


Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Splunk is committed to using inclusive and unbiased language. This blog post might contain terminology that we no longer use. For more information on our updated terminology and our stance on biased language, please visit our blog post. We appreciate your understanding as we work towards making our community more inclusive for everyone.
A common challenge that I see when working with customers involves running complex statistics to produce descriptions of the expected behaviour of a value and then using that information to assess the likelihood of a particular event happening. In short: we want something to tell us, "Is this event normal?". Sounds easy right? Well; Sometimes yes, sometimes no.
Let's look at how you might answer this question and then dive into some of the issues it poses as things scale-up:
This machine is sending lots of logs. Is this normal?
This user has logged in at 1 am. Is this normal?
We've seen a network communication with this particular signature. Is this normal?
The answer to these questions invariably requires us to define what we mean by normal for any given query. Thankfully, in some cases, this can be a pretty easy thing to do:
Here's what that might look like with some sample data and SPL if you're not thinking about it too hard:
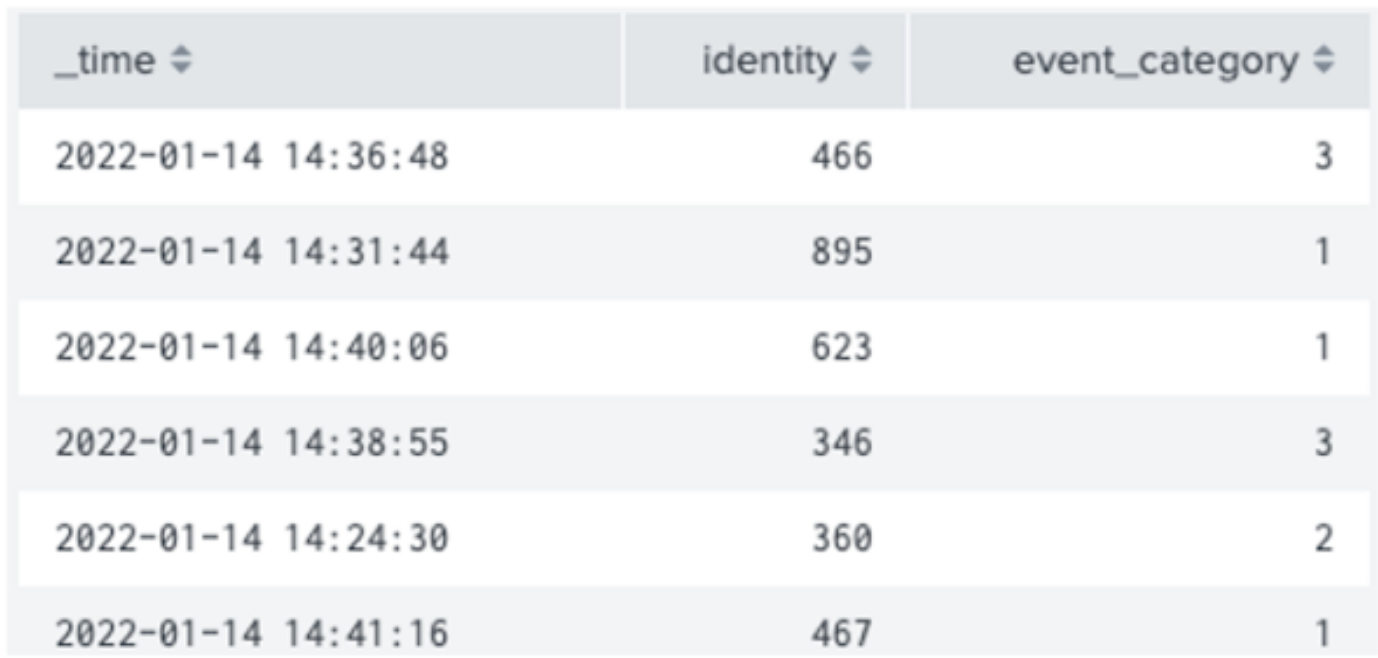
Input Data Table - Events with identity (hostname) and event_category (could be anything that we want to assess the likelihood of).
