As companies embrace containers, microservices, and complex architectural components, systems have grown more and more distributed and unpredictable, increasing the unknown unknowns. How can organizations remain efficient and effective in this type of intricate environment?
With observability-driven development.
Observability-driven development (ODD) is about using tools and hands-on developers to observe the behavior and state of a system to get insights into that specific system, especially patterns of weakness. As Charity Majors, who coined the term, explains it in her article Observability: A Manifesto:
“Observability means you can understand how your systems are working on the inside just by asking questions from the outside.”
Read on to learn more about ODD, why it matters for software today, and a guide to implementing it for your organization.
Harnessing the capability of observability for software development
ODD is a crucial practice in modern software development. A robust and proactive observability platform will help you predict and mitigate issues before they happen. As a result, you’ll improve your effectiveness when you update and track changes and release new features.
Just a few reasons why organizations need observability in their development practices include:
Modern complexity
Software systems are highly distributed and more complex than ever. When it comes to orchestrating numerous microservices, the traditional method of predicting and pinpointing issues becomes inefficient and often ineffective.
ODD is better equipped to manage this complexity because it focuses on understanding the inner workings of a system from its external outputs.
Proactive solutions
Organizations have long relied on reactive methods where developers fix issues only after they’ve caused a problem. ODD enables teams to proactively identify issues before they impact system performance or customer experience.
Fast resolution
Because it increases the visibility into how different software application components interact in real-time, ODD drastically reduces the time it takes to identify and address problems — software benefits from quicker resolution times, less downtime, and, ultimately, happier users.
Continuous improvement
ODD encourages a culture of constant learning and iteration. Teams have better insights for informed decisions because of consistent monitoring and a deep understanding of the system’s behavior. Plus, they can make choices that solve immediate issues and improve the overall system design and performance over time.
User focused
Ultimately, the software is about offering a seamless user experience. When they encounter system crashes, slow response times, and unexpected errors, it interferes with and negatively impacts their experience. ODD aims to identify and mitigate these issues even faster, perhaps before the user even notices. It ensures a smoother user experience.
DevOps and SRE practices
Organizations are adopting DevOps and Site Reliability Engineering (SRE) practices en masse. 83% of IT leaders said they are implementing DevOps to unlock more business value. This makes ODD principles more critical than ever. These practices emphasize constant collaboration, quick feedback, and shared responsibilities, all facilitated by ODD.
ODD offers an effective way to manage and improve increasingly complex systems to meet growing user expectations. Adopting ODD allows your organization to stay a step ahead of issues, leading to a smoother user experience and more robust software applications.
(DevOps monitoring is a key tool in maintaining observability in development practices.)
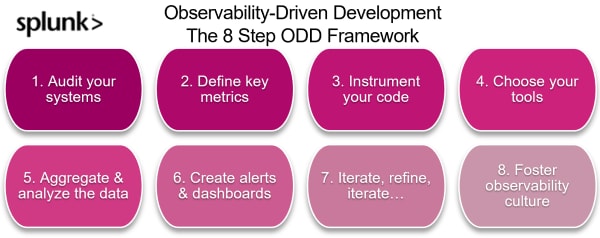
8 steps to implementing observability-driven development
Implementing ODD requires a comprehensive understanding of your software’s behavior in real-world conditions and a strategic approach to proactively finding and fixing problems.
Here is a step-by-step guide to implementing ODD in your organization:
Step 1: Perform a comprehensive system audit
Before implementing ODD, you need to understand your software system thoroughly, including its architecture and critical components. Identify the key transactions, interactions, and functionalities requiring more visibility. To determine what areas could benefit the most from increased observability, you can:
- Map out microservices
- Key user flows
- Identify important transactions or functions within your system
Step 2: Define key metrics
Once you thoroughly understand your system, establish which metrics and events are most crucial for understanding your system’s behavior. This could be error rates, response times, resource usage, or other custom metrics specific to your application. Observability data must hinge on three pillars:
- Logs: records of events happening in your system
- Metrics, quantitative measurements of your system
- Traces, records of a single operation across the system.
#3: Instrument your code
Next, it’s time to add the necessary code or implement existing libraries to your application to output the data you’ve identified as important. Instrumentation may involve:
- Setting up loggers
- Integrating with metrics libraries
- Implementing distributed tracing systems
It’s essential to strike a balance between comprehensive data collection and not overloading your system with instrumentation overhead.
#4: Choose your observability tools
A host of tools are designed to aid with ODD, such as log aggregators, APM tools, distributed tracing systems, and more. Your tool choice needs to align with your observability needs, the complexity of your system, and your budget.





