
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

With evolving cyber threats and sudden disasters, data resilience is among the critical components of any business. Data resilience helps businesses provide continuous, uninterrupted services to their customers.
This article explains data resilience, its importance for current businesses, and the most common strategies to achieve data resilience. It also describes the advantages and challenges of achieving business data resilience.
Data resilience is the ability of an organization or its systems to continue business operations in case of unexpected disruptions that directly impact data availability. A few examples of such incidents include hardware or software failures, cyberattacks, natural disasters and power outages.
Data resilience ensures the continuous availability of critical information and related resources for users regardless of disruptions and prevents unauthorized access to data. Data resilience involves several strategies, such as:
Currently, a robust and comprehensive risk management strategy is one of the major components of the business resilience program of an organization. Data resilience builds both cyber resilience and enterprise resilience.
(Explore public sector stories: Profiles in Resilience)
OK, so business resilience is important, but exactly why? There’s a few reasons for this, actually. Businesses process complex, integrated computer systems that rely heavily on various types of data. Any disruption to those systems can have cascading failure effects on day-to-day business operations.
Additionally, a large volume of data is generated, stored and used in multiple important workloads, including data analytics workloads. Such data often includes sensitive and confidential information, which should be carefully handled. Loss of such data due to unexpected disasters can have serious consequences.
Finally, with cyberattacks feeling near daily, organizations continue to suffer from the consequences of data breaches — financial losses, reputational damage, legal issues — without a proper data resilience strategy in place. Therefore, data resilience is essential for organizations to mitigate risks and build a more reliable business.

There are several strategies to quickly identify, respond to, and recover from unexpected events in order to achieve data resilience. Following are some of the most common strategies and some important tips for making them more effective.
Taking data backups is the oldest technique — and for good reason. Backups are copies of data stored separately from the original data. Regular backups ensure the availability of multiple copies of important data. Thus, they help achieve data resilience by providing a quick way to restore lost data.
When taking backups, it is important to store them in a secure, remote location. Furthermore, you should regularly test them to ensure their availability to recover data during a failure or disaster.
Data encryption ensures no unauthorized party can inspect or access sensitive data. Thus, information will remain confidential and difficult to compromise by cyber attackers. Regular backups should also be encrypted to ensure data resilience.
Additionally, encryption ensures data integrity by avoiding data tampering and alterations by third parties.
Server redundancy means having multiple servers that can run the same workloads in data centers. It allows the other servers to take over the workload if one server fails. Thus, server redundancy helps achieve data resilience by ensuring the systems remain available even during a server failure. Obvious benefits include:
Today, cloud services are one of the best solutions for achieving data resilience. Their capabilities include:
These features allow organizations to be more data resilient without managing those services independently. Cloud services also offer automatic backups, allowing organizations to quickly and easily recover their data in the event of a data loss.
They also provide disaster recovery strategies, ensuring that data can be restored efficiently in case of a natural disaster or other catastrophic events.
A disaster recovery plan is a strategy that defines the steps to follow during a disaster. It helps minimize data loss and ensure that data remains available to users.
One of the important steps in a disaster recovery plan is identifying critical data, which helps prioritize recovery efforts. This step also ensures that the organization recovers critical and sensitive data first. Additionally, the strategy should include a proper incident response plan outlining which people to contact during a disaster.
No strategy will be effective without properly educating employees on the best data management and data security practices. This training should include the following aspects:
Apart from the above techniques, data mirroring, database replication, snapshots and flash copies are some of the newest techniques that help achieve data resilience. Today, these techniques are already in practice with most major cloud service providers.
There are several ways organizations benefit from data resilience, as listed below.
Any user expects continuous access to critical information and functionalities regardless of any underlying issue. If your systems provide paid functionality, disruption of those services can irritate the users and make them discontinue using your systems. Yet, data resilience enables continuous, uninterrupted services for your customers. They will find your systems reliable, improving the reputation of your business.
Data resilience strategies involve implementing cyber security strategies like encryption, firewalls and access control. They will improve the overall security posture of the organization and make it more resilient to cyberattacks.
The more data-resilient your information and services, the more accessible they will be to your customers. Unexpected downtimes can cause severe financial losses. Data resiliency helps to:
Strategies like load balancing and auto-scaling improve system performance. They help avoid service failures due to high data loads by automatically increasing the required resources and capacity.
If it were easy, you’d probably already have resilient data. What are the actual challenges of implementing data resilience more widely inside your organization?
Even though data resilience helps improve business revenue, it also involves costly processes. For example, taking multiple backups and maintaining them in separate remote locations will incur additional costs with increased data volume. Besides, more human resources and infrastructure will be required to maintain such strategies.
Even in cloud-based systems, costs can increase as the data volume grows. Furthermore, small businesses lack the resources and infrastructure to maintain data resilience, making them vulnerable to data losses.
At present, organizations deal with sophisticated systems with complex integrations, resulting in increased data volume and complexity. Thus, implementing data resilience covering the full digital landscape of the organization becomes difficult with this high sophistication, data complexity, and volume.
Besides, some strategies may not be effective for some organizations, and they will require specific strategies. These complexities can bring many challenges in achieving data resilience.
Cyber threats evolve as new ways of attacking organizations and can be armed with sophisticated technologies. Dealing with such cyber threats is difficult without implementing the necessary updates and techniques.
Some organizations struggle to stay up-to-date to deal with those sophisticated cyber threats or may not have the budget to implement them.
Some regulations, like data privacy and security laws (GDPR in the European Union and the California Consumer Privacy Act), could become barriers when implementing data resilience strategies. Organizations should be well aware of such regulations and must ensure they meet the requirements of such regulations while maintaining data resilience.
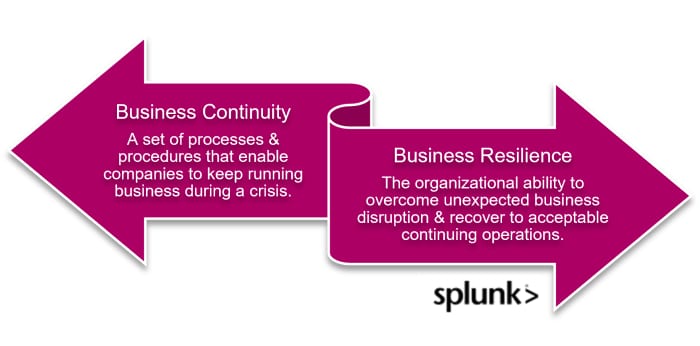
Data resilience is the ability of organizations to continue business operations even after a disaster, providing continuous, uninterrupted service to their consumers. It is critical to have strong data resilience due to increasing cyber threats and the consequences of critical data becoming unavailable for the end users.
There are several strategies to improve data resilience, including data backups, encryption, using cloud services, disaster recovery strategies and providing employees with necessary education on data resilience. Finally, the field of data resilience looks promising with new and evolving technologies like AI, ML and IoT.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
