
Top 50 Threats Today
Get this free book for a complete look at today's most critical security threats.

Incident response (IR) is the set of strategic and organized actions an organization takes in the immediate aftermath of a cyberattack or security breach. The ultimate goal of your incident response actions is to reduce the risk of future incidents. As such, incident response plans aim to:
IR involves planning, preparation, detection, containment, recovery, and remediation efforts to safeguard your organization's digital assets and minimize the adverse consequences of cybersecurity incidents.
In this article, we'll take a look at the ins and outs of incident response, including:
In the realm of cybersecurity, various incidents can pose threats to an organization's network, potentially leading to unauthorized intrusions: people are getting into your network, and they should not be there. These incidents vary in their methods, intentions, and potential consequences, and they demand vigilance and robust security measures.
Understanding and preparing for these types of security incidents is crucial for organizations seeking to protect their digital assets and maintain the security and integrity of their networks. It's important to:
NIST defines incident response as "the mitigation of violations of security policies and recommended practices." Translated: how you shut down or minimize the severity of any violations of your security posture.
The terms "incident response" and "incident management" are often used interchangeably. While they're certainly related, they are distinct practices that complement each other. Incident response and incident management both live under the umbrella of “what to do when an incident occurs,” but they have a different scope:
Incident response focuses on the immediate actions to contain, eradicate, and recover from an incident. The goals of incident response are to:
Incident management focuses on the processes that support incident response and the aftermath of the incident. This involves classification and prioritization of an incident, collaboration between different stakeholders and teams, documentation, reporting, and deriving insights from the information to prevent the incident from repeating.
Incident response is not completely the responsibility of the security or incident response teams. In fact, in cloud environments and across distributed systems, the shared responsibility model plays a crucial role in ensuring effective incident response. Here's what the shared responsibility model often means (though of course, each vendor contract may differ):
Incident response can be difficult when there’s the involvement of disparate departments. Different departments may have varying priorities, workflows, security awareness, and technical proficiency. Organizations can smooth the incident response process by establishing cross-departmental IR teams that follow a centralized plan. Clearly defining roles and responsibilities and using clear communication are essential.
Incident response is critically important for organizations for a variety of reasons, detailed below.
Minimizing cybersecurity threats. Organizations face a constant and evolving threat from cyberattacks and security breaches. These threats can result in:
Incident response helps organizations prepare for, respond to, and recover from these threats effectively. (More on threat incidents later.)
Minimizing damage to internal systems and data. The quicker an organization can respond to a cybersecurity incident, the less damage it's likely to suffer. Incident response aims to identify and mitigate the impact of incidents promptly, reducing potential financial losses and operational disruption.
Protecting data and assets. If not managed effectively, incidents can result in the loss or theft of sensitive data and intellectual property. Incident response measures help protect an organization's critical assets and ensure data confidentiality, integrity, and availability.
Managing your reputation. Public perception of an organization can be significantly impacted by how it responds to a cybersecurity incident:
Stakeholder trust. Customers, partners, investors, and other stakeholders expect organizations to safeguard their data and assets. Demonstrating a commitment to incident response and cybersecurity can build trust and confidence among these groups.
Legal and regulatory compliance. Many industries and jurisdictions have specific legal and regulatory requirements for incident reporting and handling. Non-compliance can lead to legal consequences, fines, and other penalties. Incident response helps organizations meet these obligations.
Operational continuity. Effective incident response can minimize disruptions to an organization's operations. By quickly identifying and containing threats, incident response helps maintain business continuity and ensures that daily operations continue as smoothly as possible.
Risk mitigation. Incident response planning includes risk assessments, helping organizations identify vulnerabilities and weaknesses. By understanding these risks, organizations can take proactive steps to prevent incidents and reduce their likelihood.
Continuous improvement. Incident response is an iterative process. Each incident provides an opportunity to learn and improve response strategies, making the organization more resilient and better prepared for future incidents.
Splunk IT Service Intelligence (ITSI) is an AIOps, analytics and IT management solution that helps teams predict incidents before they impact customers.

Using AI and machine learning, ITSI correlates data collected from monitoring sources and delivers a single live view of relevant IT and business services, reducing alert noise and proactively preventing outages.
Let's look at some common types of cybersecurity incidents and security breaches. For more, learn about the most common cyber threats.
Unauthorized access incidents occur when an individual or a group attempts to infiltrate an organization's systems or access its data without permission. Examples include:
Privilege escalation incidents involve an attacker:
This can result in unauthorized access to critical resources and data, posing a significant risk to an organization's security.
(Related reading: principle of least privilege.)
