
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

The rarity of certain events is a strong indicator of potential cybersecurity threats. Splunk User Behavior Analytics (UBA) includes several offline models to analyze the rarity of logged events, helping analysts utilize this signal to monitor the ever-evolving cybersecurity landscape. These rare event models are designed to detect anomalies by sifting through vast amounts of data, encompassing a multitude of events and their associated entities, such as users, devices, and apps. However, this extensive data processing can lead to significant challenges, particularly regarding memory usage. High volumes of data can cause performance degradation, primarily due to the limitations of Spark executors' RAM capacity. For instance, it has been observed that executing one of UBA's rare event models, the "Rare VPN Login Location Model," could shuffle ~77 GB of data for processing 200 million events in a 7-node cluster:
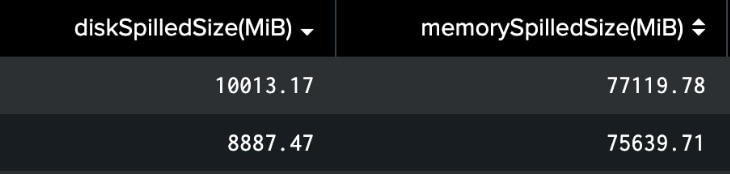
The UBA tool recognizes this issue and introduces the "cardinalitySizeLimit" configuration parameter. This new feature is designed to manage memory usage more efficiently, ensuring the system can handle large datasets without compromising performance. By setting limits on the cardinality size of all involved entities, this parameter helps to prevent memory bottlenecks, allowing the UBA models to run more smoothly and effectively. This blog post will explore how the "cardinalitySizeLimit" works, its impact on UBA performance, and how you can leverage this new feature to enhance your threat detection capabilities.
The Rare VPN Login Location model identifies unusual geolocations of VPN authentication sources by tracking geolocations as features and uses a machine learning algorithm to determine the rarity of a VPN login attempt. Unlike models that use multiple signals to track rarity, this model focuses on individual events that may contain rare values in single features. When rare values are detected, the model considers the number of concurrent occurrences and adjusts the anomaly score accordingly. Multiple rare values across different features may indicate a higher risk, leading to a higher anomaly score. To enhance anomaly detection, the model incorporates additional context from peer groups, including users and devices. It builds a profile of the peer group based on source geolocation or organizational units and compares feature values within the corresponding peer group. The model also calculates conditional rarity, considering certain features as conditions for the principal feature of source geolocation.
