
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Last time, I wrote about Benford’s Law, which allowed a system to see the distribution of the first digit (or 2nd or 3rd) of any naturally occurring dataset to see if it deviates from expected behavior to look for manipulation of the dataset. Today, I’ll move onto Zipf’s Law — which is more a frequency reduction observation than a law — to look for possible indicators of fraud.
To put it simply, Zipf’s Law states that in any word based language, there will be one word that has the highest frequency of usage compared to other words in the language. The next highest used word will be half the frequency for usage compared to the most common word. This pattern continues down the line for all words in the language. In English, the most common word is “the” and the next more common word is “of.” “The” is used 7% of the time, while “of” is used 3.5 % of the time. The next most common word is “and” and it is used 2.8% of the time. Zipf’s Law is not literally to be taken into account as the distribution is not always half the previous word frequency, but there is a downward pattern.
This can have implications in cyber security. For instance, one outbound IP address from a corporation will have the highest frequency, while the next highest outbound IP address frequency will be nearly in half. This downward spiral will eventually lead to rare outbound IP addresses completing the pattern of Zipf’s Law. It is these rare IP addresses that may make for notable events as to why they were used and was some phishing scam or embedded bot leading to their appearance? Automatic threat intelligence can be applied to these least frequently occurring IP addresses via SOAR products to see if they are a cause for concern.
Zipf’s Law applies in several possible ways for fraud detection. For example, within Splunk products, we often assign risk scores to fraudulent patterns of behavior. If an aggregate risk score goes over a predetermined threshold, the result may be that this entity has engaged in fraudulent activity. Fortunately, most aggregate risk scores do not go over the threshold, which means only a partial set of entities will need to be judged upon and investigated. Here’s a distribution graph.
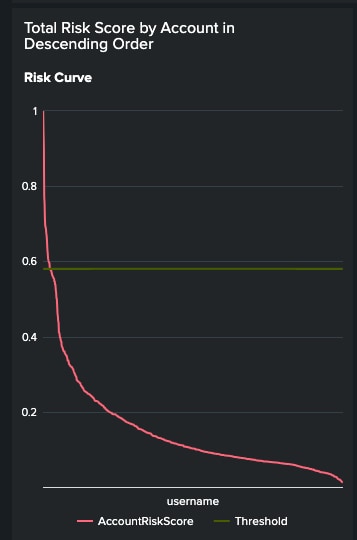
Descending Risk Scores Per Username
Notice the descending pattern in this distribution follows the Zipf’s Law ideas. In this case, the investigations will be for the highest occurring aggregate risk scores rather than the lowest ones as they are probably benign in a system that accurately measures risks.
Let’s change the use case to wire transfer. On any given day, a wire transfer may occur from one bank to another bank in another country. The pattern of distribution of frequencies for the count of countries appearing as the recipient country will be descending and follow a curve similar to Zipf’s Law. There may be some countries that rarely appear on that day as the recipient country. In fact, that country may appear only once for the entire day. In Splunk we can use the rare command to see this.
index=transations sourcetype=wire_transfer|``` transformation, where clauses, etc|rare destCountry|sort - count
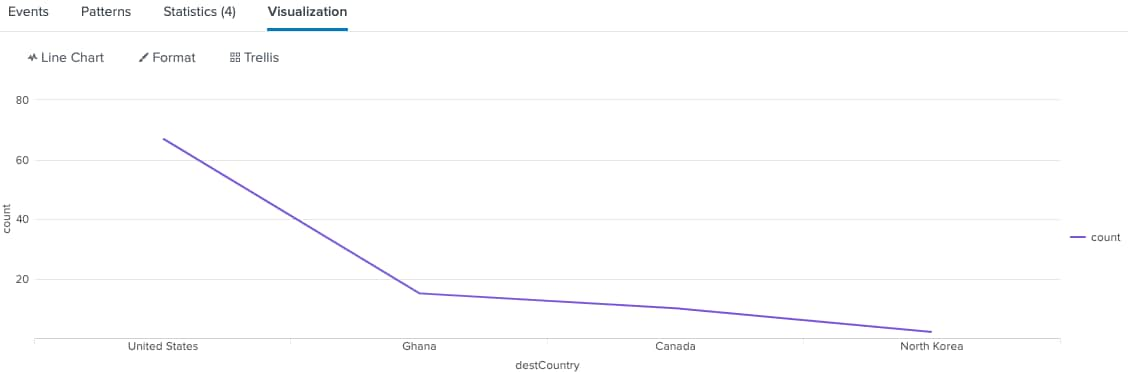
Descending Order of Wire Transfer Recipient Counties
In this example, we are using the rare command to count the frequency of the rarest countries that are the destination countries of a wire transfer. Because rare returns count sizes least to highest, in order to be consistent with our other charts, we sort the results from highest to lowest in the chart. This doesn’t exactly follow Zipf’s Law in the literal sense, but it does show a reduction curve that follows the law in spirit. What is missing here is context for the transaction such as the account name, the amount, etc. Let’s add that into the search.
index=transations sourcetype=wire_transfer|``` comment: transformation, where
clauses, etc|stats count, list(_time) as Time, values(customer) as
Customer, values(FromAccount) as FromAccount, values(ToAccount) as
ToAccount, values(action) as action, values(amount) as amount by
destCountry |where count=1|eval RiskScore_DestCountry=30

In this example, we are using the stats command to save context for the transaction so it can be used to feed an alert or collect into a risk index. We no longer need to use rare as just counting the destination countries’ frequency can get us the rarest count and in our case the rarest count is exactly one as zero would be meaningless. In the end, an arbitrary risk score is added to the results of the search so that it can be stored in a risk index for further aggregation of risk scores against the same entity.
The idea here is that most wire transfers will occur more than once to a country where wire transfer is expected due to the nature of the business and connected entities. If a wire transfer only occurs once for a country in a day, it may be suspicious. This does not mean it is fraud, but it does add to the risk. This additional risk score may be the one that tips the aggregate risk score for the entity over a predetermined threshold due to other risk scores for the entity, which then means it is probably fraud. We have used the pattern of Zipf’s Law to help determine risk in this instance, which then helps determine possible fraud, when combined with other risky actions.
Zipf’s Law is a reduction graph that is applicable to many types of data. It can be applied to topics of cybersecurity and fraud detection. Notice that it is not always the lowest frequency occurrence that needs to be investigated as in some cases it is the highest frequency occurrence that is notable. With Splunk’s rare and stats commands, one can easily determine frequency counts for any variable to understand its pattern of distribution. The rarest frequency may be the most suspicious in some cases and this may result in an added risk score for the transaction. This risk score will be useful, when combined with other risk scores for more genuine fraud detection. For instance, suppose the same entity cited for wire transfer to a country rarely used as a destination also failed login multiple times before succeeding and changed their password before initiating the wire transfer.
Each of those actions should generate a risk score. If we add up the risk scores, we would get:
TotalRiskScore=RiskScore_DestCountry + RiskScore_LoginFailures +
RiskScore_PasswordChange
This would most likely trigger a total risk score over some predetermined threshold indicating the likelihood of fraud. In Splunk Enterprise Security, the use of Risk Based Alerting would make this a streamlined process. In Splunk Enterprise or Splunk Cloud Platform, it can still be done, but with additional Splunk commands to manage a Risk Index and to create an alert. In either case, a SOAR product could initiate further actions for the alert, one of which would be to block the wire transfer from happening. Hence, our approach for adding in risk factors using rare events leads to better fraud detection and prevention.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