Insider threat incidents occur when anyone with access privileges — a current or former employee, contractor, or some other individual — misuses their access for malicious purposes. Examples of insider threats include:
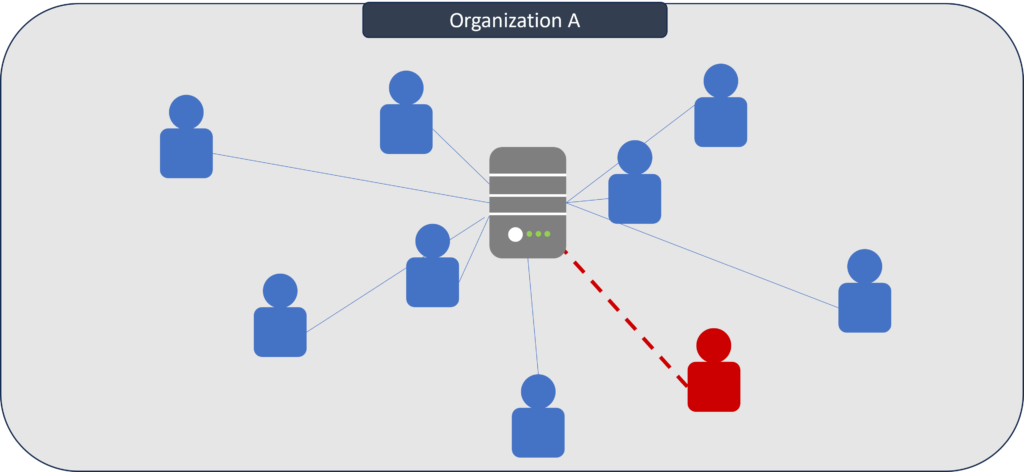
(Image source.)
Phishing incidents involve attackers sending deceptive emails or messages that appear to originate from legitimate sources but are, in reality, clever traps.
The primary objective of phishing is to deceive recipients into divulging sensitive information or to spread malware through malicious attachments or links.
Malware incidents involve the use of malicious software, such as viruses or Trojan horses, to compromise an organization's systems or data.
Different types of malware serve various purposes, from gaining unauthorized access to systems to disrupting normal operations. For instance, ransomware encrypts data and demands a ransom, usually money, for its release.
(Related reading: malware detection.)
A DoS incident occurs when an attacker floods a system or network with excessive traffic, rendering it unavailable to legitimate users.
The intention is to disrupt operations and services, causing inconvenience or financial harm to the organization.
(Related reading: DDoS, distributed denial-of-service attacks.)
In a MitM incident, aka on-path attacks, an attacker intercepts and potentially alters the communication between two parties without their knowledge. This can happen as easily as someone eavesdropping a conversation between you and a colleague.
Attackers can steal sensitive information or, when online, inject malicious content into the communication, compromising the confidentiality and integrity of data.
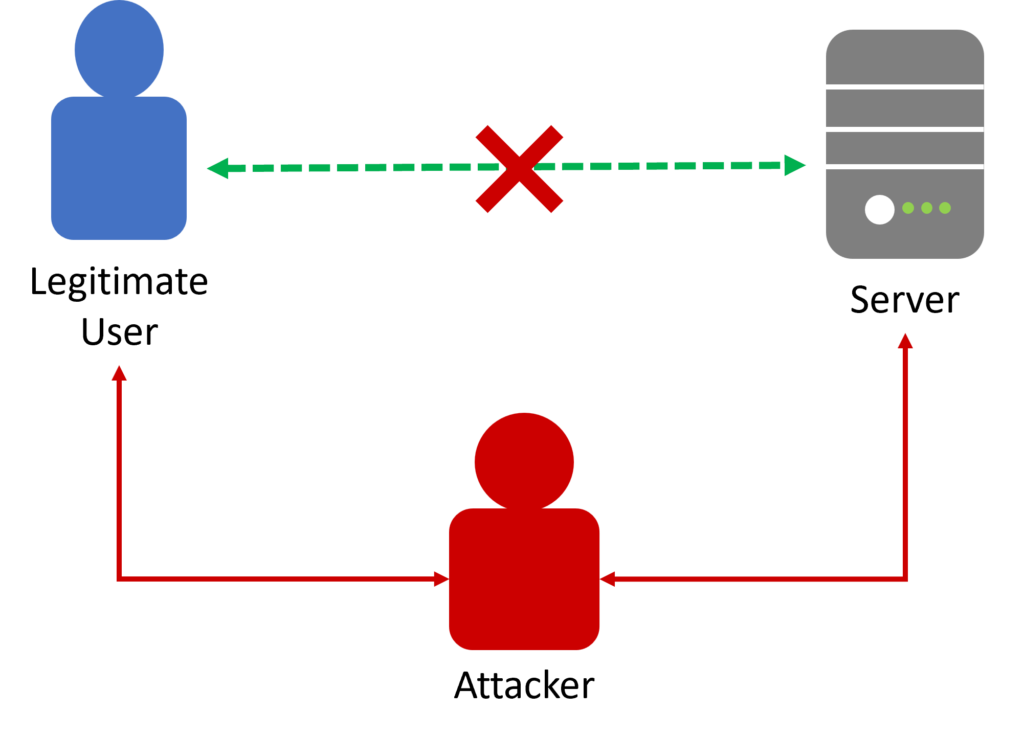
APTs are sophisticated and targeted attacks designed to gain access to an organization's systems or data.