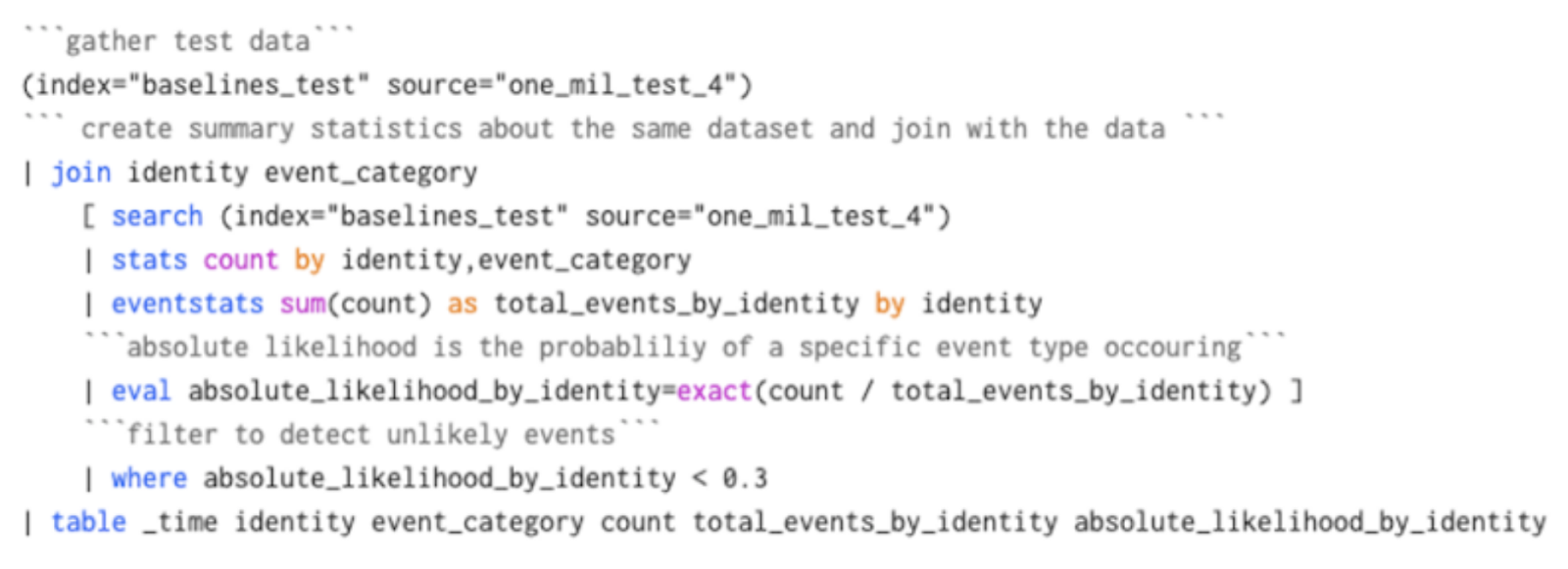
Search - Assesses statistics of dataset and joins back against initial dataset
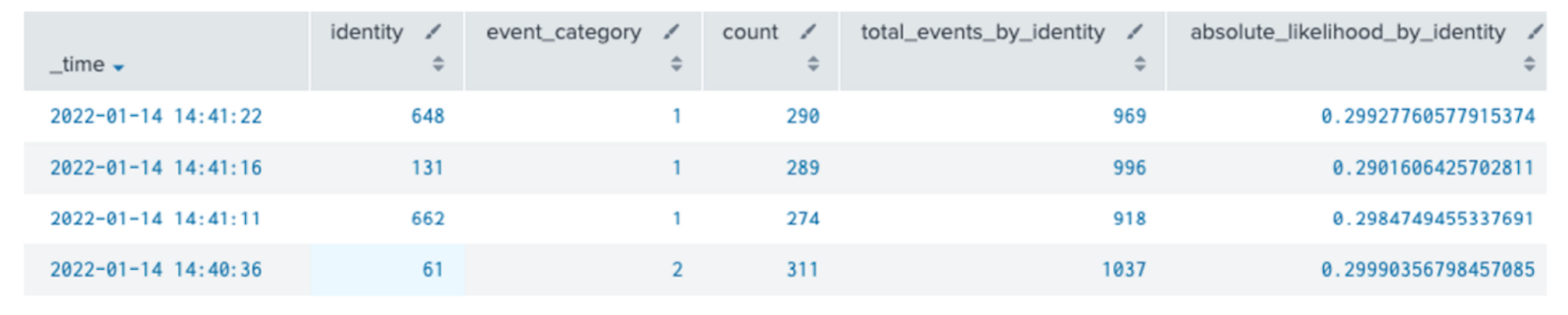
Output Data Table - A set of data with associated event likelihoods for each event category on each identity (host).
