
Debunking AI & ML Myths
AI is evolving fast. See how AI and humans can thrive together in this free guide.

Foundation Models are central to the ongoing hype around Artificial Intelligence. Google’s BERT, OpenAI’s GPT series, Stability AI’s Stable Diffusion, and thousands of models from the open-source community Hugging Face pretrained on large data assets serve as Foundation Models in AI.
So, what exactly is a Foundation Model? Let’s discuss the working principles, key purpose, challenges and opportunities of Foundation Models in AI.
A Foundation Model is a general class of generative AI models that is trained on large data assets at scale. A foundation model must have the following key properties:
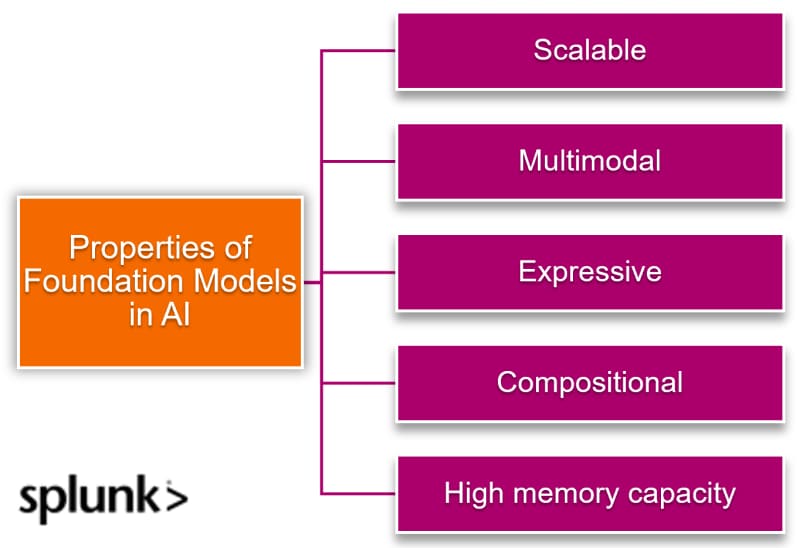
Scalable. The model architecture can efficiently train on large volumes of multidimensional data. Foundation models can fuse knowledge from multimodal data about a downstream application.
Multimodal. The training data can take multiple forms including text, audio, images and video. For example, medical diagnosis involves analysis of:
As in multimodal AI, the foundation model can capture knowledge from all information domains that span multiple modes.
Expressive. The models not only converge efficiently to accuracy metrics but can assimilate real-world data used to train them, by capturing rich knowledge representations.
Compositional. The models can effectively generalize to new downstream tasks. Similar to human intelligence, foundation models can effectively generalize on the out-of-distribution data. This information may contain some similarities to the training data, but cannot belong to the training data distribution itself.
High memory capacity. The models can accumulate growing and vast knowledge. Since the models learn from a variety of data distributions, it can continually learn on new data without catastrophically forgetting its previously learned knowledge. This objective is also known as continual learning in AI.
Together, these properties combine to realize three essential objectives:
Training mechanism typically entails self-supervised learning. In a self-supervised setting, the model learns general representations of unstructured data without externally imposed ground-truth labels.
In simple terms, an output label corresponding to the input data is not known.
Instead, common patterns within the data distribution are used to group them together based on discovered correlations. These categories are generated from a pretext task that is generally easier to solve and are used as supervisory signals or implicit labels for the more challenging downstream tasks such as:
Following the same concepts, the paradigm of the Foundation Model is enabled by its scale of learning against large volumes of information, and the deep learning approach of Transfer Learning.
The key idea of transfer learning is to use existing knowledge to solve a complex task. In the context of deep learning, transfer learning refers to the practice of:
The recent success of transfer learning comes down to three fundamental driving forces in present era of artificial intelligence:
Recent advancements in transfer learning, which is the key enabler of general-purpose foundation models used today, are largely attributed to transform-based architecture models deployed in a self-supervised training setting.
The hype around AI is largely based on the promise of AGI: Artificial General Intelligence. AGI refers to an AI agent with intelligence that can surpass a human mind. This promise comes from the emergence and homogenization of general foundation models.
Foundation models also have some limitations. Since the model can only train on publicly available information, it can naturally learn a bias toward highly represented groups (or a bias against underrepresented groups).
As we have already observed the instances of inductive bias among popular foundation models, it is safe to say that, so far, no single algorithm or model that can perform well universally.
The No Free Lunch theorem persists. For now, at least, AGI is far from reality.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
