches depends on identifying the bottleneck in the system. Some bottlenecks are soft (software configuration related) and others are hard (system resource limits) but identifying them can help solve for skipped searches more efficiently. As a next step, analyze your Splunk system for skipped searches and check if you can implement some of the suggestions listed above to improve skipped search ratio.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
