
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.
Logs and other supporting data, like metrics and traces, have become one of the most important elements of observability in recent times. The ability to harness the power of this data has enabled teams to significantly speed up problem resolution by quickly understanding the root-cause of issues as well as enabling them to understand why a system behaves the way that it does. It can also be used for business analytics too; ranging from “why do our customers leave at certain parts of the journey” through to “are the marketing events that we are running successful?” As observability data is critical to the management of modern platforms today, the ability to manage that data quickly, easily and in a cost effective manner is key to ensuring the maximum value derived from it. I go into more depth of why log data is important and the key challenges of harnessing in my blog here.
Since the time of writing the previous blog, Splunk has announced the release of the new and exciting Ingest Processor technology which now makes it even easier to manage this log data. But, before we get into why this is an important piece of tech, let’s recap the challenges with harnessing log data generally and how Splunk helps solve them:
These challenges mean it becomes too difficult, too hard and too time consuming to harness this data and utilise the valuable insights it contains. This will result in issues taking longer to identify and longer to troubleshoot and fix them as the correct data isn’t available to the right teams.
Splunk has over two decades of experience when it comes to harnessing the power of log data, from both an observability, security and business perspective, with its award-winning data platform. The following unique principles explain the why:
1. Schema-at-read - At the lowest level, Splunk has built a platform where there is no requirement to understand the format of the data before ingestion; simply onboard the data into Splunk and start observing insights from it.
2. Search Processing Language (SPL) - SPL allows you to quickly search and interrogate the data, build out visualisations, use the machine learning toolkit to spot anomalies and forecast the future trends of that data and much, much more.
3. Correlation - one of the biggest challenges of harnessing data from these platforms is being able to correlate different data sets together - for example, what if I wanted to find the same user ID in multiple data sets to create a single journey? In Splunk this is easy - using the schema-at-read approach - this data correlation is quickly done at search time byusing SPL, by combining multiple data sets together.
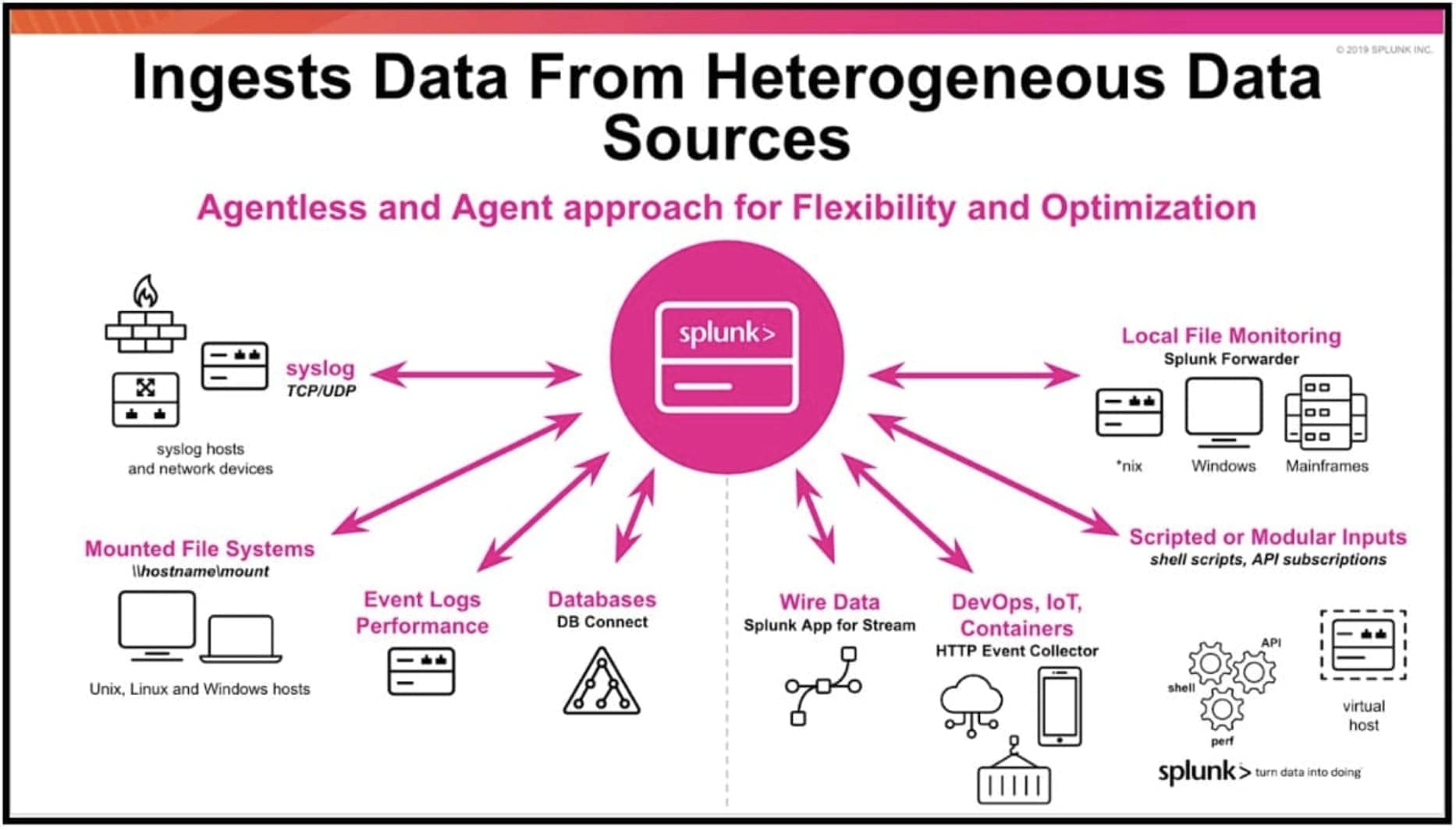
4. Lots of data sets (what Splunk calls GDI - get[ing] data in) - Splunk supports any human readable data into the platform. In fact, there are over 2000 technical add-ons and apps to assist with this - which are technology vendor, Splunk and community written and Splunk vetted - available on Splunkbase which makes getting data in even easier to do. And not just from agents; the platform supports agentless approaches too, as shown below.