In this approach, we count up the occurrence of an event in our dataset by identity, using the "stats" and "eventstats" commands. We then "join" it against our search to work out how likely each event is for each identity. You'll get similar results using the "anomalydetection" command, and it's an equivalent level of computational effort as well. This seems to be a perfectly reasonable solution, and it is for small numbers of identities or categories and small datasets!
What happens when we go beyond our friendly controlled test environment, though? How does this fare when faced with 10s of millions of events and millions of identities or event types? Hint: Things start to break.
This initial methodology applied to this dataset has challenges that prevent it from being applicable at scale. This approach is commonly implemented in ways that aren't ideal for Splunk to efficiently process. Implementations of methods like this may try to use "join" and "append" or "union" commands with sub-searches. Unfortunately, such commands often lead to memory or event buffer size limits when trying to scale up.
Another issue we can see here is that we're scanning a wide time range to compute our likelihood values in the same search as calling up the data to join them against. This can be more than a bit annoying, as what if I want to run this anomaly detection hourly but calculate my reference likelihoods from a week, month or even a year's worth of data? Do I really have to compute those likelihoods across that whole dataset every time? Of course not!
We can definitely improve on this, and there are just three tricks to it:
Initial Approach: A scheduled search takes data from an index and compares it to historic data in the same index. When anomalies are found, alerts may be generated.
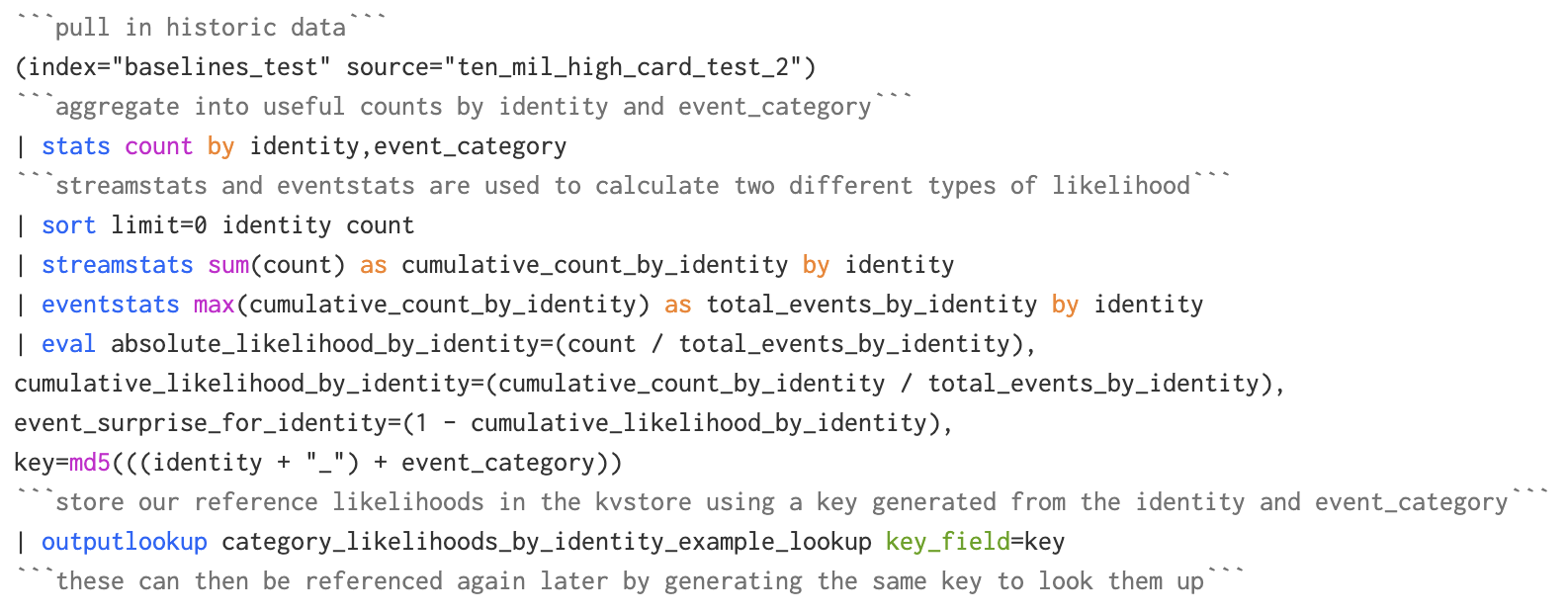
Modified Methodology: A scheduled search creates per-identity key-value pairs representing historic identity behaviour (counts of events and calculated likelihoods) on an infrequent basis and saves them into the KVStore. A second scheduled search which runs more frequently compares the new data with the stored statistics with high efficiency even at large scale and high cardinality.