These attacks are often orchestrated with the intention of stealing sensitive information or maintaining a long-term presence within the network, making them particularly challenging to detect and counter. Indeed, the average breach from an APT takes 150 days to be discovered.
Ransomware is a type of malicious software (malware) designed to encrypt a victim's files or lock them out of their computer system until a ransom is paid to the attacker. The ransom is typically demanded in cryptocurrency, such as Bitcoin, which provides a level of anonymity to the cybercriminals.
Ransomware attacks are a significant cybersecurity threat, and they can have devastating consequences for individuals, businesses, and organizations.
(Related reading: trends in ransomware.)
Now that we understand incidents and the concept of IR, let's look at frameworks that actually help you respond to incidents effectively. We'll cover two popular frameworks, from SANS and NIST, expert cybersecurity organizations.
The SANS Institute, a renowned organization in the field of cybersecurity, has outlined a comprehensive six-phase incident response life cycle, which provides a structured approach to handling cybersecurity incidents. These phases are designed to be repeated for each incident that occurs to continually improve an organization's incident response capabilities — and their overall security posture and readiness to respond to future threats.
The SANS incident response framework takes a highly practical approach to incident response. It’s great for organizations that focus attention on hands-on training and real-world scenarios. It also provides courses that include theoretical and practical training to deal with real-life incidents.
SANS is suitable for organizations that want their teams to follow a structured and repeatable process for incident response. The framework has clear, actionable steps that help guide even less experienced teams through an incident life cycle. It's also beneficial for organizations that want to stay ahead of emerging threats and require the latest data.
Here's an in-depth explanation of each phase.
In the preparation phase, the organization reviews its existing security measures, policies, and procedures to assess their effectiveness. This typically involves conducting a risk assessment to identify vulnerabilities and prioritize critical assets.
The findings from the risk assessment inform the development or refinement of incident response plans, including:
This phase is about enhancing the organization's readiness to respond to incidents and ensuring that high-priority assets are adequately protected.
(Related reading: CSIRTs, or critical security incident response teams.)
During this phase, security teams use the tools and procedures established in the preparation phase to detect and identify suspicious or malicious activity within the organization's network and systems.
When an incident is detected, the response team works to understand:
This phase also involves protecting and preserving any evidence related to the incident for further analysis and potential legal action. Communication plans are initiated to inform stakeholders, authorities, legal counsel, and users about the incident.
Once an incident is confirmed, the focus shifts to containment, with the goal of limiting the damage caused by the attack. Quick containment minimizes the attacker's ability to cause further harm. Containment is usually carried out in two phases:
For example, this may involve segmenting off the compromised network area or taking infected servers offline while rerouting traffic to failover systems.
(Related reading: redundancy vs. resiliency.)
In this phase, the incident response team gains a comprehensive understanding of the extent of the attack and identifies all affected systems and resources. The focus is on ejecting attackers from the network and eliminating malware from compromised systems. This phase continues until all traces of the attack are removed.
Depending on the severity of the incident, some systems may need to be taken offline and replaced with clean, patched versions during the recovery phase.
During the recovery phase, the incident response team brings updated or replacement systems online. The goal is to return systems to normal operation. Ideally, data and systems can be restored without data loss, but in some cases, it may be necessary to recover from the last clean backup.
The recovery phase also includes monitoring systems to ensure that attackers do not return or re-exploit vulnerabilities.
The final phase involves a comprehensive review of the incident response process. Team members evaluate what worked well and what didn't, and they identify areas for improvement.
Lessons learned, along with feedback and suggestions, are documented to inform the next round of preparation. Any incomplete documentation is wrapped up during this phase. This phase is essential for continuous improvement in incident response capabilities.
(Related reading: how to conduct incident reviews/postmortem/lessons learned.)
In addition to SANS, the NIST framework for incident response is another popular approach. The NIST incident response cycle consists of four key phases (full PDF here), each with specific goals and roles in the incident response process.
NIST's incident response framework benefits organizations that need a more flexible high-level blueprint for incident response. It aligns with the regulations of various industries such as healthcare, finance, or government agencies. Therefore, it’s beneficial for organizations that focus on compliance.
NIST’s adaptable framework makes it easier to integrate into a wide range of security strategies and is also better for organizations focusing on long-term risk management alongside incident response.
Now, let's look at each step.

(Image source.)