Additionally, it tracks the frequency of rare logins and the number of entities (users and devices) that have performed similar logins. This helps the model handle situations where geolocation might be unusual for each user in environments where users typically perform network logins. Even if an interactive login is rare for each user and potentially their peer group, the model can recognize that multiple users are having interactive logins over various days and can reduce the anomaly score or optionally discount it entirely. This complex context modeling involves a large number of entities, imposing a heavy burden on Spark jobs to execute this offline batch model.
The data from various entities necessary for context modeling is stored in distributed nodes across a Hadoop cluster. As the number of entities increases, the frequency of data shuffling between nodes and between RAM and disk also rises. The Spark shuffle write process is a crucial component of distributed data processing, but it can become a significant performance bottleneck, especially in large-scale tasks. Shuffling occurs when Spark redistributes data across different nodes to ensure that each subsequent computation stage has access to the appropriate data partitions. This redistribution involves writing intermediate data to disk, which can be highly I/O-intensive and time-consuming. Monitoring this process is possible through UBA/Service Apps/Spark for the corresponding jobs, as shown below.
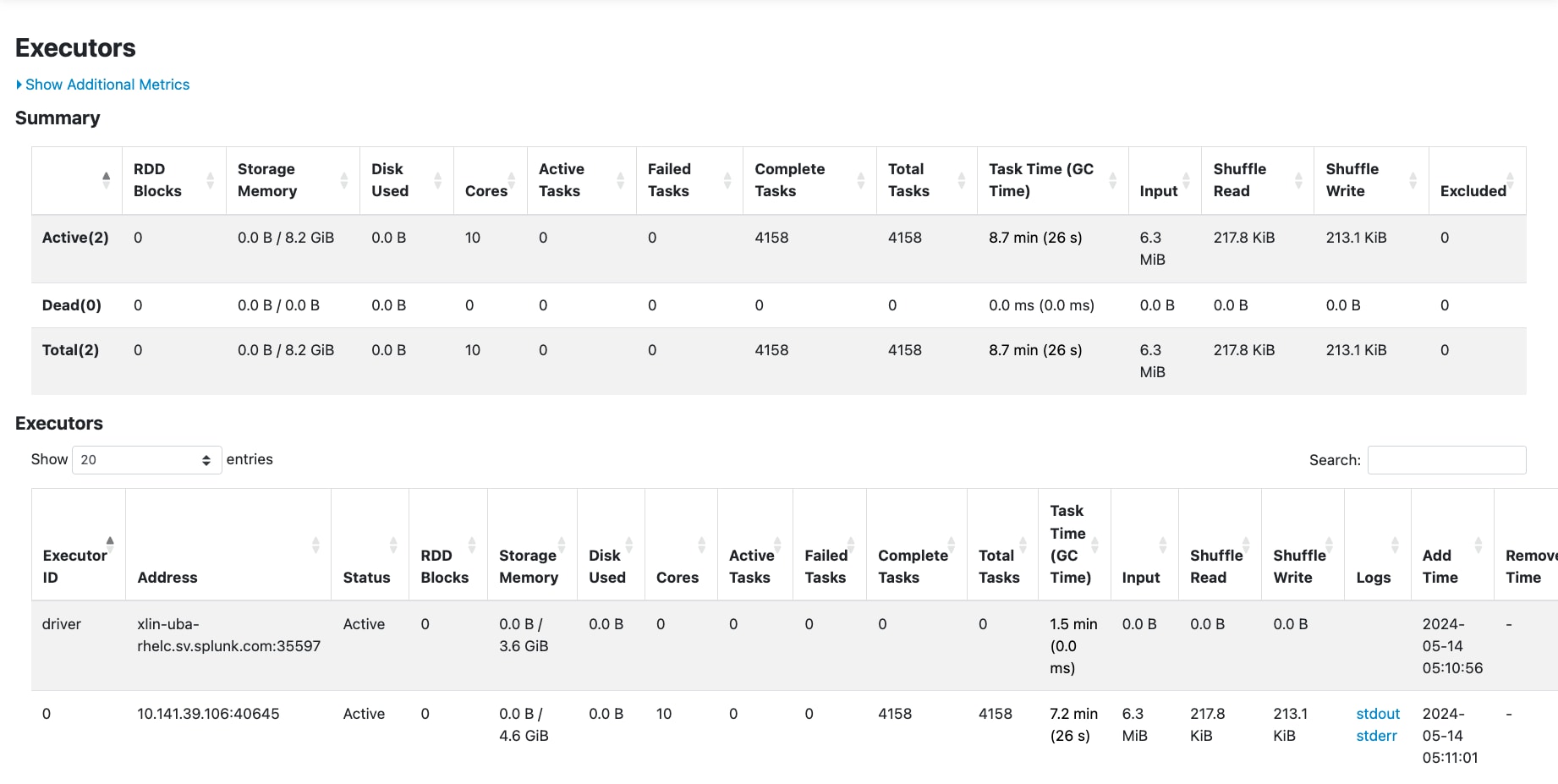
When a shuffle operation is triggered in a distributed computing environment, data from different partitions are combined and redistributed. This process involves writing the data to local disk (shuffle write) and reading it back during the subsequent stage (shuffle read). If the dataset being processed is large, the shuffle write phase can lead to substantial disk I/O operations, consuming considerable time and system resources. Furthermore, the network traffic generated by transferring large amounts of data between nodes can exacerbate latency issues, especially in environments with limited bandwidth. Excessive shuffling not only prolongs execution times but also puts additional strain on the system's infrastructure. High disk I/O can slow down other processes running on the same nodes, reducing system efficiency overall. Increased memory usage during shuffle operations can cause out-of-memory errors or necessitate frequent garbage collection, further degrading performance. Additionally, excessive shuffling can lead to network congestion, impacting the performance of other network-dependent tasks.
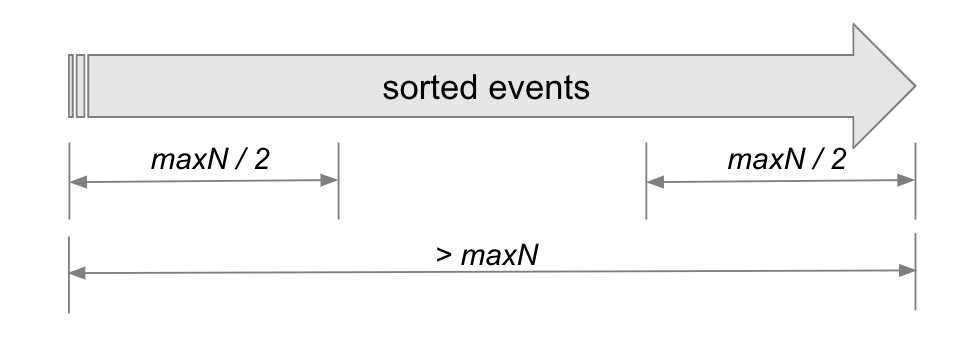
To address a memory usage bottleneck encountered during the execution of a rare VPN login geolocation model, we have introduced a new parameter called "cardinalitySizeLimit." This parameter sets an upper bound on the number of entities (maxN) the model will process. As illustrated in the figure below, if the number of entities exceeds the specified cardinalitySizeLimit value, the model will selectively process only the top and bottom halves of the sorted events, up to maxN/2 each. This approach ensures the model remains within resource constraints and operates efficiently, preventing memory exhaustion during execution.