All of this can be done in addition to other optimisation methods such as using tstats and creating accelerated data models. In addition, these tips don't stop at this kind of likelihood comparison calculation and can be customised into many different data processing pipelines for significantly increased efficiency.
So hopefully, those ideas whet your appetite. However, if I've not convinced you to look into these topics further just yet, let's investigate the kind of improvements we can create with some performance testing.
My reference data for this test consists of many records, each with an identity containing several hostnames (identities) and an event_category that may take on several values. I aim to calculate the likelihood of seeing any particular event compared to the more likely events for each identity.
We will compare the method described initially against the improved methodology (for which an example is provided at the end of the blog).
I've created several datasets to test against varying data scales; 1 million events and 10 million events in "low" and "high" cardinality configurations. I've used these datasets to test the computation time to apply each of our methods. Lastly, I've used this information to predict the total time it would take to compute on a single day in my test environment, assuming that I want to run an anomaly detection search each hour and look for the least likely events.
Number of Events | Max Number of Distinct Identities | Max number of Distinct Event Categories Per Identity | Initial Approach Daily Computation Time | Modified Methodology Daily Computation Time | Reduction in Computation Time |
1 Million | 1000 | 8 “low” cardinality | 1,015s | 71s | 92.9% |
10 Million | 1000 | 8 “low” cardinality | 15,496s* | 901s | 94.2% |
1 Million | 1000 | 1000 “high” cardinality | 946s* | 121s | 87.1% |
10 Million | 1000 | 1000 “high” cardinality | Search Fail** | 1200s | - |
As you can see, there are some significant improvements to be had! Our improved methodology is nearly 10 times faster in almost all the tests! In addition, several of the initial method tests hit memory or timeout limits(*) inherent to sub-search usage. This leads to returning incomplete results or alternately outright failed(**) searches! In production environments, I've seen this sort of methodology have many times more significant improvements than I've seen here, as the benefits can scale with the size of the problem.
Now that I've managed to convince you it's worth it (I assume I have, right? I mean, look at those numbers!) Here's an example of the searches used to compute the modified method described above.
Above, you can see the search used to create our reference statistics by identity and event category. These are stored in a KVStore collection, using a custom _key field. This might be executed daily over several days/weeks/months worth of data in off-peak hours. You’ll need to create a KVStore collection and lookup definition to let you do this.
This second search then allows us to look up our pre-computed statistics for a given event and apply a threshold to find only the most unlikely ones. It can be scheduled to run very frequently, as all it does is look up a specific identity-event_category pair in the KVStore lookup we created above. We can then filter based on one of our calculated likelihood values. You could potentially even turn something like this into an automatic lookup, folding in relevant statistics about whenever your data is queried. Where we have no match on our lookup, we can surmise that we've never seen that particular identity-category combination before.
In this particular example, I've gone a bit further than the initial search and included a couple of different likelihood calculations, which can be helpful in a variety of use cases. I'll be breaking this down in more detail in some upcoming content. I've seen these kinds of likelihoods used for detecting anomalies in user behaviours (has this person done this before?), system behaviours (does this machine usually send traffic like this at this time of day?) and transactional analysis (do we typically ship this many units to these addresses?). A common approach to building out this kind of anomaly detection is to use these methods to define several different behavioural detections, which can then be aggregated to identify clusters of abnormal usage that might indicate a significant threat. This is similar to the approach taken by Splunk's RBA and UBA and, indeed, can be used in conjunction to build effective detections.
And that's it! If you want to take it to the next level again, you can think about how you might update the KVstore rather than completely recalculating our statistics daily, or just reach out to me, and I'll show you how! If you found these ideas and this approach helpful, please let me know on LinkedIn!
For more information on optimising away your joins, check out this tremendous .conf talk from 2019.
You can also see this approach applied for a slightly different use case in this whitepaper published by our SURGe team on detecting supply chain attacks using JA3.
Thanks very much to my global colleagues in the ML Architect team, Philipp Drieger, Jason Losco, Phil Salm, and our fearless Product Manager, Greg Ainslie-Malik. Also to many of my colleagues in SURGe, but specifically Marcus LaFerrera, my colleagues in the UK Architect and CSE teams: Darren Dance, Stefan Bogdanis, Rupert Truman and Ed Asiedu, and the many others who contributed to the approach and ideas outlined in this blog.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