The preparation phase focuses on getting the organization ready to respond to cybersecurity incidents effectively. It includes:
In this phase, the organization assesses its risk environment, applies security best practices to systems and networks, secures the network perimeter, deploys anti-malware tools, and provides training to users. It involves creating an environment where the incident response team can quickly mobilize and coordinate their efforts when needed.
This phase involves identifying the type of threat an organization is facing and determining whether it constitutes an incident. It includes detecting and analyzing signs of potential incidents: indicators of compromise and indicators of attack.
During detection and analysis, the organization looks for precursors (indicators of future incidents) and indicators (evidence that an incident may be occurring or has already occurred). To detect and identify anomalies, use techniques such as:
Incidents are documented and prioritized, and this information is then used to respond effectively.
The bulk of active incident response takes place in this phase. The primary objectives are to contain the threat, eradicate it, and recover affected systems to resume normal operations. Containment strategies are defined based on the type of attack and the potential damage. Incident response teams work to:
Eradication involves removing malware and compromised accounts. The recovery phase focuses on restoring systems from clean backups, implementing security patches, and improving defenses.
This often-overlooked phase is crucial for learning from the incident and improving future incident response efforts. It includes conducting an incident review or "lessons learned" meeting, preserving data and evidence, and revisiting preparation for future cybersecurity threats.
In the post-incident phase, the organization conducts a thorough review of the incident, documenting key findings and strategies for improvement. Data collected during the incident is preserved, and the incident response team assesses its performance against established baselines and metrics. The findings and lessons learned can inform future incident response and prevention efforts. Additionally, organizations are encouraged to share their insights with other entities to enhance collective cybersecurity knowledge.
Commonly used incident response technologies encompass a range of tools and solutions that play crucial roles in identifying, analyzing, and mitigating security incidents. Some of these technologies and solutions are detailed below.
SIEM systems serve as centralized platforms for aggregating and correlating security event data. SIEMs put together data from various internal security tools, including firewalls, vulnerability scanners, and threat intelligence feeds.
SIEM helps incident response teams sift through the vast volume of notifications generated by these tools, enabling them to focus on indicators of actual threats and reduce "alert fatigue."
(Learn about our industry-leading SIEM, Splunk Enterprise Security.)
SOAR technology empowers security teams to define playbooks, which are structured workflows that coordinate different security operations and tools in response to security incidents. SOAR also facilitates the automation of specific tasks within these workflows, improving efficiency in incident response.
(Learn more: SIEM vs SOAR: What’s The Difference?)
Endpoint detection and response (EDR) software is designed to provide automatic protection for an organization's end users, endpoint devices, and IT assets against cyberthreats that can bypass traditional antivirus software and other endpoint security tools. It continuously collects data from all network endpoints, analyzing it in real time to detect known or suspected cyberthreats and respond automatically to prevent or minimize potential damage.
Extended Detection and Response (XDR) is a cybersecurity technology that unifies security tools, data sources, telemetry, and analytics across various parts of the hybrid IT environment, including endpoints, networks, and both private and public clouds. It aims to create a centralized system for threat prevention, detection, and response, helping security teams and Security Operations Centers (SOCs) streamline their efforts by eliminating tool silos and automating responses throughout the entire cyberthreat kill chain.
Though more "modern" than EDR, XDR does have certain limitations, primarily:
These drawbacks can restrict security teams’ ability to use existing or new security solutions of their choice with an XDR platform. Security teams may also encounter blind spots due to XDR solutions’ limited security data coverage, especially when using XDR as the primary security operations platform.
UEBA leverages behavioral analytics, machine learning algorithms, and automation to identify abnormal and potentially hazardous user and device behavior. It's particularly effective at detecting insider threats, such as malicious insiders or hackers using compromised insider credentials.
UEBA functionality is often integrated into SIEM, EDR, and XDR solutions, enhancing their capabilities in identifying and responding to security incidents.
(Learn more: Splunk User Behavior Analytics.)
ASM solutions automate the continuous process of discovering, analyzing, remediating, and monitoring vulnerabilities and potential attack vectors across an organization's entire attack surface. These solutions can uncover previously unmonitored network assets, establish relationships between assets, and provide essential insights to enhance overall security.
These incident response technologies play crucial roles in helping organizations bolster their cybersecurity efforts, detect and respond to threats more effectively, and manage their attack surface to reduce vulnerabilities and potential attack vectors.
Incident response is essential for organizations to protect themselves from the ever-present and evolving threats in the digital landscape. It helps organizations safeguard their data, minimize damage, maintain trust, and meet legal and regulatory obligations. A well-executed incident response strategy is a cornerstone of modern cybersecurity risk management.
Splunk is helping enterprise organizations around the world build their digital resilience. Explore Splunk's industry-leading products and solutions for cybersecurity, monitoring and observability, and data management.
See an error or have a suggestion? Please let us know by emailing ssg-blogs@splunk.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.


The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk LLC All rights reserved.