5. Storage - multiple options to ensure the most economical approach to storing data securely and also ensuring it remains available.
6. Performance - Splunk’s data platform uses patented technology to quickly ingest, process, store, analyse and view the varied data sets across the observed platform as fast as possible, to ensure you receive your insights when it matters most.
What is the Ingest Processor? It is a new service that is part of your Splunk Cloud stack and it observes all the incoming data before it is ingested into Splunk. As it sits within the data stream itself, you can do some really cool powerful things to the data, essentially making your data much more valuable and focused on what you need it for. Another bonus is that it can aid in making your Splunk license far more efficient by not only ingesting the data you need for observability but also ensuring that you are ingesting the right data that really matters in both solving issues and providing intelligence of your platform. Once the data has been processed, the data is then forwarded to Splunk to be ingested into the Splunk data platform.
The benefits of Ingest Processor include:
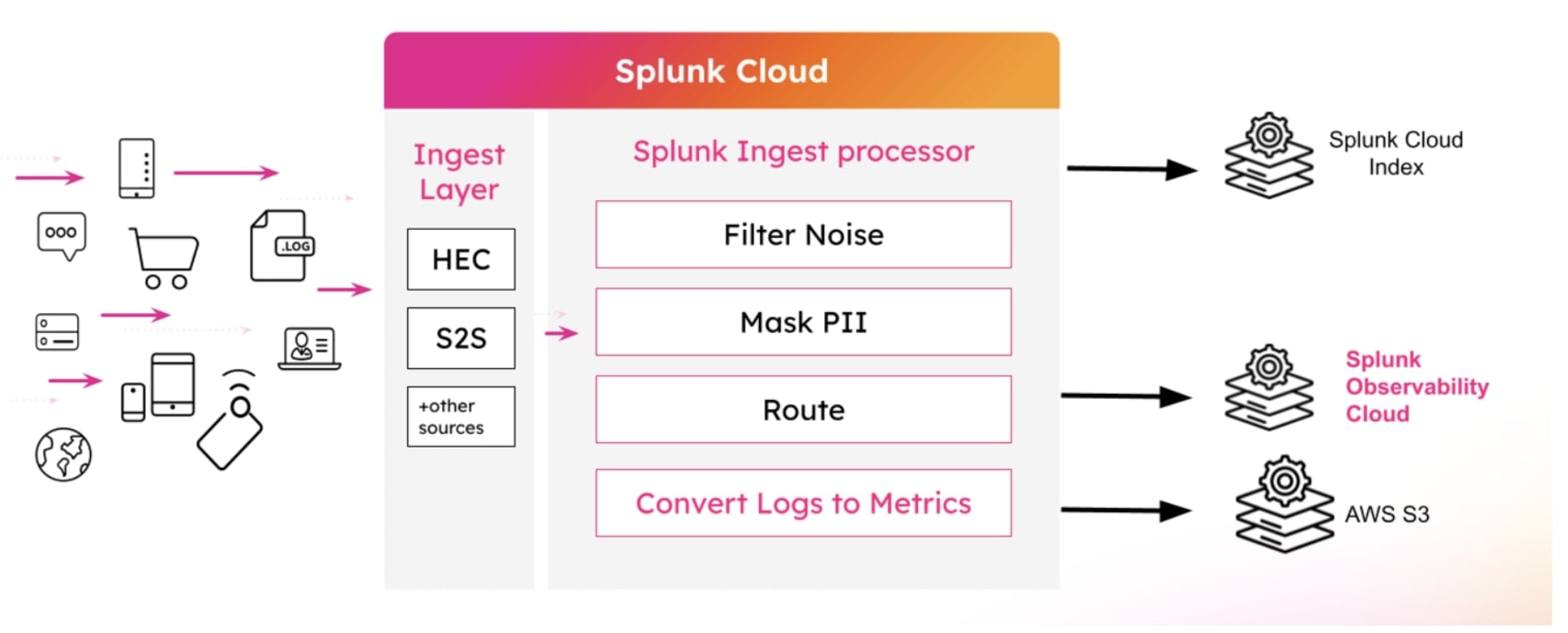
Building out data pipelines is easy within the Ingest Processor as it uses SPL2, a version of SPL that is designed for effective processing of data in motion - in stream and search - as well as at rest. And with an easy-to-use pipeline interface, along with a walk through wizard, you can quickly create a data pipeline and route the data to where you want it to go. The pipeline can also be tested on the data to ensure that it works and is providing the output you want before deployment.
In summary, the introduction of the Ingest Processor will revolutionise the use of log data within your environment. It will make the data much more relevant and focused, enabling quicker identification of issues, faster troubleshooting and issue resolution as well as being able to interrogate that log data to understand both customer and system behaviour. Check out the below links for some further reading:
Thanks to my colleague and fellow blogger, Ben Lovley, for his contribution to this blog. Check out Ben’s blogs here and learn more about doing cool things with data and Splunk.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