The default value for cardinalitySizeLimit is set at 10,000,000. Users can adjust this value to any positive integer through the local model register file: /etc/caspida/local/conf/modelregistry/offlineworkflow/ModelRegistry.json. For example,

By fine-tuning this parameter to a sufficiently minimal value, the effectiveness of job shuffle read/write operations can be significantly improved, resulting in more favorable performance metrics, as illustrated in the figure below. This optimization facilitates smoother data flow and faster task execution, enhancing overall system efficiency and user experience. As long as the parameter is set large enough to encompass all related entities, this constraint will not adversely affect the detection accuracy of the rare VPN login geolocation model.

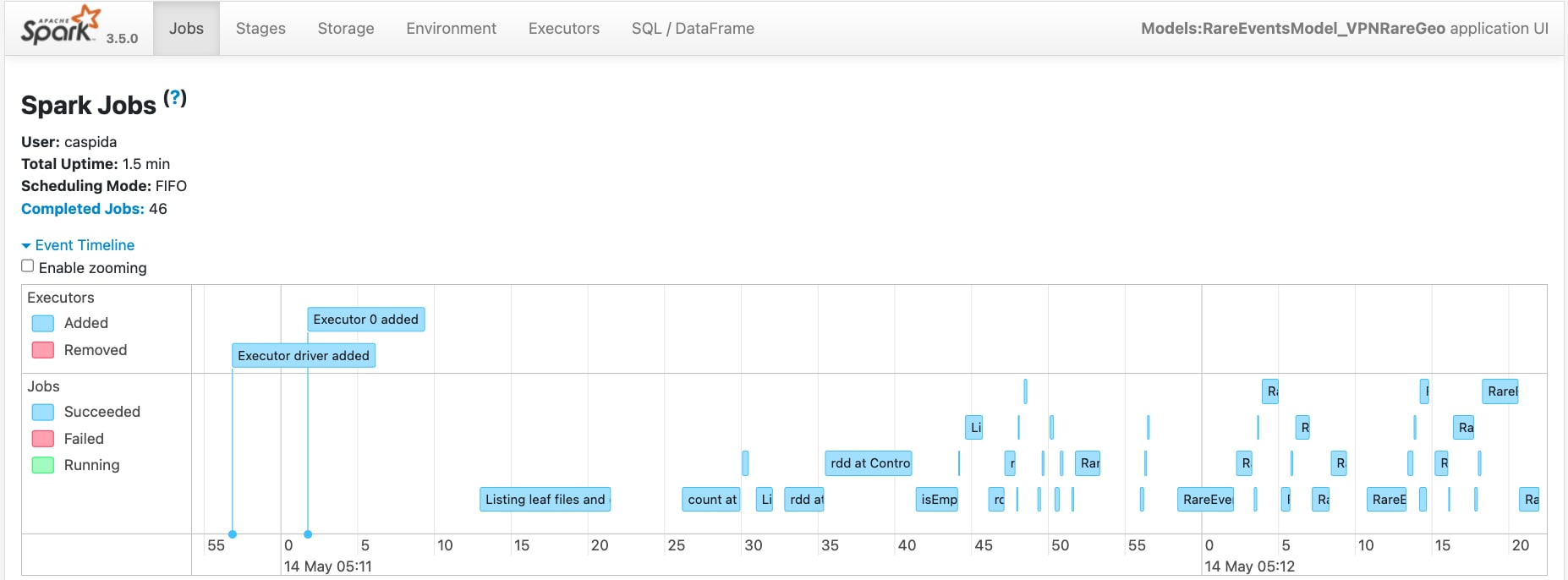
Another method to assess the performance of the rare VPN login geolocation model is by examining the execution of Spark jobs through the Spark History Server, as demonstrated below. In instances with no bottlenecks related to read/write shuffling, all stages of a distributed job are displayed in green, indicating seamless execution.
The new cardinalitySizeLimit configuration parameter can now be applied to all rare event models, as listed in the table below. This parameter can be specified separately in its own model definition block within the customized model registry file.
| RareEventsModel_HTTPUserAgentString |
| RareEventsModel_FWPortApplication |
| RareEventsModel_WindowsLogs |
| RareEventsModel_WindowsLogins |
| RareEventsModel_WindowsAuthentications |
| RareEventsModel_NetworkCommunicationRareGeo |
| RareEventsModel_VPNRareGeo |
| RareEventsModel_ExternalAlarm |
| RareEventsModel_FileAccess |
| RareEventsModel_FWScopePortApp |
| RareEventsModel_UnusualProcessAccess |
| RareEventsModel_RareEmailDomain |
| RareEventsModel_HTTPUserAgentString |
| RareEventsModel_FWPortApplication |
| RareEventsModel_UnusualDBActivity |
If you want to learn more about rare event detection models, refer to Splunk UBA documentation here.
Any feedback or requests? Feel free to put an issue in Splunk Ideas, and we’ll follow up. Alternatively, join us on the Slack channel. Follow these instructions if you need an invitation to our Splunk user groups on Slack.
Special appreciation is extended to Cui Lin and Ericsson Tsao for their dedicated efforts in conducting performance tests. Credit is owed to the Splunk Product Marketing Team for their invaluable support throughout this project.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
